用于细化结构变体检出的机器学习模型的制作方法
- 国知局
- 2024-11-21 11:54:01
背景技术:
1、近年来,生物技术公司和研究机构已经改进用于对核苷酸进行测序并确定基因组样本的核苷酸碱基检出的硬件和软件。例如,一些现有测序机和测序-数据分析软件(统称为“现有测序系统”)通过使用常规桑格(sanger)测序或合成测序(sbs)方法来预测序列内的单独核苷酸碱基。当使用sbs时,现有测序系统可监测从模板平行合成的数千个寡核苷酸以预测生长的核苷酸读段的核苷酸碱基检出。在许多现有测序系统中,相机捕获掺入寡核苷酸中的被辐照荧光标签的图像。在捕获此类图像之后,一些现有测序系统确定与寡核苷酸相对应的核苷酸读段的核苷酸碱基检出并将碱基检出数据发送到具有测序-数据分析软件的计算设备,该计算设备将核苷酸读段与参考基因组进行比对。基于被比对核苷酸读段与参考基因组之间的差异,现有系统还可利用变体检出器来识别基因组样本的变体,诸如单核苷酸多态性(snp),以及/或者结构变体。
2、尽管有在测序和变体检出方面的这些最新进展,但是现有测序系统经常包括不准确地确定结构变体检出、尤其是针对在碱基对长度的阈值范围(例如,从50个至200个碱基对的长度)内的结构变体的结构变体检出的变体检出器。例如,许多现有系统生成包括针对在碱基对长度的阈值范围内的结构变体的过量数目的假阳性检出和/或假阴性检出的结构变体检出。促成这种不准确度的是,一些测序系统过度依赖不可靠的真值集数据。例如,一些现有系统基于包含某些不一致性和错误的数据(诸如来自测序过程的不一致或易错的读段数据或不一致或易错的参考数据和/或来自变体检出模型的变体检出)来执行变体检出和/或变体检出过滤。事实上,在行业中的标准或替代真值集数据(例如,precisionfda真值集数据或长读段数据)包含错误或覆盖空洞(不过数目很少),该错误或读段覆盖空洞可通过在这些数据上进行训练的现有系统传播并影响该现有系统的结构变体检出。因此,太过于依赖此类真值集数据导致许多现有系统生成包括本来在更准确的系统的情况下可能减少的过量数目的假阳性检出和/或假阴性检出的结构变体检出。如下文所描述,已经证明真值集数据对在碱基对长度的阈值范围内确定相对更小大小结构变体检出的现有测序系统特别成问题。
3、一些现有测序系统利用要求对数百万或数十亿不可用或不完整的碱基检出数据进行训练的模型,这加剧了这种结构变体检出不准确度。更具体地,一些测序系统利用要求过量量的训练数据来实现可接受的准确度量度的深度学习模型。然而,结构变体的训练数据在整个行业中是相对有限的,并且使用不完整或非实质的数据的训练模型导致不准确且不可靠的结构变体检出预测。因此,依赖深度学习模型的现有系统经常产生不准确的结构变体检出,这对在碱基对长度的阈值范围内的相对更小大小结构变体可能是尤其突出的。
4、除不准确地确定结构变体检出之外,一些现有测序系统还因过度复杂的模型而低效地消耗了计算资源。具体地,一些现有测序系统的结构变体检出器是计算成本高且缓慢的。事实上,一些测序系统利用具有要求大量计算资源(例如,计算时间、处理能力和存储器)来进行训练和应用的深度学习架构的结构变体检出器。例如,一些现有测序系统利用即使在训练之后也跨多个计算设备消费许多小时来生成单个样本序列的结构变体检出的深度学习架构。
5、作为具有复杂深度学习网络的现有测序系统的另一个缺点,许多此类系统利用使序列数据不可解释的模型架构。更具体地,用于变体检出的一些现有深度神经网络多次变换和操纵序列数据,跨各个层和神经元从一个不可解释的潜在向量改变为另一个此类潜在向量,作为生成结构变体检出的基础。在许多情况下,这些深度神经网络的内部数据是不可解释的,并且不可能在神经网络架构本身之外以任何方式利用。
技术实现思路
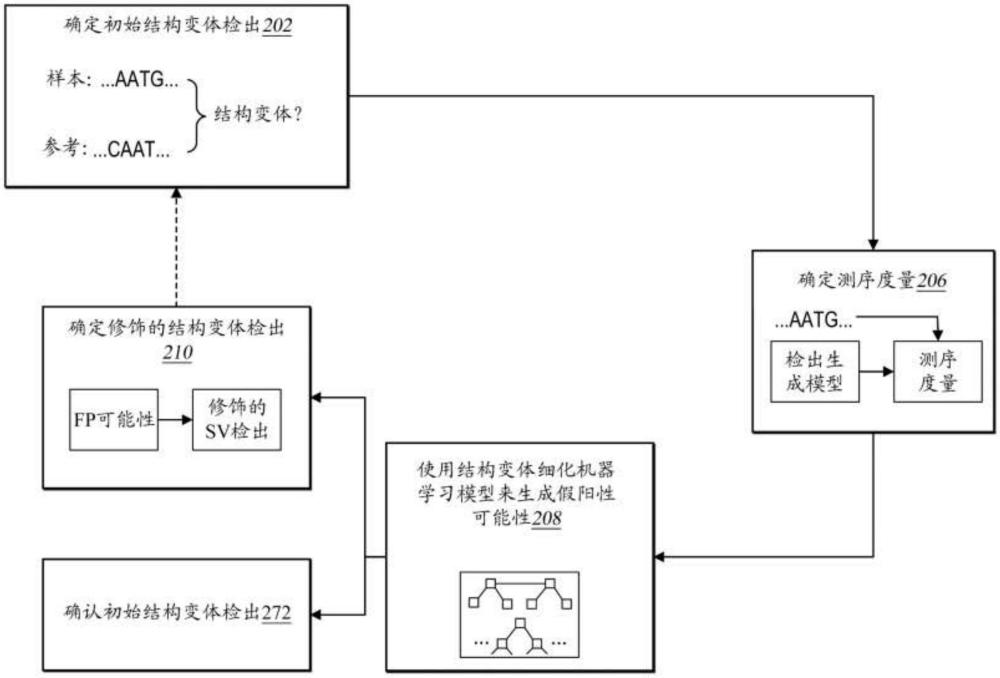
1、本公开描述了可利用机器学习模型来修饰或确认检出生成模型的结构变体检出的方法、非暂态计算机可读介质和系统的实施方案。例如,所公开的系统可训练或利用结构变体细化机器学习模型来减少假阳性检出(例如,在不存在结构变体的情况下的结构变体检出)和/或假阴性检出(例如,在存在结构变体的情况下的结构变体检出)。事实上,所公开的系统可确定与初始结构变体检出相对应的测序度量并利用该结构变体细化机器学习模型基于该测序度量来确定该初始结构变体检出是假阳性的假阳性可能性。基于来自该结构变体细化机器学习模型的该假阳性可能性,所公开的系统可校正或确认由检出生成模型初始确定的结构变体检出(例如,在50个至200个碱基对之间的长度)。如所公开,该系统还可定制或校正结构变体的训练数据以训练结构变体细化机器学习模型来生成修饰的结构变体检出。
技术特征:1.一种系统,包括:
2.根据权利要求1所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过确定超过阈值数目的碱基对的缺失、超过所述阈值数目的碱基对的插入、超过所述阈值数目的碱基对的复制、倒位、易位或拷贝数变异(cnv)来确定所述初始结构变体检出。
3.根据权利要求1所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过确定在碱基对的阈值范围内的一定数目的碱基对的结构变体检出来确定所述初始结构变体检出。
4.根据权利要求1所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过识别基于读段的测序度量、基于参考的测序度量或变体区域质量测序度量中的一者或多者来识别与所述初始结构变体检出相对应的所述测序度量。
5.根据权利要求4所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过针对所述初始结构变体检出确定以下中的一者或多者来识别所述基于读段的测序度量:
6.根据权利要求4所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过确定以下中的一者或多者来识别所述变体区域质量测序度量:
7.根据权利要求4所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过在参考基因组的与所述基因组样本的所述一个或多个基因组坐标相对应的一个或多个基因组区域内识别以下中的一者或多者来识别所述基于参考的测序度量:
8.根据权利要求1所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统:
9.根据权利要求1所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统:
10.根据权利要求9所述的系统,还包括指令,所述指令在由所述至少一个处理器执行时使所述系统通过以下来基于所述结构变体准则来确定所述基准真值结构变体检出被不正确地标记:
11.一种计算机实现的方法,包括:
12.根据权利要求11所述的计算机实现的方法,其中:
13.根据权利要求11所述的计算机实现的方法,其中确定所述初始结构变体检出包括确定超过阈值数目的碱基对的缺失、超过所述阈值数目的碱基对的插入、超过所述阈值数目的碱基对的复制、倒位、易位或拷贝数变异(cnv)。
14.根据权利要求11所述的计算机实现的方法,其中识别与所述初始结构变体检出相对应的所述测序度量包括识别基于读段的测序度量、基于参考的测序度量或变体区域质量测序度量中的一者或多者。
15.根据权利要求11所述的计算机实现的方法,其中识别所述测序度量包括针对所述初始结构变体检出确定以下中的一者或多者:
16.根据权利要求11所述的计算机实现的方法,其中识别所述测序度量包括确定以下中的一者或多者:
17.根据权利要求11所述的计算机实现的方法,其中识别所述测序度量包括在参考基因组的与所述基因组样本的所述一个或多个基因组坐标相对应的一个或多个基因组区域内识别以下中的一者或多者:
18.一种非暂态计算机可读介质,所述非暂态计算机可读介质包括指令,所述指令在由至少一个处理器执行时使计算设备:
19.根据权利要求18所述的非暂态计算机可读介质,其中所述结构变体细化机器学习模型包括一个或多个梯度提升决策树。
20.根据权利要求18所述的非暂态计算机可读介质,还包括指令,所述指令在由所述至少一个处理器执行时使所述计算设备:
21.根据权利要求18所述的非暂态计算机可读介质,还包括指令,所述指令在由所述至少一个处理器执行时使所述计算设备:
22.根据权利要求21所述的非暂态计算机可读介质,还包括指令,所述指令在由所述至少一个处理器执行时使所述计算设备通过以下来基于所述结构变体准则来确定所述基准真值结构变体检出被不正确地标记:
23.根据权利要求18所述的非暂态计算机可读介质,还包括指令,所述指令在由所述至少一个处理器执行时使所述计算设备利用基于所述测序度量的所述结构变体细化机器学习模型以及所述初始结构变体检出作为输入来生成所述假阳性可能性。
技术总结本公开描述了可利用机器学习模型来细化检出生成模型的结构变体检出的方法、非暂态计算机可读介质和系统。例如,所公开的系统可训练和利用结构变体细化机器学习模型来减少假阳性和/或假阴性。事实上,所公开的系统可通过训练和利用该结构变体细化机器学习模型来改进或细化通过检出生成模型来确定的结构变体检出(例如,在50个至200个碱基对之间的长度)。如所公开,该系统可确定测序度量并可定制结构变体细化机器学习模型的训练数据以生成修饰的结构变体检出。技术研发人员:S·察利,G·D·帕纳比,N·纳里艾受保护的技术使用者:因美纳有限公司技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/333283.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表