1.本发明涉及连续范围查询技术,特别是涉及一种面向轨迹流数据的连续范围查询技术
背景技术:
2.随着全球定位系统的发展和移动设备的普及,移动对象正在连续不断地高速产生大量的流数据。对流数据的处理也就成为了新兴的技术热点,吸引了人们的广泛关注。
3.目前,已经有了一些关于查询流数据的研究。
4.针对微博数据和移动对象的实时查询就是其中的一种。该查询的索引结构是格网或金字塔结构。由于针对的数据是点类型的,这两种结构在插入和删除数据时涉及到节点的合并与分裂,可能要调整整个结构,所以更新困难,逐个点处理的效率太低,需要使用批量更新的方式保证数据插入的效率。但是,批量更新索引法并不能保证最新的数据及时地出现在查询结果集中。因此,该查询结果的可靠性不足。另外,点类型的数据就是一个点,如带有地理位置的微博数据、移动对象的当前位置数据这类只包括一个点的数据。相对于线类型的数据,如具有点序列的轨迹来说,点类型的数据是没有历史数据的。因此,该查询不能支持实时和历史数据联合查询的场景。
5.实时和历史数据的联合查询是通过基于分布式的计算框架进行数据的分区和计算来实现的。该查询将接收到的实时数据根据属性进行分区,再与分区内的历史数据合并,实现对二者的联合查询。该类型的查询中,有两种方法值得引起关注。一个是,waterwheel提出的一种数据分区方式,将key
‑
时间组成的二维空间划分为多个矩形,在每个矩形代表的范围中根据key值范围建立内存中的模板b 树索引,实现数据的快速更新,有效支持key范围和时间范围的查询。例如,当key为小明、时间为10分钟时,可以查询10分钟内到达的、id是小明的数据。另一个是,dragoon基于分布式处理框架spark提出的不同rdd之间的数据分享机制,避免了spark原生机制在数据更新时不必要的数据拷贝,并在此基础之上实现数据的实时索引和查询。rdd(resilient distributed dataset),即弹性分布式数据集,是spark中的一种数据抽象方式,它代表一个不可变、可分区、里面的元素可并行计算的集合。rdd将操作分为两类:转换与行动。rdd的每次转换都会生成一个新的rdd,所以rdd之间就会形成类似于流水线一样的前后依赖关系。无论执行了多少次转换操作,rdd都不会真正执行运算,只有当行动操作被执行时,运算才会触发。这就是spark的惰性调用机制,是spark高效计算的基础。正是因为懒惰执行,spark才能更有效地运行于内存,使得高效的共享内存机制避免了大量中间结果,从而避免了磁盘写入写出带来的性能消耗。
6.前述两种实时和历史数据的联合查询方式,虽然都在一定的场景中能够得到很好的应用,但也都有各自的局限性。waterwheel提出的方式不能高效支持空间范围查询,只能处理根据id和时间属性进行的查询。dragoon解决的仅是数据的实时更新问题和普通的单次查询问题,且仍采用了批量更新索引的方式进行实时数据的更新,不能保证最新的数据及时地出现在查询结果集中,另外,在连续查询的时候效率也依然没有提高。
技术实现要素:
7.为了在保证数据实时更新的情况下,同时实现时间范围查询和空间范围查询,并提高连续范围查询的效率,本发明提出了一种新的连续范围查询的技术,包括了位置信息发送模块,索引模块和查询模块。本发明先改进了索引模块,可以保证轨迹点根据其空间位置和时间顺序快速插入,并且支持轨迹的id
‑
时间范围查询和空间范围查询。接着,本发明改进了查询模块,采用了一种内外存结合的查询机制,并最大程度地减少空间相交判断的次数和需检索的数据次数,即充分利用了有限的内存资源并提高了连续范围查询的效率,同时保证结果的准确性。在此基础上,本发明对索引模块和查询模块进行了补充,使其在查询变化的情况下也能保证查询的准确性。进一步地,本发明的技术,还包括了内存清理模块。当查询次数和并发查询数目增加时,其庞大的结果集会增加内存负担。因此,内存清理模块提供的合理的内存清理机制,可以高效支持大量查询,同时保证查询结果的准确性。
8.为了更清晰地阐述本发明的技术方案,先给出下述相关定义:
9.定义1轨迹(trajectory)。轨迹tr是由地理空间中的移动对象o
j
(1≤j≤m)产生的一系列时间有序的轨迹点序列,表示为其中,一个轨迹点是移动对象o
j
产生的第i条gnss记录,表示为一个二元组为这条gnss记录产生时的时间,为产生这条gnss记录时,该移动对象所处地理位置的坐标,表示为(lat,lng)。一条轨迹中,任意一个轨迹点数大于2的子集称为子轨迹,表示为为方便起见,下文中子轨迹也称为轨迹。
10.gnss,即卫星导航系统(global navigation satellite system),是覆盖全球的用于空间定位的卫星系统,允许小巧的电子接收器确定它的所在位置(经度、纬度和高度),并且经由卫星广播沿着视线方向传送的时间信号精确到10米的范围内。接收机计算的精确时间以及位置,可以作为科学实验的参考。世界上主要的卫星导航系统有美国的全球定位系统gps,俄罗斯的格罗纳斯(glonass),中国的北斗卫星导航定位系统,以及欧盟伽利略(galileo)定位系统。
11.定义2轨迹流(trajectory streams)。轨迹流ts由地理空间中的移动对象o
j
(1≤j≤m)产生,与轨迹一样包含一系列gnss记录,表示为其中,一个轨迹点是移动对象o
j
产生的第i条gnss记录。与轨迹不同的是,轨迹流数据没有边界,是无限的。
12.定义3空间相交判断。给定两个空间几何对象a和b,计算a与b的空间几何是否存在交集。若则a与b空间相交。
13.定义4轨迹流的连续范围查询(continuous range query on trajectory streams)。给定轨迹流ts,和空间范围r,轨迹流的连续范围查询每隔固定时间t重复执行,连续满足以下两个条件的轨迹tr
i
:
14.tr
i
包含其关联对象产生的最新一个轨迹点r
latest
;
15.tr
i
中所有轨迹点均在轨迹流ts中,且轨迹点的空间位置均位于空间范围r内。
16.即:
17.定义5查询(query)。查询q由三个属性组成,分别是唯一标识q
id
,查询的几何空间
范围q
range
和发起查询的时间q
t
。表示为三元组(q
id
,q
range
,q
t
)。
18.定义6查询缓冲区,即查询缓冲区集合(query buffers set)。给定缓冲距离ε,对查询集中所有几何进行缓冲分析,得到缓冲结果的集合,如图1所示。
19.定义7id
‑
时间范围查询(id
‑
temporal query)。给定轨迹集合tset,id
‑
时间范围查询的参数为移动对象的唯一标识id和时间范围tr=[t
min
,t
max
],返回tset中所有满足以下两个条件的轨迹tr
i
∈tset:
[0020]
tr
i
.id=id;
[0021]
tr
i
中所有轨迹点均产生于时间范围tr内。
[0022]
即:
[0023]
第一方面,本发明实施例提出一种面向轨迹流数据的连续范围查询的方法,该方法包括:
[0024]
移动对象通过卫星导航系统gnss获得当前位置信息,持续向查询系统发送轨迹点数据,该轨迹点为该移动对象产生的gnss记录,该gnss记录包括该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。
[0025]
对该轨迹点进行索引,发起查询q。
[0026]
该查询q的属性包括:唯一标识,查询空间范围和发起查询的时间。
[0027]
该查询q包括根据格网的空间属性进行的空间范围查询和根据双向链表的时间属性进行的时间范围查询。该索引包括索引结构和索引更新。
[0028]
该索引结构采用格网与双向链表结合的结构,通过该格网管理该轨迹点的该空间属性,通过该双向链表管理该轨迹点的该时间属性。
[0029]
该格网通过对该查询空间范围进行格网划分获得,以格网预设点坐标作为该格网的唯一标识,即格网坐标,以该查询空间范围内的所有格网为格网集,以预设格网坐标为格网集原点。
[0030]
每一个格网都有一个格网指针,该格网指针指向该格网范围内最新的轨迹点,该格网范围内的所有轨迹点按照到达顺序的逆序排序。
[0031]
轨迹使用该双向链表存储,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的该格网中与该轨迹点到达顺序相邻的两个轨迹点。
[0032]
该索引更新在接收新轨迹点时进行,当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0033]
当该新轨迹点为顺序到达的最新轨迹点时,将该新轨迹点添加至该新轨迹点所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网的格网指针。
[0034]
当该新轨迹点不是顺序到达的最新轨迹点时,根据该新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的该新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。
[0035]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法,其特征在于:
[0036]
该查询空间范围为查询缓冲区,该查询缓冲区为该查询空间范围的边界向外扩展ε米的空间范围。
[0037]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0038]
散列映射存储查询对象的id,该查询对象是轨迹点与查询q的查询空间范围做空间相交判断的结果非空的移动对象。
[0039]
散列映射存储该查询对象的第一对象指针,该第一对象指针指向该查询对象在该查询空间范围的最旧轨迹点。
[0040]
散列映射存储该查询对象的第二对象指针,该第二对象指针指向该查询对象在该查询空间范围的最新轨迹点。
[0041]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0042]
散列映射存储该查询对象的进入时间戳,即该查询对象进入查询空间范围时的轨迹点的时间属性。
[0043]
查询q第二次执行开始,沿着该双向链表从最新的轨迹点向历史数据方向检索至该进入时间戳,即返回查询结果。
[0044]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0045]
当该查询空间范围变为新查询空间范围时,计算查询空间范围变化差集。
[0046]
当该新查询空间范围落在该查询空间范围内时,计算该查询空间范围变化差集中的格网,即减少格网,将该减少格网从该格网集中删除,删除最新轨迹点在该减少格网中的该双向链表,更新该新查询空间范围内的格网的双向链表的相关节点的第一节点指针、第二节点指针、第三节点指针,更新新查询对象的进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0047]
当该新查询空间范围不在该查询空间范围内时,计算所述查询空间范围变化差集中的所述格网,即新增格网,得到新增格网集和新增格网集原点,根据新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集;以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,对查询结果中的轨迹点进行索引;发起新的查询q2,查询当前位置在该新增格网集中的移动对象,得到新查询对象,用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引。
[0048]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法,其特征在于:
[0049]
该查询系统使用内外存结合的方式工作,该内外存结合的工作方式包括:
[0050]
该查询q第一次执行时,从外存中读取移动对象的轨迹点,与该查询空间范围做空间相交判断。
[0051]
将该查询q的查询空间范围保存在内存中。
[0052]
仅对该查询q的查询对象在该查询空间范围内的轨迹点进行索引,该索引保存在内存中。
[0053]
当该查询对象离开该查询空间范围时,删除该查询对象的轨迹点的索引。
[0054]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括内存清理,该内存清理包括:
[0055]
清除静止对象在该查询空间范围内的轨迹点的索引,该静止对象是查询系统在静
止时间内没有收到新轨迹点的查询对象,该静止时间可在该查询系统中预设。
[0056]
清除无效轨迹点的索引,该无效轨迹点是没有出现在查询q的查询结果中的轨迹点。
[0057]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法中的内存清理还包括:
[0058]
当该查询q有两个以上时,清除无效查询轨迹点的索引,该无效查询轨迹点是只出现在无效查询中的轨迹点,该无效查询是在无效查询时间内没有发起执行的查询q,该无效查询时间可以在该查询系统中预设。
[0059]
清除低效高采样轨迹点的索引,该低效高采样轨迹点,是低效对象的除最新的轨迹点外的轨迹点,该低效对象是指只出现在查询频率最低的查询q中的采样频率大于预设采样频率的移动对象,在清除低效高采样轨迹点后,该查询频率最低的查询q发起查询时,该低效对象的轨迹点通过外存读取。
[0060]
第二方面,本发明实施例提出一种面向轨迹流数据的连续范围查询的系统,该系统包括:
[0061]
位置信息发送模块,索引模块和查询模块。
[0062]
该位置信息发送模块,在移动对象上,用于通过卫星导航系统gnss获得当前位置信息,持续向查询系统发送轨迹点数据,该轨迹点为该移动对象产生的gnss记录,该gnss记录包括该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。
[0063]
该查询模块,用于发起查询q,该查询q的属性包括:唯一标识q
id
、查询空间范围q
range
和发起查询的时间q
t
。
[0064]
该查询模块,包括空间范围查询模块和时间范围查询模块。
[0065]
该空间范围查询模块,用于在发起该查询q时,根据该格网的空间属性进行空间范围查询。
[0066]
该时间范围查询模块,用于在发起该查询q时,根据该双向链表的时间属性进行时间范围查询。
[0067]
该索引模块,用于对该轨迹点进行索引,包括索引结构模块和索引更新模块。
[0068]
该索引结构模块,用于搭建结合格网与双向链表的结构,包括格网模块与链表模块,通过该格网模块管理该轨迹点的空间属性,通过该链表模块管理该轨迹点的时间属性。
[0069]
该格网模块,包括格网划分模块和格网指针模块。
[0070]
该格网划分模块,用于对该查询空间范围进行格网划分获得该格网,以格网预设点坐标作为该格网的唯一标识,即格网坐标,以该查询空间范围内的所有格网为格网集,以预设格网坐标为格网集原点。
[0071]
该格网指针模块,用于管理该格网的格网指针,每一个该格网都有一个格网指针,该格网指针指向该格网范围内最新的该轨迹点,该格网范围内的所有轨迹点按照到达顺序的逆序排序。
[0072]
该链表模块,用于使用该双向链表存储轨迹,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的格网中与该轨迹点到达顺序相邻的两个轨迹点。
[0073]
该索引更新模块,用于在接收新轨迹点时进行索引更新,包括计算与判断模块,顺序更新模块和乱序更新模块。
[0074]
计算与判断模块,用于当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0075]
顺序更新模块,用于当该新轨迹点为顺序到达的最新轨迹点时,将该新轨迹点添加至其所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新其所在的格网的格网指针。
[0076]
乱序更新模块,用于当该新轨迹点不是顺序到达的最新轨迹点时,根据新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新其所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。
[0077]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统,其特征在于:
[0078]
该查询空间范围为查询缓冲区,该查询缓冲区为该查询空间范围的边界向外扩展ε米的空间范围。
[0079]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括散列映射存储模块,该散列映射存储模块包括:
[0080]
查询对象id存储模块,第一对象指针存储模块和第二对象指针存储模块。
[0081]
该查询对象id存储模块,用于散列映射存储查询对象的id,该查询对象是该轨迹点与该查询q的查询空间范围做空间相交判断的结果非空的移动对象。
[0082]
该第一对象指针存储模块,用于散列映射存储该查询对象的第一对象指针,该第一对象指针指向该查询对象在该查询空间范围的最旧轨迹点。
[0083]
该第二对象指针存储模块,用于散列映射存储该查询对象的第二对象指针,该第二对象指针指向该查询对象在该查询空间范围的最新轨迹点。
[0084]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括历史数据检索模块,该历史数据检索模块包括:
[0085]
时间戳存储模块和结果返回模块。
[0086]
该时间戳存储模块,用于散列映射存储该查询对象的进入时间戳,即该查询对象进入该查询空间范围时的轨迹点的时间属性。
[0087]
该结果返回模块,用于从查询q第二次执行开始,沿着该双向链表从最新的轨迹点向历史数据方向检索至该进入时间戳,即返回查询结果。
[0088]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括空间范围变化模块,该空间范围变化模块包括:
[0089]
差集计算模块,缩小变化模块和扩大变化模块。
[0090]
该差集计算模块,用于当所述查询空间范围变为新查询空间范围时,计算查询空间范围变化差集。
[0091]
该缩小变化模块,用于当该新查询空间范围落在该查询空间范围内时,计算该查询空间范围变化差集中的格网,即减少格网,将该减少格网从该格网集中删除,删除最新轨迹点在该减少格网中的双向链表,更新该新查询空间范围内的格网的双向链表的相关节点
的第一节点指针、第二节点指针、第三节点指针,更新新查询对象的该进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0092]
该扩大变化模块,用于当该新查询空间范围不在该查询空间范围内时,计算该查询空间范围变化差集中的格网,即新增格网,得到新增格网集和新增格网集原点,根据该新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集;以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,对查询结果中的轨迹点进行索引;发起新的查询q2,查询当前位置在该新增格网集中的移动对象,得到新查询对象,用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引。
[0093]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统,其特征在于:
[0094]
该查询系统使用内外存结合的方式工作。该内外存结合的工作方式包括:
[0095]
该查询q第一次执行时,从外存中读取该移动对象的轨迹点,与该查询空间范围做空间相交判断。
[0096]
将该查询q的查询空间范围保存在内存中。
[0097]
仅对该查询q的查询对象在该查询空间范围内的轨迹点进行索引,该索引保存在内存中。
[0098]
当该查询对象离开该查询空间范围时,删除该查询对象的轨迹点的索引。
[0099]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括内存清理模块,该内存清理模块包括:清除静止对象模块和清除无效轨迹点模块。
[0100]
该清除静止对象模块,用于清除静止对象在该查询空间范围内的轨迹点的索引,该静止对象是该查询系统在静止时间内没有收到新轨迹点的查询对象,该静止时间可在查询系统中预设。
[0101]
该清除无效轨迹点模块,用于清除无效轨迹点的索引,该无效轨迹点是没有出现在该查询q的查询结果中的轨迹点。
[0102]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统的内存清理模块还包括:
[0103]
清除无效查询轨迹点模块和清除低效高采样轨迹点模块。
[0104]
该清除无效查询轨迹点模块,用于当该查询q有两个以上时,清除无效查询轨迹点的索引,该无效查询轨迹点是只出现在无效查询中的轨迹点,该无效查询是在无效查询时间内没有发起执行的查询q,该无效查询时间可以在查询系统中预设。
[0105]
清除低效高采样轨迹点模块,用于当该查询q有两个以上时,清除低效高采样轨迹点的索引,该低效高采样轨迹点,是低效对象的除最新的轨迹点外的轨迹点,该低效对象是指只出现在查询频率最低的查询q中的采样频率大于预设采样频率的移动对象,清除低效高采样轨迹点后,该查询频率最低的查询q发起查询时,该低效对象的轨迹点通过外存读取。
[0106]
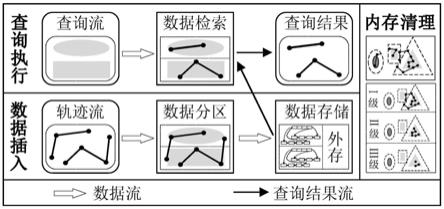
综合使用了本发明提出的格网与双向链表结合的索引方法,内外存结合的查询机制和内存清理机制,并最大程度地减少空间相交判断的次数和需检索的数据次数时,一些实施例提供的查询系统在服务器端的功能如图2所示,可分为三个部分:数据插入、查询执行和内存清理。图2中白色空心箭头表示数据插入和查询执行过程中的数据流向,黑色实线
箭头表示查询结果的流向。
附图说明
[0107]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0108]
图1为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的查询缓冲区示意图
[0109]
图2为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例在服务器端的功能框架图
[0110]
图3为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的索引结构示意图
[0111]
图4为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的向格网中插入新轨迹点的示意图
[0112]
图5为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的轨迹与查询范围缓冲区关系示例
[0113]
图6为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的格网更新示例
[0114]
图7为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的对比实验的实验数据集
[0115]
图8为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的对比实验的不同查询空间范围下初始查询效率的对比图示
[0116]
图9为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的对比实验的不同查询空间范围下后续查询效率的对比图示
[0117]
图10为本发明的面向轨迹流数据的连续范围查询的方法的一具体实施例的对比实验的不同对象数目下索引时间的对比图示
具体实施方式
[0118]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。本领域技术人员应当理解的是,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员可以进行任何适当的修改或变型,从而获得所有其它实施例。
[0119]
下面,以对城市中特殊车辆的监控和追踪为例对本发明的技术方案进行说明。
[0120]
第一方面,本发明实施例提出一种面向轨迹流数据的连续范围查询的方法,该方法包括以下步骤:
[0121]
移动对象通过卫星导航系统gnss获得当前位置信息,持续向查询系统发送轨迹点数据,该轨迹点为该移动对象产生的gnss记录,该gnss记录包括该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。
[0122]
对该轨迹点进行索引,发起查询q。
[0123]
该查询q的属性包括:唯一标识q
id
,查询空间范围q
range
和发起查询的时间q
t
。
[0124]
该查询q包括根据格网的空间属性进行的空间范围查询和根据双向链表的时间属性进行的时间范围查询。该索引包括索引结构和索引更新。
[0125]
该索引结构采用格网与双向链表结合的结构,通过该格网管理该轨迹点的该空间属性,通过该双向链表管理该轨迹点的该时间属性。
[0126]
该格网通过对该查询空间范围进行格网划分获得,以格网预设点坐标作为该格网的唯一标识,即格网坐标,以该查询空间范围内的所有格网为格网集,以预设格网坐标为格网集原点。
[0127]
每一个格网都有一个格网指针,该格网指针指向该格网范围内最新的轨迹点,该格网范围内的所有轨迹点按照到达顺序的逆序排序。
[0128]
轨迹使用该双向链表存储,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的该格网中与该轨迹点到达顺序相邻的两个轨迹点。
[0129]
该索引更新在接收新轨迹点时进行,当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0130]
当该新轨迹点为顺序到达的最新轨迹点时,将该新轨迹点添加至该新轨迹点所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网的格网指针。
[0131]
当该新轨迹点不是顺序到达的最新轨迹点时,根据该新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的该新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。
[0132]
本实施例中,移动对象是城市中的特殊车辆,如危险化工品车辆、渣土车等。这些特殊车辆需要装配gnss定位系统,每隔一定时间自动向查询系统上传一条gnss记录。该条gnss记录即该移动对象的一个轨迹点,包括了该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。目前,较常使用的是gps系统。如,一辆危险化工品车为移动对象a,则查询系统在接收到该移动对象a的轨迹点,对该轨迹点进行索引后,可以发起查询q。该查询q的属性包括:唯一标识q
id
,查询空间范围q
range
和发起查询的时间q
t
。唯一标识q
id
区分了不同的查询q。查询空间范围是根据城市的管理需要确定的,可将城市的重点监测区域列为查询空间范围。发起查询的时间表示了此次查询的时间,一个查询可以在不同的时间先后发起多次查询。该查询q包括根据格网的空间属性进行的空间范围查询和根据双向链表的时间属性进行的时间范围查询。当查询q第一次执行时,即对查询空间范围内的轨迹点建立索引,同时在查询系统中保存该查询q的设置。
[0133]
索引结构如图3所示。该索引结构采用格网与双向链表结合的结构,通过该格网管理该轨迹点的该空间属性,使用该双向链表管理该轨迹点的该时间属性。该格网通过对该查询空间范围进行格网划分获得。图3最上面一行的g(0,0),g(1,0)
……
代表一个个划分好的格网。每一个格网都有一个格网指针,该格网指针指向该格网范围内最新的轨迹点,如图
3中格网g(0,0)指向了轨迹点a6,格网g(1,0)指向了轨迹点a5。a5、a6分别是移动对象a的第5、6个轨迹点。每一个格网范围内的所有轨迹点按照到达顺序的逆序排序,如图3所示,格网g(1,1)先后收到的轨迹点依次为b5,a3,b4,b3。轨迹使用双向链表存储,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的格网中与该轨迹点到达顺序相邻的两个轨迹点。如图3所示,a1、a2、a3、a4、a5、a6为先后到达的移动对象a的轨迹点,也是存储移动对象a的轨迹的双向链表的节点。每一个节点的第一节点指针都指向了该轨迹点所在的轨迹中的前一个轨迹点,如图1所示,a6指向了a5,a5指向了a4,a4指向了a3,a3指向了a2,a2指向了a1。在格网g(3,0)中,a1、a2、a4三个轨迹点先后抵达,彼此相邻,因此,它们的第二节点指针、第三节点指针相互指向了彼此。
[0134]
每一个格网都有一个唯一标识,即格网坐标。该格网坐标可以由格网预设点的坐标来确定,该预设点可以是格网的一个顶角,也可以是其中心点,总之,是任一可以确定唯一坐标的点。以该查询空间范围内的所有格网为格网集,以预设点坐标为格网集原点。该预设点可以是该格网集的任一可以明确的格网的明确的一个点,如最下面一行的最左边的那个格网的左下角的顶点,即格网集的左下角的格网的左下角的顶点。
[0135]
该索引更新在接收新轨迹点时进行,当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0136]
当该新轨迹点为顺序到达的最新轨迹点时,如图4所示,格网g(3,0)原先有两个轨迹点a1和a2,在接收到顺序到达的最新的轨迹点a4后,将该新轨迹点a4添加至该新轨迹点所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网的格网指针。
[0137]
当该新轨迹点不是顺序到达的最新轨迹点时,根据该新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的该新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。前文的轨迹定义中提到,轨迹由时间有序的gnss记录组成。但在现实情况中,由于网络延迟和gnss定位设备故障等原因,gnss记录不一定按照其产生的顺序到达。但现有技术假定接收的gnss记录为有序数据,未针对数据乱序的问题给出准确且有效的解决方案。例如,有两个轨迹点分别产生于10点和10点30分,由于网络延迟等原因,10点产生的轨迹点a迟于10点30分产生的轨迹点b被接收到。现有技术对这两个轨迹点的实际产生时间不予理会,就会在最终的查询结果中造成错误。本实施例的技术方案,对a进行了额外处理,在索引中找到它应该在的存储位置,那么,在下次返回查询结果时,a就也在查询结果中了,查询系统能返回正确的查询结果。
[0138]
在对城市中特殊车辆的监控与跟踪中,查询q以城市中的重点监测区域为查询空间范围。查询系统按照一定的频率发起查询q的执行,每次执行时,查询系统都会解析接收到的轨迹点的位置信息,判断其是否在查询空间范围内。查询系统对落在查询空间范围内的轨迹点建立索引,根据轨迹点的时间属性与空间属性,给出查询空间范围内的实时位置信息与历史位置信息。根据实时位置信息,可以方便地对该特殊车辆进行拦截。根据历史位置信息,可以知道该车辆进入重点监测区域的行驶路线,以实现对其途经区域的安全排查。
这是本发明提出的查询方法在实时和历史数据联合查询的场景中的实际应用。
[0139]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法,其特征在于:
[0140]
该查询空间范围为查询缓冲区,该查询缓冲区为该查询空间范围的边界向外扩展ε米的空间范围。
[0141]
本实施例的提出,是基于以下的假设:当前在查询q的缓冲范围ε米中的对象,进入查询范围的可能性远大于在缓冲范围外的对象。以图5为例(实心点为对象当前位置点,空心点为历史时刻的轨迹点):对象a和b当前位于查询q的查询缓冲区内,其进入查询空间范围所需的时间小于对象c,下一时刻对象a和b比对象c更有可能进入查询范围。因此,对移动对象a和b在查询缓冲区中的轨迹点进行索引,可以有效提高查询效率。
[0142]
在对城市中特殊车辆的监控与跟踪中,以城市中的重点监测区域为查询空间范围,可以将该范围向外扩展,如扩展100米,将距离重点监测区域100米内的特殊车辆纳入监测范围,当检测到该车辆的轨迹点落入重点监测区域时,可以第一时间快速响应。
[0143]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0144]
散列映射存储查询对象的id,该查询对象是轨迹点与查询q的查询空间范围做空间相交判断的结果非空的移动对象。
[0145]
散列映射存储该查询对象的第一对象指针,该第一对象指针指向该查询对象在该查询空间范围的最旧轨迹点。
[0146]
散列映射存储该查询对象的第二对象指针,该第二对象指针指向该查询对象在该查询空间范围的最新轨迹点。
[0147]
在本实施例中,散列映射存储查询对象的id如图3最下面一行所示,a、b、c为查询对象的id。每个查询对象都有指向最旧轨迹点的第一对象指针与指向最新轨迹点的第二对象指针。如图3所示,查询对象a的第一对象指针指向了轨迹点a1,第二对象指针指向了轨迹点a6。本实施例的技术方案支持并行的id
‑
时间范围查询,即可以并行进行多个id
‑
时间范围的查询。
[0148]
在对城市中特殊车辆的监控与跟踪中,通过散列映射存储进入重点监测区域的特殊车辆的id和在该重点监测区域内的最新轨迹点及最旧轨迹点,可以对进入重点监测区域的特殊车辆中的多个任意选中的车辆进行指定时间范围内的位置信息的查询。
[0149]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0150]
散列映射存储该查询对象的进入时间戳,即该查询对象进入查询空间范围时的轨迹点的时间属性。
[0151]
查询q第二次执行开始,沿着该双向链表从最新的轨迹点向历史数据方向检索至该进入时间戳,即返回查询结果。
[0152]
在本实施例的提出是基于以下的洞察:连续查询的结果具有关联性,已经被返回的历史轨迹始终是后续查询结果的子集,直至对象离开该查询的查询空间范围。根据这种特性,查询q第一次执行后,其查询空间范围即保存在查询系统中。查询的后续执行转为id
‑
时间范围查询,无需进行耗时的空间相交判断。本实施例中,在查询q第一次执行后,即使用散列映射存储其命中的所有对象的id,及这些对象进入查询时的时间戳。后续执行只需沿着链表从最新的轨迹点向历史数据方向检索至指定时间戳。具体操作时,可以设定向历史数据方向检索,直到访问到第一个不在返回结果中的数据,越过返回数据的边界,即返回查
询结果。每个查询只有在第一次执行时需要进行空间相交判断,后续执行均为常数复杂度的时间数字比较,且后续执行访问的数据量,最多只比其返回的结果数多1个,最大程度提高查询效率,满足流数据查询与追踪场景对低延迟查询的要求。
[0153]
在对城市中特殊车辆的监控与跟踪中,通过散列映射存储特殊车辆进入重点监测区域的时间戳,把对进入重点监测区域的特殊车辆的id
‑
空间范围查询转变为了id
‑
时间范围查询,避免了大量的空间相交判断,实现了同时快速查询多个任意选中的车辆的实时与历史位置数据。
[0154]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括:
[0155]
当该查询空间范围变为新查询空间范围时,计算查询空间范围变化差集。
[0156]
如果该新查询空间范围落在该查询空间范围内,计算该查询空间范围变化差集中的格网,即减少格网,将该减少格网从该格网集中删除,删除最新轨迹点在该减少格网中的该双向链表,更新该新查询空间范围内的格网的双向链表的相关节点的第一节点指针、第二节点指针、第三节点指针,更新新查询对象的进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0157]
如果该新查询空间范围不在该查询空间范围内,计算所述查询空间范围变化差集中的所述格网,即新增格网,得到新增格网集和新增格网集原点,根据新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集;以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,对查询结果中的轨迹点进行索引;发起新的查询q2,查询当前位置在该新增格网集中的移动对象,得到新查询对象,用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引。
[0158]
如果该新查询空间范围与该查询空间范围相比,既减少一部分,又新增了一部分,则减少的部分为减少格网,新增的部分为新增格网,分别按照前述减少格网、新增格网的部分处理,再予以合并即可。
[0159]
本实施例中,查询空间范围发生了变化,新查询空间范围可能落在该查询空间范围内,也可能不在该查询空间范围内。在对城市中特殊车辆的监控与跟踪中,表现为重点监测区域的减少或增加。比如,因为某片区域正在进行拆迁,整个区域已被封闭施工,不可能有车辆进入,便可将该区域从重点监测区域中去除,这就是查询空间范围的缩小。或者,某区域原为城乡结合部,经过多年发展后,渐趋繁荣,成为了新兴的城市商业区,需要纳入重点监测区域,这就是查询空间范围的扩张。
[0160]
如果该新查询空间范围落在该查询空间范围内,通过计算获得减少格网后,将该减少格网从该格网集中删除,并删除最新轨迹点在该减少格网中的该双向链表;更新该新查询空间范围内的格网的双向链表的相关节点的第一节点指针、第二节点指针、第三节点指针,使得这些指针不再指向处于减少格网内的轨迹点;更新新查询对象的进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0161]
如果该新查询空间范围不在该查询空间范围内,计算所述查询空间范围变化差集中的所述格网,即新增格网,得到新增格网集和新增格网集原点,根据新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集,如图6所示。以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,
对查询结果中的轨迹点进行索引,得到查询对象在新增格网集中的轨迹点。发起新的查询q2,查询当前位置在该新增格网集中的移动对象,得到新查询对象。该新查询对象的当前位置在该查询空间范围外,查询系统中没有对其轨迹点进行索引。用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引,就得到了当前位置在新增新增格网集中的移动对象的轨迹点。通过查询q1、查询q2、查询q3,就补足了新查询空间范围内的轨迹点,完成了对所有轨迹点的索引工作。并且,也没有额外处理多余的轨迹点,使得查询系统的工作量处于最低水平。
[0162]
本实施例的技术方案解决了查询空间范围变化时删除或补充轨迹点的问题。在对城市中特殊车辆的监控与跟踪中,满足了城市管理中对重点监测区域调整的需求,使得查询系统在各个场景中的应用更具适应性。
[0163]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法,其特征在于:
[0164]
该查询系统使用内外存结合的方式工作,该内外存结合的工作方式包括:
[0165]
该查询q第一次执行时,从外存中读取移动对象的轨迹点,与该查询空间范围做空间相交判断。
[0166]
将该查询q的查询空间范围保存在内存中。
[0167]
仅对该查询q的查询对象在该查询空间范围内的轨迹点进行索引,该索引保存在内存中。
[0168]
当该查询对象离开该查询空间范围时,删除该查询对象的轨迹点的索引。
[0169]
本实施例中,查询系统在查询q第一次执行时就将查询需要使用的查询空间范围、轨迹点等都保存在了内存中,查询q之后的所有执行,都是工作在内存中的,从而避免了磁盘写入写出带来的性能消耗。内存的工作效率要远远高于外存,因此大大提升了查询系统的工作效率。
[0170]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法还包括内存清理,该内存清理包括:
[0171]
清除静止对象在该查询空间范围内的轨迹点的索引,该静止对象是查询系统在静止时间内没有收到新轨迹点的查询对象,该静止时间可在该查询系统中预设。
[0172]
清除无效轨迹点的索引,该无效轨迹点是没有出现在查询q的查询结果中的轨迹点。
[0173]
在本实施例中,当移动对象在预设的静止时间内没有上传新的轨迹点数据时,查询系统认为该移动对象处于静止状态,就不再对该移动对象的轨迹点进行查询了。查询系统会对所有处在查询空间范围内的轨迹点进行索引,但是,进行了索引的轨迹点如果没有出现在查询q的查询结果中,即没有哪个查询命中了该轨迹点,即可认为该轨迹点为无效轨迹点,进而将其清除。本实施例的技术方案解决了当查询次数增加时,存储的轨迹点数据过多造成内存负担的问题。
[0174]
在对城市中特殊车辆的监控与跟踪中,进入重点监测区域的特殊车辆如果静止超过一定时间,如两小时,查询系统可以推定其已被相关部门人员截获接管,从而将其轨迹点从查询系统中去除,以减轻查询系统内存的负担。还有一种情况,虽然某辆特殊车辆驶入了重点监测区域,但是该特殊车辆是向相关的管理机构备案或请示过的,所以各个查询都没有将其列入查询范围。对这样的特殊车辆,查询系统也会将其轨迹点删除以减轻查询系统
内存的负担。
[0175]
在一些实施例中,该面向轨迹流数据的连续范围查询的方法中的内存清理还包括:
[0176]
当该查询q有两个以上时,清除无效查询轨迹点的索引,该无效查询轨迹点是只出现在无效查询中的轨迹点,该无效查询是在无效查询时间内没有发起执行的查询q,该无效查询时间可以在该查询系统中预设。
[0177]
清除低效高采样轨迹点的索引,该低效高采样轨迹点,是低效对象的除最新的轨迹点外的轨迹点,该低效对象是指只出现在查询频率最低的查询q中的采样频率大于预设采样频率的移动对象,在清除低效高采样轨迹点后,该查询频率最低的查询q发起查询时,该低效对象的轨迹点通过外存读取。
[0178]
在本实施例中,当查询q在预设的无效查询时间内没有发起执行时,该查询q被认定为无效查询,只出现在无效查询的查询结果中的轨迹点,就是无效查询轨迹点。清除无效查询轨迹点的索引不会对查询的结果产生影响。清除低频查询命中的高采样率轨迹的轨迹点索引,会对查询的结果产生影响,因此,需要通过从外存读取轨迹点来予以弥补。本实施例的技术方案解决了当并发查询数目增加时,存储的轨迹点数据过多造成内存负担的问题。虽然通过外存读取数据会对查询系统的工作效率产生一些影响,但整体来说,内存负担减轻带来的工作效率的提升是更重要的。
[0179]
在对城市中特殊车辆的监控与跟踪中,有些特殊车辆是在指定时段内禁止进入重点监测区域,在非指定时段内可以进入的。这样,在非指定时段内,一些查询就不会发起执行,成为无效查询。只在无效查询的查询结果中出现的特殊车辆,也就不需要继续进行监测了,可以删除其轨迹点的索引。还有一种情况,就是针对一些特殊车辆的查询比其他车辆的频率低,但是这些特殊车辆可能因为某些原因仍然设置了比较高的轨迹点发送频率。如,洒水车。城市中的洒水车行走速度特别慢,针对其的查询也是低频查询。但是,如果洒水车发送轨迹点的频率过高,那么,就会造成其轨迹点数据的使用效率非常低,又占据了较多的内存资源。这时,查询系统就可以采用清除低效高采样轨迹点的索引的方式,自行弥补这个缺陷,在保证查询准确性的情况下,减轻内存负担,提高工作效率。
[0180]
也可以将前述两个实施例中内存清理的轨迹点按照被访问的频率分为三个等级,如图2所示:
[0181]ⅰ级为不会出现在结果集中的轨迹点。如超过5分钟(查询系统设置的最大采样频率)没有更新轨迹点的轨迹,以及只被无效查询(在无效查询时间内未发送执行请求的查询)命中的轨迹点。
[0182]ⅱ级指位于查询空间范围中,但没被任何查询命中的轨迹点。
[0183]ⅲ级指只被低频查询命中的高采样率轨迹点。
[0184]ⅰ和ⅱ两个级别的轨迹点,直接清除也不会对查询产生影响。ⅲ级的轨迹点,需选择当前未清理的请求频率最低的查询q,删除其中采样率高且未被其他高频率的查询命中的轨迹的历史轨迹点,只保留其最新轨迹点。ⅲ级轨迹清理后,后续只保存最新一个轨迹点,关联的查询结果通过外存查询返回。
[0185]
第二方面,本发明实施例提出一种面向轨迹流数据的连续范围查询的系统,该系统包括:
[0186]
位置信息发送模块,索引模块和查询模块。
[0187]
该位置信息发送模块,在移动对象上,用于通过卫星导航系统gnss获得当前位置信息,持续向查询系统发送轨迹点数据,该轨迹点为该移动对象产生的gnss记录,该gnss记录包括该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。
[0188]
该查询模块,用于发起查询q,该查询q的属性包括:唯一标识q
id
、查询空间范围q
range
和发起查询的时间q
t
。
[0189]
该查询模块,包括空间范围查询模块和时间范围查询模块。
[0190]
该空间范围查询模块,用于在发起该查询q时,根据该格网的空间属性进行空间范围查询。
[0191]
该时间范围查询模块,用于在发起该查询q时,根据该双向链表的时间属性进行时间范围查询。
[0192]
该索引模块,用于对该轨迹点进行索引,包括索引结构模块和索引更新模块。
[0193]
该索引结构模块,用于搭建结合格网与双向链表的结构,包括格网模块与链表模块,通过该格网模块管理该轨迹点的空间属性,通过该链表模块管理该轨迹点的时间属性。
[0194]
该格网模块,包括格网划分模块和格网指针模块。
[0195]
该格网划分模块,用于对该查询空间范围进行格网划分获得该格网,以格网预设点坐标作为该格网的唯一标识,即格网坐标,以该查询空间范围内的所有格网为格网集,以预设格网坐标为格网集原点。
[0196]
该格网指针模块,用于管理该格网的格网指针,每一个该格网都有一个格网指针,该格网指针指向该格网范围内最新的该轨迹点,该格网范围内的所有轨迹点按照到达顺序的逆序排序。
[0197]
该链表模块,用于使用该双向链表存储轨迹,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的格网中与该轨迹点到达顺序相邻的两个轨迹点。
[0198]
该索引更新模块,用于在接收新轨迹点时进行索引更新,包括计算与判断模块,顺序更新模块和乱序更新模块。
[0199]
计算与判断模块,用于当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0200]
顺序更新模块,用于当该新轨迹点为顺序到达的最新轨迹点时,将该新轨迹点添加至其所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新其所在的格网的格网指针。
[0201]
乱序更新模块,用于当该新轨迹点不是顺序到达的最新轨迹点时,根据新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新其所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。
[0202]
本实施例中,移动对象是城市中的特殊车辆,如危险化工品车辆、渣土车等。这些特殊车辆需要装配gnss定位系统,每隔一定时间自动向查询系统上传一条gnss记录。该条
gnss记录即该移动对象的一个轨迹点,包括了该gnss记录产生的时间,即时间属性,和该移动对象所处地理位置的坐标,即空间属性。目前,较常使用的是gps系统。如,一辆危险化工品车为移动对象a,则查询系统在接收到该移动对象a的轨迹点,对该轨迹点进行索引后,可以发起查询q。该查询q的属性包括:唯一标识q
id
,查询空间范围q
range
和发起查询的时间q
t
。唯一标识q
id
区分了不同的查询q。查询空间范围是根据城市的管理需要确定的,可将城市的重点监测区域列为查询空间范围。发起查询的时间表示了此次查询的时间,一个查询可以在不同的时间先后发起多次查询。该查询q包括根据格网的空间属性进行的空间范围查询和根据双向链表的时间属性进行的时间范围查询。当查询q第一次执行时,即对查询空间范围内的轨迹点建立索引,同时在查询系统中保存该查询q的设置。
[0203]
索引结构如图3所示。该索引结构采用格网与双向链表结合的结构,通过该格网管理该轨迹点的该空间属性,使用该双向链表管理该轨迹点的该时间属性。该格网通过对该查询空间范围进行格网划分获得。图3最上面一行的g(0,0),g(1,0)
……
代表一个个划分好的格网。每一个格网都有一个格网指针,该格网指针指向该格网范围内最新的轨迹点,如图3中格网g(0,0)指向了轨迹点a6,格网g(1,0)指向了轨迹点a5。a5、a6分别是移动对象a的第5、6个轨迹点。每一个格网范围内的所有轨迹点按照到达顺序的逆序排序,如图3所示,格网g(1,1)先后收到的轨迹点依次为b5,a3,b4,b3。轨迹使用双向链表存储,该双向链表的每个节点为一个轨迹点,该节点的第一节点指针指向该轨迹点在该轨迹中的前一个轨迹点,该节点的第二节点指针和第三节点指针指向该轨迹点所在的格网中与该轨迹点到达顺序相邻的两个轨迹点。如图3所示,a1、a2、a3、a4、a5、a6为先后到达的移动对象a的轨迹点,也是存储移动对象a的轨迹的双向链表的节点。每一个节点的第一节点指针都指向了该轨迹点所在的轨迹中的前一个轨迹点,如图1所示,a6指向了a5,a5指向了a4,a4指向了a3,a3指向了a2,a2指向了a1。在格网g(3,0)中,a1、a2、a4三个轨迹点先后抵达,彼此相邻,因此,它们的第二节点指针、第三节点指针相互指向了彼此。
[0204]
每一个格网都有一个唯一标识,即格网坐标。该格网坐标可以由格网预设点的坐标来确定,该预设点可以是格网的一个顶角,也可以是其中心点,总之,是任一可以确定唯一坐标的点。以该查询空间范围内的所有格网为格网集,以预设点坐标为格网集原点。该预设点可以是该格网集的任一可以明确的格网的明确的一个点,如最下面一行的最左边的那个格网的左下角的顶点,即格网集的左下角的格网的左下角的顶点。
[0205]
该索引更新在接收新轨迹点时进行,当该新轨迹点的空间属性落在该查询q的查询空间范围时,根据该新轨迹点与该格网集原点的相对位置计算该新轨迹点所在的格网,根据该新轨迹点的时间属性判断该新轨迹点是否为顺序到达的最新轨迹点。
[0206]
当该新轨迹点为顺序到达的最新轨迹点时,如图4所示,格网g(3,0)原先有两个轨迹点a1和a2,在接收到顺序到达的最新的轨迹点a4后,将该新轨迹点a4添加至该新轨迹点所在的格网的双向链表的末尾,更新该双向链表的相关轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网的格网指针。
[0207]
当该新轨迹点不是顺序到达的最新轨迹点时,根据该新轨迹点的时间属性在该双向链表中找对应的插入位置,并更新该双向链表的该新轨迹点对应的节点的第一节点指针、第二节点指针、第三节点指针,更新该新轨迹点所在的格网中与该新轨迹点的时间属性相邻的轨迹点对应的节点的第二节点指针、第三节点指针。前文的轨迹定义中提到,轨迹由
时间有序的gnss记录组成。但在现实情况中,由于网络延迟和gnss定位设备故障等原因,gnss记录不一定按照其产生的顺序到达。但现有技术假定接收的gnss记录为有序数据,未针对数据乱序的问题给出准确且有效的解决方案。例如,有两个轨迹点分别产生于10点和10点30分,由于网络延迟等原因,10点产生的轨迹点a迟于10点30分产生的轨迹点b被接收到。现有技术对这两个轨迹点的实际产生时间不予理会,就会在最终的查询结果中造成错误。本实施例的技术方案,对a进行了额外处理,在索引中找到它应该在的存储位置,那么,在下次返回查询结果时,a就也在查询结果中了,查询系统能返回正确的查询结果。
[0208]
在对城市中特殊车辆的监控与跟踪中,查询q以城市中的重点监测区域为查询空间范围。查询系统按照一定的频率发起查询q的执行,每次执行时,查询系统都会解析接收到的轨迹点的位置信息,判断其是否在查询空间范围内。查询系统对落在查询空间范围内的轨迹点建立索引,根据轨迹点的时间属性与空间属性,给出查询空间范围内的实时位置信息与历史位置信息。根据实时位置信息,可以方便地对该特殊车辆进行拦截。根据历史位置信息,可以知道该车辆进入重点监测区域的行驶路线,以实现对其途经区域的安全排查。这是本发明提出的查询方法在实时和历史数据联合查询的场景中的实际应用。
[0209]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统,其特征在于:
[0210]
该查询空间范围为查询缓冲区,该查询缓冲区为该查询空间范围的边界向外扩展ε米的空间范围。
[0211]
本实施例的提出,是基于以下的假设:当前在查询q的缓冲范围ε米中的对象,进入查询范围的可能性远大于在缓冲范围外的对象。以图5为例(实心点为对象当前位置点,空心点为历史时刻的轨迹点):对象a和b当前位于查询q的查询缓冲区内,其进入查询空间范围所需的时间小于对象c,下一时刻对象a和b比对象c更有可能进入查询范围。因此,对移动对象a和b在查询缓冲区中的轨迹点进行索引,可以有效提高查询效率。
[0212]
在对城市中特殊车辆的监控与跟踪中,以城市中的重点监测区域为查询空间范围,可以将该范围向外扩展,如扩展100米,将距离重点监测区域100米内的特殊车辆纳入监测范围,当检测到该车辆的轨迹点落入重点监测区域时,可以第一时间快速响应。
[0213]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括散列映射存储模块,该散列映射存储模块包括:
[0214]
查询对象id存储模块,第一对象指针存储模块和第二对象指针存储模块。
[0215]
该查询对象id存储模块,用于散列映射存储查询对象的id,该查询对象是该轨迹点与该查询q的查询空间范围做空间相交判断的结果非空的移动对象。
[0216]
该第一对象指针存储模块,用于散列映射存储该查询对象的第一对象指针,该第一对象指针指向该查询对象在该查询空间范围的最旧轨迹点。
[0217]
该第二对象指针存储模块,用于散列映射存储该查询对象的第二对象指针,该第二对象指针指向该查询对象在该查询空间范围的最新轨迹点。
[0218]
在本实施例中,散列映射存储查询对象的id如图3最下面一行所示,a、b、c为查询对象的id。每个查询对象都有指向最旧轨迹点的第一对象指针与指向最新轨迹点的第二对象指针。如图3所示,查询对象a的第一对象指针指向了轨迹点a1,第二对象指针指向了轨迹点a6。本实施例的技术方案支持并行的id
‑
时间范围查询,即可以并行进行多个id
‑
时间范围的查询。
[0219]
在对城市中特殊车辆的监控与跟踪中,通过散列映射存储进入重点监测区域的特殊车辆的id和在该重点监测区域内的最新轨迹点及最旧轨迹点,可以对进入重点监测区域的特殊车辆中的多个任意选中的车辆进行指定时间范围内的位置信息的查询。
[0220]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括历史数据检索模块,该历史数据检索模块包括:
[0221]
时间戳存储模块和结果返回模块。
[0222]
该时间戳存储模块,用于散列映射存储该查询对象的进入时间戳,即该查询对象进入该查询空间范围时的轨迹点的时间属性。
[0223]
该结果返回模块,用于从查询q第二次执行开始,沿着该双向链表从最新的轨迹点向历史数据方向检索至该进入时间戳,即返回查询结果。
[0224]
在本实施例的提出是基于以下的洞察:连续查询的结果具有关联性,已经被返回的历史轨迹始终是后续查询结果的子集,直至对象离开该查询的查询空间范围。根据这种特性,查询q第一次执行后,其查询空间范围即保存在查询系统中。查询的后续执行转为id
‑
时间范围查询,无需进行耗时的空间相交判断。本实施例中,在查询q第一次执行后,即使用散列映射存储其命中的所有对象的id,及这些对象进入查询时的时间戳。后续执行只需沿着链表从最新的轨迹点向历史数据方向检索至指定时间戳。具体操作时,可以设定向历史数据方向检索,直到访问到第一个不在返回结果中的数据,越过返回数据的边界,即返回查询结果。每个查询只有在第一次执行时需要进行空间相交判断,后续执行均为常数复杂度的时间数字比较,且后续执行访问的数据量,最多只比其返回的结果数多1个,最大程度提高查询效率,满足流数据查询与追踪场景对低延迟查询的要求。
[0225]
在对城市中特殊车辆的监控与跟踪中,通过散列映射存储特殊车辆进入重点监测区域的时间戳,把对进入重点监测区域的特殊车辆的id
‑
空间范围查询转变为了id
‑
时间范围查询,避免了大量的空间相交判断,实现了同时快速查询多个任意选中的车辆的实时与历史位置数据。
[0226]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括空间范围变化模块,该空间范围变化模块包括:
[0227]
差集计算模块,缩小变化模块和扩大变化模块。
[0228]
该差集计算模块,用于当所述查询空间范围变为新查询空间范围时,计算查询空间范围变化差集。
[0229]
该缩小变化模块,用于当该新查询空间范围落在该查询空间范围内时,计算该查询空间范围变化差集中的格网,即减少格网,将该减少格网从该格网集中删除,删除最新轨迹点在该减少格网中的双向链表,更新该新查询空间范围内的格网的双向链表的相关节点的第一节点指针、第二节点指针、第三节点指针,更新新查询对象的该进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0230]
该扩大变化模块,用于当该新查询空间范围不在该查询空间范围内时,计算该查询空间范围变化差集中的格网,即新增格网,得到新增格网集和新增格网集原点,根据该新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集;以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,对查询结果中的轨迹点进行索引;发起新的查询q2,查询当前位置在该新增格网集
中的移动对象,得到新查询对象,用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引。
[0231]
如果该新查询空间范围与该查询空间范围相比,既减少一部分,又新增了一部分,则减少的部分为减少格网,新增的部分为新增格网,分别按照前述减少格网、新增格网的部分处理,再予以合并即可。
[0232]
本实施例中,查询空间范围发生了变化,新查询空间范围可能落在该查询空间范围内,也可能不在该查询空间范围内。在对城市中特殊车辆的监控与跟踪中,表现为重点监测区域的减少或增加。比如,因为某片区域正在进行拆迁,整个区域已被封闭施工,不可能有车辆进入,便可将该区域从重点监测区域中去除,这就是查询空间范围的缩小。或者,某区域原为城乡结合部,经过多年发展后,渐趋繁荣,成为了新兴的城市商业区,需要纳入重点监测区域,这就是查询空间范围的扩张。
[0233]
如果该新查询空间范围落在该查询空间范围内,通过计算获得减少格网后,将该减少格网从该格网集中删除,并删除最新轨迹点在该减少格网中的该双向链表;更新该新查询空间范围内的格网的双向链表的相关节点的第一节点指针、第二节点指针、第三节点指针,使得这些指针不再指向处于减少格网内的轨迹点;更新新查询对象的进入时间戳,该新查询对象即在该新查询空间范围内的移动对象。
[0234]
如果该新查询空间范围不在该查询空间范围内,计算所述查询空间范围变化差集中的所述格网,即新增格网,得到新增格网集和新增格网集原点,根据新增格网集原点与该格网集原点的位置关系,将该新增格网集与该格网集合并,得到该新查询空间范围的格网集,如图6所示。以该查询对象的id和该新增格网集的空间范围作为属性,发起新的查询q1,对查询结果中的轨迹点进行索引,得到查询对象在新增格网集中的轨迹点。发起新的查询q2,查询当前位置在该新增格网集中的移动对象,得到新查询对象。该新查询对象的当前位置在该查询空间范围外,查询系统中没有对其轨迹点进行索引。用该新查询对象的id和该新查询空间范围作为属性,发起新的查询q3,对查询结果中的轨迹点进行索引,就得到了当前位置在新增新增格网集中的移动对象的轨迹点。通过查询q1、查询q2、查询q3,就补足了新查询空间范围内的轨迹点,完成了对所有轨迹点的索引工作。并且,也没有额外处理多余的轨迹点,使得查询系统的工作量处于最低水平。
[0235]
本实施例的技术方案解决了查询空间范围变化时删除或补充轨迹点的问题。在对城市中特殊车辆的监控与跟踪中,满足了城市管理中对重点监测区域调整的需求,使得查询系统在各个场景中的应用更具适应性。
[0236]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统,其特征在于:
[0237]
该查询系统使用内外存结合的方式工作。该内外存结合的工作方式包括:
[0238]
该查询q第一次执行时,从外存中读取该移动对象的轨迹点,与该查询空间范围做空间相交判断。
[0239]
将该查询q的查询空间范围保存在内存中。
[0240]
仅对该查询q的查询对象在该查询空间范围内的轨迹点进行索引,该索引保存在内存中。
[0241]
当该查询对象离开该查询空间范围时,删除该查询对象的轨迹点的索引。
[0242]
本实施例中,查询系统在查询q第一次执行时就将查询需要使用的查询空间范围、
轨迹点等都保存在了内存中,查询q之后的所有执行,都是工作在内存中的,从而避免了磁盘写入写出带来的性能消耗。内存的工作效率要远远高于外存,因此大大提升了查询系统的工作效率。
[0243]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统还包括内存清理模块,该内存清理模块包括:清除静止对象模块和清除无效轨迹点模块。
[0244]
该清除静止对象模块,用于清除静止对象在该查询空间范围内的轨迹点的索引,该静止对象是该查询系统在静止时间内没有收到新轨迹点的查询对象,该静止时间可在查询系统中预设。
[0245]
该清除无效轨迹点模块,用于清除无效轨迹点的索引,该无效轨迹点是没有出现在该查询q的查询结果中的轨迹点。
[0246]
在本实施例中,当移动对象在预设的静止时间内没有上传新的轨迹点数据时,查询系统认为该移动对象处于静止状态,就不再对该移动对象的轨迹点进行查询了。查询系统会对所有处在查询空间范围内的轨迹点进行索引,但是,进行了索引的轨迹点如果没有出现在查询q的查询结果中,即没有哪个查询命中了该轨迹点,即可认为该轨迹点为无效轨迹点,进而将其清除。本实施例的技术方案解决了当查询次数增加时,存储的轨迹点数据过多造成内存负担的问题。
[0247]
在对城市中特殊车辆的监控与跟踪中,进入重点监测区域的特殊车辆如果静止超过一定时间,如两小时,查询系统可以推定其已被相关部门人员截获接管,从而将其轨迹点从查询系统中去除,以减轻查询系统内存的负担。还有一种情况,虽然某辆特殊车辆驶入了重点监测区域,但是该特殊车辆是向相关的管理机构备案或请示过的,所以各个查询都没有将其列入查询范围。对这样的特殊车辆,查询系统也会将其轨迹点删除以减轻查询系统内存的负担。
[0248]
在一些实施例中,该面向轨迹流数据的连续范围查询的系统的内存清理模块还包括:
[0249]
清除无效查询轨迹点模块和清除低效高采样轨迹点模块。
[0250]
该清除无效查询轨迹点模块,用于当该查询q有两个以上时,清除无效查询轨迹点的索引,该无效查询轨迹点是只出现在无效查询中的轨迹点,该无效查询是在无效查询时间内没有发起执行的查询q,该无效查询时间可以在查询系统中预设。
[0251]
清除低效高采样轨迹点模块,用于当该查询q有两个以上时,清除低效高采样轨迹点的索引,该低效高采样轨迹点,是低效对象的除最新的轨迹点外的轨迹点,该低效对象是指只出现在查询频率最低的查询q中的采样频率大于预设采样频率的移动对象,清除低效高采样轨迹点后,该查询频率最低的查询q发起查询时,该低效对象的轨迹点通过外存读取。
[0252]
在本实施例中,当查询q在预设的无效查询时间内没有发起执行时,该查询q被认定为无效查询,只出现在无效查询的查询结果中的轨迹点,就是无效查询轨迹点。清除无效查询轨迹点的索引不会对查询的结果产生影响。清除低频查询命中的高采样率轨迹的轨迹点索引,会对查询的结果产生影响,因此,需要通过从外存读取轨迹点来予以弥补。本实施例的技术方案解决了当并发查询数目增加时,存储的轨迹点数据过多造成内存负担的问题。虽然通过外存读取数据会对查询系统的工作效率产生一些影响,但整体来说,内存负担
减轻带来的工作效率的提升是更重要的。
[0253]
在对城市中特殊车辆的监控与跟踪中,有些特殊车辆是在指定时段内禁止进入重点监测区域,在非指定时段内可以进入的。这样,在非指定时段内,一些查询就不会发起执行,成为无效查询。只在无效查询的查询结果中出现的特殊车辆,也就不需要继续进行监测了,可以删除其轨迹点的索引。还有一种情况,就是针对一些特殊车辆的查询比其他车辆的频率低,但是这些特殊车辆可能因为某些原因仍然设置了比较高的轨迹点发送频率。如,洒水车。城市中的洒水车行走速度特别慢,针对其的查询也是低频查询。但是,如果洒水车发送轨迹点的频率过高,那么,就会造成其轨迹点数据的使用效率非常低,又占据了较多的内存资源。这时,查询系统就可以采用清除低效高采样轨迹点的索引的方式,自行弥补这个缺陷,在保证查询准确性的情况下,减轻内存负担,提高工作效率。
[0254]
也可以将前述两个实施例中内存清理模块清理的轨迹点按照被访问的频率分为三个等级,如图2所示:
[0255]ⅰ级为不会出现在结果集中的轨迹点。如超过5分钟(查询系统设置的最大采样频率)没有更新轨迹点的轨迹,以及只被无效查询(在无效查询时间内未发送执行请求的查询)命中的轨迹点。
[0256]ⅱ级指位于查询空间范围中,但没被任何查询命中的轨迹点。
[0257]ⅲ级指只被低频查询命中的高采样率轨迹点。
[0258]ⅰ和ⅱ两个级别的轨迹点,直接清除也不会对查询产生影响。ⅲ级的轨迹点,需选择当前未清理的请求频率最低的查询q,删除其中采样率高且未被其他高频率的查询命中的轨迹的历史轨迹点,只保留其最新轨迹点。ⅲ级轨迹清理后,后续只保存最新一个轨迹点,关联的查询结果通过外存查询返回。
[0259]
为了充分说明本发明提出的技术方案的实际效果,根据本发明提出的一些具体实施方式进行了对比实验,并给出如下的对比条件与实验数据:
[0260]
使用数据集porto作为实验数据集,图7为该数据集的统计信息。该数据集的采集时间为2013年07月01日至2014年06月30日,移动对象为葡萄牙波尔图市的442辆出租车,采样频率约为15秒。
[0261]
实验环境的服务器配置为centos 7.4,16核cpu,32gb内存和500gb硬盘。
[0262]
对比内容为查询效率和索引更新的效率。
[0263]
本文提出的方法为a,综合使用了本发明提出的格网与双向链表结合的索引方法,内外存结合的查询机制和内存清理机制,并最大程度地减少空间相交判断的次数和需检索的数据次数。
[0264]
对比方法为b,基于sole实现。该方法使用格网作为索引结构,只保存对象的当前位置,其余的历史轨迹点从外存中查询。
[0265]
图8和图9展示查询尺寸对于查询效率的影响。分别设置查询的空间范围为1、3、5、7、10km2,记录每次查询所需的平均时间。两种方法中,初始查询(查询的第一次执行)都需要执行一次外存查询,因此效率基本相同;而在后续查询中,只要查询范围不发生变化,方法a只访问内存,且只需对极少数的数据做空间相交判断,并对极少的数据进行检索,因此查询效率远高于方法b。
[0266]
图10展示对象数目对索引时间的影响。分别设置对象数目为0.8k、1.6k、3k、7k、
14k、28k和55k,对比保存全量数据集所需的时间。由图可得,对象数目增加时,数据的到达速率增加,数据插入所需时间随之增长。方法b只需要将最新到达的轨迹点保存至对应的格网,而方法a还需要维护每条轨迹的链表结构,因此方法b的数据插入效率要高于方法a。但由上一组实验结果可得,方法a维护的索引结构使其在查询效率上有远高于方法b的表现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。