1.本发明涉及互联网云计算技术领域,特别涉及一种云定制招聘会方法及系统。
背景技术:
2.目前,企业报名参加一个招聘会,不能提前知道来参加招聘会的求职者都有谁,无法掌握参加招聘会的求职者信息,这样的话,对于企业来说,参加招聘会是盲目的,无法判断参加招聘会的求职者中是否存在企业需要的人才,招聘人才的效果就难以预测和掌握,企业也不能准确判断是否需要参加招聘会,同时,求职者报名参加一个招聘会,只能得到招聘会的有哪些企业参加,需要自己一个个查找企业的相关信息,十分麻烦,也不能准确判断是否需要参加招聘会。
技术实现要素:
3.本发明目的之一在于提供了一种云定制招聘会方法及系统,通过云端服务器实现了求职者与招聘企业的信息对接,可以帮助招聘企业提前掌握参加招聘会的求职者信息,准确判断参加招聘会的求职者中是否存在企业需要的人才,预测参加招聘会的招聘人才效果,从而帮助企业判断是否需要参加招聘会,增加了企业了解人才情况的便利性,也可以帮助求职者提前了解适合自己的企业信息,增加了求职者了解企业的便利性。
4.本发明实施例提供的一种云定制招聘会方法,应用于云端服务器,通过云端服务器执行如下操作:
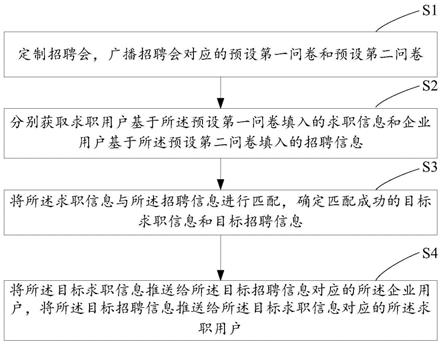
5.定制招聘会,广播招聘会对应的预设第一问卷和预设第二问卷;
6.分别获取求职用户基于预设第一问卷填入的求职信息和企业用户基于预设第二问卷填入的招聘信息;
7.将求职信息与招聘信息进行匹配,确定匹配成功的目标求职信息和目标招聘信息;
8.将目标求职信息推送给目标招聘信息对应的企业用户,将目标招聘信息推送给目标求职信息对应的求职用户。
9.优选的,将求职信息与招聘信息进行匹配,包括:
10.获取预设的匹配任务集合,从匹配任务集合中选取任一匹配任务;
11.通过预设的多个获取路径分别获取重要性数据,整合各重要性数据,获得重要性大数据;
12.基于重要性大数据确定匹配任务的重要值;
13.将匹配任务集合中各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;
14.按预设顺序从目标匹配任务集合中选取目标匹配任务;
15.分别提取求职信息中与目标匹配任务对应的第一待匹配信息和招聘信息中与目标匹配任务对应的第二待匹配信息;
16.基于信息匹配技术将第一待匹配信息和第二待匹配信息进行匹配,获得第一匹配值;
17.若第一匹配值大于等于预设的匹配值阈值,则目标匹配任务的执行结果为匹配成功,否则为匹配失败;
18.若目标匹配任务集合中前预设个数的目标匹配任务的执行结果均为匹配成功,则求职信息和招聘信息匹配成功,否则匹配失败。
19.优选的,基于重要性大数据确定匹配任务的重要值,包括:
20.对重要性大数据进行预处理,获得目标大数据;
21.确定目标大数据中与匹配任务相关联的关联数据;
22.确定关联数据在目标大数据中所占的比例;
23.将比例作为匹配任务的重要值。
24.优选的,对重要性大数据进行预处理,包括;
25.对重要性大数据进行解析,获得多个目标数据以及与目标数据一一对应的多个获取节点;
26.通过每个获取节点获取验证数据,整合各验证数据获得验证大数据,验证大数据包括:发布目标数据的用户在历史上发布的多个历史数据;
27.确定用户发布目标数据的目标时刻;
28.确定验证大数据中用户在目标时刻前预设时间段内发布的多个历史数据,并将其整合成第一历史大数据;
29.确定验证大数据中用户在目标时刻后预设时间段内发布的多个历史数据,并将其整合成第二历史大数据;
30.基于语义识别技术对第一历史大数据进行识别,获得多个第一语义特征,并基于各第一语义特征构建第一语义特征数据库;
31.基于语义识别技术对第二历史大数据进行识别,获得多个第二语义特征,并基于各第二语义特征构建第二语义特征数据库;
32.基于语义识别技术对目标数据进行识别,获得第三语义特征;
33.将第三语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第一个数;
34.将第三语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第二个数;
35.基于预设的转换规则将第三语义特征转换成多个否定语义特征和类否定语义特征,否定语义特征和类否定语义特征按否定程度等级划分;
36.将每个否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第三个数;
37.将每个否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第四个数;
38.将每个类否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第五个数;
39.将每个类否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定
匹配成功的第二语义特征的第六个数;
40.基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,计算公式如下:
[0041][0042][0043][0044]
其中,γ为判定指数,α1为第一个数,α2为第二个数,α
3,i
为第一语义特征数据库中与第i个否定语义特征匹配成功的第一语义特征的第三个数,α
4,i
为第二语义特征数据库中与第i个否定语义特征匹配成功的第二语义特征的第四个数,α
5,i
为第一语义特征数据库中与第i个类否定语义特征匹配成功的第一语义特征的第五个数,α
6,i
为第二语义特征数据库中与第i个类否定语义特征匹配成功的第二语义特征的第六个数,σ
1,i
为第i个否定语义特征对应的否定程度等级,σ
2,i
为第i个类否定语义特征对应的否定程度等级,n1为否定语义特征的总数目,n2为类否定语义特征的总数目,x1为第一语义特征数据库中的第一语义特征的总数目,x2为第二语义特征数据库中的第二语义特征的总数目,μ1和μ2为预设的权重值,θ1和θ2为中间变量;
[0045]
若判定指数小于等于预设的判定指数阈值,从重要性大数据中剔除目标数据;
[0046]
当需要剔除的目标数据全部剔除后,完成预处理。
[0047]
优选的,将求职信息与招聘信息进行匹配之前,对求职信息和招聘信息进行预处理;
[0048]
其中,对求职信息和招聘信息进行预处理,包括:
[0049]
获取求职用户的第一参会信息,第一参会信息包括:历史上求职用户参见招聘会的第一记录;
[0050]
获取企业用户的第二参会信息,第二参会信息包括:历史上企业用户参加招聘会的第二记录;
[0051]
确定第一记录和第二记录中具有相同记录的第七个数;
[0052]
基于第七个数计算屏蔽指数,计算公式如下:
[0053][0054]
其中,β为屏蔽指数,d1为第一参会信息中第一记录的总数目,d2为第二参会信息中第二记录的总数目,z为第七个数;
[0055]
若屏蔽指数大于等于预设的屏蔽指数阈值时,不进行对应求职信息和招聘信息之
间的匹配。
[0056]
本发明实施例提供的一种云定制招聘会系统,应用于云端服务器,云端服务器包括:
[0057]
定制与广播模块,用于定制招聘会,广播招聘会对应的预设第一问卷和预设第二问卷;
[0058]
获取模块,用于分别获取求职用户基于预设第一问卷填入的求职信息和企业用户基于预设第二问卷填入的招聘信息;
[0059]
匹配模块,用于将求职信息与招聘信息进行匹配,确定匹配成功的目标求职信息和目标招聘信息;
[0060]
推送模块,用于将目标求职信息推送给目标招聘信息对应的企业用户,将目标招聘信息推送给目标求职信息对应的求职用户。
[0061]
优选的,匹配模块执行如下操作:
[0062]
获取预设的匹配任务集合,从匹配任务集合中选取任一匹配任务;
[0063]
通过预设的多个获取路径分别获取重要性数据,整合各重要性数据,获得重要性大数据;
[0064]
基于重要性大数据确定匹配任务的重要值;
[0065]
将匹配任务集合中各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;
[0066]
按预设顺序从目标匹配任务集合中选取目标匹配任务;
[0067]
分别提取求职信息中与目标匹配任务对应的第一待匹配信息和招聘信息中与目标匹配任务对应的第二待匹配信息;
[0068]
基于信息匹配技术将第一待匹配信息和第二待匹配信息进行匹配,获得第一匹配值;
[0069]
若第一匹配值大于等于预设的匹配值阈值,则目标匹配任务的执行结果为匹配成功,否则为匹配失败;
[0070]
若目标匹配任务集合中前预设个数的目标匹配任务的执行结果均为匹配成功,则求职信息和招聘信息匹配成功,否则匹配失败。
[0071]
优选的,匹配模块执行如下操作:
[0072]
对重要性大数据进行预处理,获得目标大数据;
[0073]
确定目标大数据中与匹配任务相关联的关联数据;
[0074]
确定关联数据在目标大数据中所占的比例;
[0075]
将比例作为匹配任务的重要值。
[0076]
优选的,匹配模块执行如下操作:
[0077]
对重要性大数据进行解析,获得多个目标数据以及与目标数据一一对应的多个获取节点;
[0078]
通过每个获取节点获取验证数据,整合各验证数据获得验证大数据,验证大数据包括:发布目标数据的用户在历史上发布的多个历史数据;
[0079]
确定用户发布目标数据的目标时刻;
[0080]
确定验证大数据中用户在目标时刻前预设时间段内发布的多个历史数据,并将其
整合成第一历史大数据;
[0081]
确定验证大数据中用户在目标时刻后预设时间段内发布的多个历史数据,并将其整合成第二历史大数据;
[0082]
基于语义识别技术对第一历史大数据进行识别,获得多个第一语义特征,并基于各第一语义特征构建第一语义特征数据库;
[0083]
基于语义识别技术对第二历史大数据进行识别,获得多个第二语义特征,并基于各第二语义特征构建第二语义特征数据库;
[0084]
基于语义识别技术对目标数据进行识别,获得第三语义特征;
[0085]
将第三语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第一个数;
[0086]
将第三语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第二个数;
[0087]
基于预设的转换规则将第三语义特征转换成多个否定语义特征和类否定语义特征,否定语义特征和类否定语义特征按否定程度等级划分;
[0088]
将每个否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第三个数;
[0089]
将每个否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第四个数;
[0090]
将每个类否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第五个数;
[0091]
将每个类否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第六个数;
[0092]
基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,计算公式如下:
[0093][0094][0095][0096]
其中,γ为判定指数,α1为第一个数,α2为第二个数,α
3,i
为第一语义特征数据库中与第i个否定语义特征匹配成功的第一语义特征的第三个数,α
4,i
为第二语义特征数据库中与第i个否定语义特征匹配成功的第二语义特征的第四个数,α
5,i
为第一语义特征数据库中与第i个类否定语义特征匹配成功的第一语义特征的第五个数,α
6,i
为第二语义特征数据库中与第i个类否定语义特征匹配成功的第二语义特征的第六个数,σ
1,i
为第i个否定语义特
征对应的否定程度等级,σ
2,i
为第i个类否定语义特征对应的否定程度等级,n1为否定语义特征的总数目,n2为类否定语义特征的总数目,x1为第一语义特征数据库中的第一语义特征的总数目,x2为第二语义特征数据库中的第二语义特征的总数目,μ1和μ2为预设的权重值,θ1和θ2为中间变量;
[0097]
若判定指数小于等于预设的判定指数阈值,从重要性大数据中剔除目标数据;
[0098]
当需要剔除的目标数据全部剔除后,完成预处理。
[0099]
优选的,云端服务器还包括:
[0100]
预处理模块,用于在将求职信息与招聘信息进行匹配之前,对求职信息和招聘信息进行预处理;
[0101]
预处理模块执行如下操作:
[0102]
获取求职用户的第一参会信息,第一参会信息包括:历史上求职用户参见招聘会的第一记录;
[0103]
获取企业用户的第二参会信息,第二参会信息包括:历史上企业用户参加招聘会的第二记录;
[0104]
确定第一记录和第二记录中具有相同记录的第七个数;
[0105]
基于第七个数计算屏蔽指数,计算公式如下:
[0106][0107]
其中,β为屏蔽指数,d1为第一参会信息中第一记录的总数目,d2为第二参会信息中第二记录的总数目,z为第七个数;
[0108]
若屏蔽指数大于等于预设的屏蔽指数阈值时,不进行对应求职信息和招聘信息之间的匹配。
[0109]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
[0110]
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
[0111]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0112]
图1为本发明实施例中一种云定制招聘会方法的流程图;
[0113]
图2为本发明实施例中一种云定制招聘会系统的示意图。
具体实施方式
[0114]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0115]
本发明实施例提供了一种云定制招聘会方法,应用于云端服务器,如图1所示,通过云端服务器执行如下操作:
[0116]
s1、定制招聘会,广播招聘会对应的预设第一问卷和预设第二问卷;
[0117]
s2、分别获取求职用户基于预设第一问卷填入的求职信息和企业用户基于预设第二问卷填入的招聘信息;
[0118]
s3、将求职信息与招聘信息进行匹配,确定匹配成功的目标求职信息和目标招聘信息;
[0119]
s4、将目标求职信息推送给目标招聘信息对应的企业用户,将目标招聘信息推送给目标求职信息对应的求职用户。
[0120]
上述技术方案的工作原理及有益效果为:
[0121]
定制招聘会(例如:时间、地点和面试方式),广播招聘会对应的预设第一问卷(供求职者填写的问卷,包含多个填写项,例如:姓名、年龄、学历、爱好、家庭背景、工作经验等)和预设第二问卷(供企业hr填写的问卷,包含多个填写项,例如:年龄要求、学历要求和工作经验要求等);各用户通过上网终端(手机、电脑和平板等)查看到招聘会的两份问卷,问卷上标注有招聘会的信息(时间、地点和面试方式),确认参加后,选择对应问卷进行填写即可;将求职信息和招聘信息进行匹配,确定任意一组匹配成功的目标求职信息和目标招聘信息,将目标招聘信息推送给对应求职用户,供其查看,将目标求职信息推送给对应企业用户,供其查看。
[0122]
本发明实施例通过云端服务器实现了求职者与招聘企业的信息对接,可以帮助招聘企业提前掌握参加招聘会的求职者信息,准确判断参加招聘会的求职者中是否存在企业需要的人才,预测参加招聘会的招聘人才效果,从而帮助企业判断是否需要参加招聘会,增加了企业了解人才情况的便利性,也可以帮助求职者提前了解适合自己的企业信息,增加了求职者了解企业的便利性。
[0123]
本发明实施例提供了一种云定制招聘会方法,将求职信息与招聘信息进行匹配,包括:
[0124]
获取预设的匹配任务集合,从匹配任务集合中选取任一匹配任务;
[0125]
通过预设的多个获取路径分别获取重要性数据,整合各重要性数据,获得重要性大数据;
[0126]
基于重要性大数据确定匹配任务的重要值;
[0127]
将匹配任务集合中各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;
[0128]
按预设顺序从目标匹配任务集合中选取目标匹配任务;
[0129]
分别提取求职信息中与目标匹配任务对应的第一待匹配信息和招聘信息中与目标匹配任务对应的第二待匹配信息;
[0130]
基于信息匹配技术将第一待匹配信息和第二待匹配信息进行匹配,获得第一匹配值;
[0131]
若第一匹配值大于等于预设的匹配值阈值,则目标匹配任务的执行结果为匹配成功,否则为匹配失败;
[0132]
若目标匹配任务集合中前预设个数的目标匹配任务的执行结果均为匹配成功,则求职信息和招聘信息匹配成功,否则匹配失败。
[0133]
上述技术方案的工作原理及有益效果为:
[0134]
预设的匹配任务集合具体为:多个匹配任务组成,例如:工作经验项匹配任务、学历项匹配任务和兴趣爱好项匹配任务等;预设的多个获取路径具体为:与多个论坛网站连接(例如:招聘交流论坛和hr交流论坛等),通过该获取路径可以获取重要性数据(例如:某hr交流论坛上各认证专家发表的招聘技巧文章中有关看重求职者何种信息的数据),整合(例如:按时间顺序组合)各重要性数据,获得重要性大数据;基于重要性大数据确定各匹配任务的重要值,重要值越大,说明求职者的某种信息应与企业要求相符的重要性越大,将各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;按预设顺序(优先选取靠前项)选取目标匹配任务;执行该目标匹配任务,当前预设个数(例如:8个)目标匹配任务执行结果均为匹配成功时,说明,该求职者的求职信息重要部分与企业相符,匹配成功;预设的匹配度阈值具体为:例如,95.5。
[0135]
本发明实施例在执行匹配任务时,确定各匹配任务的重要值,优先执行重要值较大的任务,当重要值靠前的匹配任务执行结果均为匹配成功时,就能说明求职者的求职信息重要部分与企业相符,无需继续执行其余重要值较低的匹配任务,提升了系统的工作效率,节省了大量时间。
[0136]
本发明实施例提供了一种云定制招聘会方法,基于重要性大数据确定匹配任务的重要值,包括:
[0137]
对重要性大数据进行预处理,获得目标大数据;
[0138]
确定目标大数据中与匹配任务相关联的关联数据;
[0139]
确定关联数据在目标大数据中所占的比例;
[0140]
将比例作为匹配任务的重要值。
[0141]
上述技术方案的工作原理及有益效果为:
[0142]
匹配任务对应的关联数据在目标大数据中的比例越大,说明越多用户(例如:认证专家和资深hr等)认为该匹配任务对应的信息项(例如:人生规划)与企业要求相符很重要,因此,将比例作为重要值即可。
[0143]
本发明实施例将关联数据在目标大数据中所占的比例作为重要值,设置合理。
[0144]
本发明实施例提供了一种云定制招聘会方法,对重要性大数据进行预处理,包括;
[0145]
对重要性大数据进行解析,获得多个目标数据以及与目标数据一一对应的多个获取节点;
[0146]
通过每个获取节点获取验证数据,整合各验证数据获得验证大数据,验证大数据包括:发布目标数据的用户在历史上发布的多个历史数据;
[0147]
确定用户发布目标数据的目标时刻;
[0148]
确定验证大数据中用户在目标时刻前预设时间段内发布的多个历史数据,并将其整合成第一历史大数据;
[0149]
确定验证大数据中用户在目标时刻后预设时间段内发布的多个历史数据,并将其整合成第二历史大数据;
[0150]
基于语义识别技术对第一历史大数据进行识别,获得多个第一语义特征,并基于各第一语义特征构建第一语义特征数据库;
[0151]
基于语义识别技术对第二历史大数据进行识别,获得多个第二语义特征,并基于各第二语义特征构建第二语义特征数据库;
[0152]
基于语义识别技术对目标数据进行识别,获得第三语义特征;
[0153]
将第三语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第一个数;
[0154]
将第三语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第二个数;
[0155]
基于预设的转换规则将第三语义特征转换成多个否定语义特征和类否定语义特征,否定语义特征和类否定语义特征按否定程度等级划分;
[0156]
将每个否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第三个数;
[0157]
将每个否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第四个数;
[0158]
将每个类否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第五个数;
[0159]
将每个类否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第六个数;
[0160]
基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,计算公式如下:
[0161][0162][0163][0164]
其中,γ为判定指数,α1为第一个数,α2为第二个数,α
3,i
为第一语义特征数据库中与第i个否定语义特征匹配成功的第一语义特征的第三个数,α
4,i
为第二语义特征数据库中与第i个否定语义特征匹配成功的第二语义特征的第四个数,α
5,i
为第一语义特征数据库中与第i个类否定语义特征匹配成功的第一语义特征的第五个数,α
6,i
为第二语义特征数据库中与第i个类否定语义特征匹配成功的第二语义特征的第六个数,σ
1,i
为第i个否定语义特征对应的否定程度等级,σ
2,i
为第i个类否定语义特征对应的否定程度等级,n1为否定语义特征的总数目,n2为类否定语义特征的总数目,x1为第一语义特征数据库中的第一语义特征的总数目,x2为第二语义特征数据库中的第二语义特征的总数目,μ1和μ2为预设的权重值,θ1和θ2为中间变量;
[0165]
若判定指数小于等于预设的判定指数阈值,从重要性大数据中剔除目标数据;
[0166]
当需要剔除的目标数据全部剔除后,完成预处理。
[0167]
上述技术方案的工作原理及有益效果为:
[0168]
预设时间段具体为:例如,30天;预设的转换规则具体为:例如,将目标数据“招聘求职者时,应看重其人生规划是否与公司发展规划相符”中的第三语义特征“看重人生规划”转换为多个否定语义特征“不看重人生规划”“人生规划不重要”以及多个类否定语义特征“人生规划不太重要”“人生规划还行”等,否定语义特征的否定程度等级比类否定语义特征的否定等级大;重要性大数据包含有多个目标数据(用户发布的数据)和与目标数据一一对应的多个获取节点(每个获取节点可以获取该用户在外站发布的有关看重求职者何种信息的数据,用户在注册时,不仅需提供专家证明、hr工作经验证明等,还需提供自己在外站的账户链接,例如;主页链接);第一语义特征数据库中的第一语义特征与第三语义特征匹配成功的第一个数以及第二语义特征数据库中的第二语义特征与第三语义特征匹配成功的第二个数越多,说明用户在历史上越坚定该目标数据对应观点,没有异议;第一语义特征数据库中的第一语义特征与否定语义特征匹配成功的第三个数、第一语义特征数据库中的第一语义特征与类否定语义特征匹配成功的第四个数、第二语义特征数据库中的第二语义特征与否定语义特征匹配成功的第五个数和第二语义特征数据库中的第二语义特征与类否定语义特征匹配成功的第六个数越多,说明用户在历史上越不坚定该目标数据对应观点;基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,汇总判定结果,该判定指数越大,说明用户在历史上越坚定该目标数据对应观点,当判定指数小于等于预设的判定指数阈值(例如:97)时,应当剔除对应目标数据;
[0169]
本发明实施例的目的是确定用户是否在外站发表过与在获取路径对应的网站完全不一致或近似不一致的有关看重求职者何种信息的数据,若存在,说明该用户发布的目标数据用户自己都不能着实确定,也存在乱发布数据的可能,应该剔除,提升了重要性大数据的利用价值,十分智能化,同时,通过上述公式可快速给出判定指数,将判定指数与阈值比较直接给出判定结果,大大提升了系统的工作效率。
[0170]
本发明实施例提供了一种云定制招聘会方法,将求职信息与招聘信息进行匹配之前,对求职信息和招聘信息进行预处理;
[0171]
其中,对求职信息和招聘信息进行预处理,包括:
[0172]
获取求职用户的第一参会信息,第一参会信息包括:历史上求职用户参见招聘会的第一记录;
[0173]
获取企业用户的第二参会信息,第二参会信息包括:历史上企业用户参加招聘会的第二记录;
[0174]
确定第一记录和第二记录中具有相同记录的第七个数;
[0175]
基于第七个数计算屏蔽指数,计算公式如下:
[0176][0177]
其中,β为屏蔽指数,d1为第一参会信息中第一记录的总数目,d2为第二参会信息中第二记录的总数目,z为第七个数;
[0178]
若屏蔽指数大于等于预设的屏蔽指数阈值时,不进行对应求职信息和招聘信息之间的匹配。
[0179]
上述技术方案的工作原理及有益效果为:
[0180]
第七个数越大,说明该求职信息对应的求职用户和该招聘信息对应的企业用户参见过相同招聘会的次数越多;基于第七个数计算屏蔽指数,屏蔽指数越大,说明越无需进行该求职信息和招聘信息之间的匹配;预设的屏蔽指数阈值具体为:例如,75。
[0181]
本发明实施例可以识别经常参见同一招聘会的求职用户和企业用户,不将他们的求职信息和招聘信息进行匹配,设置合理。
[0182]
本发明实施例提供了一种云定制招聘会系统,应用于云端服务器,如图2所示,云端服务器包括:
[0183]
定制与广播模块1,用于定制招聘会,广播招聘会对应的预设第一问卷和预设第二问卷;
[0184]
获取模块2,用于分别获取求职用户基于预设第一问卷填入的求职信息和企业用户基于预设第二问卷填入的招聘信息;
[0185]
匹配模块3,用于将求职信息与招聘信息进行匹配,确定匹配成功的目标求职信息和目标招聘信息;
[0186]
推送模块4,用于将目标求职信息推送给目标招聘信息对应的企业用户,将目标招聘信息推送给目标求职信息对应的求职用户。
[0187]
上述技术方案的工作原理及有益效果为:
[0188]
定制招聘会(例如:时间、地点和面试方式),广播招聘会对应的预设第一问卷(供求职者填写的问卷,包含多个填写项,例如:姓名、年龄、学历、爱好、家庭背景、工作经验等)和预设第二问卷(供企业hr填写的问卷,包含多个填写项,例如:年龄要求、学历要求和工作经验要求等);各用户通过上网终端(手机、电脑和平板等)查看到招聘会的两份问卷,问卷上标注有招聘会的信息(时间、地点和面试方式),确认参加后,选择对应问卷进行填写即可;将求职信息和招聘信息进行匹配,确定任意一组匹配成功的目标求职信息和目标招聘信息,将目标招聘信息推送给对应求职用户,供其查看,将目标求职信息推送给对应企业用户,供其查看。
[0189]
本发明实施例通过云端服务器实现了求职者与招聘企业的信息对接,可以帮助招聘企业提前掌握参加招聘会的求职者信息,准确判断参加招聘会的求职者中是否存在企业需要的人才,预测参加招聘会的招聘人才效果,从而帮助企业判断是否需要参加招聘会,增加了企业了解人才情况的便利性,也可以帮助求职者提前了解适合自己的企业信息,增加了求职者了解企业的便利性。
[0190]
本发明实施例提供了一种云定制招聘会系统,匹配模块3执行如下操作:
[0191]
获取预设的匹配任务集合,从匹配任务集合中选取任一匹配任务;
[0192]
通过预设的多个获取路径分别获取重要性数据,整合各重要性数据,获得重要性大数据;
[0193]
基于重要性大数据确定匹配任务的重要值;
[0194]
将匹配任务集合中各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;
[0195]
按预设顺序从目标匹配任务集合中选取目标匹配任务;
[0196]
分别提取求职信息中与目标匹配任务对应的第一待匹配信息和招聘信息中与目标匹配任务对应的第二待匹配信息;
[0197]
基于信息匹配技术将第一待匹配信息和第二待匹配信息进行匹配,获得第一匹配值;
[0198]
若第一匹配值大于等于预设的匹配值阈值,则目标匹配任务的执行结果为匹配成功,否则为匹配失败;
[0199]
若目标匹配任务集合中前预设个数的目标匹配任务的执行结果均为匹配成功,则求职信息和招聘信息匹配成功,否则匹配失败。
[0200]
上述技术方案的工作原理及有益效果为:
[0201]
预设的匹配任务集合具体为:多个匹配任务组成,例如:工作经验项匹配任务、学历项匹配任务和兴趣爱好项匹配任务等;预设的多个获取路径具体为:与多个论坛网站连接(例如:招聘交流论坛和hr交流论坛等),通过该获取路径可以获取重要性数据(例如:某hr交流论坛上各认证专家发表的招聘技巧文章中有关看重求职者何种信息的数据),整合(例如:按时间顺序组合)各重要性数据,获得重要性大数据;基于重要性大数据确定各匹配任务的重要值,重要值越大,说明求职者的某种信息应与企业要求相符的重要性越大,将各匹配任务基于对应重要值从大至小进行排序,获得目标匹配任务集合;按预设顺序(优先选取靠前项)选取目标匹配任务;执行该目标匹配任务,当前预设个数(例如:8个)目标匹配任务执行结果均为匹配成功时,说明,该求职者的求职信息重要部分与企业相符,匹配成功;预设的匹配度阈值具体为:例如,95.5。
[0202]
本发明实施例在执行匹配任务时,确定各匹配任务的重要值,优先执行重要值较大的任务,当重要值靠前的匹配任务执行结果均为匹配成功时,就能说明求职者的求职信息重要部分与企业相符,无需继续执行其余重要值较低的匹配任务,提升了系统的工作效率,节省了大量时间。
[0203]
本发明实施例提供了一种云定制招聘会系统,匹配模块3执行如下操作:
[0204]
对重要性大数据进行预处理,获得目标大数据;
[0205]
确定目标大数据中与匹配任务相关联的关联数据;
[0206]
确定关联数据在目标大数据中所占的比例;
[0207]
将比例作为匹配任务的重要值。
[0208]
上述技术方案的工作原理及有益效果为:
[0209]
匹配任务对应的关联数据在目标大数据中的比例越大,说明越多用户(例如:认证专家和资深hr等)认为该匹配任务对应的信息项(例如:人生规划)与企业要求相符很重要,因此,将比例作为重要值即可。
[0210]
本发明实施例将关联数据在目标大数据中所占的比例作为重要值,设置合理。
[0211]
本发明实施例提供了一种云定制招聘会系统,匹配模块3执行如下操作:
[0212]
对重要性大数据进行解析,获得多个目标数据以及与目标数据一一对应的多个获取节点;
[0213]
通过每个获取节点获取验证数据,整合各验证数据获得验证大数据,验证大数据包括:发布目标数据的用户在历史上发布的多个历史数据;
[0214]
确定用户发布目标数据的目标时刻;
[0215]
确定验证大数据中用户在目标时刻前预设时间段内发布的多个历史数据,并将其整合成第一历史大数据;
[0216]
确定验证大数据中用户在目标时刻后预设时间段内发布的多个历史数据,并将其整合成第二历史大数据;
[0217]
基于语义识别技术对第一历史大数据进行识别,获得多个第一语义特征,并基于各第一语义特征构建第一语义特征数据库;
[0218]
基于语义识别技术对第二历史大数据进行识别,获得多个第二语义特征,并基于各第二语义特征构建第二语义特征数据库;
[0219]
基于语义识别技术对目标数据进行识别,获得第三语义特征;
[0220]
将第三语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第一个数;
[0221]
将第三语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第二个数;
[0222]
基于预设的转换规则将第三语义特征转换成多个否定语义特征和类否定语义特征,否定语义特征和类否定语义特征按否定程度等级划分;
[0223]
将每个否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第三个数;
[0224]
将每个否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第四个数;
[0225]
将每个类否定语义特征与第一语义特征数据库中的第一语义特征进行匹配,确定匹配成功的第一语义特征的第五个数;
[0226]
将每个类否定语义特征与第二语义特征数据库中的第二语义特征进行匹配,确定匹配成功的第二语义特征的第六个数;
[0227]
基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,计算公式如下:
[0228][0229][0230][0231]
其中,γ为判定指数,α1为第一个数,α2为第二个数,α
3,i
为第一语义特征数据库中与第i个否定语义特征匹配成功的第一语义特征的第三个数,α
4,i
为第二语义特征数据库中与第i个否定语义特征匹配成功的第二语义特征的第四个数,α
5,i
为第一语义特征数据库中与第i个类否定语义特征匹配成功的第一语义特征的第五个数,α
6,i
为第二语义特征数据库中与第i个类否定语义特征匹配成功的第二语义特征的第六个数,σ
1,i
为第i个否定语义特征对应的否定程度等级,σ
2,i
为第i个类否定语义特征对应的否定程度等级,n1为否定语义
特征的总数目,n2为类否定语义特征的总数目,x1为第一语义特征数据库中的第一语义特征的总数目,x2为第二语义特征数据库中的第二语义特征的总数目,μ1和μ2为预设的权重值,θ1和θ2为中间变量;
[0232]
若判定指数小于等于预设的判定指数阈值,从重要性大数据中剔除目标数据;
[0233]
当需要剔除的目标数据全部剔除后,完成预处理。
[0234]
上述技术方案的工作原理及有益效果为:
[0235]
预设时间段具体为:例如,30天;预设的转换规则具体为:例如,将目标数据“招聘求职者时,应看重其人生规划是否与公司发展规划相符”中的第三语义特征“看重人生规划”转换为多个否定语义特征“不看重人生规划”“人生规划不重要”以及多个类否定语义特征“人生规划不太重要”“人生规划还行”等,否定语义特征的否定程度等级比类否定语义特征的否定等级大;重要性大数据包含有多个目标数据(用户发布的数据)和与目标数据一一对应的多个获取节点(每个获取节点可以获取该用户在外站发布的有关看重求职者何种信息的数据,用户在注册时,不仅需提供专家证明、hr工作经验证明等,还需提供自己在外站的账户链接,例如;主页链接);第一语义特征数据库中的第一语义特征与第三语义特征匹配成功的第一个数以及第二语义特征数据库中的第二语义特征与第三语义特征匹配成功的第二个数越多,说明用户在历史上越坚定该目标数据对应观点,没有异议;第一语义特征数据库中的第一语义特征与否定语义特征匹配成功的第三个数、第一语义特征数据库中的第一语义特征与类否定语义特征匹配成功的第四个数、第二语义特征数据库中的第二语义特征与否定语义特征匹配成功的第五个数和第二语义特征数据库中的第二语义特征与类否定语义特征匹配成功的第六个数越多,说明用户在历史上越不坚定该目标数据对应观点;基于第一个数、第二个数、第三个数、第四个数、第五个数和第六个数计算判定指数,汇总判定结果,该判定指数越大,说明用户在历史上越坚定该目标数据对应观点,当判定指数小于等于预设的判定指数阈值(例如:97)时,应当剔除对应目标数据;
[0236]
本发明实施例的目的是确定用户是否在外站发表过与在获取路径对应的网站完全不一致或近似不一致的有关看重求职者何种信息的数据,若存在,说明该用户发布的目标数据用户自己都不能着实确定,也存在乱发布数据的可能,应该剔除,提升了重要性大数据的利用价值,十分智能化,同时,通过上述公式可快速给出判定指数,将判定指数与阈值比较直接给出判定结果,大大提升了系统的工作效率。
[0237]
本发明实施例提供了一种云定制招聘会系统,云端服务器还包括:
[0238]
预处理模块,用于在将求职信息与招聘信息进行匹配之前,对求职信息和招聘信息进行预处理;
[0239]
预处理模块执行如下操作:
[0240]
获取求职用户的第一参会信息,第一参会信息包括:历史上求职用户参见招聘会的第一记录;
[0241]
获取企业用户的第二参会信息,第二参会信息包括:历史上企业用户参加招聘会的第二记录;
[0242]
确定第一记录和第二记录中具有相同记录的第七个数;
[0243]
基于第七个数计算屏蔽指数,计算公式如下:
[0244][0245]
其中,β为屏蔽指数,d1为第一参会信息中第一记录的总数目,d2为第二参会信息中第二记录的总数目,z为第七个数;
[0246]
若屏蔽指数大于等于预设的屏蔽指数阈值时,不进行对应求职信息和招聘信息之间的匹配。
[0247]
上述技术方案的工作原理及有益效果为:
[0248]
第七个数越大,说明该求职信息对应的求职用户和该招聘信息对应的企业用户参见过相同招聘会的次数越多;基于第七个数计算屏蔽指数,屏蔽指数越大,说明越无需进行该求职信息和招聘信息之间的匹配;预设的屏蔽指数阈值具体为:例如,75。
[0249]
本发明实施例可以识别经常参见同一招聘会的求职用户和企业用户,不将他们的求职信息和招聘信息进行匹配,设置合理。
[0250]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。