一种面向人工智能大模型高效训练的并行策略搜索方法与流程
- 国知局
- 2024-11-21 11:51:33
本发明涉及人工智能,具体涉及一种面向人工智能大模型高效训练的并行策略搜索方法。
背景技术:
1、近年来,人工智能大模型的参数量快速上涨,并在计算机视觉、自然语言处理等各个领域的大部分任务上取得了最佳的效果。与之相对的,计算硬件发展的速度非常缓慢。因此不得不利用单机多卡或集群进行并行训练。
2、并行策略是一种计算策略,用于在多个处理器或计算机上同时处理多个计算任务或数据集,这种策略主要目的是加速处理速度和提高效率。在不同的领域和应用中,并行策略有多种形式,包括数据并行、模型并行、流水线并行和混和并行。
3、现有基于机器学习的分布式并行策略自动搜索和调优技术通常以训练时间或通信时间为单一性能评价指标,在特定深度学习模型下实现分布式并行策略的搜索和调优,因此训练整体性能提升受限。此外,并行策略的搜索调优过程本身会产生巨大的额外开销,甚至无法抵消并行训练所带来的性能优化收益。
技术实现思路
1、本发明的目的是提供一种面向人工智能大模型高效训练的并行策略搜索方法,以解决现有技术中的上述不足之处。
2、为了实现上述目的,本发明提供如下技术方案:一种面向人工智能大模型高效训练的并行策略搜索方法,具体包括以下步骤:
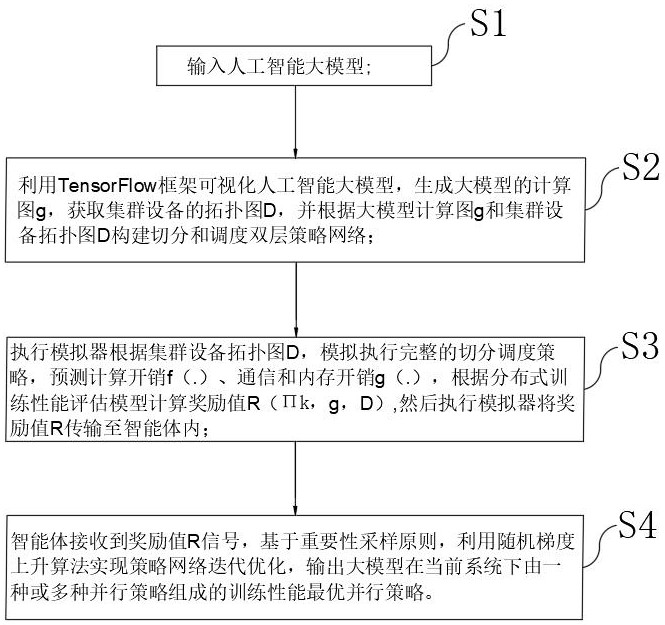
3、s1、输入人工智能大模型;
4、s2、利用tensorflow框架可视化人工智能大模型,生成大模型的计算图g,获取集群设备的拓扑图d,并根据大模型计算图g和集群设备拓扑图d构建切分和调度双层策略网络;
5、s3、执行模拟器根据集群设备拓扑图d,模拟执行完整的切分调度策略,预测计算开销f(.)、通信和内存开销g(.),根据分布式训练性能评估模型计算奖励值,然后执行模拟器将奖励值r传输至智能体内;
6、s4、智能体接收到奖励值r信号,基于重要性采样原则,利用随机梯度上升算法实现策略网络迭代优化,输出大模型在当前系统下由一种或多种并行策略组成的训练性能最优并行策略。
7、进一步地,s2中所述大模型计算图g具体为g(o,e),其中顶点o表示待训练大模型网络算子,记为o={o1,o2,……,on},e为连接顶点o的有向边,表示计算节点间的通信数据,记为e={e11,e12,……,eij}:
8、所述集群设备拓扑图d是将集群计算设备抽象得到,由m个可用设备{d1,d2,……,dm}组成。
9、进一步地,s2中通过将所述切分和调度双层策略网络引入共享层并组成智能体。
10、进一步地,s3中所述执行模拟器用于在单节点上通过队列的形式模拟gpu算子计算和通信过程。
11、进一步地,s3中所述分布式训练性能评估模型包括计算代价模型、通信代价模型和内存代价模型;
12、计算代价模型用于衡量第i个设备di在训练过程中的计算负载情况,表示为,其中n为参与计算的总张量数,分别表示当前张量第k维度大小,ci为第i个设备di上参与运算的张浮点操作数,ci为第i个设备的计算密度;
13、通信代价模型用于衡量设备di和dj之间在训练过程中的通信负载情况,表示为,其中n为参与通信的总张量数,tn表示在设备di,dj之间传输的张量,a为计算张量尺寸规模函数,表示设备i和设备j间通信带宽;
14、内存代价模型用于衡量第i个设备di在训练过程中的内存负载情况,表示为,其中n表示存储在当前设备di上的总张量数,tn表示当前张量,a为计算张量尺寸规模函数。
15、进一步地,s3中所述奖励值根据计算代价模型、通信代价模型和内存代价模型构建,可表示为,其中表示为第k个并行策略,α和β是权重参数,ei表示大模型训练过程中的计算负载情况,表示大模型训练过程中的通信负载情况,mi表示大模型训练过程中的内存负载情况。
16、进一步地,s4具体包括以下步骤:
17、令和分别表示切分和调度策略,对应的网络参数用表示,生成并行策略的概率分布;
18、进一步分离切分和调度策略网络参数后,可细化为目标函数,由tf框架对目标函数关于和求偏导数和;
19、最后利用随机梯度上升算法实现切分和调度策略网络参数的迭代优化,返回训练性能最优的并行策略和对应的奖励值r。
20、进一步地,s4中的重要性采样原则用于解决参数变化导致的剧烈抖动而引起抽取策略样本效率低和样本间方差大的问题。
21、进一步地,所述随机梯度上升算法具体为:
22、输入可用设备序列组,切分和调度网络初始化参数;
23、设置最小奖励min为无限大,奖励值r为0;
24、算法从i=1到n进行循环;
25、在每次循环过程中,定义一个包括若干子组,将添加到一个列表group中;
26、利用将group与配对得到;
27、将配对结果应用到评估模型中计算得到奖励值ri;
28、如果ri<min,那么更新最优策略π*为,min为当前的ri,参数为原加上,参数为原加上;
29、若ri=min,则跳出循环,输出当前ri和对应的最优策略π*;
30、若算法从i=1到n循环结束,仍未有ri=min,则输出rn和对应的最优策略π*。
31、与现有技术相比,本发明提供的一种面向人工智能大模型高效训练的并行策略搜索方法,具备以下有益效果:
32、1、通过挖掘神经网络模型并行训练过程中的计算和通信特点,建立分布式训练性能评估模型,更准确地评估并行策略的综合性能;
33、2、通过采用双层策略网络构建智能体,减少搜索过程中的开销,防止内存溢出;
34、3、通过采用随机梯度上升算法有利于算法在参数改变可能导致新旧策略概率分布的剧烈变化时保持平稳收敛。
技术特征:1.一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s2中所述大模型计算图g具体为g(o,e),其中顶点o表示待训练大模型网络算子,记为o={o1,o2,……,on},e为连接顶点o的有向边,表示计算节点间的通信数据,记为e={e11,e12,……,eij};
3.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s2中通过将所述切分和调度双层策略网络引入共享层并组成智能体。
4.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s3中所述执行模拟器用于在单节点上通过队列的形式模拟gpu算子计算和通信过程。
5.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s3中所述分布式训练性能评估模型包括计算代价模型、通信代价模型和内存代价模型;
6.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s3中所述奖励值根据计算代价模型、通信代价模型和内存代价模型构建,可表示为,其中表示为第k个并行策略,α和β是权重参数,ei表示大模型训练过程中的计算负载情况,表示大模型训练过程中的通信负载情况,mi表示大模型训练过程中的内存负载情况。
7.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s4具体包括以下步骤:
8.根据权利要求1所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,s4中的重要性采样原则用于解决参数变化导致的剧烈抖动而引起抽取策略样本效率低和样本间方差大的问题。
9.根据权利要求7所述的一种面向人工智能大模型高效训练的并行策略搜索方法,其特征在于,所述随机梯度上升算法具体为:
技术总结本发明公开了一种面向人工智能大模型高效训练的并行策略搜索方法,涉及人工智能技术领域,具体包括以下步骤:S1、输入人工智能大模型;S2、利用TensorFlow框架可视化人工智能大模型,生成大模型的计算图g,获取集群设备的拓扑图D;该面向人工智能大模型高效训练的并行策略搜索方法,通过挖掘神经网络模型并行训练过程中的计算和通信特点,建立分布式训练性能评估模型,更准确地评估并行策略的综合性能,通过采用双层策略网络构建智能体,减少搜索过程中的开销,防止内存溢出,通过采用随机梯度上升算法有利于算法在参数改变可能导致新旧策略概率分布的剧烈变化时保持平稳收敛。技术研发人员:沈益民,周学立,李蒙科,陈峥,林冉孜,杨凡受保护的技术使用者:成都边界元科技有限公司技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/333050.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。