神经网络操作方法和设备
1.本技术要求于2020年9月8日在韩国知识产权局提交的第10-2020-0114724号韩国专利申请的权益,所述韩国专利申请的全部公开出于所有目的通过引用包含于此。
技术领域
2.下面的描述涉及神经网络操作方法和设备。
背景技术:
3.在过去,为了执行逐元素求和(elementwise-sum)操作,在存储器中以单个特征图的形式连续布置两个特征图之后,乘积累加(mac)运算器执行1
×
1卷积。
4.逐元素操作通常不需要单独的权重。然而,当mac运算器将执行逐元素操作时,需要用于乘法的权重。
5.另外,存在以下限制:mac运算器应具有可配置的数据路径,并且mac运算器的一部分应被可控制到启用状态或禁用状态,以用于逐通道mac操作。因此,存在提高硬件资源使用率和处理速度的需要。
技术实现要素:
6.提供本发明内容来以简化的形式介绍在以下具体实施方式中进一步描述的构思的选择。本发明内容不意在确认要求权利的主题的关键特征或必要特征,也不意在用于帮助确定要求权利的主题的范围。
7.在一个总体方面,一种计算机实施的神经网络操作方法包括:将将被执行神经网络的操作的矩阵存储在存储器中;通过混洗器从存储器读取将被执行神经网络的操作的矩阵;通过混洗器对矩阵的元素的一部分进行混洗,并将混洗的矩阵发送给运算器;和通过运算器基于混洗的矩阵执行所述操作的替换操作。
8.通过混洗器对矩阵的元素的一部分进行混洗的步骤包括:通过对矩阵的元素的一部分执行预定的读取操作或预定的存储操作,对矩阵的元素的一部分进行混洗。
9.所述神经网络操作方法还包括:通过混洗器将混洗的矩阵发送给存储器进行存储;和通过运算器从存储器读取混洗的矩阵。
10.在另一总体方面,一种计算机实施的神经网络操作方法包括:通过混洗器从运算器接收将被执行神经网络的操作的矩阵;通过混洗器对矩阵的元素的一部分进行混洗,并将混洗的矩阵存储在存储器中;通过运算器从存储器读取混洗的矩阵;和通过运算器基于混洗的矩阵执行所述操作的替换操作。
11.通过混洗器对矩阵的元素的一部分进行混洗的步骤包括:通过对矩阵的元素的一部分执行预定的存储操作,对矩阵的元素的一部分进行混洗。
12.混洗的步骤包括:对包括在矩阵中的第一矩阵的行和列中的任一者或两者以及包括在矩阵中的第二矩阵的行和列中的任一者或两者进行混洗。
13.混洗的步骤包括:将第一矩阵的行或列中的一行或一列存储在存储器中;将第一
矩阵的行或列中的另一行或另一列存储在存储器中的与存储第一矩阵的行或列中的所述一行或所述一列的位置相距预定间隔的位置处;和将第二矩阵的行或列中的一行或一列存储在存储器中的存储第一矩阵的行或列中的所述一行或所述一列的位置与存储第一矩阵的行或列中的所述另一行或所述另一列的位置之间。
14.在另一总体方面,一种神经网络操作设备包括:存储器,被配置为存储将被执行神经网络的操作的矩阵;和处理器,被配置为:从存储器读取将被执行神经网络的操作的矩阵;对矩阵的元素的一部分进行混洗,并且基于混洗的矩阵执行所述操作的替换操作。
15.处理器还被配置为:通过对矩阵的元素的一部分执行预定的读取操作或预定的存储操作,对矩阵的元素的一部分进行混洗。
16.在另一总体方面,一种神经网络操作设备包括:混洗器,被配置为从运算器接收将被执行神经网络的操作的矩阵,对矩阵的元素的一部分进行混洗,并将混洗的矩阵存储在存储器中;存储器,被配置为存储混洗的矩阵;和运算器,被配置为从存储器读取混洗的矩阵,并且基于混洗的矩阵执行所述操作的替换操作。
17.在一个总体方面,一种神经网络操作方法包括:存储将被执行神经网络的操作的矩阵;对矩阵的元素的一部分进行混洗;和基于混洗的矩阵执行所述操作的替换操作。
18.混洗的步骤可包括:对包括在矩阵中的第一矩阵的行和列中的任一者或两者以及包括在矩阵中的第二矩阵的行和列中的任一者或两者进行混洗。
19.混洗的步骤还可包括:存储第一矩阵的行或列中的一行或一列;将第一矩阵的行或列中的另一行或另一列存储在与存储所述一行或所述一列的位置相距预定间隔的位置处;和将第二矩阵的行或列中的一行或一列存储在存储所述一行或所述一列的位置与存储所述另一行或所述另一列的位置之间。
20.预定间隔可基于将被执行所述操作的矩阵的数量而被确定。
21.混洗的步骤可包括:将第一矩阵的行或列中的一行或一列发送给运算器以用于替换操作;和将第二矩阵的行或列中的一行或一列发送给运算器,以便与所述一行或所述一列邻近地被操作。
22.所述操作可包括逐元素求和操作和逐元素最大操作中的任一者或两者。
23.替换操作可包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何两种或更多种的任何组合。
24.执行的步骤可包括:当在所述操作之后将执行另一操作时,将替换操作和所述另一操作合并。
25.合并的步骤可包括:确定替换操作和所述另一操作是否是可合并的;和基于确定结果将替换操作和所述另一操作合并。
26.基于确定结果将将替换操作和所述另一操作合并的步骤可包括:通过基于矩阵的行或列的数量调整所述另一操作的核大小和所述另一操作的步长大小来将替换操作和所述另一操作合并。
27.一种非暂时性计算机可读存储介质可存储指令,所述指令在被一个或多个处理器执行时,配置所述一个或多个处理器执行以上的方法。
28.在另一总体方面,一种神经网络操作设备包括:存储器,被配置为存储将被执行神经网络的操作的矩阵;和处理器,被配置为:对矩阵的元素的一部分进行混洗,并且基于混
洗的矩阵执行所述操作的替换操作。
29.处理器还被可配置为:对包括在矩阵中的第一矩阵的行和列中的任一者或两者以及包括在矩阵中的第二矩阵的行和列中的任一者或两者进行混洗。
30.处理器还可被配置为:存储第一矩阵的行或列中的一行或一列;将第一矩阵的行或列中的另一行或另一列存储在与存储所述一行或所述一列的位置相距预定间隔的位置处;和将第二矩阵的行或列中的一行或一列存储在存储所述一行或所述一列的位置与存储所述另一行或所述另一列的位置之间。
31.预定间隔可基于将被执行所述操作的矩阵的数量而被确定。
32.处理器还可被配置为:将第一矩阵的行或列中的一行或一列发送给运算器以用于替换操作;和将第二矩阵的行或列中的一行或一列发送给运算器,以便与所述一行或所述一列邻近地被操作。
33.所述操作可包括逐元素求和操作和逐元素最大操作中的任一者或两者。
34.替换操作可包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何两种或更多种的任何组合。
35.处理器还可被配置为:当在所述操作之后将执行另一操作时,将替换操作和所述另一操作合并。
36.处理器还可被配置为:确定替换操作和另一操作是否是可合并的;和基于确定结果将替换操作和所述另一操作合并。
37.处理器还可被配置为:通过基于矩阵的行或列的数量调整所述另一操作的核大小和所述另一操作的步长大小来将替换操作和所述另一操作合并。
38.在一个总体方面,一种通过神经网络识别图像的方法包括:获得待识别的图像作为输入图像;基于输入图像获得神经网络内的预定层的输入特征图;存储将被执行预定层的操作的输入特征图;对输入特征图的元素的一部分进行混洗;基于混洗的输入特征图执行用于替换预定层的操作的替换操作,以生成预定层的输出特征图;和基于输出特征图获得图像识别结果。
39.基于输入图像获得神经网络内的预定层的输入特征图的步骤包括:神经网络的第i层基于作为第i层的输入特征图的第i-1层的输出特征图,输出第i层的输出特征图,i为大于1的整数,其中,神经网络的第一层接收输入图像,并基于输入图像输出第一层的输出特征图作为第二层的输入特征图,其中,神经网络的最后层基于前一层的输出特征图生成并输出图像识别结果。
40.混洗的步骤包括:对包括在输入特征图中的第一矩阵的行和列中的任一者或两者以及包括在输入特征图中的第二矩阵的行和列中的任一者或两者进行混洗。
41.混洗的步骤还包括:存储第一矩阵的行或列中的一行或一列;将第一矩阵的行或列中的另一行或另一列存储在与存储第一矩阵的行或列中的所述一行或所述一列的位置相距预定间隔的位置处;和将第二矩阵的行或列中的一行或一列存储在存储第一矩阵的行或列中的所述一行或所述一列的位置与存储第一矩阵的行或列中的所述另一行或所述另一列的位置之间。
42.预定间隔基于将被执行预定层的操作的输入特征图的操作数矩阵的数量而被确定。
43.混洗的步骤还包括:将第一矩阵的行或列中的一行或一列发送给运算器以用于替换操作;和将第二矩阵的行或列中的一行或一列发送给运算器,以便与第一矩阵的行或列中的所述一行或所述一列邻近地被操作。
44.预定层的操作包括逐元素求和操作和逐元素最大操作中的任一者或两者。
45.替换操作包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何两种或更多种的任何组合。
46.执行的步骤包括:当在预定层的操作之后将执行另一操作时,将替换操作和所述另一操作合并。
47.合并的步骤包括:确定替换操作和所述另一操作是否是可合并的;和基于确定结果将替换操作和所述另一操作合并。
48.基于确定结果将替换操作和所述另一操作合并的步骤包括:通过基于将被执行混洗的输入特征图的操作数矩阵的数量调整所述另一操作的核大小和所述另一操作的步长大小来将替换操作和所述另一操作合并。
49.在另一方面,一种通过神经网络识别图像的设备包括:存储器,被配置为存储将被执行预定层的操作的输入特征图;和处理器,被配置为:获得待识别的图像作为输入图像,基于输入图像获得神经网络内的预定层的输入特征图,对输入特征图的元素的一部分进行混洗,并且基于混洗的输入特征图执行用于替换预定层的操作的替换操作,以生成预定层的输出特征图,以及基于输出特征图获得图像识别结果。
50.处理器还被配置为:对包括在输入特征图中的第一矩阵的行和列中的任一者或两者以及包括在输入特征图中的第二矩阵的行和列中的任一者或两者进行混洗。
51.处理器还被配置为:存储第一矩阵的行或列中的一行或一列;将第一矩阵的行或列中的另一行或另一列存储在与存储第一矩阵的行或列中的所述一行或所述一列的位置相距预定间隔的位置处;和将第二矩阵的行或列中的一行或一列存储在存储第一矩阵的行或列中的所述一行或所述一列的位置与存储第一矩阵的行或列中的所述另一行或所述另一列的位置之间。
52.预定间隔基于将被执行预定层的操作的输入特征图的操作数矩阵的数量而被确定。
53.处理器还被配置为:将第一矩阵的行或列中的一行或一列发送给运算器以用于替换操作;和将第二矩阵的行或列中的一行或一列发送给运算器,以便与第一矩阵的行或列中的所述一行或所述一列邻近地被操作。
54.预定层的操作包括逐元素求和操作和逐元素最大操作中的任一者或两者。
55.替换操作包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何两种或更多种的任何组合。
56.处理器还被配置为:当在预定层的操作之后将执行另一操作时,将替换操作和所述另一操作合并。
57.处理器还被配置为:确定替换操作和所述另一操作是否是可合并的;和基于确定结果将替换操作和所述另一操作合并。
58.处理器还被配置为:通过基于将被执行混洗的输入特征图的操作数矩阵的数量调整所述另一操作的核大小和所述另一操作的步长大小来将替换操作和所述另一操作合并。
59.从下面的具体实施方式、附图以及权利要求,其它特征和方面将是清楚的。
附图说明
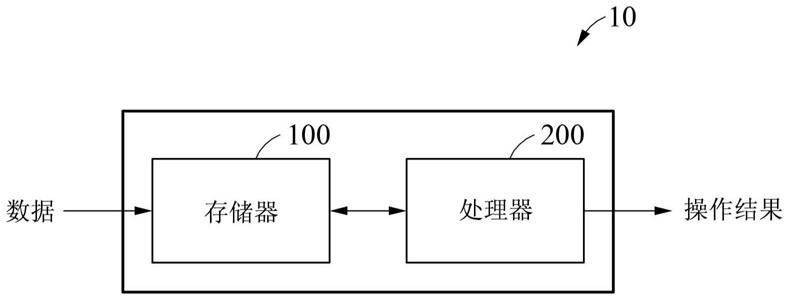
60.图1示出神经网络操作设备的示例。
61.图2示出图1中示出的存储器和处理器的示例。
62.图3a和图3b示出混洗操作的示例。
63.图3c示出混洗操作的示例。
64.图4示出混洗操作的示例。
65.图5示出混洗操作的示例。
66.图6示出使用单独的混洗器的混洗操作的示例。
67.图7a示出逐元素最大(elementwise-max)操作的示例。
68.图7b示出最大池化操作的示例。
69.图7c示出用最大池化操作替换逐元素最大操作的示例。
70.图8a示出逐元素求和操作的示例。
71.图8b示出平均池化操作的示例。
72.图8c示出用平均池化操作或求和池化操作替换逐元素求和操作的示例。
73.图9示出合并神经网络操作的示例。
74.图10示出合并神经网络操作的示例。
75.图11示出合并神经网络操作的示例。
76.图12示出用于合并神经网络操作的核重新布置的示例。
77.图13示出替换神经网络操作和合并神经网络操作的示例。
78.图14示出图1的神经网络操作设备的操作的流程的示例。
79.贯穿附图和具体实施方式,除非另外描述或提供,否则相同的附图参考标号将被理解为表示相同的元件、特征和结构。附图可不按比例,并且为了清楚、说明和方便,附图中的元件的相对尺寸、比例和描绘可被夸大。
具体实施方式
80.提供下面的具体实施方式以帮助读者获得对在此描述的方法、设备和/或系统的全面理解。然而,在理解本技术的公开之后,在此描述的方法、设备和/或系统的各种改变、修改和等同物将是清楚的。例如,在此描述的操作的顺序仅是示例,并且不限于在此阐述的那些顺序,而是除了必须以特定的次序发生的操作之外,可如在理解本技术的公开之后将是清楚的那样被改变。此外,为了更加清楚和简明,可省略在理解本技术的公开之后已知的特征的描述。
81.在此描述的特征可以以不同的形式来实现,而不应被解释为限于在此描述的示例。相反,在此描述的示例已被提供,以仅示出在理解本技术的公开之后将是清楚的实现在此描述的方法、设备和/或系统的许多可行方式中的一些可行方式。
82.贯穿说明书,当诸如层、区域或基底的元件被描述为“在”另一元件“上”、“连接到”或“结合到”另一元件时,所述元件可直接“在”所述另一元件“上”、“连接到”或“结合到”所述另一元件,或者可存在介于它们之间的一个或多个其它元件。相反,当元件被描述为“直
接在”另一元件“上”、“直接连接到”或“直接结合到”另一元件时,可不存在介于它们之间的其它元件。
83.如在此使用的,术语“和/或”包括相关联的所列项中的任何一个和任何两个或更多个的任何组合。
84.尽管在此可使用诸如“第一”、“第二”和“第三”的术语来描述各种构件、组件、区域、层或部分,但是这些构件、组件、区域、层或部分不被这些术语限制。相反,这些术语仅用于将一个构件、组件、区域、层或部分与另一构件、组件、区域、层或部分进行区分。因此,在不脱离示例的教导的情况下,在此描述的示例中所称的第一构件、第一组件、第一区域、第一层或第一部分也可被称为第二构件、第二组件、第二区域、第二层或第二部分。
85.为了便于描述,在此可使用空间相对术语(诸如,“在
……
上面”、“上面的”、“在
……
下面”、“下面的”)来描述附图中示出的一个元件与另一个元件的关系。这样的空间相对术语意在包含除了在附图中描绘的方位之外装置在使用或操作中的不同方位。例如,如果附图中的装置被翻转,则被描述相对于“在”另一元件“上面”或“上面的”元件随后将相对于“在”另一元件“下面”或“下面的”。因此,根据装置的空间方位,术语“在
……
上面”包括方位“在
……
上面”和“在
……
下面”两者。装置也可以以其它方式被定位(例如,旋转90度或在其它方位),并且在此使用的空间相对术语将被相应地解释。
86.在此使用的术语仅用于描述各种示例,并将不用于限制公开。除非上下文另外清楚地指示,否则单数形式也意在包括复数形式。术语“包含”、“包括”和“具有”说明存在叙述的特征、数量、操作、构件、元件和/或它们的组合,但不排除存在或添加一个或多个其它特征、数量、操作、构件、元件和/或它们的组合。
87.如在理解本技术的公开之后将清楚的,在此描述的示例的特征可以以各种方式组合。此外,尽管在此描述的示例具有各种配置,但是如在理解本技术的公开之后将清楚的,其它配置是可行的。
88.图1示出神经网络操作设备的示例。
89.参照图1,神经网络操作设备10可执行神经网络操作。响应于神经网络的操作被处理,神经网络操作设备10可执行各种任务。例如,神经网络操作设备10可执行图像识别(诸如,对象分类、对象检测、对象标识、对象识别或用户认证)。神经网络操作设备10可用另外的神经网络操作替换预定的神经网络操作或将预定的神经网络操作变换为另外的神经网络操作。
90.神经网络操作设备10可用可执行的操作来替换可能由单个运算器不期望地执行的神经网络操作。神经网络操作设备10可将两个或更多个神经网络操作合并成一个神经网络操作。
91.由此,神经网络操作设备10可在高效地使用硬件资源的同时提高神经网络的操作执行速度。
92.神经网络可包括深度神经网络(dnn)。神经网络可包括卷积神经网络(cnn)、循环神经网络(rnn)、感知器、前馈(ff)、径向基网络(rbf)、深度前馈(dff)、长短期记忆(lstm)、门控循环单元(gru)、自编码器(ae)、变分自编码器(vae)、降噪自编码器(dae)、稀疏自编码器(sae)、马尔可夫链(mc)、霍普菲尔德网络(hn)、玻尔兹曼机(bm)、受限玻尔兹曼机(rbm)、深度信念网络(dbn)、深度卷积网络(dcn)、解卷积网络(dn)、深度卷积逆图形网络(dcign)、
生成对抗网络(gan)、液体状态机(lsm)、极限学习机(elm)、回声状态网络(esn)、深度残差网络(drn)、可微神经计算机(dnc)、神经图灵机(ntm)、胶囊网络(cn)、kohonen网络(kn)以及注意力网络(an)。
93.神经网络操作可包括逐元素操作。逐元素操作可包括逐元素最大(elementwise-max)操作和逐元素求和(elementwise-sum)操作。在下文中,操作可表示神经网络操作。
94.神经网络操作设备10包括存储器100和处理器200。存储器100可存储可由处理器执行的指令(或程序)。例如,指令可包括用于执行处理器的操作和/或处理器的每个元件的操作的指令。
95.存储器100可被实现为易失性存储器装置或非易失性存储器装置。
96.易失性存储器装置可被实现为动态随机存取存储器(dram)、静态随机存取存储器(sram)、晶闸管ram(t-ram)、零电容器ram(z-ram)或双晶体管ram(ttram)。
97.非易失性存储器装置可被实现为电可擦除可编程只读存储器(eeprom)、闪存、磁ram(mram)、自旋转移力矩(stt)-mram、导电桥接ram(cbram)、铁电ram(feram)、相变ram(pram)、电阻式ram(rram)、纳米管rram、聚合物ram(poram)、纳米浮栅存储器(nfgm)、全息存储器、分子电子存储器装置或绝缘电阻变化存储器。
98.存储器100可存储将被执行神经网络的操作的矩阵。存储器100可存储由处理器200通过处理操作而生成的操作结果。将被执行神经网络的操作的矩阵可被称为“输入特征图”,通过每个层的处理操作而生成的操作结果可被称为“输出特征图”。层的输出特征图可以是后续层的输入特征图,或者可用于生成后续层的输入特征图。例如,当神经网络操作设备10执行图像识别时,用于识别图像的神经网络可被实现在神经网络操作设备10内。神经网络的输入层的输入特征图可对应于输入数据。例如,输入数据可以是输入图像或从输入图像的初始处理产生的数据。在一个示例中,神经网络的第一层接收输入图像,并基于输入图像输出第一层的输出特征图作为第二层的输入特征图。神经网络的第i层基于作为第i层的输入特征图的第i-1层的输出特征图,输出第i层的输出特征图,i为大于1的整数。神经网络的最后层基于前一层的输出特征图生成并输出与输入图像对应的识别结果。
99.处理器200可处理存储在存储器100中的数据。处理器200可执行存储在存储器100中的计算机可读代码(例如,软件)以及由处理器200触发的指令。
[0100]“处理器200”可以是由包括具有执行期望的操作的物理结构的电路的硬件实现的数据处理装置。例如,期望的操作可包含包括在程序中的指令或代码。
[0101]
例如,硬件实现的数据处理装置可包括微处理器、中央处理器(cpu)、处理器核、多核处理器、多处理器、专用集成电路(asic)以及现场可编程门阵列(fpga)。
[0102]
处理器200可包括运算器。运算器可在处理器200外部或内部实现。运算器可包括乘积累加(mac)运算器。
[0103]
处理器200可对将被执行神经网络的操作的矩阵的元素的至少一部分进行混洗(shuffle)。例如,处理器200可对神经网络的预定层的输入特征图的元素的至少一部分进行混洗。处理器200可对包括在矩阵(或输入特征图)中的第一矩阵的行和列中的任一者或两者以及包括在矩阵(或输入特征图)中的第二矩阵的行和列中的任一者或两者进行混洗。
[0104]
处理器200可存储第一矩阵的行或列中的一行或一列。例如,处理器200可将第一矩阵的行或列中的一行或一列存储在存储器100中。
[0105]
处理器200可将矩阵的行或列的一部分存储在存储器100中的不同位置处。
[0106]
处理器200可将第一矩阵的行或列中的另一行或另一列存储在与存储第一矩阵的行或列中的一行或一列的位置相距预定间隔的位置处。可基于将被执行操作的矩阵的数量来确定预定间隔。例如,可基于将被执行预定层的操作的预定层的输入特征图的操作数矩阵的数量来确定预定间隔。
[0107]
处理器200可将第二矩阵的行或列中的一行或一列存储在存储第一矩阵的行或列中的一行或一列的位置与存储第一矩阵的行或列中的另一行或另一列的位置之间。
[0108]
处理器200可对矩阵的行或列进行混洗并将矩阵的行或列存储在存储器100中,或者可直接通过运算器对行或列进行混洗并发送混洗的矩阵。处理器200可将第一矩阵的行或列中的一行或一列发送给运算器,以进行替换操作。处理器200可将第二矩阵的行或列中的一行或一列发送给运算器,以便与第一矩阵的行或列中的一行或一列邻近地被操作。
[0109]
神经网络操作可包括逐元素求和操作和逐元素最大操作中的至少一种。
[0110]
神经网络操作的替换操作可包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何组合。
[0111]
当在操作之后将执行另一操作时,处理器200可将替换操作与另一操作合并(或融合)。
[0112]
处理器200可确定替换操作和另一操作是否是可合并的,并且基于确定结果将替换操作与另一操作合并。相同的操作可以是可合并的操作。平均池化操作和求和池化操作可以是可合并的。此外,逐元素求和操作和卷积操作可以是可合并的。
[0113]
处理器200可通过基于矩阵的行或列的数量调整另一操作的核大小和另一操作的步长大小来将替换操作与另一操作合并。处理器200可通过基于将被执行混洗的输入特征图的操作数矩阵的数量来调整另一操作的核大小和另一操作的步长大小,以将替换操作与另一操作合并。将参照图9至图12详细描述合并操作。
[0114]
处理器200可基于混洗的矩阵来执行神经网络的操作的替换操作。例如,处理器200可基于混洗的输入特征图来执行用于替换神经网络的预定层的操作的替换操作。
[0115]
处理器200可用不需要权重的池化操作来替换逐元素操作,从而减少存储器100的使用。通过利用常规mac运算器执行的逐元素求和操作需要权重以将每个元素乘以1,而池化操作不需要权重,因此可减少存储器100的使用。另外,处理器200可通过操作替换来提高硬件性能,并且与向量操作相比通过更高效地利用数据并行性来提高操作速度。
[0116]
此外,处理器200可使硬件能够通过对操作进行合并来一次处理两个或更多个操作,从而减少操作循环的数量。另外,处理器200可将难以在通道基础上并行化的逐元素操作与卷积操作合并,从而增大运算器250的利用率。
[0117]
图2示出图1中示出的存储器和处理器的示例。
[0118]
参照图2,处理器200可包括混洗器210、池化器230和运算器250。在该示例中,混洗器210可在处理器200外部实现。可选地,混洗操作可在不使用单独的混洗器210的情况下仅用处理器200执行。
[0119]
处理器200可用运算器可处理或期望处理的操作来替换运算器不可处理或不期望处理的操作。例如,如果运算器是mac运算器,则处理器200可用池化操作或卷积操作替换逐元素操作。池化操作可包括最大池化操作、平均池化操作和求和池化操作。
[0120]
混洗器210可在将被执行神经网络操作的矩阵的一部分被存储在存储器100中时执行混洗。混洗器210可存储第一矩阵的行或列中的一行或一列。
[0121]
混洗器210可将第一矩阵的行或列中的另一行或另一列存储在与存储第一矩阵的行或列中的一行或一列的位置相距预定间隔的位置处。可基于将被执行操作的矩阵的数量来确定预定间隔。
[0122]
混洗器210可将第二矩阵的行或列中的一行或一列存储在存储第一矩阵的行或列中的一行或一列的位置与存储第一矩阵的行或列中的另一行或另一列的位置之间。
[0123]
混洗器210可将第一矩阵的行或列中的一行或一列发送到运算器以用于替换操作。混洗器210可将第二矩阵的行或列中的一行或一列发送到运算器,以便与第一矩阵的行或列中的一行或一列邻近地被操作。
[0124]
池化器230可执行池化操作。池化操作可以是从输入数据中仅提取与核大小对应的区域中的一些元素的操作。池化器230可执行最大池化操作、平均池化操作和求和池化操作。
[0125]
运算器250可执行神经网络操作。例如,运算器250可执行mac操作。
[0126]
在下文中,将参照图3a至图6详细描述混洗操作。
[0127]
图3a和图3b示出混洗操作的示例。
[0128]
参照图3a和图3b,存储器100可包括第一存储器110和第二存储器130。第一存储器110可存储矩阵a和矩阵b。
[0129]
处理器200可对矩阵的一些元素进行混洗。处理器200可对矩阵的行或列执行混洗。在下文中,将基于矩阵的列来描述处理器200的混洗操作。然而,处理器200还可逐行执行混洗。
[0130]
矩阵a可包括列a0至an,矩阵b可包括列b0至bn,其中,n是自然数。处理器200可将存储在第一存储器110中的矩阵a的列311复制到第二存储器130。在下文中,将描述第一矩阵是矩阵a并且第二矩阵是矩阵b的示例。
[0131]
处理器200可将列311存储在第二存储器130的第一位置处。处理器200可将列313存储在与存储列311的位置相距预定间隔的位置处。
[0132]
可基于将被执行操作的矩阵的数量来确定预定间隔。由于在图3a的示例中,将被执行操作的矩阵的数量是“2”,因此列312可被存储在与列311相距与两个存储器区域对应的间隔的位置处。同样地,处理器200可将列313存储在与存储在第二存储器130中的列312相距相应间隔的位置处。
[0133]
处理器200可将第二矩阵的行或列存储在存储第一矩阵的行或列的位置与存储第一矩阵的另一行或另一列的位置之间。
[0134]
在图3b的示例中,处理器200可将作为第二矩阵的矩阵b的列331存储在第二存储器130中存储的列311与列312之间。类似地,处理器200可将列332存储在列312与列313之间。
[0135]
处理器200可通过以上描述的复制操作和存储操作将混洗的矩阵存储在第二存储器130中。在该示例中,第一存储器110和第二存储器130可被实现为dram和/或sram。
[0136]
图3c示出混洗操作的示例。
[0137]
参照图3c,处理器200可将混洗的矩阵存储在存储将被执行神经网络操作的矩阵
的同一存储器中。在图3c的示例中,矩阵a和矩阵b可被存储在第一存储器110中。
[0138]
处理器200可将作为第一矩阵的矩阵a的列311存储在第一存储器110中的预定位置处。处理器200可将列312存储在与第一存储器110中存储列311的位置相距预定间隔的位置处。以相同的方式,处理器200可复制列313并将列313存储在与存储列312的位置相距相应间隔的位置处。
[0139]
处理器200可将作为第二矩阵的矩阵b的列331存储在第一矩阵的列311与列312之间。类似地,处理器200可通过以相同的方式存储第二矩阵的列332和列333来执行混洗。
[0140]
图4示出混洗操作的示例。
[0141]
参照图4,处理器200可通过将运算器250的输出以预定间隔存储在存储器100中来执行混洗。
[0142]
例如,当运算器250输出矩阵a的列411时,处理器200可将列411存储在存储器100的第一区域中。此后,处理器200可将从运算器250输出的列412存储在与存储器100中存储的列411相距预定间隔的位置处。
[0143]
如上所述,可基于将被执行操作的矩阵的数量来确定预定间隔。在图4的示例中,预定间隔可以是2。
[0144]
当矩阵a的所有元素被存储时,处理器200可通过矩阵b将运算器250的另一输出存储在存储器100中。当运算器250输出矩阵b的列431时,处理器200可将列431存储在列411与列412之间。类似地,处理器200可通过以相同的方式存储矩阵b的列432和列433来执行混洗。例如,处理器200可将列432存储在列412与列413之间。
[0145]
通过在将运算器250的输出写入存储器100的处理中执行混洗,可在不使用用于混洗的单独的存储器区域的情况下执行混洗。
[0146]
图5示出混洗操作的示例。
[0147]
参照图5,处理器200可通过对运算器250的输入进行混洗来执行矩阵混洗。
[0148]
存储器100可存储矩阵a和矩阵b。处理器200可通过将矩阵a的元素的一部分以及矩阵b的元素的一部分交替地输入到运算器250中来执行混洗。
[0149]
处理器200可首先将矩阵a的列511输入到运算器250中,其次将矩阵b的列531输入到运算器250中。此后,处理器200可将矩阵a的列512输入到运算器250中,并且将矩阵b的列532输入到运算器250中。
[0150]
换句话说,处理器200可通过将第一矩阵的元素的一部分以及第二矩阵的元素的一部分交替地输入到运算器250中来执行混洗。
[0151]
图6示出使用单独的混洗器的混洗操作的示例。
[0152]
参照图6,处理器200可使用被配置为用于执行混洗的单独的硬件的混洗器210来执行混洗。在该示例中,混洗器210的操作可与参照图3a至图5描述的混洗操作相同。
[0153]
混洗器210的输出可连接到运算器250或存储器100。通过单独地配置混洗器210,可提高混洗效率。
[0154]
在下文中,将参照图7a至图7c详细描述用最大池化操作替换逐元素最大操作的处理。
[0155]
图7a示出逐元素最大操作的示例,图7b示出最大池化操作的示例,图7c示出用最大池化操作替换逐元素最大操作的示例。
[0156]
参照图7a至图7c,处理器200可通过对将被执行操作的矩阵进行混洗并用另一神经网络操作替换一个神经网络操作来执行操作。
[0157]
逐元素最大操作可以是用于通过比较操作数矩阵(operand matrice)的元素并从中提取最大元素来生成新矩阵的操作。
[0158]
例如,在图7a的示例中,当对矩阵a和矩阵b执行逐元素最大操作时,输出矩阵的第一元素711可以是通过对矩阵a的第一元素a(0,0)和矩阵b的第一元素b(0,0)执行最大操作而获得的值。
[0159]
类似地,输出矩阵的第二元素712可以是通过对矩阵a的第二元素a(0,1)和矩阵b的第二元素b(0,1)执行最大操作而获得的值。
[0160]
通过对剩余元素执行相同的操作,可执行针对两个矩阵a和矩阵b的逐元素最大操作。
[0161]
最大池化操作可以是用于针对输入矩阵提取与核重叠的区域中的最大值的操作。在图7b的示例中,核可以是阴影部分。
[0162]
在图7b中,核大小是(1,2),核大小可基于将被执行混洗的操作数矩阵的数量而被调整。步长可以是核在将被执行操作的矩阵上移动的距离。
[0163]
在图7b的示例中,当执行最大池化操作时,可通过对矩阵a的第一元素731和第二元素732执行最大操作来提取输出矩阵的第一元素。之后,可通过移动与步长对应的间隔来重复相同的操作。在图7b的示例中,步长大小是(1,2)。因此,可通过对元素733和元素734执行最大操作来提取输出矩阵的第二元素的值。
[0164]
处理器200可通过对矩阵的元素的一部分进行混洗来用最大池化操作替换逐元素最大操作。处理器200可对矩阵a的元素的一部分以及矩阵b的元素的一部分进行混洗。
[0165]
图7c的示例描述执行逐列混洗的情况。然而,逐行混洗也是可行的。
[0166]
处理器200可通过以上描述的混洗处理交替地布置矩阵a的列751至列753以及矩阵b的列771至列773。在混洗的矩阵中,矩阵b的列771可布置在矩阵a的列751的右侧,矩阵a的列752可布置在矩阵b的列771的右侧。类似地,矩阵b的列772可布置在矩阵a的列752的右侧。剩余列也可如上所述的被混洗。
[0167]
处理器200可基于混洗的矩阵执行神经网络操作的替换操作。图7c示出处理器200用混洗的矩阵的最大池化操作来替换矩阵a和矩阵b的逐元素最大操作的示例。
[0168]
处理器200可通过对其中矩阵a和矩阵b被混洗的矩阵执行最大池化操作来输出与矩阵a和矩阵b的逐元素最大操作相同的结果。
[0169]
在该示例中,可基于将被执行神经网络操作的操作数矩阵的数量来确定最大池化操作的核大小和步长大小。例如,如果存在两个操作数矩阵,则最大池化操作的核大小可被确定为(1,2),最大池化操作的步长大小可被确定为(1,2)。如果存在三个操作数矩阵,则最大池化操作的核大小可被确定为(1,3),最大池化操作的步长大小可被确定为(1,3)。
[0170]
在下文中,将参照图8a至图8c详细描述用平均池化操作或求和池化操作来替换逐元素求和操作的处理。
[0171]
图8a示出逐元素求和操作的示例,图8b示出平均池化操作的示例,图8c示出用平均池化操作或求和池化操作来替换逐元素求和操作的示例。
[0172]
参照图8a至图8c,逐元素求和操作可以是用于将操作数矩阵的元素相加的操作。
[0173]
例如,当对矩阵a和矩阵b执行逐元素求和操作时,输出矩阵的第一元素811可以是矩阵a的第一元素a(0,0)和矩阵b的第一元素b(0,0)之和。输出矩阵的第二元素可以是矩阵a的第二元素a(0,1)和矩阵b的第二元素b(0,1)之和。
[0174]
输出矩阵的剩余元素也可以以与以上描述相同的方式进行计算。
[0175]
平均池化操作可以是用于提取与核重叠的区域中的矩阵的元素的平均的操作。例如,如图8b中所示,如果核大小是(1,2),则平均池化操作的输出矩阵的第一元素可具有矩阵a的第一元素a(0,0)和第二元素a(0,1)的平均值。
[0176]
此后,平均池化操作的输出矩阵的第二元素可以是在核移位步长的大小之后与核重叠的区域的平均值。在图8b的示例中,由于步长大小是(1,2),因此平均池化操作的第二元素可具有矩阵a的元素a(0,2)和元素a(0,3)的平均值。
[0177]
求和池化操作可以是用于提取与核重叠的区域中的矩阵的元素之和的操作。求和池化操作的核和步长的描述可与平均池化操作的描述相同。
[0178]
处理器200可通过对矩阵的元素的一部分进行混洗来用平均池化操作替换逐元素求和操作。处理器200可对矩阵a的元素的一部分以及矩阵b的元素的一部分进行混洗。图8c的示例描述执行逐列混洗的情况。然而,逐行混洗也是可行的。
[0179]
处理器200可通过以上描述的混洗处理交替地布置矩阵a的列851至列853以及矩阵b的列871至列873。在混洗的矩阵中,矩阵b的列871可布置在矩阵a的列851的右侧,矩阵a的列852可布置在矩阵b的列871的右侧。类似地,矩阵b的列872可布置在矩阵a的列852的右侧。剩余列也可如上所述地被混洗。
[0180]
处理器200可基于混洗的矩阵执行神经网络操作的替换操作。图8c示出处理器200用混洗的矩阵的平均池化操作或求和池化操作来替换矩阵a和矩阵b的逐元素求和操作的示例。
[0181]
处理器200可通过对其中矩阵a和矩阵b被混洗的矩阵执行平均池化操作然后将操作结果乘以2,来输出与矩阵a和矩阵b的逐元素求和操作相同的结果。
[0182]
处理器200可通过对其中矩阵a和矩阵b被混洗的矩阵执行求和池化操作来输出与矩阵a和矩阵b的逐元素求和操作相同的结果。
[0183]
在该示例中,可基于将被执行神经网络操作的操作数矩阵的数量来确定最大池化操作的核大小和步长大小。例如,如果存在两个操作数矩阵,则最大池化操作的核大小可被确定为(1,2),最大池化操作的步长大小可被确定为(1,2)。如果存在三个操作数矩阵,则最大池化操作的核大小可被确定为(1,3),最大池化操作的步长大小可被确定为(1,3)。
[0184]
在下文中,将参照图9和图12详细描述合并操作的处理。
[0185]
图9示出合并神经网络操作的示例。
[0186]
参照图9,如果在操作之后将执行另一操作,则处理器200可将替换操作与另一操作合并(或融合)。
[0187]
图9示出通过对包括列911至列913的矩阵a执行逐元素最大操作并对作为逐元素最大操作的结果的矩阵b 930执行最大池化操作来生成最终矩阵c 950的示例。在该示例中,处理器200可以以如上所述的方式对矩阵a执行混洗,并且执行最大池化操作,从而将逐元素操作和最大池化操作合并成一个最大池化操作。
[0188]
处理器200可确定在作为替换操作的最大池化操作之后将执行的操作是否是可合
并的,然后响应于确定随后的操作是相同的操作,将两个操作合并成一个操作。
[0189]
处理器200可将逐元素操作和最大池化操作合并成一个最大池化操作。在这种情况下,处理器200可基于将被合并的替换操作或另一操作的核大小和步长大小来调整合并的操作的核大小和步长大小。
[0190]
在图9的示例中,合并之前的另一操作(例如,最大池化操作)的核大小可以是(k_h,k_w),合并之前的另一操作的步长大小可以是(s_h,s_w)。处理器200可将合并的最大池化操作的核大小调整为(k_h,k_w
×
n),并且将合并的最大池化操作的步长大小调整为(s_h,s_w
×
n)。
[0191]
这里,k_h表示核高度,k_w表示核宽度。s_h表示步长高度,s_w表示步长宽度。n表示将被执行混洗操作的操作数矩阵的数量。在图9的示例中,n可以是3。
[0192]
图9示出核大小的宽度以及步长大小的宽度乘以n的示例,因为在逐列对矩阵进行混洗之后操作被合并。然而,如果矩阵被逐行混洗,则处理器200可将高度乘以n。
[0193]
为了执行合并的操作,处理器200可通过对包括在矩阵a中的元素911至元素913进行混洗并且对混洗的矩阵a 970执行调整了核和步长的最大池化操作来生成作为最终结果的矩阵c 950。
[0194]
图10示出合并神经网络操作的示例。
[0195]
参照图10,当将对预定矩阵相继执行一个操作和另一操作时,处理器200可将所述一个操作的替换操作与另一操作合并(或融合)。
[0196]
图10示出对包括列1011至列1013的矩阵a执行逐元素求和操作,然后对作为逐元素求和操作的结果的矩阵b 1030执行平均池化操作的示例。
[0197]
在该示例中,处理器200可以以如上所述的方式对矩阵a执行混洗,从而将逐元素求和操作和平均池化操作合并成一个平均池化操作。可选地,处理器200可以以如上所述的方式对矩阵a执行混洗,从而将逐元素求和操作和平均池化操作合并成一个求和池化操作。
[0198]
处理器200可确定在平均池化操作或求和池化操作之后将被执行的操作(替换操作)是否是可合并的,然后响应于确定随后的操作是相同的操作,将两个操作合并成一个操作。
[0199]
如上所述,相同的操作可以是可合并的,并且平均池化操作和求和池化操作可以是可合并的。
[0200]
处理器200可将作为将对矩阵a执行的逐元素操作的替换操作的平均池化操作(或求和池化操作)以及随后的平均池化操作(或求和池化操作)合并成一个平均池化操作(或求和池化操作)。
[0201]
在这种情况下,处理器200可基于另一操作的核大小和步长大小来调整合并的操作的核大小和步长大小。
[0202]
在图10的示例中,合并之前的另一操作的核大小可以是(k_h,k_w),合并之前的另一操作的步长大小可以是(s_h,s_w)。处理器200可将合并的平均池化(或求和池化)操作的核大小调整为(k_h,k_w
×
n),并且将合并的平均池化(或求和池化)操作的步长大小调整为(s_h,s_w
×
n)。
[0203]
这里,k_h表示核高度,k_w表示核宽度。s_h表示步长高度,s_w表示步长宽度。n表示将被执行混洗操作的操作数矩阵的数量(例如,将被执行混洗操作的矩阵a的列1011至列
1013的数量)。在图10的示例中,n可以是3。
[0204]
图10示出核大小的宽度以及步长大小的宽度乘以n的示例,因为在逐列对矩阵进行混洗之后操作被合并。然而,如果矩阵被逐行混洗,则处理器200可将高度乘以n。
[0205]
在该示例中,如果合并的操作是平均池化操作,则执行操作的结果可以是通过将预期结果除以n而获得的值。因此,处理器200可将结果乘以n以得到原始预期结果。换句话说,如果合并的操作是平均池化操作,则处理器200可通过将合并的平均池化操作的结果乘以n来计算作为最终结果的矩阵c 1050。
[0206]
在该示例中,如果合并的操作是求和池化操作,则执行操作的结果可以是通过将预期结果乘以(k_h
×
k_w)而获得的值。因此,处理器200可将结果除以(k_h
×
k_w)以得到原始预期结果。换句话说,如果合并的操作是求和池化操作,则处理器200可通过将合并的求和池化操作的结果除以(k_h
×
k_w)来输出合并的操作的结果。
[0207]
在下文中,将参照图11和图12详细描述将逐元素求和操作与卷积操作合并的处理。
[0208]
图11示出合并神经网络操作的示例,图12示出用于合并神经网络操作的核重新布置的示例。
[0209]
参照图11和图12,处理器200可将逐元素求和操作和卷积操作合并。图11示出通过对包括列1111至列1113的矩阵a进行逐元素求和操作来计算矩阵b 1130然后执行矩阵b 1130和预定滤波器(或核)的卷积操作来生成矩阵c 1150的示例。
[0210]
处理器200可根据分配率(distributive property)将逐元素求和操作和逐元素求和操作随后的卷积操作合并成一个卷积操作。由于通过分配率满足累积((an bn)
×
滤波器)==累积(an
×
滤波器 bn
×
滤波器),因此处理器200可将逐元素求和操作和卷积操作合并。
[0211]
处理器200可基于将被合并的替换操作或另一操作的核大小和步长大小来调整合并的操作的核大小和步长大小。
[0212]
处理器200可通过将卷积操作的滤波器大小增大n倍并将每个滤波器的元素重复n次来将逐元素求和操作和卷积操作合并。
[0213]
图12示出n是2的示例。在该示例中,处理器200可通过在合并之前复制卷积操作的核的元素1211来生成元素1231,并且通过复制元素1212来生成元素1232。类似地,处理器200可通过复制核的剩余元素来将核大小增大n倍。此外,处理器200可将步长大小增大n倍。
[0214]
在图11的示例中,合并之前的另一操作的核大小可以是(k_h,k_w),合并之前的另一操作的步长大小可以是(s_h,s_w)。处理器200可将合并的卷积操作的核大小调整为(k_h,k_w
×
n),并且将合并的卷积操作的步长大小调整为(s_h,s_w
×
n)。
[0215]
这里,k_h表示核高度,k_w表示核宽度。s_h表示步长高度,s_w表示步长宽度。n表示将被执行混洗操作的操作数矩阵的数量(例如,将被执行混洗操作的矩阵a的列1111至列1113的数量)。
[0216]
在该示例中,当逐高度(或基于矩阵的行)执行混洗时,处理器200可将核高度和步长高度乘以n。
[0217]
图13示出替换神经网络操作和合并神经网络操作的示例。
[0218]
参照图13,在操作1310中,处理器200可确定将被执行的操作是否是逐元素最大操
作。如果将被执行的操作是逐元素最大操作,则在操作1311中,处理器200可通过将n个输入逐宽度或逐高度混洗1次来执行重新布置。在该示例中,混洗操作可与参照图3a至图6描述的混洗操作相同。
[0219]
在操作1312中,处理器200可确定在将被执行的操作随后的操作是否是最大池化操作。如果随后的操作是最大池化操作,则在操作1313中,处理器200可通过将随后的最大池化操作的核、步长和填充逐宽度/逐高度乘以n来将操作合并成一个操作。
[0220]
如果随后的操作不是最大池化操作,则在操作1314中,处理器200可用最大池化操作替换逐元素最大操作。在该示例中,如果基于矩阵的列执行混洗,则处理器200可逐宽度将核大小调整为(1,n),逐宽度将步长大小调整为(1,n),并且将填充设置为(0,0)。如果基于矩阵的行执行混洗,则处理器200可调整核高度和步长高度。
[0221]
如果首先将被执行的操作不是逐元素最大操作,则在操作1315中,处理器200可确定将被执行的操作是否是逐元素求和操作。如果将被执行的操作不是逐元素求和操作,则在操作1316中,处理器200可搜索使用另一硬件的另一操作方法。如果将被执行的操作是逐元素求和操作,则在操作1317中,处理器200可通过将n个输入逐宽度或逐高度混洗1次来执行重新布置。
[0222]
在操作1318中,处理器200可确定逐元素求和操作随后的操作是否是平均池化操作。如果随后的操作是平均池化操作,则在操作1319中,处理器200可通过将平均池化操作的核、步长和填充逐行或逐列乘以n来将操作合并成一个操作。在该示例中,处理器200可不将除数设置为k_h
×
k_w
×
n,而是设置为k_h
×
k_w。
[0223]
如果随后的操作不是平均池化操作,则在操作1320,处理器200可确定随后的操作是否是mac操作。mac操作可包括由求和与乘法形成的操作。例如,mac操作可包括卷积操作或逐深度卷积操作(depthwise convolution operation)。
[0224]
如果随后的操作是mac操作,则在操作1321中,处理器200可将mac操作的核、步长和填充逐行或逐列乘以n,并且通过核重新布置将初始操作和随后的操作合并成一个mac操作。
[0225]
如果随后的操作不是mac操作,则在操作1322中,处理器200可用平均池化操作替换逐元素求和操作。在该示例中,当矩阵被逐列混洗时,处理器200可将核大小设置为(1,n),将步长大小设置为(1,n),并且将填充设置为(0,0)。此外,处理器200可不将除数设置为k_h
×
k_w,而是设置为1。
[0226]
图14示出图1的神经网络操作设备的操作的流程的示例。
[0227]
在操作1410中,存储器100可存储将被执行神经网络的操作的矩阵。神经网络的操作可包括逐元素求和操作和逐元素最大操作中的至少一种。
[0228]
在操作1430中,处理器200可对矩阵的元素的至少一部分进行混洗。处理器200可对包括在矩阵中的第一矩阵的行或列中的至少一者以及包括在矩阵中的第二矩阵的行或列中的至少一者进行混洗。
[0229]
详细地,处理器200可存储第一矩阵的行或列中的一行或一列。处理器200可将第一矩阵的行或列中的另一行或另一列存储在与存储第一矩阵的行或列中的一行或一列的位置相距预定间隔的位置处。
[0230]
然后,处理器200可将第二矩阵的行或列中的一行或一列存储在存储第一矩阵的
行或列中的一行或一列的位置与存储第一矩阵的行或列中的另一行或另一列的位置之间。在该示例中,可基于将被执行操作的矩阵的数量来确定预定间隔。
[0231]
根据另一混洗方法,处理器200可将第一矩阵的行或列中的一行或一列发送给运算器以用于替换操作。处理器200可将第二矩阵的行或列中的一行或一列发送给运算器,以便与第一矩阵的行或列中的一行或一列邻近地被操作。
[0232]
在操作1450中,处理器200可基于混洗的矩阵执行操作的替换操作。替换操作可包括最大池化操作、平均池化操作、求和池化操作和卷积操作中的任何一种或任何组合。
[0233]
如果在操作之后将执行另一操作,则处理器200可将替换操作和另一操作合并。处理器200可确定替换操作和另一操作是否是可合并的。处理器200可基于确定结果将替换操作和另一操作合并。
[0234]
在该示例中,处理器200可通过基于将被执行混洗操作的操作数矩阵的数量调整另一操作的核大小和另一操作的步长大小来将替换操作和另一操作合并。
[0235]
执行在本技术中描述的操作的图1至图14中的神经网络操作设备10、存储器100、处理器200、混洗器210、池化器230、运算器250、第一存储器110以及第二存储器130由硬件组件实现,硬件组件被配置为执行在本技术中描述的由硬件组件执行的操作。可用于执行在本技术中描述的操作的硬件组件的示例在适当的情况下包括:控制器、传感器、生成器、驱动器、存储器、比较器、算术逻辑单元、加法器、减法器、乘法器、除法器、积分器和被配置为执行在本技术中描述的操作的任何其它电子组件。在其它示例中,执行在本技术中描述的操作的硬件组件中的一个或多个通过计算硬件(例如,通过一个或多个处理器或计算机)来实现。处理器或计算机可通过一个或多个处理元件(诸如,逻辑门阵列、控制器和算术逻辑单元、数字信号处理器、微型计算机、可编程逻辑控制器、现场可编程门阵列、可编程逻辑阵列、微处理器或被配置为以限定的方式响应并执行指令以实现期望的结果的任何其它装置或装置的组合)来实现。在一个示例中,处理器或计算机包括或连接到存储由处理器或计算机执行的指令或软件的一个或多个存储器。由处理器或计算机实现的硬件组件可执行用于执行在本技术中描述的操作的指令或软件(诸如,操作系统(os)和在os上运行的一个或多个软件应用)。硬件组件也可响应于指令或软件的执行来访问、操控、处理、创建和存储数据。为了简明起见,单数术语“处理器”或“计算机”可用在本技术中描述的示例的描述中,但是在其它示例中,多个处理器或计算机可被使用,或者处理器或计算机可包括多个处理元件或多种类型的处理元件或二者。例如,单个硬件组件或者两个或更多个硬件组件可通过单个处理器、或者两个或更多个处理器、或者处理器和控制器来实现。一个或多个硬件组件可通过一个或多个处理器、或者处理器和控制器来实现,并且一个或多个其它硬件组件可通过一个或多个其它处理器、或者另外的处理器和另外的控制器来实现。一个或多个处理器、或者处理器和控制器可实现单个硬件组件或者两个或更多个硬件组件。硬件组件可具有不同的处理配置中的任何一个或多个,不同的处理配置的示例包括:单个处理器、独立处理器、并行处理器、单指令单数据(sisd)多处理、单指令多数据(simd)多处理、多指令单数据(misd)多处理以及多指令多数据(mimd)多处理。
[0236]
图1至图14中示出的执行在本技术中描述的操作的方法通过计算硬件(例如,通过一个或多个处理器或计算机)来执行,计算硬件被实现为如上所述地执行指令或软件,以执行在本技术中描述的由所述方法执行的操作。例如,单个操作或者两个或更多个操作可通
过单个处理器、或者两个或更多个处理器、或者处理器和控制器来执行。一个或多个操作可通过一个或多个处理器、或者处理器和控制器来执行,并且一个或多个其它操作可通过一个或多个其它处理器、或者另外的处理器和另外的控制器来执行。一个或多个处理器、或者处理器和控制器可执行单个操作或者两个或更多个操作。
[0237]
用于控制计算硬件(例如,一个或多个处理器或计算机)以实现硬件组件并执行如上所述的方法的指令或软件可被编写为计算机程序、代码段、指令或它们的任何组合,以单独地或共同地指示或配置一个或多个处理器或计算机如机器或专用计算机那样进行操作,以执行由如上所述的硬件组件和方法执行的操作。在一个示例中,指令或软件包括由一个或多个处理器或计算机直接执行的机器代码(诸如,由编译器产生的机器代码)。在另一示例中,指令或软件包括由一个或多个处理器或计算机使用解释器执行的高级代码。可基于附图中示出的框图和流程图以及说明书中的相应描述,使用任何编程语言编写指令或软件,其中,附图中示出的框图和流程图以及说明书中的相应描述公开了用于执行由如上所述的硬件组件和方法执行的操作的算法。
[0238]
用于控制计算硬件(例如,一个或多个处理器或计算机)以实现硬件组件并执行如上所述的方法的指令或软件以及任何相关联的数据、数据文件和数据结构可被记录、存储或固定在一个或多个非暂时性计算机可读存储介质中或一个或多个非暂时性计算机可读存储介质上。非暂时性计算机可读存储介质的示例包括:只读存储器(rom)、随机存取存储器(ram)、闪存、cd-rom、cd-r、cd r、cd-rw、cd rw、dvd-rom、dvd-r、dvd r、dvd-rw、dvd rw、dvd-ram、bd-rom、bd-r、bd-r lth、bd-re、磁带、软盘、磁光数据存储装置、光学数据存储装置、硬盘、固态盘、以及任何其它装置,任何其它装置被配置为以非暂时性方式存储指令或软件以及任何相关联的数据、数据文件和数据结构并将指令或软件以及任何相关联的数据、数据文件和数据结构提供给一个或多个处理器或计算机,使得一个或多个处理器和计算机可执行指令。在一个示例中,指令或软件以及任何相关联的数据、数据文件和数据结构分布在联网的计算机系统上,使得指令和软件以及任何相关联的数据、数据文件和数据结构通过一个或多个处理器或计算机以分布式的方式被存储、访问和执行。
[0239]
虽然本公开包括特定的示例,但是在理解本技术的公开之后将清楚,在不脱离权利要求及它们的等同物的精神和范围的情况下,可在这些示例中进行形式和细节上的各种改变。在此描述的示例将被认为仅是描述性的,而不是出于限制的目的。每个示例中的特征或方面的描述应被认为可适用于其它示例中的类似特征或方面。如果描述的技术以不同的顺序被执行,和/或如果描述的系统、架构、装置或电路中的组件以不同的方式被组合,和/或由其它组件或它们的等同物替换或补充,则可实现合适的结果。因此,公开的范围不是由具体实施方式限定,而是由权利要求及它们的等同物限定,并且在权利要求及它们的等同物的范围内的所有变化应被解释为包括在公开中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。