1.本发明属于稀疏表示,监督字典学习的技术领域,具体涉及一种基于数据驱动的有监督字典学习音频分类方法、系统及介质。
背景技术:
2.传统的字典学习公式最大限度地减小了给定信号与其在学习字典上的稀疏表示之间的重构误差。虽然这个方法对于解决信号去噪很方便,但是由于它的最终目标是通过学习到的字典去获得训练信号的区分性分解,所以它可能不适用于分类任务。由于传统字典学习技术在分类方面的局限性,有监督字典学习得到了广泛的应用。
3.ramirez等人建议通过加强字典的正交性来获取不同的信息,使学习字典尽可能的不同,即一个类对应一个字典;fulkerson等人提出首先学习一个非常大的字典,然后根据包含凝聚信息瓶颈(aib)的预定义准则合并字典的原子以起到压缩字典的效果;mairal等人提出联合学习字典与分类任务;随后张和杨等人提出将类别标签嵌入字典以及稀疏编码的学习当中以达到最小化类内差异与最大化类间差异的作用。
技术实现要素:
4.本发明的主要目的在于克服传统字典学习方法对音频识别任务的缺点与不足,提供一种基于数据驱动的有监督字典学习音频分类方法、系统及介质,针对每个不同的类,学习不同的对应的字典,以提取异构信息进行分类,通过促进类特定字典之间的成对正交性和控制音频片段在这些字典上分解的稀疏性结构,寻求最小化类内的同质性和最大化类间的可分离性。
5.为了达到上述目的,本发明采用以下技术方案:
6.本发明的一个方面,提供了一种基于数据驱动的有监督字典学习音频分类方法,包括下述步骤:
7.s1、确定样本集类别数c,利用输入的样本x
n
,及其对应的类标签y
n
训练c个特定类字典d
c
,c∈[1,c];
[0008]
s2、利用已训练的字典d
c
,c∈[1,c],得出输入样本x
n
的稀疏编码a
n
,并将稀疏编码作为特征,训练svm分类器;
[0009]
s3、利用已训练的字典d
c
,c∈[1,c],和已训练的svm分类器对输入样本x
n
进行分类,输出预测标签y
~n
。
[0010]
作为优选的技术方案,所述训练c个特定类字典d
c
,c∈[1,c]如下:
[0011]
s11、初始化字典d
c0
,学习率η0,学习率更新率α,迭代次数t;
[0012]
s12、确定损失函数j;
[0013]
s13、开始次数为t的迭代求解过程,当迭代次数为t时,固定字典d
t
‑1,计算稀疏编码集合a
t
;
[0014]
s14、固定稀疏编码的集合a
t
,更新字典d
ct
;
[0015]
s15、t=t 1,进入下一次迭代,直至t=t。
[0016]
作为优选的技术方案,所述损失函数j具体形式为:
[0017]
j(a,d)=j1(d,a) μj2(d,a) λj3(a) γ1j4(a) γ2j5(d);
[0018][0019][0020][0021][0022][0023]
其中,μ为样本约束参数,λ为分类器约束参数,γ1为稀疏编码约束参数,γ2为字典学习约束参数。
[0024]
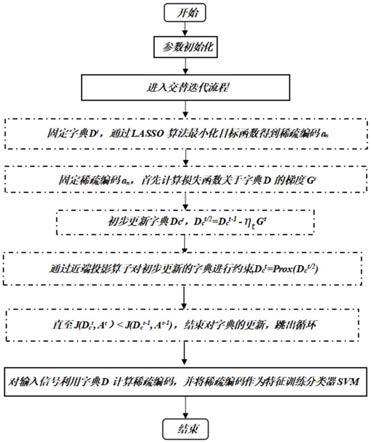
作为优选的技术方案,所述开始次数为t的迭代求解过程,当迭代次数为t时,固定字典d
t
‑1,计算稀疏编码集合a
t
的步骤具体通过lasso算法最小化损失函数j(d
t
‑1,a
t
)得到a
t
。
[0025]
作为优选的技术方案,所述固定稀疏编码的集合a
t
,更新字典d
ct
的步骤具体如下:
[0026]
s141、计算损失函数j关于字典d的梯度g
t
;
[0027]
s142、初步更新,d
ct/2
=d
ct
‑1‑
ηg
t
;
[0028]
s143、通过近端投影算子prox对初步更新的字典进行约束;
[0029]
s144、直至j(d
ct
,a
t
)<j(d
ct
‑1,a
t
‑1),结束对字典的更新。
[0030]
作为优选的技术方案,所述训练svm分类器具体为:训练得一个超平面,将不同的样本分开;其测试阶段即为判断样本在超平面所分割空间的哪一边。
[0031]
本发明的另一个方面,还提供了一种基于数据驱动的有监督字典学习音频分类系统,应用于上述的基于数据驱动的有监督字典学习音频分类方法,包括字典训练模块、svm分类器训练模块、预测输出模块;
[0032]
所述字典训练模块用于确定样本集类别数c,利用输入的样本x
n
,及其对应的类标签y
n
训练c个特定类字典d
c
,c∈[1,c];
[0033]
所述svm分类器训练模块用于利用已训练的字典d
c
,c∈[1,c],得出输入样本x
n
的稀疏编码a
n
,并将稀疏编码作为特征,训练svm分类器;
[0034]
所述预测输出模块用于利用已训练的字典d
c
,c∈[1,c],和已训练的svm分类器对输入样本x
n
进行分类,输出预测标签y
~n
。
[0035]
本发明的另一个方面,还提供了一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的基于数据驱动的有监督字典学习音频分类方法。
[0036]
本发明与现有技术相比,具有如下优点和有益效果:
[0037]
(1)本发明公开的基于数据驱动的有监督字典学习音频识别方法通过每个类学习一个字典来实现最小化类内均匀性,最大化类的可分性,提高稀疏性以控制信号在字典上分解的复杂性,同时最小化基于类的重构错误,并提高字典的成对正交性;
[0038]
(2)本发明提出的方法能够广泛应用于多个场景中,如计算听觉场景识别和音乐和弦识别;其在数据集上的测试也相对稳定,泛化能力表现优秀。
[0039]
(3)本发明提出的方法能够精确提升对音频的识别,对语音认证、音频辨伪等安全计算领域具有优异的性能。
附图说明
[0040]
图1是本发明实施例基于数据驱动的有监督字典学习音频分类方法的实现步骤流程图;
[0041]
图2是本发明实施例特定类字典d
c
的学习步骤流程图;
[0042]
图3是本发明实施例svm分类器的训练步骤流程图;
[0043]
图4是本发明实施例测试阶段进行分类并输出预测标签的流程示意图;
[0044]
图5是本发明实施例在rouen数据集上学习的成对特定类字典的相似性图;
[0045]
图6是本发明实施例在音乐和弦数据集上学习的成对特定类字典的相似性图;
[0046]
图7是本发明实施例基于数据驱动的有监督字典学习音频分类系统的结构示意图;
[0047]
图8是本发明实施例的存储介质的结构示意图。
具体实施方式
[0048]
为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0049]
实施例
[0050]
如图1所示,本实施例提供了一种基于数据驱动的有监督字典学习音频分类方,包括以下步骤:
[0051]
s1、确定样本集类别数c,利用输入的样本x
n
,及其对应的类标签y
n
训练c个特定类字典d
c
,c∈[1,c],如图2所示,具体包括以下步骤:
[0052]
s11、初始化字典d
c0
,学习率η0,学习率更新率α,迭代次数t;
[0053]
s12、确定损失函数j;
[0054]
更进一步的,所述损失函数j具体形式为:
[0055]
j(a,d)=j1(d,a) μj2(d,a) λj3(a) γ1j4(a) γ2j5(d);
[0056][0057][0058][0059]
[0060][0061]
其中,μ为样本约束参数,λ为分类器约束参数,γ1为稀疏编码约束参数,γ2为字典学习约束参数。
[0062]
s13、开始次数为t的迭代求解过程,当迭代次数为t时,固定字典d
t
‑1,计算稀疏编码a
t
;
[0063]
更进一步的,所述稀疏编码a
t
,通过lasso算法最小化损失函数j(d
t
‑1,a
t
)得到。
[0064]
s14、固定稀疏编码a
t
,更新字典d
ct
,包括以下步骤:
[0065]
s141、计算损失函数j关于字典d的梯度g
t
;具体的,损失函数为:
[0066][0067]
其中:
[0068][0069][0070][0071]
梯度为:
[0072][0073]
其中:
[0074][0075][0076][0077]
s142、初步更新,d
ct/2
=d
ct
‑1‑
ηg
t
;
[0078]
s143、通过近端投影算子prox对初步更新的字典进行约束;
[0079]
s144、直至j(d
ct
,a
t
)<j(d
ct
‑1,a
t
‑1),结束对字典的更新。
[0080]
s15、t=t 1,进入下一次迭代,直至t=t。
[0081]
s2、利用已训练的字典d
c
,c∈[1,c],得出输入样本x
n
的稀疏编码a
n
,并将稀疏编码作为特征,训练svm分类器,如图3所示;
[0082]
所述训练svm分类器具体为:训练得一个超平面,将不同的样本分开;其测试阶段即为判断样本在超平面所分割空间的哪一边。
[0083]
s3、在测试阶段,利用已训练的字典d
c
,c∈[1,c],和已训练的svm分类器对输入样本x
n
进行分类,输出预测标签y
~n
,如图4所示。
[0084]
在本实施例中,对两种不同的音频信号分类问题进行了实验,分别是计算听觉场景识别和音乐和弦识别:
[0085]
(1)在计算听觉识别问题上,本发明在east anglia和litis rouen数据集上均进行了实验。表1列出了本发明的方法在这个问题上与其他方法的比较结果;
[0086][0087][0088]
表1.本发明的方法在计算听觉识别问题上与其他方法的比较结果
[0089]
由表1易知,本发明的方法与某些方法相比已经完全胜出,在两个数据集上的测试也相对稳定,泛化能力表现优秀,表明本发明的方法还有一定的前景可以探索。图5展示了不同字典的成对相似性,可以看出,在计算听觉场景识别问题上,不同类别对应的字典还是有较大的相似性,即不同类别可能提取到的特征是相似的,不利于分类,越来越多的类别使得强制执行成对字典不相似难度增加。
[0090]
(2)在音乐和弦识别问题上,本发明制作了一个包含14个不同类别的2156个音乐和弦样本,每个样本持续时间为2s,频率为44100hz。用本发明的方法与一些传统特征相比较,得出如表2所示的结果;
[0091]
featuresmusic chordchroma0.19
±
0.01interpolated psd0.15
±
0.02
spectrogram pooling0.14
±
0.01dictionary learning0.66
±
0.01
[0092]
表2.本发明的方法在音乐和弦识别问题上与传统特征的比较结果
[0093]
由表2易知,本发明的方法优于其他传统特征。图6展示了不同字典的成对相似性,可以看到,不同字典的成对相似性最大值是在左上
‑
右下的对角线上,说明本发明的方法在音乐和弦识别数据集上达到了需要的效果,即不同类别对应的字典能够提取互异的信息,这也是本发明的方法战胜其他传统特征的一个很好的说明。
[0094]
如图7所示,在本技术的另一个实施例中,提供了一种基于数据驱动的有监督字典学习音频分类系统,该系统包括字典训练模块、svm分类器训练模块、预测输出模块;
[0095]
所述字典训练模块用于确定样本集类别数c,利用输入的样本x
n
,及其对应的类标签y
n
训练c个特定类字典d
c
,c∈[1,c];
[0096]
所述svm分类器训练模块用于利用已训练的字典d
c
,c∈[1,c],得出输入样本x
n
的稀疏编码a
n
,并将稀疏编码作为特征,训练svm分类器;
[0097]
所述预测输出模块用于利用已训练的字典d
c
,c∈[1,c],和已训练的svm分类器对输入样本x
n
进行分类,输出预测标签y
~n
。
[0098]
在此需要说明的是,上述实施例提供的系统仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能,该系统是应用于上述实施例的基于数据驱动的有监督字典学习音频分类方法。
[0099]
如图8所示,在本技术的另一个实施例中,还提供了一种存储介质,存储有程序,所述程序被处理器执行时,实现基于数据驱动的有监督字典学习音频分类方法,具体为:
[0100]
s1、确定样本集类别数c,利用输入的样本x
n
,及其对应的类标签y
n
训练c个特定类字典d
c
,c∈[1,c];
[0101]
s2、利用已训练的字典d
c
,c∈[1,c],得出输入样本x
n
的稀疏编码a
n
,并将稀疏编码作为特征,训练svm分类器;
[0102]
s3、利用已训练的字典d
c
,c∈[1,c],和已训练的svm分类器对输入样本x
n
进行分类,输出预测标签y
~n
。
[0103]
应当理解,本技术的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0104]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。