1.本发明涉及计算机视觉领域,特别涉及一种基于自适应正则深度聚类的组织病理图像分类方法。
背景技术:
2.组织病理学已成为癌症诊断的重要手段,癌症的诊断仍依赖于组织病理学活检,尤其是用于诊断良恶性肿瘤的时候,由训练有素的病理学家进行组织病理学评估仍然是癌症诊断的金标准。有经验的医生在诊断癌症的时候通常需要反复检查浏览并分析癌症的组织病理学图像,这是一项艰巨的任务.因此,对客观分类的需求筛查更为迫切,这有助于及时有效的治疗和诊断。这种困境推动了深度学习在组织病理学图像分析的发展。近年来,深度学习已经在很多计算机视觉任务(如自然图像分类)得到了发展,并且它也应用到组织病理图像分类并取得了好的结果,然后,由于组织病理图像存在很大的差异,数据的标注需要有经验的病理学家反复并且仔细的勾画感兴趣区域。目前存在足够的无标注的病理图像,然后,深度学习的性能受限于数据标注的质量,所以,如何有效的利用这些无标注数据去提高组织病理分析的性能依旧是一个开放的问题。
3.自监督学习提供了一个可能的方法去缓解数据标注的问题。自监督学习通过去学习一个代理任务从而去学习有效的表征,自监督学习的流程通常有两部分组成:1.在无标注的数据上面预训练一个特征提取网络。2.使用预训练模型作为初始化权重来训练一个组织病理图片分类模型。步骤1使得网络从无标注的数据中学习有用的语义的特征,这能够在少量标注数据的情况下提高后续的分类任务的性能。
4.自监督学习在自然场景图像中得到了应用,取得了良好的效果。然而,自然场景图像和医学图像在数据量、特征和任务规格上有很大的差异。以往的研究已经证明了自监督学习在医学图像处理中的有效性,如脑区域分割、细胞核分割、器官分割和亚型分析。例如,spitzer等人预测了从同一个大脑中采集的两个切片之间的3d距离,从而对神经网络进行预训练。与随机初始化相比,对预训练的权值进行微调可以提高分割效果。xie等人通过两个子任务(按比例三元组学习和计数排序)对网络进行预训练,使用预训练权重的网络提高了核实例的分割精度。abbet等人联合学习了组织区域的表示以及聚类的度量,以获得它们的潜在的表征。
技术实现要素:
5.本发明的技术目的在于,在有标注数据的样本数不足导致深度学习性能受限的情况下,提供一种基于自适应正则深度聚类的组织病理图像分类方法来利用无标注数据,缓解数据标注的需求,从而提高深度学习在医疗病理图像的分类性能。
6.为了实现上述目的,本发明的技术方案如下:
7.一种基于自适应正则深度聚类的组织病理图像分类方法,包括以下步骤:
8.步骤1,预训练:通过病理图像特征提取网络对无标签的病理图像进行表征提取;
通过分类器处理表征得到预测标签;对表征进行聚类并获得聚类损失,同时将聚类产生的簇作为伪标签,然后根据预测标签和伪标签得到网络损失;引入自适应的正则项因子来动态调节聚类损失的权重,并结合网络损失和聚类损失得到总的无监督损失;通过无监督损失对病理图像特征提取网络进行参数调整;迭代地执行上述步骤,直到由病理图像特征提取网络和聚类组成的无监督模型稳定即完成预训练,得到预训练的模型参数权重;
9.步骤2,基于步骤1中得到的模型参数权重作为病理图片分类模型的初始化权重,并采用有标签的病理图像进行训练以完成调参,得到训练完成的病理图片分类模型;
10.步骤3,将待分类的病理图像输入至训练完成的病理图片分类模型中进行分类,得到分类结果。
11.一种基于自适应正则深度聚类的组织病理图像分类方法,所述步骤1中,所述的病理图像特征提取网络为vgg
‑
19卷积神经网络,表征提取是将无标签的病理图像输入到病理图像特征提取网络中,并将输出f
θ
(x
n
)作为图像的表征。
12.所述的基于自适应正则深度聚类的组织病理图像分类方法,所述步骤1中,通过分类器处理表征得到预测标签包括以下步骤:
13.将提取到的图像的表征f
θ
(x
n
)通过分类器处理来获得预测标签
[0014][0015]
其中c
w
是一个参数化的分类器。
[0016]
所述的基于自适应正则深度聚类的组织病理图像分类方法,所述的分类器c
w
是由一个linear全连接层连接softmax函数而成。
[0017]
所述的基于自适应正则深度聚类的组织病理图像分类方法,所述步骤1中,对表征进行聚类并获得聚类损失,同时将聚类产生的簇作为伪标签,然后根据预测标签和伪标签得到网络损失包括以下步骤:
[0018]
1)将提取到的图像的表征f
θ
(x
n
)进行聚类;在聚类的过程中,通过最小化作为样本点的表征f
θ
(x
n
)和聚类中心之间的距离来优化聚类过程从而得到聚类损失;聚类损失l
c
为:
[0019][0020]
其中,n是无标签病理图像的样本数,c
n
是样本x
n
所对应的聚类中心;
[0021]
2)将聚类产生的簇作为伪标签,根据伪标签和预测标签得到网络损失l
n
,:
[0022][0023]
其中,是特征提取网络预测的标签,y
n
是聚类产生的簇即伪标签,l是多类逻辑损失。
[0024]
所述的基于自适应正则深度聚类的组织病理图像分类方法,在进行第一次聚类时,预先设定聚类的数量,并在后续的迭代过程中保持不变。
[0025]
所述的基于自适应正则深度聚类的组织病理图像分类方法,所述的步骤1中,引入自适应的正则项因子来动态调节聚类损失的权重,并结合网络损失和聚类损失得到总的无监督损失包括以下步骤:
[0026]
引入自适应的正则项因子g(c
t
‑1;c
t
)去动态的调节聚类损失的权重,结合网络损失和聚类损失,得到总的无监督损失l
j
:
[0027]
l
j
=l
n
g(c
t
‑1;c
t
)l
c
[0028]
其中,l
n
为网络损失,l
c
为聚类损失,g(c
t
‑1;c
t
)是一个自适应的正则项因子,为:
[0029][0030]
其中,nmi(c
t
‑1;c
t
)是衡量模型的稳定性的参数,c
t
是第t次迭代的聚类分配,对第t
‑
1次迭代和第t次迭代测量nmi来衡量模型的稳定性,定义为:
[0031][0032]
其中,i是互信息,h是熵。
[0033]
所述的基于自适应正则深度聚类的组织病理图像分类方法,所述的步骤1中,通过无监督损失对病理图像特征提取网络进行参数调整,是根据无监督损失l
j
,基于交叉熵损失函数来对病理图像特征提取网络进行反向传播以进行优化。
[0034]
一种电子设备,包括处理器和存储器,所述存储器上存储有计算机程序,当所述计算机程序被处理器执行时,使得处理器实现如前述的方法。
[0035]
一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序被处理器执行时,使得处理器实现如前述的方法。
[0036]
本发明的技术效果在于,通过迭代地对学习到的表征进行聚类,并利用将簇分配作为伪标签来学习网络的参数。结合网络损失和聚类损失对网络进行微调,本发明设计了一个自适应的正则项因子去动态的调节聚类损失的权重,从而最终得到预训练模型的权重。然后使用预训练模型作为初始化权重来训练一个组织病理图片分类模型。相比于随机初始化权重的网络,使用本发明训练出来的预训练权重的模型,只需使用10%的标记数据就可以和随机初始化权重的网络使用100%的标记数据达到相同效果。且使用本发明预训练权重的网络收敛速度更快。
附图说明
[0037]
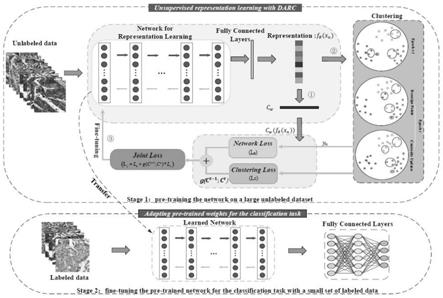
图1为本发明的流程图。
具体实施方式
[0038]
下面结合附图对本发明的实施例进行详细阐述。
[0039]
参见图1,本实施例所提供的方法包括以下步骤:
[0040]
步骤1,预训练:
[0041]
首先通过病理图像特征提取网络对无标签的病理图像进行表征提取。本实施例中所采用的病理图像特征提取网络为vgg
‑
19卷积神经网络。表征提取是将无标签的病理图像输入到病理图像特征提取网络中,并将输出f
θ
(x
n
)作为图像的表征。
[0042]
然后通过分类器处理表征得到预测标签。即通过分类器将提取到的图像的表征f
θ
(x
n
)进行处理来获得预测标签
[0043]
[0044]
其中c
w
是一个参数化的分类器。本实施例中的分类器c
w
是由一个linear全连接层连接softmax函数而成,实际实施中也可采用其他类型的分类器来实现。在本实施例的实施过程中,该分类器不变化。
[0045]
接下来对表征进行聚类并获得聚类损失,即首先将提取到的图像的表征f
θ
(x
n
)进行聚类。本实施例在进行第一次聚类时,预先设定聚类的数量,并在后续的迭代过程中保持不变。其中聚类数量一般设置为大于病理图片可能出现的分类数量。而在聚类的过程中,通过最小化作为样本点的表征f
θ
(x
n
)和聚类中心之间的欧氏距离来优化聚类过程从而得到聚类损失。其中聚类损失l
c
通过下式计算:
[0046][0047]
其中,n是无标签病理图像的样本数,c
n
是样本x
n
所对应的聚类中心。
[0048]
再将聚类产生的簇作为伪标签,然后根据预测标签和伪标签得到网络损失l
n
,:
[0049][0050]
其中,是特征提取网络预测的标签,y
n
是聚类产生的簇即伪标签,l是多类逻辑损失。
[0051]
得到网络损失和聚类损失后,本实施例引入自适应的正则项因子g(c
t
‑1;c
t
)去动态的调节聚类损失的权重,结合网络损失和聚类损失,得到总的无监督损失l
j
:
[0052]
l
j
=l
n
g(c
t
‑1;c
t
)l
c
[0053]
其中,l
n
为网络损失,l
c
为聚类损失,g(c
t
‑1;c
t
)是一个自适应的正则项因子,为:
[0054][0055]
其中,nmi(c
t
‑1;c
t
)是衡量模型的稳定性的参数,c
t
是第t次迭代的聚类分配,对第t
‑
1次迭代和第t次迭代测量nmi来衡量模型的稳定性,定义为:
[0056][0057]
其中,i是互信息,h是熵。
[0058]
然后根据无监督损失l
j
,基于交叉熵损失函数来对病理图像特征提取网络进行反向传播以进行优化。这样迭代地执行上述步骤,直到由病理图像特征提取网络和聚类组成的无监督模型稳定,即上面提到的测量nmi来衡量模型的稳定性。稳定后即完成预训练,得到预训练的模型参数权重。
[0059]
步骤2,基于步骤1中得到的模型参数权重作为病理图片分类模型的初始化权重,并采用有标签的病理图像进行训练以完成调参。本实施例在执行本步骤时,通过将有标签的病理图片数据划分为训练集,测试集和验证集。同时将训练集数据划分为不同的比例以测试模型,其中比例为1%,10%,50%,100%,然后在验证集上调参,将最后调参得到的模型在测试集上测试。最终得到训练完成的病理图片分类模型
[0060]
步骤3,将待分类的病理图像输入至训练完成的病理图片分类模型中进行分类,得
到分类结果。
[0061]
以网上公开的nct
‑
crc
‑
he
‑
100k,pcam和lc25000数据集测试模型,骨架网络为vgg
‑
19。以本实施例所得到的预训练模型作为初始化权重来训练一个组织病理图片分类模型,同时采用一个随机初始化权重的网络来作为对比。结果显示,采用本实施例训练出来的的预训练权重,只需使用10%的标记数据,即可和随机初始化权重的网络使用100%的标记数据具有相同效果。并且使用本实施例预训练权重的网络收敛速度更快,而通过t
‑
分布随机邻域嵌入(t
‑
sne)证明了本实施例所学习的表征是具有普遍性和区别性。由此可见本发明方法的有效性。
[0062]
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
[0063]
本实施例还提供了一种电子设备和一种计算机可读介质。
[0064]
其中电子设备,包括:
[0065]
一个或多个处理器;
[0066]
存储装置,用于存储一个或多个程序,
[0067]
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现前述的方法。
[0068]
具体使用中,用户能够通过作为终端设备的电子设备并基于网络来与同样作为电子设备的服务器进行交互,实现接收或发送消息等功能。终端设备一般是设有显示装置、基于人机界面来使用的各种电子设备,包括但不限于智能手机、平板电脑、笔记本电脑和台式电脑等。其中终端设备上根据需要可安装各种具体的应用软件,包括但不限于网页浏览器软件、即时通信软件、社交平台软件、购物软件等。
[0069]
服务器是用于提供各种服务的网络服务端,如对收到的从终端设备传输过来的病理图片数据提供相应分类服务的的后台服务器。以实现对病理图片数据进行分类,并将最终的分类结果返回至终端设备。
[0070]
本实施例所提供的分类方法一般由服务器执行,在实际运用中,在满足必要条件下,终端设备亦可直接执行分类。
[0071]
类似的,本发明的计算机可读介质,其上存储有计算机程序,所述程序被处理器执行时实现本发明实施例的分类方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。