1.本发明涉及血压预测方法技术领域,具体为一种黏菌优化算法的心血管疾病的识别模型的建立方法。
背景技术:
2.在心血管系统中,微循环为血液和组织之间的物质交换提供了重要场所,是血液从动脉流入静脉的唯一途径。根据临床研究表明,指端微循环(或甲襞微循环)的血流变化能够反映心脏、动脉等心血管系统中重要组成部分的状态,该微循环的状态也与心血管疾病之间存在较明显的联系。
3.微循环是一个复杂的系统,不同人体的微循环状态具有较大的不确定性,所建立的模型可能无法完全模拟微循环的结构,因此可能会在模型参数进行估计时出现多个局部最优解,而导致识别模型存在较大的识别误差。因此我们对此做出改进,提出一种黏菌优化算法的心血管疾病的识别模型的建立方法。
技术实现要素:
4.为了解决上述技术问题,本发明提供了如下的技术方案:
5.本发明黏菌优化算法的心血管疾病的识别模型的建立方法包括以下几个步骤:
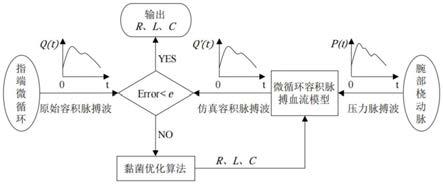
6.步骤1,采集腕部压力脉搏波和指端容积脉搏波;
7.步骤2,建立指端微循环的容积脉搏血流模型;
8.步骤3,将腕部压力脉搏波和指端容积脉搏波分别作为容积脉搏血流模型的实际输入和期望输出,然后运用黏菌优化算法降低模型参数的不确定性,估计得得到容积脉搏血流模型的最终参数,实现了微循环生理状态信息的提取;
9.步骤4,然后基于机器学习算法建立心血管疾病的识别模型,以此判断心血管的健康状态。
10.3、作为本发明的一种优选技术方案,所述建立指端微循环的容积脉搏血流模型的方法是,建立心血管仿真的电网络模型,
11.电感l表示血液在微循环中流动变化的难易程度,代表血液在微小动脉中的流动惯性;电容c表示微循环内血管总体积随血液压力p的变化率,代表了微循环的总体顺应性;电阻r表示血液在循环中流动时受到的全部阻力;
12.根据该模型,可建立如下数学表达式:
[0013][0014]
整理得模型方程为:
[0015][0016]
为获得模型的参数值,应用黏菌优化算法在设定的参数范围内求解最佳r、l、c值。
[0017]
作为本发明的一种优选技术方案,所述应用黏菌优化算法在设定的参数范围内求解最佳r、l、c值的方法是,其寻找r、l、c值位置的具体步骤如下:
[0018]
步骤1,设定种群的初始值;
[0019]
步骤2,计算当前的适应度值,并进行排序;
[0020]
步骤3、对种群的位置进行更新;
[0021]
步骤4、再次计算适应度值,并更新种群中的最优位置;
[0022]
步骤/5、对寻优过程结束条件进行判断,若未达到则再次执行步骤2~步骤5。
[0023]
作为本发明的一种优选技术方案,所述步骤3中的位置进行更新的公式如下:
[0024]
式中,和分别为搜索范围的上边界和下边界,t为当前迭代,为模拟黏菌觅食过程中当前气味浓度最高的位置,的范围为[
‑
a,a],a,a],为随机选择的两个位置,w表示位置的权重,从1线性减少至0。此外,参数p的表达式如下:
[0025]
p=tanh|s(i)
‑
df|
[0026]
式中s(i)为的适应度,df为所有迭代中的最佳适应度。参数a的表达式如下:
[0027][0028]
式中,maxt为最大迭代次数,w的公式如下:
[0029][0030]
式中,r为[0,1]内的随机值,bf、wf分别为当前迭代过程中的最佳适应度和最差适应度,condition为s(i)在排序中前50%的种群。
[0031]
作为本发明的一种优选技术方案,所述步骤4中基于机器学习算法建立心血管疾病的识别模型的方法是,通过随机森林分类算法(random forest,rf)建立心血管疾病的识别模型,其中与传统的随机森林分类算法的分类算法与回归算法的结构基本一致,两者之间的差异在于:
[0032]
(1)在决策树的节点切分时使用gini不纯度函数来衡量,
[0033]
如公式所示,
[0034]
p
mk
为当前节点训练样本中目标变量取值出现的概率,当节点处样本类别越明确时,不纯度越低;
[0035]
(2)使用投票法确定最终分类结果,依据每棵决策树的分类结果,取其众数作为最终分类结果。
[0036]
本发明的有益效果是:该种黏菌优化算法的心血管疾病的识别模型的建立方法,首先采集腕部压力脉搏波和指端容积脉搏波;建立指端微循环的容积脉搏血流模型;将腕部压力脉搏波和指端容积脉搏波分别作为容积脉搏血流模型的实际输入和期望输出,然后运用黏菌优化算法降低模型参数的不确定性,估计得得到容积脉搏血流模型的最终参数,实现了微循环生理状态信息的提取;然后基于机器学习算法建立心血管疾病的识别模型,以此判断心血管的健康状态。本发明能够获得更高的准确率,取得了较好的识别效果。
附图说明
[0037]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中;
[0038]
图1是本发明的r、l、c参数估计流程图的流程示意图;
[0039]
图2是本发明心血管疾病识别模型的建立流程;
[0040]
图3是本发明的微循环的容积脉搏血流模型电网络图;
[0041]
图4是脉搏波的标定方法图;
[0042]
图5是压力脉搏波的标定方法图;
[0043]
图6是标定后q
m
与co对比图;
[0044]
图7是仿真容积脉搏波与原始容积脉搏波对比图;
[0045]
图8是心血管疾病识别模型的预测结果图;
[0046]
图9是心血管疾病分类器对比实验结果图。
具体实施方式
[0047]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0048]
实施例:本发明一种黏菌优化算法的心血管疾病的识别模型的建立方法,包括以下几个步骤:
[0049]
步骤1,采集腕部压力脉搏波和指端容积脉搏波;
[0050]
步骤2,建立指端微循环的容积脉搏血流模型;
[0051]
步骤3,将腕部压力脉搏波和指端容积脉搏波分别作为容积脉搏血流模型的实际输入和期望输出,然后运用黏菌优化算法降低模型参数的不确定性,估计得得到容积脉搏血流模型的最终参数,实现了微循环生理状态信息的提取;
[0052]
步骤4,然后基于机器学习算法建立心血管疾病的识别模型,以此判断心血管的健康状态。
[0053]
所述建立指端微循环的容积脉搏血流模型的方法是,建立心血管仿真的电网络模型,如图3所示,
[0054]
电感l表示血液在微循环中流动变化的难易程度,代表血液在微小动脉中的流动惯性;电容c表示微循环内血管总体积随血液压力p的变化率,代表了微循环的总体顺应性;电阻r表示血液在循环中流动时受到的全部阻力;
[0055]
根据该模型,可建立如下数学表达式:
[0056][0057]
整理得模型方程为:
[0058][0059]
为获得模型的参数值,应用黏菌优化算法在设定的参数范围内求解最佳r、l、c值。
[0060]
如图1所示,所述应用黏菌优化算法在设定的参数范围内求解最佳r、l、c值的方法是,其寻找r、l、c值位置的具体步骤如下:
[0061]
步骤1,设定种群的初始值;
[0062]
步骤2,计算当前的适应度值,并进行排序;
[0063]
步骤3、对种群的位置进行更新;
[0064]
步骤4、再次计算适应度值,并更新种群中的最优位置;
[0065]
步骤/5、对寻优过程结束条件进行判断,若未达到则再次执行步骤2~步骤5。
[0066]
所述步骤3中的位置进行更新的公式如下:
[0067][0068]
式中,和分别为搜索范围的上边界和下边界,t为当前迭代,为模拟黏菌觅食过程中当前气味浓度最高的位置,的范围为[
‑
a,a],a,a],为随机选择的两个位置,w表示位置的权重,从1线性减少至0。此外,参数p的表达式如下:
[0069]
p=tanh|s(i)
‑
df|
[0070]
式中s(i)为的适应度,df为所有迭代中的最佳适应度。参数a的表达式如下:
[0071][0072]
式中,maxt为最大迭代次数,w的公式如下:
[0073][0074]
式中,r为[0,1]内的随机值,bf、wf分别为当前迭代过程中的最佳适应度和最差适应度,condition为s(i)在排序中前50%的种群。
[0075]
所述步骤4中基于机器学习算法建立心血管疾病的识别模型的方法是,通过随机森林分类算法(random forest,rf)建立心血管疾病的识别模型,其中与传统的随机森林分类算法的分类算法与回归算法的结构基本一致,两者之间的差异在于:
[0076]
(1)在决策树的节点切分时使用gini不纯度函数来衡量,
[0077]
如公式所示,
[0078]
p
mk
为当前节点训练样本中目标变量取值出现的概率,当节点处样本类别越明确时,不纯度越低;
[0079]
(2)使用投票法确定最终分类结果,依据每棵决策树的分类结果,取其众数作为最终分类结果。
[0080]
由脉搏传感器采集得到的信号可以用来近似代表血管内压力、容积等参数随时间变化的脉搏信号,但这些信号是以电压量变化表示的,其幅值不具有具体的生理意义。因此需要对这些曲线进行标定后,才能被使用于心血管仿真模型的参数估计中。
[0081]
如图4、5所示所示为压力脉搏波和容积脉搏波的信号,其中均包含了直流分量和脉动分量两部分。压力脉搏波的信号来自于动脉血管内部血液压力的变化,因此可以使用血压值对曲线进行标定[46]。在心室的搏动周期中,动脉内的最大压力为收缩压,最小压力为舒张压,分别对应于脉搏波中的最大值与最小值,因此可获得原始单周期压力脉搏波的标定公式:
[0082][0083]
式中,m
s
、m
d
分别为原始波形中的最大值和最小值由左心室射出的血液在脉搏波压力和血液灌注的作用下,通过动脉流动至人体的微循环中,并在微循环中与组织细胞完成物质交换,而指端微循环的容积脉搏波反映微动脉和毛细血管中血液容量随心脏搏动的变化,因此可以将容积脉搏波的平均值q
m
标定为左心室输出的血量,即心输出量。根据血液动力学的定义,血管的外周阻力r(pru),心输出量co(ml/s)和p
m
平均动脉压(mmhg)之间有如下关系:
[0084][0085]
式中,p
m
可计算的,q
m
(ml/s)为平均脉搏血流,sv(ml/beat)为每搏输出量,为脉搏波周期,计算公式如下
[0086][0087][0088]
由此,可推得:
[0089][0090]
式中,k、k
′
为压力脉搏波和容积脉搏波的波形特征量。
[0091]
在线性化假设下,上式中压力脉搏波和容积脉搏波的直流分量、脉动分量应分别对应,因此将容积脉搏波最大值和最小值作如下标定,
[0092][0093][0094]
与压力脉搏波的标定方法一致,可获得容积脉搏波的标定公式为
[0095][0096]
心血管疾病识别模型选取较常见、具有较高危险性的高血压、冠心病样本作为目标对象。如图2所示,在识别模型的建立过程中,首先从脉搏波样本中提取出特征,然后使用估计得到的r、l、c模型参数、以及收缩压ps、舒张压pd、平均压pm、co心输出量、q
max
最大血流量和q
min
最小血流量建立特征集,最后基于随机森林算法建立健康、高血压和冠心病的识别模型。
[0097]
实验中首先进行了脉搏波的标定,并将由标定后容积脉搏波计算得出的平均血流量与由标定后压力脉搏波计算得出的心输出量理论进行对比。如图6所示,两者呈现良好的一致性,平均绝对误差为11.10
±
8.02ml/s,说明标定方法具有一定的准确。
[0098]
如图7所示,为验证采用黏菌优化算法进行容积脉搏波血流模型参数不确定性量化的效果,对比了经过参数优化后的模型输出的仿真容积脉搏波与实际采集的原始容积脉搏波之间的差异。可以看到,两者波形相似度较高,这表明黏菌优化算法在r、l、c参数空间中搜索到了较优的位置,使得估计的模型参数值可以基本代表微循环的实际生理状态。rf、svm、knn以及dt算法在脉搏波的分类识别中应用广泛,为验证rf的分类性能,分别使用上述算法建立心血管疾病识别模型进行对比分析。实验中采用3折交叉检验法测试各个分类器的性能,并计算3次实验的平均准确率、平均精确率和平均召回率,结果图9所示。其中rf平均准确率比次优的knn提高了2.8%,达到了91.96%;平均精确率提高了3%,达到了92.13%;平均召回率提高了2.49%,达到了92.05%。结果表明,rf在四种分类算法中展现了良好的分类性能,对在空间中有较多交叉重叠的心血管参数特征有更好的区分能力,因此最终选取rf算法建立心血管疾病识别模型。
[0099]
如图8所示为使用rf算法在微循环状态参数特征集上建立的心血管疾病识别模型的预测结果,各类样本的识别准确率均达到了88%以上。其中,冠心病样本的识别准确率最
高,为95.51%,健康样本的平均识别准确率为92.11%,高血压样本的平均识别准确率为88.55%。高血压样本识别准确率较低的原因在于:健康样本中存在部分正常高值血压,其脉搏波以及心血管模型的参数可能表现出相似的特性,而冠心病患者通常会有高血压疾病史,因此也可能会表现出相似特性。整体上,所建立的模型对不同心血管健康状态下的特征参数有较好的区分能力,可以实现高血压、冠心病的有效识别。
[0100]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。