用于验证在深度学习人工神经网络中的模拟神经存储器中的非易失性存储器单元的编程操作期间存储的值的算法和电路
1.优先权声明
2.本技术要求于2019年1月29日提交的标题为“用于深度学习人工神经网络中的模拟神经存储器的精密编程电路(precision programming circuit for analog neural memory in deep learning artificial neural network)”的美国临时专利申请号62/798,394和于2019年3月21日提交的标题为“用于验证在深度学习人工神经网络中的模拟神经存储器中的非易失性存储器单元的编程操作期间存储的值的算法和电路(algorithms and circuitry for verifying a value stored during a programming operation of a non
‑
volatile memory cell in an analog neural memory in deep learning artificial neural network)”的美国专利申请号16/360,955的优先权。
技术领域
3.本发明公开了用于验证在模拟神经存储器中的编程操作期间在非易失性存储器单元中存储的值的多种验证算法和电路。
背景技术:
4.人工神经网络模拟生物神经网络(动物的中枢神经系统,特别是大脑),并且用于估计或近似可取决于大量输入并且通常未知的函数。人工神经网络通常包括互相交换消息的互连“神经元”层。
5.图1示出了人工神经网络,其中圆圈表示神经元的输入或层。连接部(称为突触)用箭头表示,并且具有可以根据经验进行调整的数值权重。这使得神经网络适应于输入并且能够学习。通常,神经网络包括多个输入的层。通常存在神经元的一个或多个中间层,以及提供神经网络的输出的神经元的输出层。处于每一级别的神经元分别地或共同地根据从突触所接收的数据作出决定。
6.在开发用于高性能信息处理的人工神经网络方面的主要挑战中的一个挑战是缺乏足够的硬件技术。实际上,实际神经网络依赖于大量的突触,从而实现神经元之间的高连通性,即非常高的计算并行性。原则上,此类复杂性可通过数字超级计算机或专用图形处理单元集群来实现。然而,相比于生物网络,这些方法除了高成本之外,能量效率也很普通,生物网络主要由于其执行低精度的模拟计算而消耗更少的能量。cmos模拟电路已被用于人工神经网络,但由于需要大量神经元和突触,大多数cmos实现的突触都过于庞大。
7.申请人先前在美国专利申请15/594,439(公开为美国专利公布2017/0337466)中公开了一种利用一个或多个非易失性存储器阵列作为突触的人工(模拟)神经网络,该专利申请以引用方式并入本文。非易失性存储器阵列作为模拟神经形态存储器操作。神经网络设备包括被配置成接收第一多个输入并从其生成第一多个输出的第一多个突触,以及被配置成接收第一多个输出的第一多个神经元。第一多个突触包括多个存储器单元,其中存储器单元中的每个存储器单元包括:形成于半导体衬底中的间隔开的源极区和漏极区,其中
沟道区在源极区和漏极区之间延伸;设置在沟道区的第一部分上方并且与第一部分绝缘的浮栅;以及设置在沟道区的第二部分上方并且与第二部分绝缘的非浮栅。多个存储器单元中的每个存储器单元被配置成存储与浮栅上的多个电子相对应的权重值。多个存储器单元被配置成将第一多个输入乘以所存储的权重值以生成第一多个输出。
8.必须擦除和编程在模拟神经形态存储器系统中使用的每个非易失性存储器单元,以在浮栅中保持非常特定且精确的电荷量(即电子数量)。例如,每个浮栅必须保持n个不同值中的一个,其中n是可由每个单元指示的不同权重的数量。n的示例包括16、32、64、128和256。
9.vmm系统中的一个挑战是对vmm的存储器单元进行准确编程的能力,因为将需要对所选择单元的浮栅进行编程以保持非常具体和精确的电荷量,使得每个浮栅可保持不同n值中的一个n值。相关挑战是验证编程值是否在旨在被编程的值的可接受范围内的能力。
10.所需要的是用于验证在编程操作期间在非易失性存储器单元中存储的值的准确性的改进验证算法和电路。
技术实现要素:
11.本发明公开了用于在非易失性存储器单元的多级编程操作之后通过将存储的权重转换成多个数字输出位来验证神经网络中非易失性存储器单元中的存储的权重的各种算法。本发明公开了用于实现算法的电路,诸如可调参考电流源。
附图说明
12.图1为示出现有技术的人工神经网络的示意图。
13.图2示出现有技术的分裂栅闪存存储器单元。
14.图3示出另一现有技术的分裂栅闪存存储器单元。
15.图4示出另一现有技术的分裂栅闪存存储器单元。
16.图5示出另一现有技术的分裂栅闪存存储器单元。
17.图6示出另一现有技术的分裂栅闪存存储器单元。
18.图7示出现有技术的堆叠栅闪存存储器单元。
19.图8为示出使用一个或多个非易失性存储器阵列的示例性人工神经网络的不同层级的示意图。
20.图9为示出矢量
‑
矩阵乘法系统的框图。
21.图10为示出使用一个或多个矢量
‑
矩阵乘法系统的示例性人工神经网络的框图。
22.图11示出矢量
‑
矩阵乘法系统的另一实施方案。
23.图12示出矢量
‑
矩阵乘法系统的另一实施方案。
24.图13示出矢量
‑
矩阵乘法系统的另一实施方案。
25.图14示出矢量
‑
矩阵乘法系统的另一实施方案。
26.图15示出矢量
‑
矩阵乘法系统的另一实施方案。
27.图16示出现有技术的长短期存储器系统。
28.图17示出在长短期存储器系统中使用的示例性单元。
29.图18示出图17的示例性单元的一个实施方案。
30.图19示出图17的示例性单元的另一实施方案。
31.图20示出现有技术的栅控递归单元系统。
32.图21示出在栅控递归单元系统中使用的示例性单元。
33.图22示出图21的示例性单元的一个实施方案。
34.图23示出图21的示例性单元的另一实施方案。
35.图24示出矢量
‑
矩阵乘法系统的另一实施方案。
36.图25示出矢量
‑
矩阵乘法系统的另一实施方案。
37.图26示出矢量
‑
矩阵乘法系统的另一实施方案。
38.图27示出矢量
‑
矩阵乘法系统的另一实施方案。
39.图28示出矢量
‑
矩阵乘法系统的另一实施方案。
40.图29示出矢量
‑
矩阵乘法系统的另一实施方案。
41.图30示出矢量
‑
矩阵乘法系统的另一实施方案。
42.图31示出矢量
‑
矩阵乘法系统的另一实施方案。
43.图32示出vmm系统。
44.图33示出模拟神经存储器系统。
45.图34示出用于与矢量乘法器矩阵系统一起使用的高电压生成块。
46.图35示出电荷泵和电荷泵调节电路。
47.图36示出具有电流补偿电路的高电压生成块。
48.图37示出具有电流补偿电路的另一高电压生成块。
49.图38示出另一高电压生成块。
50.图39示出用于提供电流补偿的虚拟位线。
51.图40示出高电压解码器。
52.图41示出高电压测试电路。
53.图42示出高电压生成块。
54.图43示出另一高电压生成块。
55.图44示出另一高电压生成块。
56.图45示出高电压运算放大器。
57.图46示出另一高电压运算放大器。
58.图47示出自适应高电压源。
59.图48示出列驱动器。
60.图49示出列读出放大器。
61.图50示出读取参考电路。
62.图51示出另一读取参考电路。
63.图52示出自适应高电压源。
64.图53示出另一自适应高电压源。
65.图54示出另一自适应高电压源。
66.图55示出另一自适应高电压源。
67.图56示出另一自适应高电压源。
68.图57示出单参考验证算法。
69.图58示出双参考验证算法。
70.图59示出可调参考电压源。
71.图60示出在图59的可调参考电压源中使用的子电路。
具体实施方式
72.本发明的人工神经网络利用cmos技术和非易失性存储器阵列的组合。
73.非易失性存储器单元
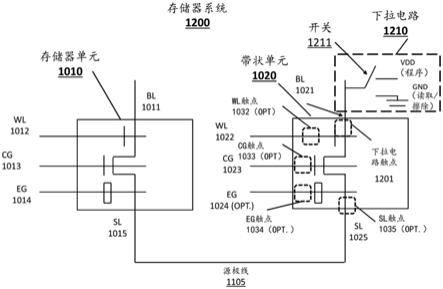
74.数字非易失性存储器是众所周知的。例如,美国专利5,029,130(“130专利”),其以引用方式并入本文,公开了分裂栅非易失性存储器单元的阵列,它是一种闪存存储器单元。此类存储器单元210在图2中示出。每个存储器单元210包括形成于半导体衬底12中的源极区14和漏极区16,其间具有沟道区18。浮栅20形成在沟道区18的第一部分上方并且与其绝缘(并控制其电导率),并且形成在源极区14的一部分上方。字线端子22(其通常被耦接到字线)具有设置在沟道区18的第二部分上方并且与该沟道区的第二部分绝缘(并且控制其电导率)的第一部分,以及向上延伸并且位于浮栅20上方的第二部分。浮栅20和字线端子22通过栅极氧化物与衬底12绝缘。位线24耦接到漏极区16。
75.通过将高的正电压置于字线端子22上来对存储器单元210进行擦除(其中电子从浮栅去除),这导致浮栅20上的电子经由fowler
‑
nordheim隧穿从浮栅20到字线端子22隧穿通过中间绝缘体。
76.通过将正的电压置于字线端子22上以及将正的电压置于源极区14上来编程存储器单元210(其中电子被置于浮栅上)。电子电流将从源极区14流向漏极区16。当电子到达字线端子22和浮栅20之间的间隙时,电子将加速并且变热。由于来自浮栅20的静电引力,一些加热的电子将通过栅极氧化物被注入到浮栅20上。
77.通过将正的读取电压置于漏极区16和字线端子22(其接通沟道区18的在字线端子下方的部分)上来读取存储器单元210。如果浮栅20带正电(即,电子被擦除),则沟道区18的在浮栅20下方的部分也被接通,并且电流将流过沟道区18,该沟道区被感测为擦除状态或“1”状态。如果浮栅20带负电(即,通过电子进行了编程),则沟道区的在浮栅20下方的部分被大部分或完全关断,并且电流将不会(或者有很少的电流)流过沟道区18,该沟道区被感测为编程状态或“0”状态。
78.表1示出了可以施加到存储器单元110的端子用于执行读取、擦除和编程操作的典型电压范围:
79.表1:图2的闪存存储器单元210的操作
[0080] wlblsl读取2
‑
3v0.6
‑
2v0v擦除约11
‑
13v0v0v编程1
‑
2v1
‑
3μa9
‑
10v
[0081]
图3示出了存储器单元310,其与图2的存储器单元210类似,但增加了控制栅(cg)28。控制栅28在编程中被偏置在高电压处(例如,10v),在擦除中被偏置在低电压或负电压处(例如,0v/
‑
8v),在读取中被偏置在低电压或中等电压处(例如,0v/2.5v)。其他端子类似于图2那样偏置。
[0082]
图4示出了四栅极存储器单元410,其包括源极区14、漏极区16、在沟道区18的第一部分上方的浮栅20、在沟道区18的第二部分上方的选择栅22(通常耦接到字线wl)、在浮栅20上方的控制栅28、以及在源极区14上方的擦除栅30。这种配置在美国专利6,747,310中有所描述,该专利以引用方式并入本文以用于所有目的。这里,除了浮栅20之外,所有的栅极均为非浮栅,这意味着它们电连接到或能够电连接到电压源。编程由来自沟道区18的将自身注入到浮栅20的加热的电子执行。擦除通过从浮栅20隧穿到擦除栅30的电子来执行。
[0083]
表2示出可施加到存储器单元310的端子用于执行读取、擦除和编程操作的典型电压范围:
[0084]
表2:图4的闪存存储器单元410的操作
[0085] wl/sgblcgegsl读取1.0
‑
2v0.6
‑
2v0
‑
2.6v0
‑
2.6v0v擦除
‑
0.5v/0v0v0v/
‑
8v8
‑
12v0v编程1v1μa8
‑
11v4.5
‑
9v4.5
‑
5v
[0086]
图5示出了存储器单元510,除了不含擦除栅eg,存储器单元510与图4的存储器单元410类似。通过将衬底18偏置到高电压并将控制栅cg28偏置到低电压或负电压来执行擦除。另选地,通过将字线22偏置到正电压并将控制栅28偏置到负电压来执行擦除。编程和读取类似于图4的那样。
[0087]
图6示出三栅极存储器单元610,其为另一种类型的闪存存储器单元。存储器单元610与图4的存储器单元410相同,不同的是存储器单元610没有单独的控制栅。除了没有施加控制栅偏置,擦除操作(由此通过使用擦除栅进行擦除)和读取操作与图4的操作类似。在没有控制栅偏置的情况下,编程操作也被完成,并且结果,在编程操作期间必须在源极线上施加更高的电压,以补偿控制栅偏置的缺乏。
[0088]
表3示出可施加到存储器单元610的端子用于执行读取、擦除和编程操作的典型电压范围:
[0089]
表3:图6的闪存存储器单元610的操作
[0090] wl/sgblegsl读取0.7
‑
2.2v0.6
‑
2v0
‑
2.6v0v擦除
‑
0.5v/0v0v11.5v0v编程1v2
‑
3μa4.5v7
‑
9v
[0091]
图7示出堆叠栅存储器单元710,其为另一种类型的闪存存储器单元。存储器单元710与图2的存储器单元210类似,不同的是浮栅20在整个沟道区18上方延伸,并且控制栅22(其在这里将耦接到字线)在浮栅20上方延伸,由绝缘层(未示出)分开。擦除、编程和读取操作以与先前针对存储器单元210所述类似的方式操作。
[0092]
表4示出可以施加到存储器单元710和衬底12的端子用于执行读取、擦除和编程操作的典型电压范围:
[0093]
表4:图7的闪存存储器单元710的操作
[0094] cgblsl衬底读取2
‑
5v0.6
‑
2v0v0v
擦除
‑
8至
‑
10v/0vfltflt8
‑
10v/15
‑
20v编程8
‑
12v3
‑
5v0v0v
[0095]
为了在人工神经网络中利用包括上述类型的非易失性存储器单元之一的存储器阵列,进行了两个修改。第一,对线路进行配置,使得每个存储器单元可被单独编程、擦除和读取,而不会不利地影响阵列中的其他存储器单元的存储器状态,如下文进一步解释。第二,提供存储器单元的连续(模拟)编程。
[0096]
具体地,阵列中的每个存储器单元的存储器状态(即,浮栅上的电荷)可在独立地并且对其他存储器单元的干扰最小的情况下连续地从完全擦除状态变为完全编程状态。在另一个实施方案,阵列中的每个存储器单元的存储器状态(即,浮栅上的电荷)可在独立地并且对其他存储器单元的干扰最小的情况下连续地从完全编程状态变为完全擦除状态,反之亦然。这意味着单元存储装置是模拟的,或者至少可存储许多离散值(诸如16或64个不同的值)中的一个离散值,这允许对存储器阵列中的所有单元进行非常精确且单独的调谐,并且这使得存储器阵列对于存储和对神经网络的突触权重进行微调调整是理想的。
[0097]
本文所述的方法和装置可应用于其他非易失性存储器技术,诸如但不限于sonos(硅
‑
氧化物
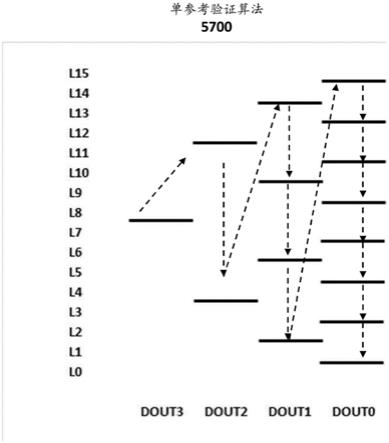
‑
氮化物
‑
氧化物
‑
硅,电荷捕获在氮化物中)、monos(金属
‑
氧化物
‑
氮化物
‑
氧化物
‑
硅,金属电荷捕获在氮化物中)、reram(电阻式ram)、pcm(相变存储器)、mram(磁性ram)、feram(铁电ram)、otp(双层或多层式一次可编程)和ceram(关联电子ram)等。本文所述的方法和装置可应用于用于神经网络的易失性存储器技术,诸如但不限于sram、dram和/或易失性突触单元。
[0098]
采用非易失性存储器单元阵列的神经网络
[0099]
图8概念性地示出本实施方案的使用非易失性存储器阵列的神经网络的非限制性示例。该示例将非易失性存储器阵列神经网络用于面部识别应用,但任何其他适当的应用也可使用基于非易失性存储器阵列的神经网络来实现。
[0100]
对于该示例,s0为输入层,其为具有5位精度的32
×
32像素rgb图像(即,三个32
×
32像素阵列,分别用于每个颜色r、g和b,每个像素为5位精度)。从输入层s0到层c1的突触cb1在一些情况下应用不同的权重集,在其他情况下应用共享权重,并且用3
×
3像素重叠滤波器(内核)扫描输入图像,将滤波器移位1个像素(或根据模型所指示的多于1个像素)。具体地,将图像的3
×
3部分中的9个像素的值(即,称为滤波器或内核)提供给突触cb1,其中将这9个输入值乘以适当的权重,并且在对该乘法的输出求和之后,由cb1的第一突触确定并提供单个输出值以用于生成特征映射的其中一层c1的像素。然后将3x3滤波器在输入层s0内向右移位一个像素(即,添加右侧的三个像素的列,并释放左侧的三个像素的列),由此将该新定位的滤波器中的9个像素值提供给突触cb1,其中将它们乘以相同的权重并且由相关联的突触确定第二单个输出值。继续该过程,直到3
×
3滤波器在输入层s0的整个32
×
32像素图像上扫描所有三种颜色和所有位(精度值)。然后使用不同组的权重重复该过程以生成c1的不同特征映射,直到计算出层c1的所有特征映射。
[0101]
在层c1处,在本示例中,存在16个特征映射,每个特征映射具有30
×
30像素。每个像素是从输入和内核的乘积中提取的新特征像素,因此每个特征映射是二维阵列,因此在该示例中,层c1由16层的二维阵列构成(记住本文所引用的层和阵列是逻辑关系,而不必是物理关系,即阵列不必定向于物理二维阵列)。在层c1中的16个特征映射中的每个特征映射
均由应用于滤波器扫描的十六个不同组的突触权重中的一组生成。c1特征映射可全部涉及相同图像特征的不同方面,诸如边界识别。例如,第一映射(使用第一权重组生成,针对用于生成该第一映射的所有扫描而共享)可识别圆形边缘,第二映射(使用与第一权重组不同的第二权重组生成)可识别矩形边缘,或某些特征的纵横比,以此类推。
[0102]
在从层c1转到层s1之前,应用激活函数p1(池化),该激活函数将来自每个特征映射中连续的非重叠2
×
2区域的值进行池化。池化函数的目的是对邻近位置求均值(或者也可使用max函数),以例如减少边缘位置的依赖性,并在进入下一阶段之前减小数据大小。在层s1处,存在16个15
×
15特征映射(即,十六个每个特征映射15
×
15像素的不同阵列)。从层s1到层c2的突触cb2利用4
×
4滤波器扫描s1中的映射,其中滤波器移位1个像素。在层c2处,存在22个12
×
12特征映射。在从层c2转到层s2之前,应用激活函数p2(池化),该激活函数将来自每个特征映射中连续的非重叠2
×
2区域的值进行池化。在层s2处,存在22个6
×
6特征映射。将激活函数(池化)应用于从层s2到层c3的突触cb3,其中层c3中的每个神经元经由cb3的相应突触连接至层s2中的每个映射。在层c3处,存在64个神经元。从层c3到输出层s3的突触cb4完全将c3连接至s3,即层c3中的每个神经元都连接到层s3中的每个神经元。s3处的输出包括10个神经元,其中最高输出神经元确定类。例如,该输出可指示对原始图像的内容的识别或分类。
[0103]
使用非易失性存储器单元的阵列或阵列的一部分来实现每层的突触。
[0104]
图9为可用于该目的的阵列的框图。矢量
‑
矩阵乘法(vmm)阵列32包括非易失性存储器单元,并且用作一层与下一层之间的突触(诸如图6中的cb1、cb2、cb3和cb4)。具体地,vmm阵列32包括非易失性存储器单元阵列33、擦除栅和字线栅解码器34、控制栅解码器35、位线解码器36和源极线解码器37,这些解码器对非易失性存储器单元阵列33的相应输入进行解码。对vmm阵列32的输入可来自擦除栅和字线栅解码器34或来自控制栅解码器35。在该示例中,源极线解码器37还对非易失性存储器单元阵列33的输出进行解码。另选地,位线解码器36可以解码非易失性存储器单元阵列33的输出。
[0105]
非易失性存储器单元阵列33用于两个目的。首先,它存储将由vmm阵列32使用的权重。其次,非易失性存储器单元阵列33有效地将输入与存储在非易失性存储器单元阵列33中的权重相乘并且每个输出线(源极线或位线)将它们相加以产生输出,该输出将作为下一层的输入或最终层的输入。通过执行乘法和加法函数,非易失性存储器单元阵列33消除了对单独的乘法和加法逻辑电路的需要,并且由于其原位存储器计算其也是高功效的。
[0106]
将非易失性存储器单元阵列33的输出提供至差分求和器(诸如求和运算放大器或求和电流镜)38,该差分求和器对非易失性存储器单元阵列33的输出进行求和,以为该卷积创建单个值。差分求和器38被布置用于执行正权重和负权重的求和。
[0107]
然后将差分求和器38的输出值求和后提供至激活函数电路39,该激活函数电路对输出进行修正。激活函数电路39可提供sigmoid、tanh、relu函数或任何其他非线性函数。激活函数电路39的经修正的输出值成为作为下一层(例如,图8中的层c1)的特征映射的元素,然后被应用于下一个突触以产生下一个特征映射层或最终层。因此,在该示例中,非易失性存储器单元阵列33构成多个突触(其从现有神经元层或从输入层诸如图像数据库接收它们的输入),并且求和器38和激活函数电路39构成多个神经元。
[0108]
图9中对vmm阵列32的输入(wlx、egx、cgx以及任选的blx和slx)可为模拟电平、二
进制电平、数字脉冲(在这种情况下,可能需要脉冲
‑
模拟转换器pac来将脉冲转换至合适的输入模拟电平)或数字位(在这种情况下,提供dac以将数字位转换至合适的输入模拟电平);输出可为模拟电平、二进制电平、数字脉冲或数字位(在这种情况下,提供输出adc以将输出模拟电平转换成数字位)。
[0109]
图10为示出多层vmm阵列32(此处标记为vmm阵列32a、32b、32c、32d和32e)的使用的框图。如图10所示,通过数模转换器31将输入(表示为inputx)从数字转换为模拟,并将其提供至输入vmm阵列32a。转换的模拟输入可以是电压或电流。第一层的输入d/a转换可通过使用将输入inputx映射到输入vmm阵列32a的矩阵乘法器的适当模拟电平的函数或lut(查找表)来完成。输入转换也可以由模拟至模拟(a/a)转换器完成,以将外部模拟输入转换成到输入vmm阵列32a的映射模拟输入。输入转换也可以由数字至数字脉冲(d/p)转换器完成,以将外部数字输入转换成到输入vmm阵列32a的映射的一个或多个数字脉冲。
[0110]
由输入vmm阵列32a产生的输出被作为到下一个vmm阵列(隐藏级别1)32b的输入提供,该输入继而生成作为下一vmm阵列(隐藏级别2)32c的输入而提供的输出,以此类推。vmm阵列32的各层用作卷积神经网络(cnn)的突触和神经元的不同层。每个vmm阵列32a、32b、32c、32d和32e可以是独立的物理非易失性存储器阵列、或者多个vmm阵列可以利用相同非易失性存储器阵列的不同部分、或者多个vmm阵列可以利用相同物理非易失性存储器阵列的重叠部分。每个vmm阵列32a、32b、32c、32d和32e也可针对其阵列或神经元的不同部分进行时分复用。图10所示的示例包含五个层(32a、32b、32c、32d、32e):一个输入层(32a)、两个隐藏层(32b、32c)和两个全连接层(32d、32e)。本领域的普通技术人员将会知道,这仅仅是示例性的,并且相反,系统可包括两个以上的隐藏层和两个以上的完全连接的层。
[0111]
矢量
‑
矩阵乘法(vmm)阵列
[0112]
图11示出神经元vmm阵列1100,该神经元vmm阵列特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1100包括非易失性存储器单元的存储器阵列1101和非易失性参考存储器单元的参考阵列1102(在阵列的顶部)。另选地,可将另一个参考阵列置于底部。
[0113]
在vmm阵列1100中,控制栅线(诸如控制栅线1103)在竖直方向上延伸(因此参考阵列1102在行方向上与控制栅线1103正交),并且擦除栅线(诸如擦除栅线1104)在水平方向上延伸。此处,vmm阵列1100的输入设置在控制栅线(cg0、cg1、cg2、cg3)上,并且vmm阵列1100的输出出现在源极线(sl0、sl1)上。在一个实施方案中,仅使用偶数行,并且在另一个实施方案中,仅使用奇数行。置于各源极线(分别为sl0、sl1)上的电流执行来自连接到该特定源极线的存储器单元的所有电流的求和函数。
[0114]
如本文针对神经网络所述,vmm阵列1100的非易失性存储器单元(即vmm阵列1100的闪存存储器)优选地被配置成在亚阈值区域中操作。
[0115]
在弱反转中偏置本文所述的非易失性参考存储器单元和非易失性存储器单元:
[0116]
ids=io*e
(vg
‑
vth)/kvt
=w*io*e
(vg)/kvt
,
[0117]
其中w=e
(
‑
vth)/kvt
[0118]
对于使用存储器单元(诸如参考存储器单元或外围存储器单元)或晶体管将输入电流转换为输入电压的i到v对数转换器:
[0119]
vg=k*vt*log[ids/wp*io]
[0120]
此处,wp为参考存储器单元或外围存储器单元的w。
[0121]
对于用作矢量矩阵乘法器vmm阵列的存储器阵列,输出电流为:
[0122]
iout=wa*io*e
(vg)/kvt
,即
[0123]
iout=(wa/wp)*iin=w*iin
[0124]
w=e
(vthp
‑
vtha)/kvt
[0125]
此处,wa=存储器阵列中的每个存储器单元的w。
[0126]
字线或控制栅可用作输入电压的存储器单元的输入。
[0127]
另选地,本文所述的vmm阵列的闪存存储器单元可被配置成在线性区域中操作:
[0128]
ids=β*(vgs
‑
vth)*vds;β=u*cox*w/l
[0129]
w=α(vgs
‑
vth)
[0130]
字线或控制栅或位线或源极线可以用作在线性区域中操作的存储器单元的输入。位线或源极线可用作存储器单元的输出。
[0131]
对于i到v线性转换器,在线性区域工作的存储器单元(例如参考存储器单元或外围存储器单元)或晶体管或电阻器可以用来将输入/输出电流线性转换成输入/输出电压。
[0132]
美国专利申请15/826,345描述了图9的vmm阵列32的其他实施方案,该申请以引用方式并入本文。如本文所述,源极线或位线可以用作神经元输出(电流求和输出)。另选地,本文所述的vmm阵列的闪存存储器单元可被配置成在饱和区域中操作:
[0133]
ids=α1/2*β*(vgs
‑
vth)2;β=u*cox*w/l
[0134]
w=α(vgs
‑
vth)2[0135]
字线、控制栅或擦除栅可以用作在饱和区域中操作的存储器单元的输入。位线或源极线可用作输出神经元的输出。
[0136]
另选地,本文所述的vmm阵列的闪存存储器单元可用于所有区域或其组合(亚阈值、线性或饱和区域)。
[0137]
图12示出神经元vmm阵列1200,该神经元vmm阵列特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的突触。vmm阵列1200包括非易失性存储器单元的存储器阵列1203、第一非易失性参考存储器单元的参考阵列1201和第二非易失性参考存储器单元的参考阵列1202。沿阵列的列方向布置的参考阵列1201和1202用于将流入端子blr0、blr1、blr2和blr3的电流输入转换为电压输入wl0、wl1、wl2和wl3。实际上,第一非易失性参考存储器单元和第二非易失性参考存储器单元通过多路复用器1214(仅部分示出)二极管式连接,其中电流输入流入其中。参考单元被调谐(例如,编程)为目标参考电平。目标参考电平由参考微阵列矩阵(未示出)提供。
[0138]
存储器阵列1203用于两个目的。首先,它将vmm阵列1200将使用的权重存储在其相应的存储器单元上。第二,存储器阵列1203有效地将输入(即,在端子blr0、blr1、blr2和blr3中提供的电流输入,参考阵列1201和1202将它们转换成输入电压以提供给字线wl0、wl1、wl2和wl3)乘以存储在存储器阵列1203中的权重,然后将所有结果(存储器单元电流)相加以在相应的位线(bl0
‑
bln)上产生输出,该输出将是下一层的输入或最终层的输入。通过执行乘法和加法函数,存储器阵列1203消除了对单独的乘法和加法逻辑电路的需要,并且也是高功效的。这里,电压输入在字线(wl0、wl1、wl2和wl3)上提供,并且输出在读取(推断)操作期间出现在相应位线(bl0
‑
bln)上。置于位线bl0
‑
bln中的每个位线上的电流执行
来自连接到该特定位线的所有非易失性存储器单元的电流的求和函数。
[0139]
表5示出用于vmm阵列1200的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的源极线和用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。
[0140]
表5:图12的vmm阵列1200的操作
[0141] wlwl
‑
未选blbl
‑
未选slsl
‑
未选读取1
‑
3.5v
‑
0.5v/0v0.6
‑
2v(ineuron)0.6v
‑
2v/0v0v0v擦除约5
‑
13v0v0v0v0v0v编程1
‑
2v
‑
0.5v/0v0.1
‑
3uavinh约2.5v4
‑
10v0
‑
1v/flt
[0142]
图13示出神经元vmm阵列1300,该神经元vmm阵列特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1300包括非易失性存储器单元的存储器阵列1303、第一非易失性参考存储器单元的参考阵列1301和第二非易失性参考存储器单元的参考阵列1302。参考阵列1301和1302在vmm阵列1300的行方向上延伸。vmm阵列与vmm1000类似,不同的是在vmm阵列1300中,字线在竖直方向上延伸。这里,输入设置在字线(wla0、wlb0、wla1、wlb2、wla2、wlb2、wla3、wlb3)上,并且输出在读取操作期间出现在源极线(sl0、sl1)上。置于各源极线上的电流执行来自连接到该特定源极线的存储器单元的所有电流的求和函数。
[0143]
表6示出用于vmm阵列1300的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的源极线和用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。
[0144]
表6:图13的vmm阵列1300的操作
[0145] wlwl
‑
未选blbl
‑
未选slsl
‑
未选读取1
‑
3.5v
‑
0.5v/0v0.6
‑
2v0.6v
‑
2v/0v约0.3
‑
1v(ineuron)0v擦除约5
‑
13v0v0v0v0vsl
‑
禁止(约4
‑
8v)编程1
‑
2v
‑
0.5v/0v0.1
‑
3uavinh约2.5v4
‑
10v0
‑
1v/flt
[0146]
图14示出神经元vmm阵列1400,该神经元vmm阵列特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1400包括非易失性存储器单元的存储器阵列1403、第一非易失性参考存储器单元的参考阵列1401和第二非易失性参考存储器单元的参考阵列1402。参考阵列1401和1402用于将流入端子blr0、blr1、blr2和blr3的电流输入转换为电压输入cg0、cg1、cg2和cg3。实际上,第一非易失性参考存储器单元和第二非易失性参考存储器单元通过多路复用器1412(仅部分示出)二极管式连接,其中电流输入通过blr0、blr1、blr2和blr3流入其中。多路复用器1412各自包括相应的多路复用器1405和共源共栅晶体管1404,以确保在读取操作期间第一非易失性参考存储器单元和第二非易失性参考存储器单元中的每一者的位线(诸如blr0)上的恒定电压。将参考单元调谐至目标参考电平。
[0147]
存储器阵列1403用于两个目的。首先,它存储将由vmm阵列1400使用的权重。第二,存储器阵列1403有效地将输入(提供到端子blr0、blr1、blr2和blr3的电流输入,参考阵列1401和1402将这些电流输入转换成输入电压以提供给控制栅cg0、cg1、cg2和cg3)乘以存储在存储器阵列中的权重,然后将所有结果(单元电流)相加以产生输出,该输出出现在bl0
‑
bln并且将是下一层的输入或最终层的输入。通过执行乘法和加法函数,存储器阵列消除了对单独的乘法和加法逻辑电路的需要,并且也是高功效的。这里,输入提供在控制栅线(cg0、cg1、cg2和cg3)上,输出在读取操作期间出现在位线(bl0
–
bln)上。置于各位线上的电流执行来自连接到该特定位线的存储器单元的所有电流的求和函数。
[0148]
vmm阵列1400为存储器阵列1403中的非易失性存储器单元实现单向调谐。也就是说,每个非易失性存储器单元被擦除,然后被部分编程,直到达到浮栅上的所需电荷。这可例如使用下文所述的精确编程技术来执行。如果在浮栅上放置过多电荷(使得错误的值存储在单元中),则必须擦除单元,并且部分编程操作的序列必须重新开始。如图所示,共享同一擦除栅(诸如eg0或eg1)的两行需要一起擦除(其被称为页面擦除),并且此后,每个单元被部分编程,直到达到浮栅上的所需电荷。
[0149]
表7示出用于vmm阵列1400的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的控制栅、用于与所选单元相同扇区中的未选单元的控制栅、用于与所选单元不同扇区中的未选单元的控制栅、用于所选单元的擦除栅、用于未选单元的擦除栅、用于所选单元的源极线、用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。
[0150]
表7:图14的vmm阵列1400的操作
[0151][0152]
图15示出神经元vmm阵列1500,该神经元vmm阵列特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。vmm阵列1500包括非易失性存储器单元的存储器阵列1503、第一非易失性参考存储器单元的参考阵列1501和第二非易失性参考存储器单元的参考阵列1502。eg线egr0、eg0、eg1和egr1竖直延伸,而cg线cg0、cg1、cg2和cg3以及sl线wl0、wl1、wl2和wl3水平延伸。vmm阵列1500与vmm阵列1400类似,不同的是vmm阵列1500实现双向调谐,其中每个单独的单元可以根据需要被完全擦除、部分编程和部分擦除,以由于使用单独的eg线而在浮栅上达到期望的电荷量。如图所示,参考阵列1501和1502将端子blr0、blr1、blr2和blr3中的输入电流转换成要在行方向上施加到存储器单元的控制栅电压cg0、cg1、cg2和cg3(通过经由多路复用器1514的二极管连接的参考单元的动作)。电流输出(神经元)在位线bl0
‑
bln中,其中每个位线对来自连接到该特定位线的非易失性存储器单元的所有电流求和。
[0153]
表8示出用于vmm阵列1500的工作电压。表中的列指示置于用于所选单元的字线、用于未选单元的字线、用于所选单元的位线、用于未选单元的位线、用于所选单元的控制
栅、用于与所选单元相同扇区中的未选单元的控制栅、用于与所选单元不同扇区中的未选单元的控制栅、用于所选单元的擦除栅、用于未选单元的擦除栅、用于所选单元的源极线、用于未选单元的源极线上的电压。行指示读取、擦除和编程操作。
[0154]
表8:图15的vmm阵列1500的操作
[0155][0156]
图24示出神经元vmm阵列2400,该神经元vmm阵列特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的神经元的突触和部件。在vmm阵列2400中,输入input0.
…
,input
n
分别在位线bl0,
…
bl
n
上被接收,并且输出output1、output2、output3和output4分别在源极线sl0、sl1、sl2和sl3上生成。
[0157]
图25示出神经元vmm阵列2500,该神经元vmm阵列特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0、input1、input2和input3分别在源极线sl0、sl1、sl2和sl3上被接收,并且输出output0,
…
output
n
在位线bl0,
…
,bl
n
上生成。
[0158]
图26示出神经元vmm阵列2600,该神经元vmm阵列特别适用于图2所示的存储器单元210,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0,
…
,input
m
分别在字线wl0,
…
,wl
m
上被接收,并且输出output0,
…
output
n
在位线bl0,
…
,bl
n
上生成。
[0159]
图27示出神经元vmm阵列2700,该神经元vmm阵列特别适用于图3所示的存储器单元310,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0,
…
,input
m
分别在字线wl0,
…
,wl
m
上被接收,并且输出output0,
…
output
n
在位线bl0,
…
,bl
n
上生成。
[0160]
图28示出神经元vmm阵列2800,该神经元vmm阵列特别适用于图4所示的存储器单元410,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0,
…
,input
n
分别在控制栅线cg0,
…
,cg
n
上被接收,并且输出output1和output2在源极线sl0和sl1上生成。
[0161]
图29示出神经元vmm阵列2900,该神经元vmm阵列特别适用于图4所示的存储器单元410,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0至input
n
分别在位线控制栅极2901
‑
1、2901
‑
2至2901
‑
(n
‑
1)和2901
‑
n的栅极上被接收,这些栅极分别耦接到位线bl0至bl
n
。示例性输出output1和output2在源极线sl0和sl1上生成。
[0162]
图30示出了神经元vmm阵列3000,该神经元vmm阵列特别适用于图3所示的存储器单元310、图5所示的存储单元510和图7所示的存储单元710,并且用作输入层与下一层之间
的神经元的突触和部件。在该示例中,输入input0,
…
,input
m
在字线wl0,
…
,wl
m
上被接收,并且输出output0,
…
,output
n
分别在位线bl0,
…
,bl
n
上生成。
[0163]
图31示出神经元vmm阵列3100,该神经元vmm阵列特别适用于图3所示的存储器单元310、图5所示的存储器单元510和图7所示的存储器单元710,并且用作输入层与下一层之间的神经元的突触和部件。在该示例中,输入input0至input
m
在控制栅线cg0至cg
m
上被接收。输出output0至output
n
分别在源极线sl0至sl
n
上生成,其中每个源极线sl
i
耦接到列i中的所有存储器单元的源极线端子。
[0164]
图32示出vmm系统3200。vmm系统3200包括vmm阵列3201(其可基于先前讨论的vmm设计中的任一种,诸如vmm 900、1000、1100、1200和1320,或其他vmm设计)、低电压行解码器3202、高电压行解码器3203、参考单元低电压列解码器3204(在列方向上示出,这意味着其在行方向上提供输入到输出的转换)、位线多路复用器3205、控制逻辑3206、模拟电路3207、神经元输出块3208、输入vmm电路块3209、预解码器3210、测试电路3211、擦除
‑
编程控制逻辑epctl 3212、模拟和高电压生成电路3213、位线pe驱动器3214、冗余阵列3215和3216、nvr扇区3217以及参考扇区3218。输入电路块3209用作从外部输入到存储器阵列的输入端子的接口。神经元输出块3208用作从存储器阵列输出到外部接口的接口。
[0165]
低电压行解码器3202为读取操作和编程操作提供偏置电压,并且为高电压行解码器3203提供解码信号。高电压行解码器3203为编程操作和擦除操作提供高电压偏置信号。任选的参考单元低电压列解码器3204为参考单元提供解码功能。位线pe驱动器3214为处于编程、验证和擦除操作期间的位线提供控制功能。模拟和高电压生成电路3213是提供各种编程、擦除、编程验证和读取操作所需的多个电压的共享偏置块。任选的冗余阵列3215和3216提供用于替换缺陷阵列部分的阵列冗余。任选的nvr(非易失性寄存器,也称为信息扇区)扇区3217是作为用于存储不限于用户信息、设备id、密码、安全密钥、修正位、配置位和制造信息的阵列扇区的扇区。
[0166]
图33示出了模拟神经存储器系统3300。模拟神经存储器系统3300包括宏块3301a、3301b、3301c、3301d、3301e、3301f、3301g和3301h;神经元输出块(诸如求和器电路以及采样和保持s/h电路)3302a、3302b、3302c、3302d、3302e、3302f、3302g和3302h;以及输入电路块3303a、3303b、3303c、3303d、3303e、3303f、3303g和3304h。宏块3301a、3301b、3301c、3301d、3301e和3301f中的每个宏块都是包含vmm阵列的vmm子系统。神经存储器子系统3333包括宏块3301、输入块3303和神经元输出块3302。神经存储器子系统3333可具有其自己的数字控制块。
[0167]
模拟神经存储器系统3300还包括系统控制块3304、模拟低电压块3305和高电压块3306。
[0168]
系统控制块3304可包括微控制器内核(诸如arm/mips/risc_v内核)以处理通用控制功能和算术操作。系统控制块3304还可包括simd(单条指令多条数据)单元以利用单条指令对多个数据进行操作。该系统控制块可包括dsp内核。该系统控制块可包括用于执行函数诸如但不限于池化、平均、最小、最大、softmax、加、减、乘、除、对数、反对数、relu、sigmoid、tanh、数据压缩的硬件或软件。该系统控制块可包括执行诸如激活逼近器/量化器/归一化器功能的硬件或软件。该系统控制块可包括执行诸如输入数据逼近器/量化器/归一化器功能的能力。该系统控制块可包括执行激活逼近器/量化器/归一化器功能的硬件或软件。神
经存储器子系统3333的控制块可包括系统控制块3304的类似元件,诸如微控制器内核、simd内核、dsp内核和其他功能单元。
[0169]
在一个实施方案中,神经元输出块3302a、3302b、3302c、3302d、3302e、3302f、3302g和3302h各自包括缓冲(例如,运算放大器)低阻抗输出型电路,该电路可驱动长且可配置的互连器。在一个实施方案中,输入电路块3303a、3303b、3303c、3303d、3303e、3303f、3303g和3303h各自提供求和高阻抗电流输出。在另一个实施方案中,神经元输出块3302a、3302b、3302c、3302d、3302e、3302f、3302g和3302h各自包括激活电路,在这种情况下,需要附加的低阻抗缓冲器来驱动输出。
[0170]
在另一个实施方案中,神经元输出块3302a、3302b、3302c、3302d、3302e、3302f、3302g和3302h各自包括输出数字位而非模拟信号的模拟
‑
数字转换块。在该实施方案中,输入电路块3303a、3303b、3303c、3303d、3303e、3303f、3303g和3303h各自包括从相应的神经元输出块接收数字位并将该数字位转换为模拟信号的数字
‑
模拟转换块。
[0171]
因此,神经元输出块3302a、3302b、3302c、3302d、3302e、3302f、3302g和3302h从宏块3301a、3301b、3301c、3301d、3301e和3301f接收输出电流,并且任选地将该输出电流转换成模拟电压、数字位或一个或多个数字脉冲,其中每个脉冲的宽度或脉冲数量响应于输出电流的值而变化。类似地,输入电路块3303a、3303b、3303c、3303d、3303e、3303f、3303g和3303h任选地接收模拟电流、模拟电压、数字位或数字脉冲,其中每个脉冲的宽度或脉冲数量响应于输出电流的值而变化,并且向宏块3301a、3301b、3301c、3301d、3301e和3301f提供模拟电流。输入电路块3303a、3303b、3303c、3303d、3303e、3303f、3303g和3303h任选地包括电压
‑
电流转换器、用于对输入信号中的数字脉冲数或输入信号中的数字脉冲的宽度进行计数的模拟或数字计数器、或数模转换器。
[0172]
长短期存储器
[0173]
现有技术包括被称为长短期存储器(lstm)的概念。lstm单元通常用于神经网络中。lstm允许神经网络在预定的任意时间间隔内记住信息并在后续操作中使用该信息。常规的lstm单元包括单元、输入栅、输出栅和忘记栅。三个栅调控进出单元的信息流以及信息在lstm中被记住的时间间隔。vmm尤其可用于lstm单元中。
[0174]
图16示出了示例性lstm 1600。该示例中的lstm 1600包括单元1601、1602、1603和1604。单元1601接收输入矢量x0并生成输出矢量h0和单元状态矢量c0。单元1602接收输入矢量x1、来自单元1601的输出矢量(隐藏状态)h0和来自单元1601的单元状态c0,并生成输出矢量h1和单元状态矢量c1。单元1603接收输入矢量x2、来自单元1602的输出矢量(隐藏状态)h1和来自单元1602的单元状态c1,并生成输出矢量h2和单元状态矢量c2。单元1604接收输入矢量x3、来自单元1603的输出矢量(隐藏状态)h2和来自单元1603的单元状态c2,并生成输出矢量h3。可使用另外的单元,并且具有四个单元的lstm仅为示例。
[0175]
图17示出可用于图16中的单元1601、1602、1603和1604的lstm单元1700的示例性具体实施。lstm单元1700接收输入矢量x(t)、来自前一单元的单元状态矢量c(t
‑
1)和来自前一单元的输出矢量h(t
‑
1),并生成单元状态矢量c(t)和输出矢量h(t)。
[0176]
lstm单元1700包括sigmoid函数设备1701、1702和1703,每个sigmoid函数设备应用0至1之间的数字来控制允许输入向量中的每个分量通过到输出向量的数量。lstm单元1700还包括用于将双曲线正切函数应用于输入向量的tanh设备1704和1705、用于将两个向
量相乘在一起的乘法器设备1706、1707和1708以及用于将两个向量相加在一起的加法设备1709。输出矢量h(t)可被提供给系统中的下一个lstm单元,或者其可被访问用于其他目的。
[0177]
图18示出lstm单元1800,该lstm单元为lstm单元1700的具体实施的示例。为了方便读者,在lstm单元1800中使用与lstm单元1700相同的编号。sigmoid函数设备1701、1702和1703以及tanh设备1704各自包括多个vmm阵列1801和激活电路块1802。因此,可以看出,vmm阵列在某些神经网络系统中使用的lstm单元中特别有用。乘法器设备1706、1707和1708以及加法设备1709以数字方式或模拟方式实施。激活函数块1802可以数字方式或模拟方式实施。
[0178]
lstm单元1800的替代形式(以及lstm单元1700的具体实施的另一示例)在图19中示出。在图19中,sigmoid函数设备1701、1702和1703以及tanh设备1704以时分复用方式共享相同的物理硬件(vmm阵列1901和激活函数块1902)。lstm单元1900还包括将两个矢量相乘在一起的乘法器设备1903,将两个矢量相加在一起的加法设备1908,tanh设备1705(其包括激活电路块1902),当从sigmoid函数块1902输出值i(t)时存储值i(t)的寄存器1907,当值f(t)*c(t
‑
1)通过多路复用器1910从乘法器设备1903输出时存储该值的寄存器1904,当值i(t)*u(t)通过多路复用器1910从乘法器设备1903输出时存储该值的寄存器1905,当值o(t)*c~(t)通过多路复用器1910从乘法器设备1903输出时存储该值的寄存器1906,和多路复用器1909。
[0179]
lstm单元1800包含多组vmm阵列1801和相应的激活函数块1802,而lstm单元1900仅包含一组vmm阵列1901和激活函数块1902,它们用于表示lstm单元1900的实施方案中的多个层。lstm单元1900将需要比lstm1800更少的空间,因为与lstm单元1800相比,lstm单元1900只需要其1/4的空间用于vmm和激活函数块。
[0180]
还可理解,lstm单元通常将包括多个vmm阵列,每个vmm阵列需要由vmm阵列之外的某些电路区块(诸如求和器和激活电路区块以及高电压生成区块)提供的功能。为每个vmm阵列提供单独的电路区块将需要半导体设备内的大量空间,并且将在一定程度上是低效的。
[0181]
栅控递归单元
[0182]
模拟vmm具体实施可用于栅控递归单元(gru)系统。gru是递归神经网络中的栅控机构。gru类似于lstm,不同的是gru单元一般包含比lstm单元更少的部件。
[0183]
图20示出了示例性gru 2000。该示例中的gru 2000包括单元2001、2002、2003和2004。单元2001接收输入矢量x0并生成输出矢量h0。单元2002接收输入矢量x1、来自单元2001的输出矢量h0并生成输出矢量h1。单元2003接收输入矢量x2和来自单元2002的输出矢量(隐藏状态)h1,并生成输出矢量h2。单元2004接收输入矢量x3和来自单元2003的输出矢量(隐藏状态)h2,并生成输出矢量h3。可以使用另外的单元,并且具有四个单元的gru仅仅是示例。
[0184]
图21示出可用于图20的单元2001、2002、2003和2004的gru单元2100的示例性具体实施。gru单元2100接收输入矢量x(t)和来自前一个gru单元的输出矢量h(t
‑
1),并生成输出矢量h(t)。gru单元2100包括sigmoid函数设备2101和2102,每个设备将介于0和1之间的数应用于来自输出矢量h(t
‑
1)和输入矢量x(t)的分量。gru单元2100还包括用于将双曲线正切函数应用于输入矢量的tanh设备2103、用于将两个矢量相乘在一起的多个乘法器设备
2104、2105和2106、用于将两个矢量相加在一起的加法设备2107,以及用于从1中减去输入以生成输出的互补设备2108。
[0185]
图22示出gru单元2200,该gru单元为gru单元2100的具体实施的示例。为了方便读者,gru单元2200中使用与gru单元2100相同的编号。如图22所示,sigmoid函数设备2101和2102以及tanh设备2103各自包括多个vmm阵列2201和激活函数块2202。因此,可以看出,vmm阵列在某些神经网络系统中使用的gru单元中特别有用。乘法器设备2104、2105和2106、加法设备2107和互补设备2108以数字方式或模拟方式实施。激活函数块2202可以数字方式或模拟方式实施。
[0186]
gru单元2200的替代形式(以及gru单元2300的具体实施的另一示例)在图23中示出。在图23中,gru单元2300利用vmm阵列2301和激活函数块2302,当该激活函数块在被配置成sigmoid函数时,应用0至1之间的数字来控制允许输入矢量中的每个分量到达输出矢量的数量。在图23中,sigmoid函数设备2101和2102以及tanh设备2103以时分复用方式共享相同的物理硬件(vmm阵列2301和激活函数块2302)。gru单元2300还包括将两个矢量相乘在一起的乘法器设备2303,将两个矢量相加在一起的加法设备2305,从1减去输入以生成输出的互补设备2309,多路复用器2304,当值h(t
‑
1)*r(t)通过多路复用器2304从乘法器设备2303输出时保持该值的寄存器2306,当值h(t
‑
1)*z(t)通过多路复用器2304从乘法器设备2303输出时保持该值的寄存器2307,和当值h^(t)*(1
‑
z(t))通过多路复用器2304从乘法器设备2303输出时保持该值的寄存器2308。
[0187]
gru单元2200包含多组vmm阵列2201和激活函数块2202,而gru单元2300仅包含一组vmm阵列2301和激活函数块2302,它们用于表示gru单元2300的实施方案中的多个层。gru单元2300将需要比gru单元2200更少的空间,因为与gru单元2200相比,gru单元2300只需要其1/3的空间用于vmm和激活函数块。
[0188]
还可以理解的是,gru系统通常将包括多个vmm阵列,每个vmm阵列需要由vmm阵列之外的某些电路区块(诸如求和器和激活电路区块以及高电压生成区块)提供的功能。为每个vmm阵列提供单独的电路区块将需要半导体设备内的大量空间,并且将在一定程度上是低效的。
[0189]
vmm阵列的输入可为模拟电平、二进制电平或数字位(在这种情况下,需要dac来将数字位转换成适当的输入模拟电平),并且输出可为模拟电平、二进制电平或数字位(在这种情况下,需要输出adc来将输出模拟电平转换成数字位)。
[0190]
对于vmm阵列中的每个存储器单元,每个权重w可由单个存储器单元或由差分单元或由两个混合存储器单元(2个单元的平均值)来实现。在差分单元的情况下,需要两个存储器单元来实现权重w作为差分权重(w=w
–
w
‑
)。在两个混合存储器单元中,需要两个存储器单元来实现权重w作为两个单元的平均值。
[0191]
高电压生成电路和其他电路
[0192]
图34示出vmm系统3400的框图。vmm系统3400包括vmm阵列3408、行解码器3407、高电压解码器3409、列解码器3410和位线驱动器3411。vmm系统3400还包括高电压生成块3412,该高电压生成块包括电荷泵3401、电荷泵调节器3402和高电压电平发生器3403。vmm系统3400还包括算法控制器3404、模拟电路3405和控制逻辑3406。
[0193]
图35提供了关于电荷泵3401和电荷泵调节器3402的进一步细节。电荷泵3401由启
用信号3501控制。当启用信号3501未生效时,电荷泵3401继续增加其输出的电压。当启用信号3501生效时,电荷泵3401保持其输出的电压电平。电荷泵调节器3402包括分压器结构,该分压器结构包括二极管3504、3506和3508以及电阻器3505、3507和3509的串联连接,每个电阻器耦接到二极管3504、3506和3508中的相应一个二极管的阴极。该结构内的分压电压节点被输入到比较器3503,该比较器接收包括电压参考的另一输入。当从电荷泵3401输出的电压足以激活二极管3504、3506和3508使得电流将流动,并且来自分压电压节点的电压超过电压参考时,启用信号将生效。因此,电荷泵调节器3402控制电荷泵3401,直到实现期望的电压电平,这是基于二极管3504、3506和3508以及电阻器3505、3507和3509的特性。作为分压器结构的示例,示出了三个二极管和三个电阻器,通常需要多于三个二极管和三个电阻器。另选地,可实现电容器而不是二极管和电阻器以产生期望的电压比,从而向比较器3503提供输入。另选地,可将适当的比电容器与二极管和电阻器并联连接,以加速分压器结构的响应。
[0194]
图36示出vmm系统3600,该vmm系统为vmm系统3400的一个实施方案。vmm系统3600包括高电压缓冲器3601和可调电流吸收器3602。高电压生成块3412生成提供到高电压缓冲器3601的电压,该高电压缓冲器继而将该电压提供到高电压解码器3409和可调电流吸收器(编程补偿电流icomp)3602。可调整由可调电流吸收器3602从高电压缓冲器3601汲取的电流icomp,以例如引起高电压缓冲器3601内的补偿电压降,从而补偿待编程的存储器单元的数量(例如,用于待编程的1个/2个/
…
/32个io的dvout1/2/
…
/32压降)并且降低高电压缓冲器3601的温度。例如,icomp=(待编程的存储器单元的数量)*iprog*m,其中iprog=单元编程电流,并且m=由于编程操作期间的存储器单元热载流子效应而引起的乘数因子。应用补偿icomp以在变化的输出负载上保持恒定的高电压输出。
[0195]
图37示出与高电压缓冲器3701和可调电流吸收器3702一起使用的vmm系统3700的一个实施方案。高电压发生器3412生成提供到高电压缓冲器3701的电压,该高电压缓冲器继而将该电压提供到高电压解码器3409。可调整由可调电流吸收器从高电压解码器3409汲取的电流(补偿电流)icomp 3702,以例如降低高电压解码器3409内的电流降(作为待编程的存储器单元的数量的函数),和/或降低高电压解码器3409的温度。例如,icomp=(待编程的存储器单元的数量)*iprog*m。iprog=单元编程电流,m=由于编程操作期间的存储器单元热载流子效应而引起的乘数因子。应用补偿icomp以在变化的输出负载上保持恒定的高电压输出。
[0196]
图38示出与高电压缓冲器3801一起使用的vmm系统3800,该高电压缓冲器此处为运算放大器。高电压发生器3412生成提供到高电压缓冲器3801的电压,该高电压缓冲器继而将该电压提供到高电压解码器3409。来自高电压解码器3409的输出(例如,该输出是解码器中的hv电压的反馈指示器)作为输入提供到高电压缓冲器3801,该高电压缓冲器然后作为闭环运算放大器操作。应用闭环补偿以在变化的输出负载上保持恒定的高电压输出。
[0197]
图39示出要与vmm系统2400、2600、2700或2800结合使用的编程电流补偿块3900,例如,作为每个vmm系统中的vmm阵列的补充。这里,虚拟编程位线(可编程虚拟阵列)设置有每组32个位线。例如,组3901包括虚拟位线3903,并且组3902包括虚拟位线3904。在组3901和3902中的一个或多个其他位分别未被编程的情况下,这些虚拟位线3903和3904可被导通(以提供位线编程电流)。相较于不使用虚拟位线3903和3904的情况,这将使编程操作期间
汲取的电流保持更为恒定。应用编程虚拟阵列补偿方案以在变化的输出负载上保持恒定的高电压输出。
[0198]
图40示出可用于实现高电压解码器3409的高电压解码器块4000的示例。此处,源极线4005耦接到vmm阵列3408中的一行或两行。nmos晶体管4001、4002、4003和4004耦接到源极线4005,如图所示。hv电源4010由hv缓冲器(诸如hv缓冲器3601、3701或3801)提供,并且hv comp信号4011诸如在图38中所示。
[0199]
图41示出测试电路4100。测试电路4100包括高电压发射器4101,该高电压发射器接收启用信号en。高电压发射器向nmos晶体管4102和nmos共源共栅晶体管4103提供高电压启用信号。nmos晶体管4102的一个端子连接到外部测试焊盘,并且nmos晶体管4103的一个端子耦接到vmm系统3400内的内部节点。该电路可例如在电压校准过程期间使用。
[0200]
图42示出高电压生成块3412的实施方案,该高电压生成块此处包括高电压生成电路4200、控制逻辑块4201、模拟电路块4202和测试块4203。高电压生成电路4200包括电荷泵和调节器4204、高电压增量器4205和高电压运算放大器4206。可基于发送至高电压增量器4205中的晶体管的微调信号来控制高电压增量器4205的输出的电压,如将在下文中进一步说明。控制逻辑块4201接收控制逻辑输入并且生成控制逻辑输出。模拟电路块4202包括电流偏置发生器4207,该电流偏置发生器用于接收参考电压vref,并且生成可用于施加在其他地方使用的偏置信号ibias的电流。模拟电路块4202还包括电压发生器4208,该电压发生器用于接收一组微调位trbit_wl,并且在各种操作期间生成施加到字线的电压。测试块4203在测试焊盘monhv_pad上接收信号,并且输出各种信号以供在测试期间监视。
[0201]
图43示出高电压生成块3412的另一实施方案。此处,高电压生成块包括电荷泵和调节器4301、高电压(hv)增量器4303和高电压运算放大器4302。可基于发送至高电压增量器4303中的晶体管的栅极的信号来控制高电压增量器4303的输出的电压。hv增量器4303包括电阻器串4315i,该电阻器串从地串联连接到电荷泵4301的输出。开关4310a,4310b,,,,4310z的网络用于以增量方式多路复用输出沿着串的电压电平。晶体管的栅极由高电压电平位移器(hvls)4320启用/禁用,该hvls继而由数字控制输入启用/禁用。hvls 4320用于将数字电压电平(例如,1v)转换为高电压电平(例如,12v)。例如,电阻器串4315i将提供从3v到10v的电压电平,其中电压增量为10mv(跨一个电阻器的电压)。因此,电阻器串的输出vhvrout将具有从3v到10v的值,其中增量为10mv。hv运算放大器4302用于缓冲该vhvrout增量电压。由于在最高电压(例如,10v)下需要hv电压,pmos开关处于或接近该值时会出现与接近击穿(bv)条件相关联的泄漏。这会影响小增量电压(例如,10mv)的准确性。因此,需要改进以克服这种bv泄漏。首先,根据pmos开关的位置分接hvls电路的电源。例如,对于4v
‑
6v串位置处的pmos开关,hvls的高电源为6v(而不是更典型的12v电源)。此外,低电源可为4v(而不是更典型的接地值)。这将降低在该电阻器串位置处跨pmos开关的电压应力。对于连接到vhvrout的pmos开关,需要具有自适应hv偏置的两个串联的pmos开关来禁用相应的多路复用路径以避免bv应力,例如示出了pmos 4310e/4310f和4310y/4310z。pmos 4310f和4310z用于多路复用路径禁用。例如,pmos 4310f和4310z的栅极处于高电压(例如,10v)以禁用10v多路复用路径。在关断条件下,pmos 4310e的栅极优选地处于约6v,以用于共源共栅以减少bv泄漏,并且pmos4310f的栅极处于10v。在导通状态下,pmos 4310f的栅极可处于约6v并且pmos 4310f的栅极可处于<6v,以从相应串到vhvrout传递8v
‑
10v(作为示例)多路
复用路径。在关断条件下,pmos 4310y的栅极处于约6v以用于共源共栅以减少bv泄漏,并且pmos 4310z的栅极处于10v。在导通条件下,pmos 4310y的栅极可处于0v并且pmos 4310z的栅极可处于0v,以从串到vhvrout传递3v
‑
5v(作为示例)多路复用路径。
[0202]
图44示出高电压生成块3412的另一实施方案。高电压生成块3412包括高电压运算放大器4403、sc(开关电容)网络4402和sc网络4401。sc网络4402包括可调电容器4404。sc网络4401包括开关4405、4407、4408和4409以及可调电容器4406。将需要在hv电平(例如,10v
‑
13v)下操作的高电压电平位移器(hvls)电路来调整sc网络4402的电容器4404。sc网络4401需要io电压(例如,1.8v、2.5v)或内核电压(例如,1.2v)开关电路。
[0203]
图45示出高电压运算放大器4500,该高电压运算放大器可用于图44中的高电压运算放大器4403。高电压运算放大器4500包括所示布置中示出的部件。hv共源共栅偏置节点vcasp、vcasn1和vcasn2以自适应方式实现,使得电压值取决于输出电压vout以使跨晶体管的最大应力电压降最小化。例如,当节点电压vout为高时,vcasn2为高并且vcasn1为低。
[0204]
图46示出高电压运算放大器4600,该高电压运算放大器可用于图44中的高电压运算放大器4403。高电压运算放大器4600包括所示布置中示出的部件。hv共源共栅偏置节点vcasn2a和vcasn2b被实现为使得电压值取决于输出电压vout以跨晶体管的最大电压降最小化。例如,当节点电压vout为高时,vcasn1b和vcas2b为高。
[0205]
图47示出自适应高电压源4700,该自适应高电压源可用于为图44中的高电压运算放大器4403提供自适应高电压共源共栅偏置。自适应高电压源4700包括所示布置中示出的部件。
[0206]
图48示出列驱动器4800,该列驱动器可用于位线驱动器3411中的每个位线驱动器。在所示配置中,列驱动器4800包括锁存器4801、反相器4802、或非门4803、pmos晶体管4804、nmos晶体管4805和4806以及读出放大器4807。如图所示,vcasa电平在较高电平下跟踪vin,即=~vin 2*vt_pmos。vcasb电平在较低电平下跟踪vin,即=~vin
‑
v*vt_nmos。对于不同的mos晶体管和不同的i*r电压降(诸如将电阻r插入电流路径中),其他值是可能的。
[0207]
图49示出读出放大器4900,该读出放大器可用于图48中的读出放大器4807。在所示配置中,读出放大器4900包括可调电流参考源4901、开关4902、nmos晶体管4903、电容器4904、开关4905、电流源4906和反相器4907。读出放大器4907耦接到vmm阵列3408中的存储器单元4908。
[0208]
图50示出参考阵列电路5000,该参考阵列电路包括位线参考解码器5001和参考单元50010至5002
n
。
[0209]
图51示出参考阵列电路5100,该参考阵列电路包括位线参考解码器5101和参考单元51020至5100
n
。
[0210]
精密编程电路和算法
[0211]
图52示出用于为hv运算放大器4403提供电压的自适应高电压源5200,该自适应高电压源包括运算放大器5201、电阻器5203和可变电阻器5202(其可为低电压域可变电阻器)。自适应高电压源5200接收输入v
in
并生成高电压信号hv
out
,其中可通过由电阻微调电路网络(未示出)调整可变电阻器5202的电阻来调整增益。在一个实施方案中,电阻器5203处于低电压域(例如,1v或1.8v)中并且使用低电压设备和运算放大器5201,并且具有微调电路网络的可变电阻器5202处于高电压域(例如,12v)中并且使用高电压设备。然后,可使用
hv
out
对非易失性存储器单元进行编程。
[0212]
图53示出用于为hv运算放大器3403提供电压的自适应高电压源5300,该自适应高电压源包括运算放大器5301、可变电阻器5303和电阻器5302。自适应高电压源5300接收输入v
in
并生成高电压信号hv
out
,其中可通过电阻微调电路网络(未示出)调整可变电阻器5303的电阻来调整增益。在一个实施方案中,可变电阻器5303和微调电路网络处于低电压域(例如,1v或1.8v)中并使用低电压设备,并且运算放大器5301和电阻器5302处于高电压域(例如,12v)中并使用高电压设备。然后,可使用hv
out
对非易失性存储器单元进行编程。
[0213]
图54示出用于为hv运算放大器4403提供电压的自适应高电压源5400,该自适应高电压源包括运算放大器5401、电阻器5402、电阻器5403、运算放大器5404和可调分压器5405。可调分压器5405接收电压源v
s
并且包括电阻器5408以及电阻器5406i和开关5407i的i组。由可调分压器5405输出的电压(其也为运算放大器5404的非反相端子上的输入电压并且为输入电压v
in
)将根据开关5407i中的哪个开关闭合而变化。响应于输入v
in
,生成高电压信号hv
out
。此处,可通过可调分压器5405调整v
in
的量值。在一个实施方案中,可调分压器5405和运算放大器5404为低电压域(例如,1v或1.8v)并且使用低电压设备,并且运算放大器5401为高电压域(例如,12v)并且使用高电压设备。然后,可使用hv
out
对非易失性存储器单元进行编程。
[0214]
图55示出用于为hv运算放大器4403提供电压的自适应高电压源5500,该自适应高电压源包括可调分压器5505和细电阻器hv网络5580。细电阻器hv网络5580包括缓冲器5501、缓冲器5502、可调分压器5503,该可调分压器包括电阻器5504j和开关5504j的j组。可调分压器5505接收电压源v
s
并且包括电阻器4408以及电阻器5506i和开关网络5507i的i组。由可调分压器5505输出的电压将根据开关网络5507i的开关中的哪个开关闭合而变化。可调分压器5503接收高电压hv_coarse 1和hv_coarse 2。高电压hv_coarse 1进一步为自适应高电压源5500的第一输出。由可调分压器5503输出的电压(其为hv_fine)将根据hv_coarse以及开关网络5504j的开关中的哪个开关闭合而变化。此处,可通过改变在可调分压器5505中闭合的开关网络5507i的开关来调整hv_coarse1/2的量值。可通过改变在可调分压器5503中闭合的开关网络5504j的开关来调整hv_fine的量值。作为数值示例,可调分压器5505可每步提供200mv(即,电压增量、跨一个电阻器5506的电压),跨hv_coarse 1和hv_coarse 2的电压为600mv,可调分压器5503可每步提供5mv(即,电压增量、跨一个电阻器5504j的电压)。可使用这些高电压对非易失性存储器单元进行编程。
[0215]
图56示出用于为hv运算放大器4403提供电压的自适应高电压源5600,该自适应高电压源包括粗sc(开关电容)网络5650和细电阻器hv网络5680。粗sc网络5650包括运算放大器5601、sc网络5609和sc网络5608。sc网络5609包括电容cfb的可调电容器5602。sc网络5608包括电容cin的可调电容器5603以及开关5604、5605、5606和5607。此处,hv
out
=v*(cin/cfb)。细电阻器hv网络5680类似于图55中的网络5580。粗sc网络5650提供粗可调电平(例如,200mv阶跃),并且细电阻器hv网络5680提供细电平(例如,5mv阶跃)。hv
out
可用于对非易失性存储器单元进行编程。
[0216]
如图52、图43、图52至图56所示的hv运算放大器5403的自适应hv电源用于根据输出电压来优化功率。vhvopa=vout dv,例如,vhvopa=6v,其中vout=4v并且dv=2v。基本上,hvopa 4403不需要始终被提供最大hv电压(例如,12v)。
[0217]
图57示出仅使用一个单电平参考实现的修改的sar(逐次逼近)顺序验证算法5700,这简化了硬件具体实施。该图示出了4位验证算法,该4位验证算法用于将单元输出转换成4个输出数字位以与4个输入数字位进行比较。通过在参考线上应用中间参考值并比较单元输出与参考电平来首先转换最高有效位dout3。下一有效位dout2接下来通过在上半部(即从l8到l15)应用中间参考值并比较单元输出与中间参考电平,然后在下半部(即从l7到l0)应用中间参考值并比较单元输出与中间参考电平来转换。接下来的数字位以类似方式转换。对于4位输出,该方法需要15个转换脉冲(阶跃)。单元输出是从存储器单元中存储的权重转换而来的电流或电压。
[0218]
图58示出使用两个参考线且转换脉冲数减半的修改的sar顺序验证算法5800。最高有效位如上所述使用单个参考线来完成。接下来的顺序转换步骤使用两个参考线。对于每个参考线,转换步骤与上文相似。对于4位输出,该方法将需要8个步骤。
[0219]
上述验证算法可用于将神经元电流(来自vmm阵列的输出电流)转换成数字位。
[0220]
图59示出在非易失性存储器单元的编程操作之后的验证操作期间使用的可调2d温度计代码参考电流源5900。2d温度计代码参考电流源5900包括缓冲镜5901(该缓冲镜包括运算放大器5902和pmos晶体管5903)、可调偏置源5904和2d阵列5905,该2d阵列包括设备5906的i行和j列的阵列,其中特定设备5906由标签5906
‑
(行)(列)标注。此处,可激活设备5906的各种组合,使得可调整由缓冲镜5901输出的参考电流的量。如图所示,2d阵列5905中存在16个电流镜(设备5906)。可调2d温度计代码参考电流源5900基本上将4数字输入代码转换成参考电流偏置,该参考电流偏置的值为从偏置源5904提供的ibiasunit的1至16倍。例如,这些值对应于诸如图58所示的vmm阵列中的存储器单元的16个电平。
[0221]
例如,偏置源5904可提供1na的电流ibiasunit,该电流被镜像到设备5906中。此处,第一行由设备5906
‑
11至5906
‑
1j组成,并且从左到右顺序地启用,一次启用一个设备5906。然后从左到右以顺序方式启用下一行以添加到第一行,这意味着启用5个,然后6个,然后7个,然后8个设备5906。因此,通过顺序地启用设备5906,可避免与常规二进制解码相关联的晶体管失配情况。启用的设备5906的总和然后由缓冲镜5901镜像并作为可调电流输出,该可调电流可用于图39中的可调电流参考源3901。偏置源5904可提供可微调的单位偏置范围,诸如50pa/100pa/200pa/../100na。所示的可调4x4 2d温度计代码参考电流源5900可为任何其他尺寸,诸如32x32或8x32。
[0222]
图60示出参考子电路6000,该参考子电路可用于图59中的设备5906。参考子电路6000包括如图所示配置的nmos晶体管6001和6002。晶体管6002为电流镜偏置晶体管,并且晶体管6001为启用晶体管(以使偏置晶体管6002能够连接到输出节点output)。
[0223]
应当指出,如本文所用,术语“在
…
上方”和“在
…
上”两者包容地包含“直接在
…
上”(之间未设置中间材料、元件或空间)和“间接在
…
上”(之间设置有中间材料、元件或空间)。类似地,术语“相邻”包括“直接相邻”(之间没有设置中间材料、元件或空间)和“间接相邻”(之间设置有中间材料、元件或空间),“安装到”包括“直接安装到”(之间没有设置中间材料、元件或空间)和“间接安装到”(之间设置有中间材料、元件或空间),并且“电耦接至”包括“直接电耦接至”(之间没有将元件电连接在一起的中间材料或元件)和“间接电耦接至”(之间有将元件电连接在一起的中间材料或元件)。例如,“在衬底上方”形成元件可包括在两者间没有中间材料/元件的情况下在衬底上直接形成元件,以及在两者间有一个或多
个中间材料/元件的情况下在衬底上间接形成元件。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。