[0001]
本公开总体上涉及存储器装置,并且更具体地涉及用于人工智能操作的调试操作的 设备和方法。
背景技术:
[0002]
存储器装置通常作为内部半导体集成电路设置于计算机或其它电子装置中。存在许 多不同类型的存储器,包含易失性存储器和非易失性存储器。易失性存储器可能需要电 力来维护其数据并且包含随机存取存储器(ram)、动态随机存取存储器(dram)和同步 动态随机存取存储器(sdram)等。非易失性存储器可以通过在断电时保留所存储的数据 来提供持久数据并且可以包含nand闪存、nor闪存、只读存储器(rom)、电可擦除 可编程rom(eeprom)、可擦除可编程rom(eprom)和电阻可变存储器,如相变随机 存取存储器(pcram)、电阻式随机存取存储器(rram)和磁阻式随机存取存储器 (mram)等。
[0003]
存储器还用作广泛范围的电子应用的易失性数据存储区和非易失性数据存储区。非 易失性存储器可以用于例如个人计算机、便携式记忆棒、数字相机、蜂窝电话、如mp3 播放器等便携式音乐播放器、电影播放器和其它电子装置中。可以将存储器单元布置成 阵列,其中所述阵列用于存储器装置中。
技术实现要素:
[0004]
在一方面,本公开涉及一种用于人工智能(ai)操作的调试操作的设备,所述设备包 括:多个存储器阵列;以及控制器,其中所述控制器被配置成使所述设备:对存储在所 述多个存储器阵列中的数据执行人工智能(ai)操作;并且对所述人工智能(ai)操作执行 调试操作。
[0005]
在另一方面,本公开涉及一种用于人工智能(ai)操作的调试操作的设备,所述设备 包括:多个存储器阵列;以及控制器,其中所述控制器被配置成:从主机接收调试命令, 以对在所述设备上执行的人工智能(ai)操作执行调试操作;并且通过使对所述人工智能(ai)操作执行所述调试操作来执行所述调试命令。
[0006]
在另外的方面,本公开涉及一种用于人工智能(ai)操作的调试操作的设备,所述设 备包括:多个存储器阵列;以及控制器,其中所述控制器被配置成使所述设备:通过响 应于从主机接收命令将寄存器中的指示符写入成特定状态来实现对人工智能(ai)操作执 行调试操作。
[0007]
在另外的方面,本公开涉及一种用于人工智能(ai)操作的调试操作的方法,所述方 法包括:对存储在多个存储器阵列中的数据执行人工智能(ai)操作;以及对所述人工智 能(ai)操作执行调试操作。
附图说明
[0008]
图1是根据本公开的多个实施例的呈包含具有人工智能(ai)加速器的存储器装置
的 计算系统的形式的设备的框图。
[0009]
图2是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置上的多个 寄存器的框图。
[0010]
图3a和3b是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置上 的多个寄存器中的多个位的框图。
[0011]
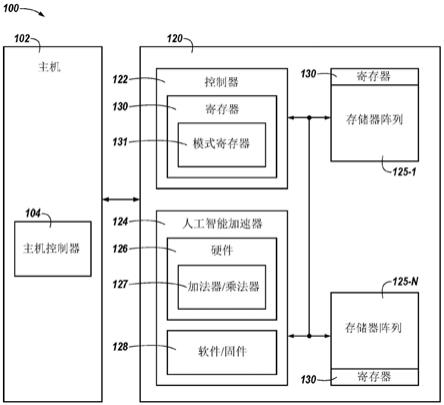
图4是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置的多个块 的框图。
[0012]
图5是展示了根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置中 的示例人工智能过程的流程图。
[0013]
图6a是根据本公开的多个实施例的呈包含具有人工智能(ai)加速器的存储器装置 的计算系统的形式的设备的框图。
[0014]
图6b是根据本公开的多个实施例的呈包含具有人工智能(ai)加速器的存储器装置 的计算系统的形式的设备的框图,所述存储器装置在阵列的存储体部分本地的数据路径 中具有共享输入/输出(i/o)线。
[0015]
图7是展示了根据本公开的多个实施例的存储器装置的读出电路系统的示意图,所 述读出电路系统包含计算组件。
[0016]
图8是展示了根据本公开的多个实施例的用于阵列的数据路径中的多条共享i/o线 的电路系统的示意图。
[0017]
图9a是展示了通过阵列本地的数据路径中的多条共享i/o线耦接到具有多个逻辑 条的计算单元的阵列的多个部分的框图实例。
[0018]
图9b是展示了通过阵列本地的数据路径中的多条共享i/o线耦接到计算单元中的 多个计算组件的多个阵列的框图实例,其中所述计算组件的间距等于共享i/o线的数据 路径的间距,并且所述间距是数位线到阵列的间距的倍数。
具体实施方式
[0019]
本公开包含涉及对人工智能操作执行调试操作的设备和方法。示例设备可以包含多 个存储器阵列和控制器,所述控制器被配置成对存储在所述多个存储器阵列中的数据执 行人工智能(ai)操作并且对ai操作执行调试操作。调试操作可以包含停止ai操作并将 ai操作的错误和调试操作的结果存储在所述多个存储器阵列的临时存储器块中。
[0020]
在一些实例中,控制器的寄存器可以用于执行调试操作。为了开始调试操作,可以 将寄存器的第一位编程为第一状态,并且为了停止和/或防止调试操作,可以将寄存器的 第一位编程为第二状态。例如,控制器可以响应于从主机接收命令将寄存器的一个位和 /或多个位编程为特定状态。控制器的不同的寄存器可以定义调试操作将停止ai操作的 层、改变神经网络的内容、改变偏差值、改变激活函数、观察层的输出、发送层的输出 和/或发送数据。
[0021]
通过停止ai操作并存储ai操作的错误和调试操作的结果来对人工智能操作执行调 试操作可以提高存储器装置的可靠性。例如,存储器装置可以检测和校正错误并基于检 测到并校正的错误来更新输入数据、偏差值、激活函数和/或神经网络,以防止将来的错 误。
[0022]
在本公开的以下详细说明中,参考了附图,附图形成详细说明的一部分,并且在附 图中,通过说明的方式示出了可以如何实践本公开的多个实施例。对这些实施例的描述 的详细程度足以使本领域的普通技术人员能够实践本公开的实施例,并且应当理解的 是,可以利用其它实施例,并且在不背离本公开的范围的情况下,可以作出过程改变、 电气改变和/或结构改变。如本文所使用的,指定符“n”表明多个如此指定的特定特征 可以包含在本公开的多个实施例中。
[0023]
如本文所使用的,“多个”事物可以指此类事物中的一或多个。例如,多个存储器 装置可以指存储器装置中的一或多个存储器装置。另外,如本文中尤其是关于附图中的 附图标记使用的如“n”等指定符表明多个如此指定的特定特征可以包含在本公开的多 个实施例中。
[0024]
本文的附图遵循编号惯例,其中一或多个第一数字与附图编号相对应,并且剩余数 字标识图中的元件或组件。可以通过使用类似的数字来标识不同附图之间类似的元件或 组件。如应理解的,可以添加、交换和/或消除在本文的各个实施例中示出的元件,以提 供本公开的多个另外的实施例。另外,在图中提供的元件的比例和相对尺度旨在展示本 公开的各个实施例,而不旨在以限制性意义使用。
[0025]
图1是根据本公开的多个实施例的呈包含存储器装置120的计算系统100的形式的 设备的框图。如本文所使用的,存储器装置120、存储器阵列125-1、
……
、125-n、存 储器控制器122和/或ai加速器124也可以被分别视为“设备”。
[0026]
如图1所展示的,主机102可以耦接到存储器装置120。主机102可以是膝上型计 算机、个人计算机、数字相机、数字记录和回放装置、移动电话、pda、存储卡读卡器、 接口集线器以及其它主机系统并且可以包含存储器存取装置,例如处理器。本领域的普 通技术人员应理解,“处理器”可以包含一或多个处理器,如并行处理系统、多个协处 理器等。
[0027]
主机102包含用于与存储器装置120通信的主机控制器108。主机控制器108可以 向存储器装置120发送命令。主机控制器108可以与存储器装置120、存储器装置120 上的存储器控制器122和/或存储器装置120上的ai加速器124通信,以执行ai操作、 读取数据、写入数据和/或擦除数据以及其它操作。ai加速器124还可以包含与图6a-9b 相关联地描述的被配置成执行ai操作的组件。ai操作可以包含机器学习或神经网络操 作,所述机器学习或神经网络操作可以包含训练操作或推理操作或两者。在一些实例中, 每个存储器装置120可以表示神经网络或深度神经网络(例如,具有三个或三个以上隐藏 层的网络)内的层。或者每个存储器装置120可以是或包含神经网络的节点,并且神经网 络的层可以由多个存储器装置或若干个存储器装置120的各部分构成。存储器装置120 可以将用于ai操作的权重(或模型)存储在存储器阵列125中。
[0028]
物理主机接口可以提供用于在具有用于物理主机接口的兼容接收器的存储器装置 120与主机102之间传递控制信号、地址信号、数据信号和其它信号的接口。信号可以 例如在如数据总线和/或地址总线等多条总线上在主机102与存储器装置120之间传送。
[0029]
存储器装置120可以包含控制器120、ai加速器124和存储器阵列125-1、
……
、 125-n。存储器装置120可以是如lpddr5装置等低功率双倍数据速率动态随机存取存 储器和/或如gddr6、gddr7、lpddr6、ddr4等图形双倍数据速率动态随机存取存 储器以及其它类型的装置。存储器阵列125-1、
……
、125-n可以包含多个存储器单元, 如易失性存储器单元
(例如,dram存储器单元以及其它类型的易失性存储器单元)和/ 或非易失性存储器单元(例如,rram存储器单元以及其它类型的非易失性存储器单元)。 存储器装置120可以读取数据和/或将数据写入存储器阵列125-1、
……
、125-n。存储器 阵列125-1、
……
、125-n可以存储在存储器装置120上执行的ai操作期间使用的数据。 存储器阵列125-1、
……
、125-n可以存储神经网络的输入、输出、权重矩阵和偏差信息 和/或被ai加速器用来在存储器装置120上执行ai操作的激活函数信息。
[0030]
主机控制器108、存储器控制器122和/或存储器装置120上的ai加速器124可以 包含控制电路系统,例如,硬件、固件和/或软件。在一或多个实施例中,主机控制器 108、控制器存储器122和/或ai加速器124可以是耦接到包含物理接口的印刷电路板的 专用集成电路(asic)。寄存器130可以位于存储器控制器122上、ai加速器124上和/ 或存储器阵列125-1、
……
、125-n中并且可由控制器122存取。而且,存储器装置120 上的存储器控制器122可以包含寄存器130。寄存器130可以被编程成提供信息以供ai 加速器执行ai操作。寄存器130可以包含任何数量的寄存器。寄存器130可以写入主 机102、存储器控制器122和/或ai加速器124和/或由其读取。寄存器130可以为ai 加速器124提供输入、输出偏差、神经网络和/或激活函数信息。寄存器130可以包含用 于选择存储器装置120的操作模式的模式寄存器131。例如,可以通过向寄存器131写 入如0xaa和/或0x2aa等字来选择ai操作模式,这禁止对与存储器装置120的正常操 作相关联的寄存器进行存取并允许对与ai操作相关联的寄存器进行存取。而且,可以 使用签名来选择ai操作模式,所述签名使用通过存储在存储器装置120中的密钥进行 认证的加密算法。
[0031]
ai加速器124可以包含用于执行ai操作的硬件126和/或软件/固件128。而且, ai加速器124还可以包含与图6a-9b相关联地描述的被配置成执行ai操作的组件。硬 件126可以包含用于执行与ai操作相关联的逻辑运算的加法器/乘法器126。存储器控 制器122和/或ai加速器124可以从主机102接收命令以执行ai操作。存储器装置120 可以使用ai加速器124、存储器阵列125-1、
……
、125-n中的数据以及寄存器130中 的信息来执行主机102的命令中请求的ai操作。存储器装置可以向主机120报告回信 息,如例如ai操作的结果和/或错误信息。可以在不使用外部处理资源的情况下执行由 ai加速器124执行的ai操作。
[0032]
存储器阵列125-1、
……
、125-n可以提供存储器系统的主存储器或者可以用作整个 存储器系统的另外的存储器或存储区。每个存储器阵列125-1、
……
、125-n可以包含存 储器单元的多个块。存储器单元的块可以用于存储在存储器装置120执行的ai操作期 间使用的数据。例如,存储器阵列125-1、
……
、125-n可以包含dram存储器单元。 实施例不限于特定类型的存储器装置。例如,存储器装置可以包含ram、rom、dram、 sdram、pcram、rram、3d xpoint和闪存等。
[0033]
举例来说,存储器装置120可以执行是或包含一或多个推理步骤的ai操作。存储 器阵列125可以是神经网络的层或者可以各自是单独的节点,并且存储器装置120可以 是层;或者存储器装置120可以是较大网络内的节点。另外或可替代地,存储器阵列125 可以存储要在节点内使用(例如,求和)的数据或权重或两者。每个节点(例如,存储器阵 列125)可以将来自从相同或不同存储器阵列125的单元读取的数据的输入与从存储器阵 列125的单元读取的权重组合。权重和数据的组合可以例如使用加法器/乘法器127在存 储器阵列125的外围内或在硬件126内求和。在此类情况下,求和的结果可以传递到在 存储器阵列
125的外围或硬件126内表示或实例化的激活函数。结果可以传递到另一个 存储器装置120或者可以在ai加速器124内使用(例如,由软件/固件128)以作出决定或 训练包含存储器装置120的网络。
[0034]
采用存储器装置120的网络可以能够或用于有监督或无监督学习。这可以与其它学 习或训练制度组合。在一些情况下,经过训练的网络或模型导入存储器装置120中或与 其一起使用,并且存储器装置120的操作主要或仅与推理有关。
[0035]
图1的实施例可以包含未展示以免模糊本公开的实施例的另外的电路系统。例如, 存储器装置120可以包含用于锁存通过i/o电路系统利用i/o连接提供的地址信号的地 址电路系统。地址信号可以由行解码器和列解码器接收和解码,以对存储器阵列 125-1、
……
、125-n进行存取。本领域技术人员应理解,地址输入连接的数量可以取决 于存储器阵列125-1、
……
、125-n的密度和架构。
[0036]
图2是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置上的多个 寄存器的框图。寄存器230可以是ai寄存器并且包含输入信息、输出信息、神经网络 信息和/或激活函数信息以及其它类型的信息,以供ai加速器、控制器和/或存储器装置 的存储器阵列(例如,图1中的ai加速器124、存储器控制器122和/或存储器阵列 125-1、
……
、125-n)使用。寄存器可以基于来自主机、ai加速器和/或控制器(例如,图 1中的主机102、ai加速器124、存储器控制器122)的命令而被读取和/或写入。
[0037]
寄存器232-0可以定义与存储器装置的ai模式相关联的参数。寄存器232-0中的位 可以开始ai操作、重新开始ai操作、指示寄存器中的内容有效、清除寄存器中的内容 和/或退出ai模式。
[0038]
寄存器232-1、232-2、232-3、232-4和232-5可以定义ai操作中使用的输入的大小、 ai操作中使用的输入的数量以及ai操作中使用的输入的开始地址和结束地址。寄存器 232-7、232-8、232-9、232-10和232-11可以定义ai操作的输出的大小、ai操作中的输 出的数量以及ai操作的输出的开始地址和结束地址。
[0039]
寄存器232-12可以用于实现使用ai操作期间使用的输入块、神经元块、输出块、 偏差块、激活函数和临时块。
[0040]
寄存器232-13、232-14、232-15、232-16、232-17、232-18、232-19、232-20、232-21、 232-22、232-23、232-24和232-25可以用于定义ai操作期间使用的神经网络。寄存器 232-13、232-14、232-15、232-16、232-17、232-18、232-19、232-20、232-21、232-22、 232-23、232-24和232-25可以定义ai操作期间使用的神经网络的神经元和/或层的大小、 数量和位置。
[0041]
寄存器232-26可以启用ai加速器的调试/保持模式并且使得能够在ai操作的层处 观察输出。例如,控制器可以被配置成对存储在多个存储器阵列中的数据执行ai操作、 停止ai操作并且对ai操作执行调试操作。
[0042]
寄存器232-26可以指示应当在ai操作期间应用激活函数,并且所述ai操作可以 在ai操作中向前进行(例如,执行ai操作中的下一步骤)。控制器可以通过将寄存器 232-26的一个位和/或多个位编程为特定状态来使ai加速器能够对ai操作执行调试操 作。在一些实例中,寄存器232-26的第一位可以被编程为第一状态以开始调试操作并且 可以被编程为第二状态以停止和/或防止调试操作。例如,响应于从主机接收命令,控制 器可以将寄存
序列中存在错误、ai操作算法中存在错误、数据页中存在ecc无法校正的错误和/或数 据页中存在ecc能够校正的错误。
[0052]
寄存器232-47可以指示要在ai操作中使用的激活函数。寄存器232-47可以指示 ai操作中可以使用的多个预定义激活函数之一和/或位于块中的自定义激活函数可以用 于ai操作中。
[0053]
寄存器232-48、232-49和232-50可以指示ai操作正在执行的神经元和/或层。在 ai操作期间发生错误的情况下,寄存器232-48、232-49和232-50可以存储发生错误的 神经元和/或层的位置。
[0054]
图3a和3b是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置上 的多个寄存器中的多个位的框图。每个寄存器332-0、
……
、332-50可以包含多个位, 位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7,以指示与执行ai操作 相关联的信息。所述多个寄存器可以包含8个位,以存储与执行ai操作相关联的信息; 然而,基于包含ai加速器的存储器的大小,所述多个寄存器可以包含任何数量的位。
[0055]
寄存器332-0可以定义与存储器装置的ai模式相关联的参数。寄存器332-0的位 334-5可以是读/写位,并且可以指示尽管可以使用其它编程约定,但是例如当被编程为 1b时的开始阶段,ai操作的详细说明可以重新开始360。一旦ai操作重新开始,寄存 器332-0的位334-5就可以重置为0b。寄存器332-0的位334-4可以是读/写位,并且可 以指示当被编程为1b时,ai操作的详细说明可以重新开始361。一旦ai操作开始,寄 存器332-0的位334-4就可以重置为0b。
[0056]
寄存器332-0的位334-3可以是读/写位,并且可以指示当被编程为1b时,ai寄存 器的内容有效362,并且当被编程为0b时,ai寄存器的内容无效。寄存器332-0的位 334-2可以是读/写位,并且可以指示当被编程为1b时,ai寄存器的内容要被清除363。 寄存器332-0的位334-1可以是只读位,并且可以指示当被编程为1b时,ai加速器正 在使用364并且执行ai操作。寄存器332-0的位334-0可以是只写位,并且可以指示当 被编程为1b时,存储器装置要退出365ai模式。
[0057]
寄存器332-1、332-2、332-3、332-4和332-5可以定义ai操作中使用的输入的大小、 ai操作中使用的输入的数量以及ai操作中使用的输入的开始地址和结束地址。寄存器 332-1和332-2的位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7可以定 义ai操作中使用的输入的大小366。输入的大小可以在位数方面指示输入的宽度和/或 可以指示输入类型,如浮点、整数和/或双精度(double)以及其它类型。寄存器332-3和 332-4的位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7可以指示ai操 作中使用的输入的数量367。寄存器332-5的位334-0、334-1、334-2和334-3可以指示 ai操作中使用的输入的存储器阵列中的块的开始地址368。寄存器332-5的位334-0、 334-1、334-2和334-3可以指示ai操作中使用的输入的存储器阵列中的块的结束地址 369。如果开始地址368和结束地址369是相同的地址,则仅指示一个输入块用于ai操 作。
[0058]
寄存器332-7、332-8、332-9、332-10和332-11可以定义ai操作的输出的大小、 ai操作中的输出的数量以及ai操作的输出的开始地址和结束地址。寄存器332-7和 332-8的位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7可以定义ai操 作中使用的输出的大小370。输出的大小可以在位数方面指示输出的宽度和/或可以指示 输出类型,如浮
点、整数和/或双精度以及其它类型。寄存器332-9和332-10的位334-0、 334-1、334-2、334-3、334-4、334-5、334-6和334-7可以指示ai操作中使用的输出的 数量371。寄存器332-11的位334-4、334-5、334-6和334-7可以指示ai操作中使用的 输出的存储器阵列中的块的开始地址372。寄存器332-11的位334-0、334-1、334-2和 334-3可以指示ai操作中使用的输出的存储器阵列中的块的结束地址373。如果开始地 址372和结束地址373是相同的地址,则仅指示一个输出块用于ai操作。
[0059]
寄存器332-12可以用于实现使用ai操作期间使用的输入块、神经元块、输出块、 偏差块、激活函数和临时块。寄存器332-12的位334-0可以启用输入块380,寄存器332-12 的位334-1可以启用神经网络块379,寄存器332-12的位334-2可以启用输出块378, 寄存器332-12的位334-3可以启用偏差块377,寄存器332-12的位334-4可以启用激活 函数块376,并且寄存器332-12的位334-5和334-6可以启用第一临时块375和第二临 时块374。
[0060]
寄存器332-13、332-14、332-15、332-16、332-17、332-18、332-19、332-20、332-21、 332-22、332-23、332-24和332-25可以用于定义ai操作期间使用的神经网络。寄存器 332-13和332-14的位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7可以 定义ai操作中使用的矩阵中的行数381。寄存器332-15和332-16的位334-0、334-1、 334-2、334-3、334-4、334-5、334-6和334-7可以定义ai操作中使用的矩阵中的列数 382。
[0061]
寄存器332-17和332-18的位334-0、334-1、334-2、334-3、334-4、334-5、334-6 和334-7可以定义ai操作中使用的神经元的大小383。神经元的大小可以在位数方面指 示神经元的宽度和/或可以指示输入类型,如浮点、整数和/或双精度以及其它类型。寄 存器332-19、332-20和322-21的位334-0、334-1、334-2、334-3、334-4、334-5、334-6 和334-7可以指示ai操作中使用的神经网络的神经元的数量384。寄存器332-22的位 334-4、334-5、334-6和334-7可以指示ai操作中使用的神经元的存储器阵列中的块的 开始地址385。寄存器332-5的位334-0、334-1、334-2和334-3可以指示ai操作中使 用的神经元的存储器阵列中的块的结束地址386。如果开始地址385和结束地址386是 相同的地址,则仅指示一个神经元块用于ai操作。寄存器332-23、332-24和322-25的 位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7可以指示ai操作中使用 的神经网络的层数387。
[0062]
寄存器332-26可以启用ai加速器的调试/保持模式并且使得能够在ai操作的层处 观察输出。例如,控制器可以被配置成对存储在多个存储器阵列中的数据执行ai操作、 停止ai操作并且对ai操作执行调试操作。
[0063]
控制器可以通过将寄存器332-26的一个位和/或多个位编程为特定状态来指示ai加 速器处于调试/保持模式。寄存器332-26的位334-0可以指示ai加速器处于调试/保持模 式,并且应当在ai操作期间应用激活函数391。在一些实例中,位334-0可以被编程为 第一状态以开始调试操作并且可以被编程为第二状态以停止和/或防止发生调试操作。例 如,响应于从主机接收命令,控制器可以将位334-0编程为第一状态和/或第二状态。
[0064]
寄存器332-26的位334-1可以指示所述ai操作可以在ai操作中向前进行390(例如, 执行ai操作中的下一步骤)。在一些实例中,位334-1可以被编程为第一状态以指示所 述ai操作可以在ai操作中向前进行390并且可以被编程为第二状态以指示所述ai操 作不能向前进行。可以将位334-1的编程嵌入到ai操作的执行中。可以停止ai操作, 可以观察ai操作的结果,可以校正错误和/或可以将寄存器332-26重新编程成包含另一 个步骤和/或
移除ai操作中的步骤。在一些实例中,在ai操作的特定步骤处的先前内 容可以恢复临时内容,以查看修改对ai操作的影响。
[0065]
寄存器232-26的位334-2和位334-3可以指示层的输出所位于的临时块有效388和 389。例如,寄存器232-26的位334-2和位334-3可以被编程为第一状态以指示临时块 有效388和389并且可以被编程为第二状态以指示临时块无效。在一些实例中,向数据 不应从临时块读取的主机和/或控制器发送信号指示临时块无效。临时块中的数据可以由 主机和/或存储器装置上的控制器改变,使得在ai操作向前进行时,可以在ai操作中 使用改变的数据。
[0066]
调试操作的结果可以被存储和/或传输。例如,调试操作的结果可以存储在所述多个 存储器阵列中的不同块中和/或发送到主机。在一些实例中,位334-4、
……
、334-7中 的一或多个位可以被编程为第一状态以将调试操作的结果发送到主机,并且位 334-4、
……
、334-7中的一或多个位可以被编程为第一状态以将调试操作的结果存储在 所述多个存储器阵列的不同块中。
[0067]
寄存器332-27、332-28和332-29的位334-0、334-1、334-2、334-3、334-4、334-5、 334-6和334-7可以定义调试/保持模式将停止392ai操作的层并观察层的输出。
[0068]
寄存器332-30、332-31、332-32和332-33可以定义ai操作中使用的临时块 的大小以及ai操作中使用的临时块的开始地址和结束地址。寄存器332-30的位 334-4、334-5、334-6和334-7可以定义ai操作中使用的第一临时块的开始地址393。寄存器332-30的位334-0、334-1、334-2和334-3可以定义ai操作中使用 的第一临时块的结束地址394。寄存器332-31和332-32的位334-0、334-1、334-2、 334-3、334-4、334-5、334-6和334-7可以定义ai操作中使用的临时块的大小395。 临时块的大小可以在位数方面指示临时块的宽度和/或可以指示输入类型,如浮 点、整数和/或双精度以及其它类型。寄存器332-33的位334-4、334-5、334-6和 334-7可以定义ai操作中使用的第二临时块的开始地址396。寄存器332-34的位 334-0、334-1、334-2和334-3可以定义ai操作中使用的第二临时块的结束地址 397。
[0069]
寄存器332-34、332-35、332-36、332-37、332-38和332-39可以与ai操作中使用 的激活函数相关联。寄存器332-34的位334-0可以实现使用激活函数3101。寄存器332-34 的位334-1可以实现将ai保持在神经元处3110并且将激活函数用于每个神经元。寄存 器332-34的位334-2可以实现将ai保持在层处399并且将激活函数用于每个层。寄存 器332-34的位334-3可以实现使用外部激活函数398。
[0070]
寄存器332-35的位334-4、334-5、334-6和334-7可以定义ai操作中使用的激活函 数块的开始地址3102。寄存器332-35的位334-0、334-1、334-2和334-3可以定义ai 操作中使用的激活函数块的结束地址3103。寄存器332-36和332-37的位334-0、334-1、 334-2、334-3、334-4、334-5、334-6和334-7可以定义激活函数的输入(例如,x轴)的分 辨率3104。寄存器332-38和332-39的位334-0、334-1、334-2、334-3、334-4、334-5、 334-6和334-7可以针对自定义激活函数的给定x轴值定义激活函数的输出(例如,y轴) 的分辨率3105。
[0071]
寄存器332-40、332-41、332-42、332-43和332-44可以定义ai操作中使用的偏差 值的大小、ai操作中使用的偏差值的数量以及ai操作中使用的偏差值的开始地址和结 束地址。寄存器332-40和332-41的位334-0、334-1、334-2、334-3、334-4、334-5、334-6 和334-7可以定义ai操作中使用的偏差值的大小3106。偏差值的大小可以在位数方面 指示偏差值
的宽度和/或可以指示偏差值类型,如浮点、整数和/或双精度以及其它类型。 寄存器332-42和332-43的位334-0、334-1、334-2、334-3、334-4、334-5、334-6和334-7 可以指示ai操作中使用的偏差值的数量3107。寄存器332-44的位334-4、334-5、334-6 和334-7可以指示ai操作中使用的偏差值的存储器阵列中的块的开始地址3108。寄存 器332-44的位334-0、334-1、334-2和334-3可以指示ai操作中使用的偏差值的存储器 阵列中的块的结束地址3109。如果开始地址3108和结束地址3109是相同的地址,则仅 指示一个偏差值块用于ai操作。
[0072]
寄存器332-45可以为ai计算提供状态信息并为调试/保持模式提供信息。寄存器 332-45的位334-0可以激活调试/保持模式3114。寄存器的位334-1可以指示ai加速器 忙碌3113并且正在执行ai操作。寄存器332-45的位334-2可以指示ai加速器接通3112 和/或应当使用ai加速器的全部能力。寄存器332-45的位334-3可以指示应当仅进行 ai操作的矩阵计算3111。寄存器332-45的位334-4可以指示ai操作可以向前进行3110 并且继续进行到下一个神经元和/或层。
[0073]
寄存器332-46可以提供有关ai操作的错误信息。主机可以在ai操作正在被执行 时检索ai操作信息。寄存器332-46的位334-3可以指示ai操作的序列中存在错误3115。 寄存器332-46的位334-2可以指示ai操作的算法中存在错误3116。寄存器332-46的位 334-1可以指示数据页中存在ecc无法校正的错误3117。寄存器332-46的位334-0可 以指示数据页中存在ecc能够校正的错误3118。
[0074]
寄存器332-47可以指示要在ai操作中使用的激活函数。寄存器332-47的位334-0、 334-1、334-2、334-3、334-4、334-5和334-6可以指示多个预定义激活函数3120之一可 以用于ai操作中。寄存器332-47的位334-7可以指示位于块中的自定义激活函数3119 可以用于ai操作中。
[0075]
寄存器332-48、332-49和332-50可以指示ai操作正在执行的神经元和/或层。寄存 器332-48、332-49和332-50的位334-0、334-1、334-2、334-3、334-4、334-5、334-6 和334-7可以指示ai操作正在执行的神经元和/或层的地址。在ai操作期间发生错误的 情况下,寄存器332-48、332-49和332-50可以指示发生错误的神经元和/或层。
[0076]
图4是根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置的多个块 的框图。输入块440是存储器阵列中的存储输入数据的块。输入块440中的数据可以用 作ai操作的输入。输入块440的地址可以在寄存器5(例如,图2中的寄存器232-5和 图3a中的332-5)中指示。实施例不限于一个输入块,因为可以存在多个输入块。数据 输入块440可以从主机发送到存储器装置。数据可以伴随命令,所述命令指示应当使用 数据在存储器装置上执行ai操作。
[0077]
输出块442是存储器阵列中的存储来自ai操作的输出数据的块。输出块442中的 数据可以用来存储来自ai操作的输出并发送到主机。输出块442的地址可以在寄存器 11(例如,图2中的寄存器232-11和图3a中的332-11)中指示。实施例不限于一个输出 块,因为可以存在多个输出块。
[0078]
可以在完成和/或保持ai操作时将输出块442中的数据发送到主机。临时块444-1 和444-2可以是存储器阵列中的在ai操作正在被执行时临时存储数据的块。尽管图4 包含两个临时块444-1和444-2,但是存储器装置可以包含一或多个临时块。可以在ai 操作通过
用于ai操作的神经网络的神经元和层迭代时将数据存储在临时块444-1和 444-2中。临时块444的地址可以在寄存器30和33(例如,图2中的寄存器232-30和232-33 以及图3b中的332-30和332-33)中指示。实施例不限于两个临时块,因为可以存在多 个临时块。
[0079]
激活函数块446可以是存储在存储用于ai操作的激活函数的存储器阵列中和/或存 储器控制器固件中的块。激活函数块446可以存储由主机和/或ai加速器创建的预定义 激活函数和/或自定义激活函数。激活函数块446的地址可以在寄存器35中(例如,图2 中的寄存器232-35和图3b中的332-35)指示。实施例不限于一个激活函数块,因为可 以存在多个激活函数块。
[0080]
偏差值块448是存储器阵列中的存储用于ai操作的偏差值的块。偏差值块448的 地址可以在寄存器44(例如,图2中的寄存器232-44和图3b中的332-44)中指示。实施 例不限于一个偏差值块,因为可以存在多个偏差值块。
[0081]
神经网络块450-1、450-2、450-3、450-4、450-5、450-6、450-7、450-8、450-9和 450-10是存储器阵列中的存储用于ai操作的神经网络的块。神经网络块450-1、450-2、 450-3、450-4、450-5、450-6、450-7、450-8、450-9和450-10可以存储ai操作中使用 的神经元和层的信息。神经网络块450-1、450-2、450-3、450-4、450-5、450-6、450-7、 450-8、450-9和450-10的地址可以在寄存器22(例如,图2中的寄存器232-22和图3a 中的332-22)中指示。
[0082]
图5是展示了根据本公开的多个实施例的具有人工智能(ai)加速器的存储器装置中 的示例人工智能过程的流程图。响应于开始ai操作,ai加速器可以将输入数据540和 神经网络数据550分别写入输入块和神经网络块中。ai加速器可以使用输入数据540 和神经网络数据550执行ai操作。结果可以存储在临时块544-1和544-2中。临时块 554-1和544-2可以用于在执行矩阵计算、添加偏差数据时存储数据和/或在ai操作期间 应用激活函数。
[0083]
ai加速器可以接收存储在临时块544-1和544-2中的ai操作的部分结果以及偏差 值数据548并使用ai操作的部分结果以及偏差值数据548执行ai操作。结果可以存储 在临时块544-1和544-2中。
[0084]
ai加速器可以接收存储在临时块544-1和544-2中的ai操作的部分结果以及激活 函数数据546并使用ai操作的部分结果以及激活函数数据546执行ai操作。结果可以 存储在输出块542中。
[0085]
控制器可以被配置成对存储在多个存储器阵列中的数据执行ai操作、停止ai操作 并且对ai操作执行调试操作。调试操作552、554、556可以在ai加速器使用输入数据 540和神经网络数据550执行ai操作之后、在使用ai操作的部分结果以及偏差值数据 548执行ai操作之后和/或在使用ai操作的部分结果以及激活函数数据546执行ai操 作之后发生。
[0086]
控制器可以通过将寄存器的一个位和/或多个位编程为特定状态来使设备能够对ai 操作执行调试操作。在一些实例中,寄存器的第一位可以被编程为第一状态以开始调试 操作并且可以被编程为第二状态以停止和/或防止调试操作。例如,响应于从主机接收命 令,控制器可以将寄存器的一个位和/或多个位编程为特定状态。
[0087]
寄存器可以指示所述ai操作可以在ai操作中向前进行(例如,执行ai操作中的下 一步骤)。在一些实例中,第二位可以被编程为第一状态以指示所述ai操作可以在ai 操作中向前进行并且可以被编程为第二状态以指示所述ai操作不能向前进行。
[0088]
寄存器可以指示层的输出所位于的临时块有效。寄存器的第三位和/或第四位可以被 编程为第一状态以指示临时块有效并且可以被编程为第二状态以指示临时块无效。
[0089]
调试操作可以包含将来自ai操作的数据存储在所述多个存储器阵列的临时块中并 验证临时块。临时块中的数据(例如,来自ai操作的部分结果、来自ai操作的错误和/ 或神经网络、激活函数、输入值和/或偏差值)可以由主机和/或存储器装置上的控制器改 变,使得在ai操作向前进行时,改变的数据可以用于ai操作中。
[0090]
调试操作结果也可以存储在临时块544-1和/或544-2中。可以存储和/或传输调试操 作的结果、来自ai操作的部分结果、来自ai操作的错误和/或神经网络、激活函数、 输入值和/或偏差值。例如,调试操作的结果可以存储在所述多个存储器阵列中的输出块 542中和/或发送到主机。寄存器的第五位可以被编程为第一状态以将调试操作的结果发 送到主机,并且第六位可以被编程为第一状态以将调试操作的结果存储在输出块中。
[0091]
图6a是根据本公开的多个实施例的呈包含具有人工智能(ai)加速器的存储器装置 620的计算系统600的形式的设备的框图,所述存储器装置包含存储器阵列625。如本 文所使用的,存储器装置620、控制器640、存储器阵列625、读出电路系统6138和/ 或多个另外的锁存器6140也可以被分别视为“设备”。
[0092]
在图6a中,ai加速器(例如,图1中的ai加速器124)可以包含被配置成执行如逻 辑运算等与ai操作相关联的操作的读出电路系统6138和另外的锁存器6140以及与图 6a-9b相关联地描述的其它组件。如下文与图6a-9b相关联地描述的,存储器装置(例 如,存储器装置620)可以被配置成执行与的ai操作相关联的操作作为ai加速器的一部 分。
[0093]
如本文所使用的,另外的锁存器旨在指另外的功能(例如,放大器、选择逻),所述 功能读出、耦接和/或移动(例如,读取、存储、缓存)阵列中的存储器单元的数据值并且 不同于图6b、7、8、9a和9b所示出的所述多条共享i/o线6144的数据路径中的计算 单元中的所述多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、6152-n。 如图6a和6b所示出的,阵列本地的多条共享输入/输出(i/o)线6144的数据路径中的逻 辑条6152-1、
……
、6152-n可以与存储体6146-1中的存储器单元的各个存储体部分 6150-1、
……
、6150-n相关联。存储体6146-1可以是存储器装置620上的多个存储体 之一。
[0094]
图6a中的系统600包含耦接(例如,连接)到存储器装置620的主机602。主机602 可以是主机系统,如个人膝上型计算机、台式计算机、数字相机、智能电话或存储卡读 卡器以及各种其它类型的主机。主机602可以包含系统主板和/或背板并且可以包含多个 处理资源(例如,一或多个处理器、微处理器或其它某种类型的控制电路系统)。系统600 可以包含单独的集成电路,或者主机602和存储器装置620两者均可以在同一集成电路 上。系统600可以是例如服务器系统和/或高性能计算(hpc)系统和/或其一部分。尽管图 6a中示出的实例展示了具有冯
·
诺依曼(von neumann)架构的系统,但是本公开的实施例 可以在非冯
·
诺依曼架构上实施,所述非冯
·
诺依曼架构可以不包含通常与冯
·
诺依曼架构 相关联的一或多个组件(例如,cpu、alu等)。
[0095]
为了清楚起见,系统600已经简化为集中于与本公开特别相关的特征。存储器阵列 625可以是dram阵列、sram阵列、stt ram阵列、pcram阵列、tram阵列、 rram阵列、与非闪存阵列和/或或非闪存阵列以及其它类型的阵列。阵列625可以包 含存储器单元,所述存储单元被布置成由存取线(所述存取线在本文可被称为字线或选择 线)耦接的行和由读出线
(所述读出线在本文可以被称为数据线或数位线)耦接的列。尽管 在图6a中示出了单个阵列625,但是实施例不限于此。例如,存储器装置620可以包 含多个阵列625(例如,dram单元、与非闪存单元等的多个存储体)。
[0096]
存储器装置620可以包含地址电路系统6525,以锁存由i/o电路系统6134通过数 据总线656(例如,连接到主机602的i/o总线)提供(例如,通过局部i/o线和全局i/o线 提供到外部alu电路系统和/或dram dq)的地址信号。如本文所使用的,dram dq 可以实现通过总线(例如,数据总线656)向存储体输入数据和/或从存储体输出数据(例 如,从控制器640和/或主机602输出和/或向其输入)。在写入操作期间,可以将电压(高 =1,低=0)施加到dq(例如,引脚)。此电压可以转化为适当的信号并存储在所选的存储 器单元中。在读取操作期间,一旦存取完成并且启用了输出(例如,通过为低的输出启用 信号),则从所选的存储器单元读取的数据值可以出现在dq处。在其它时间,dq可以 处于高阻抗状态,使得dq不会拉出或灌入电流并且不会向系统呈现信号。如本文所描 述的,当两个或两个以上装置(例如,存储体)共享组合的数据总线时,这还可以减少dq 争用。此类dq是单独的并且不同于阵列625本地的数据路径中的所述多条共享i/o线 6144(图6b中)。
[0097]
例如,可以通过带外(oob)总线657例如高速接口(hsi)从存储器装置620的控制器 640向信道控制器604提供状态和异常信息,这进而可以从信道控制器604向主机602 提供。信道控制器604可以包含逻辑组件,以在每个相应存储体的阵列中分配多个位置 (例如,用于子阵列的控制器)以存储与多个存储器装置620中的每个存储器装置的操作 相关联的各个存储体的存储体命令、应用指令(例如,用于操作序列)和自变量(pim(在存 储器中处理(processing in memory))命令)。信道控制器604可以向所述多个存储器装置 620分派命令(例如,pim命令),以将那些程序指令存储在存储器装置620的给定存储 体6146(图6b)内。
[0098]
地址信号通过地址电路系统6525接收并且由行解码器6132和列解码器6142解码, 以对存储器阵列625进行存取。通过使用读出电路系统6138的如本文所描述的多个读 出放大器来读出读出线(数位线)上的电压和/或电流变化,可以从存储器阵列625读出(读 取)数据。读出放大器可以读取和锁存来自存储器阵列625的数据页(例如,行)。如本文 所描述的,另外的计算电路系统可以耦接到读出电路系统6138并且可以与读出放大器 组合使用以读出、存储(例如,缓存和/或缓冲)、执行计算功能(例如,运算)和/或移动数 据。i/o电路系统6134可以用于通过数据总线656(例如,64位宽的数据总线)与主机602 进行双向数据通信。写入电路系统6136可以用于将数据写入存储器阵列625中。
[0099]
控制器640(例如,图6a中示出的存储体控制逻辑、定序器和定时电路系统)可以对 控制总线654从主机602提供的信号(例如,命令)进行解码。这些信号可以包含可以用 于控制在存储器阵列625上执行的操作的芯片启用信号、写入启用信号和/或地址锁存信 号,所述操作包含数据读出、数据存储、数据移动(例如,复制、传送和/或传输数据值)、 数据写入和/或数据擦除操作以及其它操作。在各个实施例中,控制器640可以负责执行 来自主机602的指令并对存储器阵列625进行存取。控制器640可以是状态机、定序器 或其它某种类型的控制器。控制器640可以控制在阵列(例如,存储器阵列625)的行中 将数据移位(例如,右或左)并且执行微代码指令以执行如计算操作等操作,例如,与、 或、或非、异或、加、减、乘、除等。
[0100]
读出电路系统6138的实例在下文进一步描述(例如,在图6a-9b中)。例如,在一 些实施例中,读出电路系统6138可以包含多个读出放大器和多个计算组件,所述多个 读出放大器和多个计算组件可以用作累加器并且可以用于在每个子阵列中(例如,对与互 补读出线相关联的数据)执行操作。
[0101]
在一些实施例中,读出电路系统6138可以用于使用存储在存储器阵列625中的数 据作为输入来执行操作并且参与用于复制、传送、传输、写入、逻辑和/或存储操作的数 据到存储器阵列625中的不同位置的移动,而无需通过读出线地址存取来传送数据(例 如,无需激发列解码信号)。这样,各种计算功能可以使用读出电路系统6138并在所述 读出电路内执行,而不是通过读出电路系统6138外部的处理资源(例如,通过与主机602 和/或位于装置620上如控制器640上或其它地方的其它处理电路系统如alu电路系统 相关联的处理器)来执行(或与其相关联)。然而,另外,根据本公开的实施例对从阵列的 行移动到计算单元中的多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、 6152-n的数据值执行计算功能。此外,作为实例,根据实施例,与激发阵列中的行所需 的示例时间60纳秒(ns)相比,可以在计算单元中以2纳秒(ns)的速度控制计算操作,而 无需将数据值移回行中。
[0102]
在各种先前的方法中,与操作数相关联的数据例如将会通过读出电路系统从存储器 中读取并通过i/o线(例如,通过局部i/o线和/或全局i/o线)提供到外部alu电路系统。 外部alu电路系统可以包含多个寄存器并且将会使用操作数执行计算功能,并且结果 将会通过i/o电路系统6134传送回阵列。
[0103]
相比之下,根据本公开的实施例对通过多条共享i/o线6144从阵列的行移动到阵列 本地的数据路径中的计算单元中的多个计算组件6148-1、
……
、6148-m和/或逻辑条 6152-1、
……
、6152-n的数据值执行计算功能。另外,读出电路系统6138可以被配置 成对存储在存储器阵列625中的数据执行操作并且将结果存储回存储器阵列625,而无 需启用耦接到读出电路系统6138的i/o线(例如,局部i/o线)。然而,一旦加载,与激 发阵列中的行所需的示例时间例如60纳秒(ns)相比,可以在计算单元中更快地,例如以 2纳秒(ns)的速度控制计算操作,而无需将数据值移回行中。读出电路系统6138可以形 成为与阵列的存储器单元成一定间距。与所述多条共享i/o线6144的数据路径相关联的 所述多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、6152-n的间距等 于数据路径的间距并且是数位线到存储器单元阵列的间距的函数。例如,计算组件的间 距是数位线到存储器单元阵列的间距的整数倍。
[0104]
例如,本文所描述的读出电路系统6138可以以与一对互补读出线(例如,数位线) 相同的间距形成。例如,一对互补存储器单元可以具有6f2间距的单元大小(例如,3f
×ꢀ
2f),其中f是特征大小。如果互补存储器单元的一对互补读出线的间距为3f,则具有 一定间距的读出电路系统指示读出电路系统(例如,每一相应对的互补读出线的读出放大 器和对应的计算组件)被形成为配合在互补读出线的3f间距内。同样,与所述多条共享 i/o线6144的数据路径相关联的计算组件6148-1、
……
、6148-m和/或逻辑条 6152-1、
……
、6152-n的间距是互补读出线的3f间距的函数。例如,计算组件 6148-1、
……
、6148-m和/或逻辑6152-1、
……
、6152-n的间距将是数位线到存储器单 元阵列的3f间距的整数倍。
[0105]
相比之下,各种现有系统的一或多个处理资源(例如,计算引擎,如alu)的电路系 统可能不符合与存储器阵列相关联的间距规则。例如,存储器阵列的存储器单元可以具 有
4f2或6f2单元大小。这样,与先前系统的alu电路系统相关联的装置(例如,逻辑 门)可能无法形成为与存储器单元成一定间距(例如,与读出线相同的间距),这可以影响 例如芯片大小和/或存储器密度。如本文所描述的,在一些计算系统和子系统(例如,中 央处理单元(cpu))的上下文中,可以在与存储器(例如,阵列中的存储器单元)没有间距 和/或在芯片上的位置处理数据。例如,数据可以由例如与主机相关联而不是与存储器成 一定间距的处理资源来处理。
[0106]
这样,在多个实施例中,不需要阵列625和读出电路系统6138外部的电路系统来 执行计算功能,因为读出电路系统6138可以执行适当的操作来执行此类计算功能或者 可以在阵列本地的多条共享i/o线的数据路径中执行此类操作,而无需使用外部处理资 源。因此,读出电路系统6138和/或所述多条共享i/o线6144的数据路径中的计算单元 中的所述多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、6152-n可以 用于至少在某种程度上补充或替换此类外部处理资源(或至少此类外部处理资源的带宽 消耗)。在一些实施例中,读出电路系统6138和/或所述多条共享i/o线6144的数据路 径中的计算单元中的所述多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、 6152-n可以用于执行除了由外部处理资源(例如,主机602)执行的操作之外的操作(例如, 以执行指令)。例如,主机602和/或读出电路系统6138可以被限制为仅执行某些操作和 /或一定数量的操作。
[0107]
本文所描述的操作可以包含与有在存储器中处理(pim)能力的装置相关联的操作。 有pim能力的装置操作可以使用基于位向量的操作。如本文所使用的,术语“位向量
”ꢀ
旨在意指在物理上连续存储在存储器单元阵列的行中的位向量存储器装置(例如,pim装 置)上的物理上连续数量的位。因此,如本文所使用的,“位向量操作”旨在意指对是虚 拟地址空间(例如,由pim装置使用)的连续部分的位向量执行的操作。例如,pim装置 中的虚拟地址空间的行可以具有16k位的位长(例如,对应于dram配置中的16k个互 补存储器单元对)。如本文针对此类16k位行所描述的读出电路系统6138可以包含形成 为与选择性地耦接到16位行中的对应存储器单元的读出线成一定间距的对应的16k个 处理元件(例如,如本文所描述的计算组件)。pim装置中的计算组件可以作为一位处理 元件(pe)对由读出电路系统6138读出(例如,由与如本文所描述的计算组件配对的读出 放大器读出和/或存储在所述读出放大器中)的存储器单元的行的位向量的单个位进行操 作。类似地,所述多条共享i/o线6144的数据路径中的计算单元中的所述多个计算组件 6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、6152-n可以作为一位处理元件(pe) 对在阵列中读出的存储器单元的行的位向量的单个位进行操作。
[0108]
启用i/o线可以包含启用(例如,导通、激活)具有耦接到解码信号(例如,列解码信 号)的栅极和耦接到i/o线的源极/漏极的晶体管。然而,实施例不限于启用i/o线。例如, 在多个实施例中,读出电路系统(例如,6138)可以用于执行操作而无需启用阵列的列解 码线。
[0109]
然而,可以启用所述多条共享i/o线6144,以便将数据值加载到所述多条共享i/o 线6144的数据路径中的计算单元中的所述多个计算组件6148-1、
……
、6148-m和/或逻 辑条6152-1、
……
、6152-n,在所述计算单元中,可以更快地控制计算操作。例如,在 计算单元中的所述多个计算组件6148-1、
……
、6148-m和/或逻辑条6152-1、
……
、6152-n 中,可以以
极区域可以耦接到数位线7168-1(d),晶体管7160-1的第二源极/漏极区域可以耦接到电 容器7162-1并且晶体管7160-1的栅极可以耦接到字线7164-y。晶体管7160-2的第一源 极/漏极区域可以耦接到数位线7168-2(d)_,晶体管7160-2的第二源极/漏极区域可以耦 接到电容器7162-2,并且晶体管7160-2的栅极可以耦接到字线7164-x。如图7所示出 的,单元板可以耦接到电容器7162-1和7162-2中的每个电容器。单元板可以是在各种 存储器阵列配置中可以被施加参考电压(例如,接地)的公共节点。
[0117]
根据本公开的多个实施例,存储器阵列725被配置成耦接到读出电路系统7138。在 本实施例中,读出电路系统7138包括读出放大器7170和对应于相应列的存储器单元的 计算组件7148(例如,耦接到相应对的互补数位线)。读出放大器7170可以耦接到一对 互补数位线7168-1和7168-2。计算组件7148可以通过传输门7172-1和7172-2耦接到 读出放大器7170。传输门7172-1和7172-2的门可以耦接到操作选择逻辑7178。
[0118]
操作选择逻辑7178可以被配置成包含传输门逻辑和交换门逻辑,所述传输门逻辑 用于控制耦接读出放大器7170与计算组件7148之间未转置的一对互补数位线的传输 门,所述交换门逻辑用于控制耦接读出放大器7170与计算组件7148之间转置的一对互 补数位线的交换门。操作选择逻辑7178也可以耦接到所述一对互补数位线7168-1和 7168-2。操作选择逻辑7178可以被配置成基于所选操作控制传输门7172-1和7172-2的 连续性。
[0119]
读出放大器7170可以被操作以确定存储在所选存储器单元中的数据值(例如,逻辑 状态)。读出放大器7170可以包括交叉耦接锁存器,所述交叉耦接锁存器在本文中可以 被称为主锁存器。在图7所展示的实例中,对应于读出放大器7170的电路系统包括锁 存器7175,所述锁存器包含耦接到一对互补数位线d 7168-1和(d)_7168-2的四个晶体 管。然而,实施例不限于本实例。锁存器7175可以是交叉耦接锁存器(例如,一对晶体 管的栅极如n沟道晶体管(例如,nmos晶体管)7182-1和7182-2与另一对晶体管如p沟 道晶体管(例如,pmos晶体管)7184-1和7184-2交叉耦接)。包括晶体管7182-1、7182-2、 7184-1和7184-2的交叉耦接锁存器7175可以被称为主锁存器。
[0120]
在操作中,当正在读出(例如,读取)存储器单元时,数位线7168-1(d)或7168-2(d)_ 中的一条数位线上的电压将略大于数位线7168-1(d)或7168-2(d)_中的另一条数位线上 的电压。可以将act信号和rnl*信号驱动为低以启用(例如,激发)读出放大器7170。 具有较低电压的数位线7168-1(d)或7168-2(d)_将使pmos晶体管7184-1或7184-2中 的一个导通的程度大于pmos晶体管7184-1或7184-2中的另一个,从而将具有较高电 压的数位线7168-1(d)或7168-2(d)_驱动为高到大于另一条数位线7168-1(d)或7168-2 (d)_被驱动为高的程度。
[0121]
类似地,具有较高电压的数位线7168-1(d)或7168-2(d)_将使nmos晶体管7182-1 或7182-2中的一个导通的程度大于nmos晶体管7182-1或7182-2中的另一个,从而将 具有较低电压的数位线7168-1(d)或7168-2(d)_驱动为低到大于另一条数位线7168-1 (d)或7168-2(d)_被驱动为低的程度。结果,在短暂的延迟之后,具有略大的电压的数 位线7168-1(d)或7168-2(d)_通过拉出晶体管被驱动到供应电压v
cc
的电压,并且另一 条数位线7168-1(d)或7168-2(d)_通过灌入晶体管被驱动到参考电压(例如,接地)的电 压。因此,交叉耦接的nmos晶体管7182-1和7182-2以及pmos晶体管7184-1和7184-2 用作读出放大器对,所述读出放大器对放大了数位线7168-1(d)和7168-2(d)_上的差分 电压并且操作以锁存从
节点7177-1和/或7177-2上的所选存储器单元读出的数据值。
[0122]
实施例不限于图7中展示的读出放大器7170配置。作为实例,读出放大器7170可 以是电流模式读出放大器和单端读出放大器(例如,耦接到一条数位线的读出放大器)。 而且,本公开的实施例不限于如图7所示出的折叠数位线架构等折叠数位线架构。
[0123]
读出放大器7170可以结合计算组件7148被操作以使用来自阵列的数据作为输入来 执行各种操作。在多个实施例中,可以将操作的结果存储回阵列,而无需通过数位线地 址存取来传送数据(例如,无需激发列解码信号,使得通过局部i/o线将数据传送到阵列 和读出电路系统外部的电路系统)。这样,本公开的多个实施例可以实现使用比各种先前 方法更少的功率来执行操作和与其相关联的计算功能。另外,由于多个实施例消除了在 局部和全局i/o线上传送数据以执行计算功能(例如,在存储器与离散处理器之间)的需 要,因此与先前的方法相比,多个实施例可以实现增加的(例如,更快的)处理能力。
[0124]
读出放大器7170可以进一步包含平衡电路系统7174,所述平衡电路系统可以被配 置成平衡数位线7168-1(d)和6768-2(d)_。在本实例中,平衡电路系统7174包括耦接 在数位线7168-1(d)与7168-2(d)_之间的晶体管7188。平衡电路系统7174还包括晶体 管7180-1和7180-2,所述晶体管各自具有耦接到平衡电压(例如,v
dd
/2)的第一源极/漏 极区域,其中v
dd
是与阵列相关联的供应电压。晶体管7180-1的第二源极/漏极区域可 以是耦接的数位线7168-1(d),并且晶体管7180-2的第二源极/漏极区域可以是耦接的数 位线7168-2(d)_。晶体管7188、7180-1和7180-2的栅极可以耦接在一起并且耦接到平 衡(eq)控制信号线7186。这样,激活eq启用了晶体管7188、7180-1和7180-2,这有 效地将数位线7168-1(d)和7168-2(d)_短接在一起并且短接到平衡电压(例如,v
cc
/2)。
[0125]
尽管图7示出了读出放大器7170包括平衡电路系统7174,但是实施例不限于此, 并且平衡电路系统7174可以与读出放大器7170分离地实施、以与图7所示出的配置不 同的配置实施或者根本不实施。
[0126]
如下文进一步描述的,在多个实施例中,读出电路系统7138(例如,读出放大器7170 和计算组件7148)可以被操作以执行所选操作并且最初将结果存储在读出放大器7170或 计算组件7148之一中,而无需通过局部或全局i/o线从读出电路系统传送数据(例如, 无需通过激活例如列解码信号来执行读出线地址存取)。
[0127]
然而,进一步地,对于本文所描述的实施例,具有读出放大器并且在一些实施例中 还可以包含如图9a和9b所示出的计算组件的读出电路系统7138还可以将来自阵列中 的存储器单元的多路复用列的存储器单元耦接到如结合图9a和9b所讨论的阵列本地的 所述多条共享i/o线9144的数据路径中的计算单元9198中的计算组件9148-1、
……
、 9148-m和/或逻辑条9152-1、
……
、9152-n。以此方式,计算组件9148-1、
……
、9148-m 和/或逻辑条9152-1、
……
、9152-n可以经由选择逻辑(结合图9a和9b所讨论的)通过 所述多条共享i/o线9144间接地耦接到一列存储器单元。
[0128]
操作(例如,涉及数据值的布尔(boolean)逻辑运算)的执行是基本且常用的。布尔逻 辑运算用于许多更高级操作中。因此,可以通过改进的操作实现的速度和/或功率效率可 以转化为更高阶功能的速度和/或功率效率。
[0129]
如图7所示出的,计算组件7148还可以包括锁存器,所述锁存器在本文可以被称 为辅助锁存器7190。辅助锁存器7190可以以与上文关于主锁存器7175所描述的方式类 似
的方式配置和操作,除了包含在辅助锁存器中的一对交叉耦接的p沟道晶体管(例如, pmos晶体管)可以使其各自的源极耦接到供应电压7176-2(例如,v
dd
),并且辅助锁存 器的一对交叉耦接的n沟道晶体管(例如,nmos晶体管)可以使其各自的源极选择性耦 接到参考电压7176-1(例如,接地),使得辅助锁存器被连续启用。计算组件748的配准 不限于图7所示出的配置,并且各种其它实施例是可行的。
[0130]
如本文所描述的,存储器装置(例如,图6a中的620)可以被配置成通过数据总线(例 如,656)和控制总线(例如,654)耦接到主机(例如,602)。存储器装置620中的存储体 6146可以包含存储器单元的多个存储体部分(图6中的6150-1、
……
、6150-n)。存储体 6146可以包含通过存储器单元的多列(图8)耦接到多个阵列的读出电路系统(例如,图6a 中的6138以及图7和图8中的对应附图标记)。读出电路系统可以包含耦接到所述列中 的每列的读出放大器和计算组件(例如,图7中分别为7170和7148)。
[0131]
每个存储体部分6150可以与阵列725本地的多条共享i/o线(图6b中的6144)的数 据路径中的计算单元中的多个逻辑条(例如,图6b中的6152-0、6152-1、
……
、6152-n-1) 相关联。耦接到存储体的控制器(例如,图6a-6b中的640)可以被配置成如本文所描述 的引导数据值移动到阵列本地的共享i/o线8144/9144(图8和9a)的数据路径中的计算 单元8198/9198(图8和9a-9b)中的逻辑条9152(图9a)中的计算组件9148(图9a)。
[0132]
存储器装置可以包含逻辑条(例如,图6b中的6152和图9a中的9152),所述逻辑 条具有可以对应于存储器单元的多列(图6b)中的多个计算组件(例如,图9a中分别为9148-1、
……
、9148-z)。如结合图7进一步讨论的,读出电路系统7138中的多个读出 放大器7170和/或计算组件7148可以选择性地耦接(例如,通过图8中的列选择电路系 统8194-1和8194-2)到多条共享i/o线8144(图8)。列选择电路系统可以被配置成通过选 择性地耦接到多个(例如,四个、八个和十六个以及其它可能性)读出放大器和/或计算组 件来选择性地读出阵列的存储器单元的特定列中的数据。
[0133]
在一些实施例中,存储体中多个逻辑条(例如,图6b中的6152-1、
……
、6152-n) 可以对应于图6b中的多个存储体部分6150-1、
……
、6150-n(例如,具有多个子阵列的 象限)。逻辑条可以包含阵列725本地的共享i/o线9144(图9a)的数据路径中的类似于 图7所示出的计算组件7148的多个计算组件9148-1、
……
、9148-z(图9a)。如将在图8 示出的,从阵列的行读出的数据值可以通过列选择逻辑经由多条共享i/o线8144(图8) 并行移动到所述多条共享i/o线8144(图8)的数据路径中的计算单元8198(图8)中的多个 计算组件9148(图9a)。在一些实施例中,数据量可以对应于所述多条共享i/o线的至少 一千位宽度。
[0134]
如本文所描述的,存储器单元阵列可以包含dram存储器单元的实施方案,其中 控制器被配置成响应于命令通过共享i/o线将数据从源位置移动(例如,复制、传送和/ 或传输)到目的地位置。在各个实施例中,源位置可以在第一存储体中,并且目的地位置 可以是在阵列725本地的共享i/o线8144(图8)的数据路径中的计算单元8198(图8)中。
[0135]
如图8所描述的,设备可以被配置成将数据从源位置(包含与第一数量的读出放大器 和计算组件相关联的特定行(例如,图8中的819)和列地址)移动(例如,复制、传送和/ 或传输)到共享i/o线(例如,图8中的8144)。另外,设备可以被配置成将数据移动到目 的地位置,所述目的地位置包含与共享i/o线9144(图9a)的数据路径中的计算单元 9198(图9b)相关联的特定逻辑条952(图9a)。如读者将理解的,每条共享i/o线8144(图 8)可以实际上
包含互补的共享i/o线对(例如,图8中的共享i/o线和共享i/o线*)。在 本文所描述的一些实施例中,可以将2048条共享i/o线(例如,互补对共享i/o线)配置 为2048位宽的共享i/o线。在本文所描述的一些实施例中,可以将1024条共享i/o线(例 如,互补对共享i/o线)配置为1024位宽的共享i/o线。
[0136]
图8是展示了根据本公开的多个实施例的用于存储器装置中的数据移动的电路系统 的示意图。图8示出了八个读出放大器(例如,分别为8170-0、8170-1、
……
、8170-7 处的读出放大器0、1、
……
、7),所述读出放大器各自耦接到相应的一对互补共享i/o 线8144(例如,共享i/o线和共享i/o线*)。图8还示出了八个计算组件(例如,8148-0、 8148-1、
……
、8148-7处的计算组件0、1、
……
、7),所述计算组件各自通过相应的传 输门8172-1和8172-2以及数位线8168-1和8168-2耦接到相应的读出放大器(例如,如 针对8170-0处读出放大器0所示出的)。例如,传输门可以如图2所示出的进行连接并 且可以通过操作选择信号pass进行控制。例如,选择逻辑的输出可以耦接到传输门 8172-1和8172-2的门以及数位线8168-1和8168-2。对应的读出放大器和计算组件对可 以有助于形成8138-0、8138-1、
……
、8138-7处指示的读出电路系统。
[0137]
如结合图7所描述的,可以将一对互补数位线8168-1和8168-2上存在的数据值加 载到计算组件8148-0中。例如,当启用传输门8172-1和8172-2时,可以将一对互补数 位线8168-1和8168-2上的数据值从读出放大器传递到计算组件(例如,8170-0到8148-0)。 所述一对互补数位线对8168-1和8168-2上的数据值可以是当读出放大器8170-0被激发 时存储在读出放大器中的数据值。
[0138]
图8中的读出放大器8170-0、8170-1、
……
、8170-7可以各自对应于图7中示出的 读出放大器7170。图8中示出的计算组件8148-0、8148-1、
……
、8148-7可以各自对应 于图7中示出的计算组件7148。一个读出放大器与一个计算组件的组合可以有助于耦接 到共享i/o线8144的dram存储器子阵列8145的一部分的读出电路系统(例如,8138-0、 8138-1、
……
、8138-7),所述共享i/o线由共享i/o线8144的数据路径中的多个逻辑条 共享。
[0139]
图8所展示的实施例的配置是出于清楚的目的示出的,但是不限于这些配置。例如, 针对读出放大器8170-0、8170-1、
……
、8170-7结合计算组件8148-0、8148-1、
……
、 8148-7和共享i/o线8144在图8中展示的配置不限于读出电路系统的读出放大器 8170-0、8170-1、
……
、8170-7与计算组件8148-0、8148-1、
……
、8148-7的组合的一 半形成在存储器单元(未示出)的列8192上方并且一半形成在存储器单元的列8192下方。 形成被配置成耦接到共享i/o线的读出电路系统的读出放大器与计算组件的此类组合的 数量也不限于八个。另外,共享i/o线8144的配置不限于被分成两个以用于分别耦接两 组互补数位线8168-1和8168-2中的每组数位线,共享i/o线8144的定位也不限于在形 成读出电路系统的读出放大器与计算组件的组合的中间(例如,而不是在读出放大器与计 算组件的组合的任一端处)。
[0140]
图8所展示的电路系统还示出了列选择电路系统8194-1和8194-2,所述列选择电 路系统被配置成相对于子阵列8145的特定列8192、与其相关联的互补数位线8168-1和 8168-2以及共享i/o线8144实施数据移动操作(例如,如图6a-6b所示出的控制器640 所引导的)。例如,列选择电路系统8194-1具有被配置成与如列0(332-0)、列2、列4和 列6等对应列耦接的选择线0、2、4和6。列选择电路系统8194-2具有被配置成与如列1、列3、列5和列7等
对应列耦接的选择线1、3、5和7。在各个实施例中,结合图3 描述的列选择电路系统8194可以表示由多路复用器实现并包含在其中的功能的至少一 部分,所述多路复用器例如八(8)路多路复用器、十六(16)路多路复用器等。
[0141]
控制器840可以耦接到列选择电路系统8194,以控制选择线(例如,选择线0)对存 储在读出放大器、计算组件中和/或存在于一对互补数位线(例如,通过来自选择线0的 信号激活选择晶体管8196-1和8196-2时,为8168-1和8168-2)上的数据值进行存取。 激活选择晶体管8196-1和8196-2(例如,如由控制器540引导的)实现了耦接读出放大器 8170-0、计算组件8148-0和/或列0(8192-0)的互补数位线8168-1和8168-2,以将数位线 0和数位线0*上的数据值移动到共享i/o线8144。例如,移动的数据值可以是存储(缓 存)在读出放大器8170-0和/或计算组件8148-0中的来自特定行819的数据值。可以通过 控制器激活适当的选择晶体管来类似地选择来自列0到列7中的每列的数据值。
[0142]
此外,启用(例如,激活)选择晶体管(例如,选择晶体管8196-1和8196-2)可以使特 定读出放大器和/或计算组件(例如,分别为8170-0和/或8148-0)能够与共享i/o线8144 耦接,使得可以将放大器和/或计算组件所存储的数据值移动到(例如,置于其上和/或传 送到)共享i/o线8144。在一些实施例中,一次选择一列(例如,列8192-0)耦接到特定共 享i/o线8144,以移动(例如,复制、传送和/或传输)所存储的数据值。在图8的示例配 置中,共享i/o线8144被展示为共享差分i/o线对(例如,共享i/o线和共享i/o线*)。 因此,列0(8192-0)的选择可以产生来自行(例如,行819)和/或如存储在与互补数位线 8168-1和8168-2相关联的读出放大器和/或计算组件中的两个数据值(例如,值为0和/ 或1的两位)。这些数据值可以与共享差分i/o线8144的每个共享差分i/o对(例如,共 享i/o和共享i/o*)并行输入。
[0143]
图9a是展示了通过阵列925本地的数据路径中的多条共享i/o线9144耦接到具有 多个逻辑条9152-1、
……
、9152-n的计算单元9198的阵列925的多个部分9150的框图。 在图9a的示例实施例中,示出了具有多个子阵列9145-1、
……
、9145-32的存储体部分 9150(例如,存储体象限)。在图9a中,在存储体象限9150中展示了三十二(32)个子阵 列。然而,实施例不限于本实例。本实例示出了具有被十六(16)路多路复用器多路复用 到共享i/o线9144的16k列的存储体部分。因此,将16k列多路复用到1k条共享i/o 线9144,使得每16列可以提供可以作为一组1024(1k)位并行移动到计算单元9198的 数据值。此处,共享i/o线9144为计算单元9198提供1k位宽的数据路径。
[0144]
在图9a的实例中,每个逻辑条9152-1、
……
、9152-n具有多个计算组件 9148-1、
……
、9148-z,所述多个计算组件与本文结合图7的读出电路系统7138所描述 的相同。在一些实施例中,所述多个逻辑条9152-1、
……
、9152-n中的每个逻辑条被配 置成使用所述多个计算组件9148-1、
……
、9148-z来执行计算功能。在一些实施例中, 所述多个逻辑条9152-1、
……
、9152-z中的每个逻辑条可以使用所述多个计算组件 9148-1、
……
、9148-z来执行不同的逻辑运算。例如,在一些实施例中,所述多个逻辑 条9152-1、
……
、9152-z中的至少一个逻辑条可以被配置成执行长移位加速器操作,例 如,八(8)或六十四(64)位桶式移位器操作。本实例还可以提供八(8)位数据块(chunk)中的 部分重新排序并且可以支持具有8位交叉条的256位数据块中的聚集/分散操作。在另一 个实例中,在一些实施例中,所述多个逻辑条9152-1、
……
、9152-z中的至少一个逻辑 条可以被配置成执行kogge-stone
加速以生成部分先行进位以加速水平加法。在另一个 实例中,在一些实施例中,所述多个逻辑条9152-1、
……
、9152-z中的至少一个逻辑条 可以被配置成执行“数据块”数学加速。本实例可以在小的位组(例如,4或8位数据块) 中提供竖直模式加速。在另一个实例中,在一些实施例中,所述多个逻辑条9152-1、
……
、 9152-z可以被配置成充当显式掩码寄存器,以实施如编译器将会使用的布尔运算。如本 文所使用的,“数据块”旨在指代比所寻址的数据行更小的位长度,例如,可以对256 位数据块(在128字节可寻址行内)进行寻址以将位宽度与特定接口相匹配。匹配16k 列存储器阵列的256位接口可能是期望的。
[0145]
根据实施例,与存储体部分相关联的控制器540(图5)可以执行微代码指令,以引导 将1k位数据值从与所述多个子阵列9145-1、
……
、9145-32中的特定存取行相关的每个 多路复用列并行移动到计算单元9198中的特定逻辑条9152-1、
……
、9152-n的特定计 算组件9148-1、
……
、9148-z。
[0146]
根据一些实施例,蝶形网络9202可以用于将1k位数据值连接到所述多个逻辑条 9152-1、
……
、9152-n中的相应逻辑条中的所述多个计算组件9148-1、
……
、9148-z 中的相应计算组件。通过举例而非通过限制,可以将1k位数据值并行移动到与存储体 部分9150的4个象限中的每个象限中的32个子阵列9145-1、
……
、9145-32中的每个 子阵列相关联的逻辑条。在本实例中,具有1k个计算组件9148-1、
……
、9148-z的128 个逻辑条9152-1、
……
、9152-n各自可以包含在计算单元9198中。可以根据来自控制 器640(图6a)的微代码指令来操作加载到计算单元9198的逻辑条9152-1、
……
、9152-n 中的所述多个计算组件9148-1、
……
、9148-z的数据值,以便与本文结合图7的读出电 路系统7138所描述的相同地对数据值执行操作,例如,与、或、或非、异或、加、减、 乘、除等。如上文指出的,一旦将数据值加载到计算单元9198,根据由控制器640(图 6a)执行的微代码指令,可以例如以大约2纳秒(ns)的速度更快地在计算单元中控制计算 操作,而无需将数据值移回到阵列525(图5)的行中。例如,可以使用计算单元9198以 比激发阵列625中的行(图6a)并对其进行存取所需的示例时间例如大约60纳秒(ns)快得 多的速度来执行计算操作。
[0147]
在图9a的示例实施例中,所述多条共享i/o线9144的数据路径中的计算单元9198 中的所述多个计算组件9148-1、
……
、9148-z和/或逻辑条9152-1、
……
、9152-n的间 距等于共享i/o线的数据路径的间距。根据实施例,数据路径的间距是数位线到存储器 单元的阵列525(图5)的的函数,例如倍数(2x、4x等)。例如,所述多个计算组件 9148-1、
……
、9148-z和/或逻辑9152-1、
……
、9152-n的间距是数位线到存储器单元 阵列的间距的整数倍。
[0148]
图9b是展示了通过阵列本地的数据路径中的多条共享i/o线耦接到计算单元中的 多个计算组件的多个阵列的框图实例,其中所述计算组件的间距等于共享i/o线的数据 路径的间距,并且所述间距是数位线到阵列的间距的倍数。图9b的实例展示了可以具 有通过数位线9168存取的存储器单元的多个阵列,例如,存储体象限9150-1、9150-2、 阵列的各部分等。
[0149]
在图9b的实例中,示出了根据数位线制造工艺的给定特征尺寸(设计规则)间距为大 约一万六千(16k)条数位线9168宽的存储体象限9150-1和9150-2。还示出了多条共享 i/o线9144-1、9144-2、
……
、9144-z,所述多条共享i/o线可以具有是数位线制造工艺 的给定特征尺寸(设计规则)的函数例如倍数的不同间距。在图9b的示例中,所述多条共 享i/o
线9144-1、9144-z的数据路径的间距大约比数位线9168的间距大十六(16)倍。因 此,在本实例中,示出了通过16:1多路复用器,例如分别为9204-1、
……
、9204-z和 9206-1、
……
、9206-z被多路复用到16k条数位线9168的大约一千(1k)条共享i/o线 9144-1、
……
、9144-z。然而,实施例不限于此处提供的数字实例,并且更多或更少的 数位线9168可以被多路复用到多条共享i/o线9144-1、
……
、9144-z。例如,共享i/o 线9144-1、
……
、9144-z的间距可以是如由数位线制造工艺的给定特征尺寸(设计规则) 设定的数位线9168的间距的除16倍(例如,16x)之外的倍数。
[0150]
如图9b的实例所示出的,例如多个计算组件9148-1、
……
、9148-z和9149-1、
……
、 9149-z中的计算组件可以分别与每条共享i/o线9144-1、
……
、9144-z相关联。所述多 个计算组件9148-1、
……
、9148-z和9149-1、
……
、9149-z可以分别在被示出为9198-1 和9198-2的计算单元的多个逻辑条,例如图9a所示出的9152-1、9152-2、
……
、9152-n 内。如图9b的实例所示出的,例如与每条共享i/o线9144-1、
……
、9144-z相关联的 多个计算组件9148-1、
……
、9148-z和9149-1、
……
、9149-z中的计算组件的间距可 以等于共享i/o线9144-1、
……
、9144-z的数据路径的间距,并且因此是阵列例如9150-1 和9150-2的数位线9168的间距的十六倍(例如,16x)。根据各个实施例,由于共享i/o 线9144-1、
……
、9144-z的数据路径中的计算组件9148-1、
……
、9148-z和9149-1、
……
、 9149-z不受与数位线8168的间距成一对一(例如,1x倍)关系的限制,因此计算组件 9148-1、
……
、9148-z和9149-1、
……
、9149-z不限于阵列9150-1和9150-2的“竖直
”ꢀ
对齐,并且在本实例中可以大十六倍(16x)。这样,共享i/o线9144-1、
……
、9144-z的 数据路径中的计算组件9148-1、
……
、9148-z和9149-1、
……
、9149-z可以用于对存 储在其中的数据值执行更稳健的逻辑运算集(例如,通过具有更大的占用面积和空间), 如上文提及的长移位加速,同时仍然靠近阵列9150-1和9150-1并且在阵列或存储器管 芯的外围区域中不偏离。
[0151]
尽管本文已经展示并描述了具体实施例,但是本领域的普通技术人员应理解,为了 实现相同结果计算的布置可以取代所示出的具体实施例。本公开旨在覆盖本公开的各个 实施例的改编或变化。应理解的是,以上描述是以说明性的方式而非限制性方式进行的。 回顾以上描述,以上实施例的组合和本文中未具体描述的其它实施例对于本领域技术人 员而言将会是显而易见的。本公开的各个实施例的范围包含以上结构和方法被使用的其 它应用。因此,本公开的各个实施例的范围应当参考所附权利要求连同与此类权利要求 被赋予的等同物的全部范围确定。
[0152]
在前述的具体实施方式中,出于精简本公开的目的,将各种特征聚集在单个实施例 中。本公开的此方法不应被解释为反映本公开的所公开实施例必须使用比每个权利要求 中明确陈述的更多的特征的意图。相反,如以下的权利要求所反映的,创造性主题在于 少于单个所公开实施例的全部特征。因此,以下权利要求由此被并入具体实施方式中, 其中每项权利要求独自代表单独的实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。