1.本发明涉及影像数据处理,尤其是医疗图像分割技术领域,特别是提供一种基于多种易混淆小部件的语义分割方法。
背景技术:
2.国内外的研究都表明,胎儿超声心动图依旧是目前对胎儿心脏首选的检查方法。医务工作者通过对超声心动图的分析,可以了解到足量的信息。但是受客观临床环境影响,图中的心脏部件容易混淆,而且部件大多数都偏小,多种易混淆的小部件对图像识别带来困难。
3.近些年来很多研究者采用深度学习方法处理医疗影像数据,助力高效辅助临床实践。在解决医学图像分割任务中,u
‑
net是种常用的分割网络。在不同的场景中,研究者使用了不同的变种,解决不同研究领域内的问题。基于超声心动图做研究的人们,大多会分为es和ed两个时期分别展开实验。基于超声心动图,目前更多的研究是基于成人超声心动图,对lv的研究。jafari做了成人lv的分割工作,他们基于四腔心切面,分别在es和ed两个时期对lv进行分割,实现了准确自动地分割出lv结构。xu等人基于正常组四腔心切面,借助dw
‑
net对五个部件进行分割研究。yang基于正常组和多个患病组,对五个部件进行分割,同时针对各组数据量不平衡问题,采用数据量基本保持均衡的原则,提升了分割效果。
4.除了降主动脉(dao),左心室(lv),左心房(la),右心室(rv),右心房(ra)这五个部件之外,还有房间隔(si),室间隔(vs),二尖瓣(mv),三尖瓣(tv),心外膜(ep)等小部件是描述心脏结构的通用部件。从图像中准确分割出这些部件,对于准确了解心脏的结构信息,判断胎儿心脏发育健康程度,给出合理的咨询服务,有重要意义。
5.受制于不均衡的样本,现有的数据增强方式往往是大量的随机尝试,缺乏系统化的方法。除此之外,胎儿心脏的解剖结构形变程度剧烈,存在尺度跨度不一等困难,也给语义分割造成了较大难度。
6.另一方面,扰动范数p的思想来源于神经网络对抗样本攻击算法的研究中。对于一个有效样本,经过攻击算法添加细微扰动之后,生成不易被人眼察觉却可以使得分类模型给出错误预测的攻击样本。攻击算法试图搜索找到使得模型分类错误的最小对抗扰动。扰动的大小使用p来衡量,通过设置超参限制扰动范数,使得对抗样本不易被人察觉。扰动范数p的不同取值代表了不同的含义。当p=0的时候,刻画修改的总像素点个数。当p=2的时候,此时代表欧氏距离,所有像素点均可以被修改。当p为无穷时,限制了单个点的修改范围。本发明另一方面旨在仿照干扰范数p的思想,对输出的特征进行指数幂运算。
技术实现要素:
7.本发明的目的在于在小规模数据集下,在多种易混淆小部件的胎儿四腔心图像中,本发明基于深度学习方法,使用幂指数方法和级联网络提升分割精度,尤其是小部件的miou(平均交并比)和缺失率,增强模型的鲁棒性和泛化能力。
8.作为一个实施例,本发明的一种基于多种易混淆小部件的语义分割方法,设计一种级联网络作为分割网络,将多个相对而言较为独立的模型的输入输出连接在一起,使得网络整体上由多个模型级联在一起,形成一个多阶段的流程。
9.进一步的,将分割网络得到的输出层特征信息和原始图像拼接在一起作为输入,作为先验信息交给分割网络训练。
10.其中,为了统一尺度,将特征图像和原始图像都做相同的归一化操作。
11.其中,本发明方法使用denseaspp、fastfcn、pspnet和deeplab v3 四个分割网络作为特征提取器,特征提取器之后连接ewep层对特征精度进行提高,增强模型分割能力。
12.作为另一个实施例,本发明针对现有技术中由于胎儿心脏的心尖朝向并无规律性,所朝向的各个方向更很难达到平衡,常用的数据增强方法考虑在旋转、平移、对比度、亮度方面做调整,有很大随机尝试的因素,缺乏系统的增强方法的问题,即针对心尖朝向不平衡的具体问题,提出的一种基于多种易混淆小部件的语义分割方法,具体采用多方向细密度的数据增强方法,处理数据集;
13.所述的多方向细密度的数据增强方法,具体如下:
14.s101、将原图像顺时针旋转30和60度,分别生成第二图像和第三图像;原图像为面对检查者方向的视图;
15.s102、将原图像、第二图像和第三图像顺时针旋转90度,生成第四图像、第五图像和第六图像;
16.s103、将原图像、第二图像、第三图像、第四图像、第五图像和第六图像水平翻转后生成背对检查者方向的第十三图像、第二十四图像、第二十三图像、第二十二图像、第二十一图像和第二十图像;
17.s104、将原图像、第二图像、第三图像、第四图像、第五图像、第六图像、第十三图像、第二十四图像、第二十三图像、第二十二图像、第二十一图像和第二十图像垂直翻转后生成背对检查者方向的第十九图像、第十八图像、第十七图像、第十六图像、第十五图像和第十四图像,以及面对检查者方向的第七图像、第八图像、第九图像、第十图像、第十一图像和第十二图像。
18.进行上述操作之后,会产生心尖朝向24个角度的情况,即面向被检查方向12个角度,背朝被检查方向12个角度。
19.作为再一个实施例,本发明提出一种基于多种易混淆小部件的语义分割方法,仿照干扰范数p的思想,对输出的特征进行了指数幂运算:
20.具体而言,假设最终输出的特征的形状为c*w*h,其中特征的长度为c,分别对应了c个可能的种类;假设对于像素位置(wi,hi),其对应的c个类别的值分别为f1,f2,f3,
…
f
c
;在经过分类器后,假设该像素被分类到了种类m,则f
m
为f1到f
c
中的最大值。经过对特征进行指数幂运算之后,上述c个类别的值变为了到各个数值之间的差异被放大。
21.其中,对于指数幂运算的k的选取,采用了动态指数法,随着训练次数的增多,逐渐扩大指数的值;即在需要进行整体优化时,更应当让其增大感受野,侧重于全局考虑;而随着训练次数的增多,应该放大错误,让模型集中优化错误分类的地方。
22.本发明一种基于多种易混淆小部件的语义分割方法,优点及功效在于:通过设计一种级联网络作为分割网络增强模型分割能力;提出的多方向细密度的增强方法,可以显
著提升模型泛化能力;通过指数幂策略,即通过不断扩大易混淆区域反馈信息的力度更好地优化模型。
附图说明
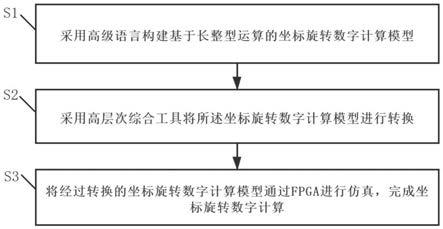
23.图1所示为本发明方法流程框图
24.图2a、b所示为本发明实施例数据增强生成覆盖的24种角度
25.图3a~f所示为本发明实施例多方向细密度的数据增强方法的示例
26.图4a、b所示为本发明实施例分别使用r、f、rf三种增强方式处理数据集的效果对比图
具体实施方式
27.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本发明而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本发明所要求保护的技术方案。
28.实施例1
29.本实施例提供一种基于多种易混淆小部件的语义分割方法,如图1所示,设计一种级联网络作为分割网络,将多个相对而言较为独立的模型的输入输出连接在一起,使得网络整体上由多个模型级联在一起,形成一个多阶段的流程。具体的,是将第一阶段网络得到的输出层特征信息和原始图像拼接在一起作为第二阶段网络的输入,作为先验信息交给分割网络训练。本实施例具体采用了两阶段级联网络作为分割网络,第一阶段网络所提取到的特征输入到第二阶段,帮助第二阶段模型优化易混淆像素;本实施例使用denseaspp、fastfcn、pspnet和deeplab v3 四个模型作为特征提取器,每个阶段都在特征提取器后接入ewep层对特征精度进行提高,增强模型分割能力。
30.其中,为了统一尺度,将特征图像和原始图像都做相同的归一化操作。
31.实施例2
32.本实施例为在实施例1的基础上,在所述的级联网络之前,进一步设置有多方向细密度的数据增强方法,以增大图像所覆盖的角度范围,使得角度分布更加均衡,增强模型的鲁棒性。
33.如图2a、b所示, 代表面对检查者方向,x代表背对检查者方向,假设原图是1号,2~23号是数据增强生成出的图像。
34.s101:1号图像顺时针旋转30和60度生成2和3号图像。
35.s102:1/2/3号图像顺时针旋转90度生成4/5/6号图像。
36.s103:1/2/3/4/5/6号图像水平翻转生成13/24/23/22/21/20号图像。
37.s104:1/2/3/4/5/6/13/24/23/22/21/20号图像垂直翻转生成19/18/17/16/15/14/7/8/9/10/11/12号图像。
38.进行上述操作之后,会产生心尖朝向24个角度的情况。 表示胎儿面向被检查方向,x表示胎儿背朝被检查方向。即面向被检查方向12个角度(如图2a),背朝被检查方向12个角度(如图2b)。
39.如图3a~3f,为对原始图像分别旋转30度、60度、90度、水平翻转、垂直翻转处理后的图像。基于五种基本方法的组合,组合出rf密度最大的方式,可以显著提升模型泛化能力。
40.如图4a、b所示为本发明实施例采用多角度细密度的增强方式处理数据集的效果对比图,其中,用r代表只做s101,f代表只做s102和s103,rf代表r和f的组合。相比于f增强方式主要旨在拓宽数据覆盖范围,r增强方式的数据集的覆盖力度更密。如果将r方式和f方式综合到一起使用,形成rf增强方式,结果证明,iou指标又大幅度提升,而且缺失率很低。这说明多角度细密度的增强方式,可以显著提升模型泛化能力。
41.实施例3
42.本发明提出一种基于多种易混淆小部件的语义分割方法,仿照干扰范数p的思想,对输出的特征进行了指数幂运算:
43.具体而言,假设是做c类别的语义分割任务(包含背景一共c个类别),所以模型会输出c个通道。w,h是图像的宽和高,最终输出的特征的形状为c*w*h,其中特征的长度为c,分别对应了c个可能的种类;假设对于像素位置(wi,hi),其对应的c个类别的值分别为f1,f2,f3,
…
f
c
;在经过分类器后,假设该像素被分类到了种类m,则f
m
为f1到f
c
中的最大值。经过对特征进行指数幂运算之后,上述c个类别的值变为了到各个数值之间的差异被放大。
44.其中,对于指数幂运算的k的选取,采用了动态指数法,随着训练次数的增多,逐渐扩大指数的值;即在需要进行整体优化时,更应当让其增大感受野,侧重于全局考虑;而随着训练次数的增多,应该放大错误,让模型集中优化错误分类的地方。
45.表1和表2分别是在deeplabv3 模型下,不同选项(option)中各个部件的正确点的个数和iou。optipn1~4分别是固定指数幂k为1,2,3,4。option5~8分别设置步长为0.01,0.0125,0.015,0.02,指数幂k随着迭代轮数增大而根据步长增大。所以option1是基线(baseline)。
46.option2与option4相比,option2正确像素点少,而有高iou。这是因为牺牲了大部件的像素点,换取了小部件像素点。比如dao、tv、ivs的iou显著提升,而la的iou却下降了。option2和option7相比,option7有更多正确的像素点,但是iou并没有改变,这是因为不同部件间的平衡过程。
[0047][0048][0049]
表1在deeplabv3 模型下,各个部件分割正确点的数量。
[0050]
ꢀꢀ
bgdaolalvrarvtvmvivsiasep
option1dl0.97650.55170.63670.56520.66870.64920.1710.10150.44150.15920.329option2dl0.98030.55960.63080.61710.69490.65270.26070.22740.42670.24730.3643option3dl0.98070.54370.63510.60770.6780.65940.23570.2310.43910.24960.3782option4dl0.98080.5550.64890.6010.67430.64620.25340.240.40750.2570.374option5dl0.97950.54930.64090.61450.69590.66410.26210.21290.4220.21970.3634option6dl0.98020.5620.65860.63710.68930.66970.23840.2730.45050.24640.3742option7dl0.97860.54730.65990.63090.6970.64050.24680.23990.42460.23440.3605option8dl0.980.53490.65490.58640.6820.65320.24450.23670.40710.23690.3713
[0051]
表2在deeplabv3 模型下,各个部件的iou。
[0052]
表3显示不同模型下,有无先验信息的miou和mr(缺失率)。有先验信息的过程往往都有更高的miou和更低的mr,从而验证了本方法的有效性。表格中红加粗斜体部分数据的是该模型使用不同的option中,最高的miou指标。
[0053][0054][0055]
表3有无先验信息的分割对比结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。