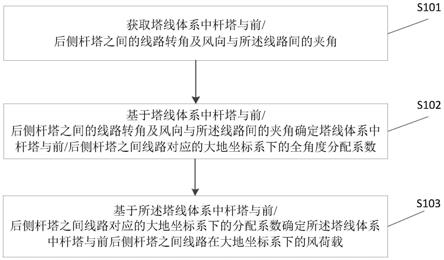
1.本发明属于语义信息领域,具体涉及一种基于语义的研发设计资源全景空间构建方法。
背景技术:
2.由于设计资源空间随着资源的种类、数量、状态变化而时时改变,如何建立一个统一的全景空间对研发设计资源进行统一的组织显得尤为重要。资源的可共享度直接影响到资源的共享和使用效率,是解决研发设计资源共享的核心关键问题之一。随着海量研发设计资源的生成,亟需建立基于语义的设计资源的高维索引,通过语义关联挖掘算法,对海量设计资源实体进行跨时间、跨空间综合语义分析,实现设计资源空间与差异化需求的快速关联,在研发设计资源全景空间模型的基础上能够自动生成不同维度(如专业、类别、性质、来源等维度)的资源视图,实现特定类别资源的快速定位和查找。
技术实现要素:
3.本专利的目的是将海量的研发设计资源数据,通过文本处理算法,将文本类研发设计资源进行语义向量化表达,构建出研发设计资源的语义共享过程,能够得到研发设计资源在共享过程中的语义变化趋势,在基于完整设计流程周期基础上,直观地表达出各流程环节中研发设计资源语义信息变化,同时,将不同设计环节中的研发设计资源利用关联关系进行整合,最终构建出研发设计资源语义全景空间,为研究人员在后续的设计过程中的研发设计资源共享提供支持。主要技术方案如下:
4.一种基于语义的研发设计资源全景空间构建方法,包括下列步骤:
5.第一步,提取在设计全流程中的文本类企业共享资源,构建研发设计资源文本语料集;
6.第二步,对研发设计资源文本语料集进行文本预处理生成研发设计资源文本语料库;
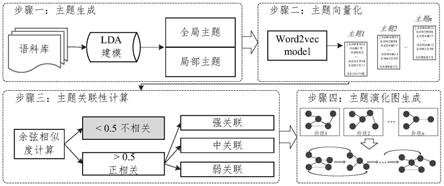
7.第三步:lda处理
8.分别对研发设计资源文本语料库和研发设计子语料库进行lda处理,生成研发设计资源全局主题和研发设计资源局部主题两部分主题内容;其中研发设计资源文本语料库是在研发设计全流程中的全资源文本,研发设计子语料库是基于研发设计子流程中的资源文本,是研发设计语料库的子集;具体方法如下:
9.1)基于研发设计全流程,构建研发设计资源全局主题
10.对研发设计资源文本语料库进行lda处理,包括确定相对应的最优主题数;
11.首先,研发设计资源全局主题的最优主题数通过层次聚类的方法得到,选取覆盖研发设计资源文本语料库内容所在的聚类簇数作为研发设计资源全局主题的最优主题数k;
12.其次,对通过层次聚类方法得到的最优主题数k进行主题一致性评估以判断其合
理性,主题一致性得分越高,研发设计资源全局主题的最优主题数k所对应的lda模型效果越好;
13.最后,根据lda算法的α和β参数以及研发设计资源全局主题的最优主题数k,构建具有k个主题数的研发设计资源全局主题g
i∈[1,k]
;
[0014]
2)基于研发设计子流程,构建研发设计资源局部主题
[0015]
根据研发设计全流程中的各个子流程阶段,将研发设计资源文本语料库划分成为分属于各个研发设计子流程的研发设计资源文本子语料库,并对每一个研发设计资源文本子语料库进行lda处理;其中各个研发设计资源文本子语料库最优主题数r
t
(t∈1,2,3,...),r
t
通过困惑度计算得到,研发设计资源子语料库困惑度的计算公式如下:
[0016][0017]
其中,m表示研发设计资源文本子语料库;
[0018]
nm表示在单个研发设计子流程下研发设计资源文本子语料库m中总词数;
[0019]
p(w)表示词w在研发设计资源文本m中的概率;
[0020]
p(z|m)表示主题z在研发设计资源文本m中的概率分布;
[0021]
p(w|z)表示词w在主题z中的概率分布;
[0022]
最后利用lda算法以及研发设计资源局部主题的最优主题数(r1,r2,..)构建具有r1,r2,..个主题数的研发设计资源局部主题l
j∈[1,rt.]
;
[0023]
第四步:主题向量化
[0024]
对生成的研发设计资源全局主题和研发设计资源局部主题进行word2vec向量化构建;
[0025]
第五步:主题关联性计算;
[0026]
通过余弦相似度公式,分别计算每一个研发设计资源全局主题向量和局部主题之间的关联性;其中关联性计算包括:研发设计资源全局主题向量间的关联性计算;研发设计资源局部主题向量间的关联性计算;研发设计资源全局主题向量与研发设计资源局部主题向量的关联计算;
[0027]
第六步:主题关联关系图谱绘制;
[0028]
设定余弦相似度阈值用以表示主题间关联程度,当阈值大于0.5,则表明两个主题间具有关联关系,反之则表明两个主题间无关联关系;其中在阈值大于0.5的关联中又进一步分为三个关联强度间隔,分别以强、中、弱关联程度表示;
[0029]
1)首先,计算相邻研发设计子流程中的研发设计资源局部主题向量间的关联性,按照研发设计资源局部主题向量间的强中弱关联强度将相邻研发设计子流程中的研发设计资源局部主题l
j∈[1,r]
关联关系构建;生成研发设计资源局部主题间关联关系图谱;
[0030]
2)计算研发设计资源全局主题向量与研发设计资源局部主题向量的关联性,生成研发设计资源全局主题的关联关系图谱;
[0031]
3)根据研发设计资源全局主题的关联关系图谱以及相对应的主题词构建研发设计资源全景空间,为研发设计人员提供支持。
[0032]
其中,第四步的主题向量化方法具体步骤如下:
[0033]
1)分别将研发设计资源全局主题g
i∈[1,k]
和研发设计资源局部主题中的各个主题词作为输入,将研发设计资源文本语料库中的文本作为输出。经过训练,得到word2vec模型。其中研发设计资源全局主题g
i∈[1,k]
和研发设计资源局部主题中的每个主题词都在word2vec模型中以100-300维度的向量形式表达。
[0034]
2)通过lda处理得到的研发设计资源全局主题g
i∈[1,k]
和研发设计资源局部主题中的各个主题均以“主题词*权重 主题词*权重
…”
的形式呈现,将研发设计全局主题g
i∈[1,k]
和研发设计资源局部主题中的各主题词向量及其权重加权求和,最终得到100-300维度向量空间的研发设计资源全局主题向量和研发设计资源局部主题向量
[0035]
本专利提出一种基于语义的研发设计资源全景空间构建方法,结合lda和word2vec方法,充分考虑了研发设计资源文本语料库上下文本语义,从设计全流程出发,构建基于设计全流程下的研发设计资源全局主题图谱,直观呈现了在设计全流程下的研发设计资源的共享状态。针对各个设计流程子环节,构建不同设计环节下的研发设计资源文本子语料库的局部主题图谱,明确了设计子任务环节中的研发设计资源共享关联关系。最后,通过对研发设计资源全局主题和研发设计资源局部主题间的关联关系图谱,有效地将在设计过程中研发设计资源共享的总体变化趋势和局部关联关系表达,解决了研发人员在研发设计资源共享过程中资源利用率低的问题。许多有关主题建模的研究一般只考虑主题词,而忽略了主题中主题词所占的权重,本发明通过加权求和得到的主题向量,充分考虑了主题词在主题中的权重和文档上下文关系,将所在主题进行了准确的表达,为下一步主题间关联计算做了良好的准备。
附图说明
[0036]
图1总体技术方案流程
[0037]
图2主题向量化方案
[0038]
图3设计流程及资源建模
[0039]
图4全局主题最优主题数生成
[0040]
图5研发设计资源全景空间
具体实施方式
[0041]
一种基于语义的研发设计资源全景空间构建方法总体技术方法流程如图1所示:
[0042]
第一步,文本资源获取
[0043]
提取在设计全流程中的所有文本类研发共享设计资源,构建研发设计资源文本语料库集。
[0044]
具体内容包括但不限于:设计各阶段需求描述,设计方案,设计讨论,设计工具列
表,工具参数列表,实施环节报告等设计流程有关的研发资源。
[0045]
第二步,文本预处理
[0046]
对研发设计资源文本语料库集进行文本预处理生成研发设计资源文本语料库,具体包括数字和特殊字符的清理,停用词和特殊词去除,用zip’s定律去除研发设计资源文本语料库中过于常见或罕见的词汇。
[0047]
第三步:lda处理
[0048]
分别对研发设计资源文本语料库和研发设计子语料库进行lda处理,生成研发设计资源全局主题和研发设计资源局部主题两部分主题内容。其中研发设计资源文本语料库是在研发设计全流程中的全资源文本,研发设计子语料库是基于研发设计子流程中的资源文本,是研发设计语料库的子集。本专利通过研发设计资源语料库构建研发设计资源全局主题,并将各设计阶段中的研发设计子语料库构建各研发设计局部主题(图3)。具体方法如下:
[0049]
1)基于研发设计全流程,构建研发设计资源全局主题。
[0050]
本专利使用gensim libray实现lda模型,lda模型由参数(α,β)以及文档主题数确定。本文中lda算法的α和β参数均设置为0.1的默认值。
[0051]
由于研发设计资源语料库包含的数据量巨大,通过困惑度计算文档lda最优主题数的方法无法适用,因此本专利中研发设计资源全局主题的最优主题数通过层次聚类的方法得到,得到聚类结果如图4(a)所示,选取覆盖研发设计资源文本语料库85%所在的聚类簇数,作为研发设计资源全局主题的最优主题数k。
[0052]
对通过层次聚类方法得到的研发设计资源全局主题的最优主题数k进行主题一致性评估(图4(b)),主题一致性越高,对应主题数所在的lda模型效果越好。
[0053]
根据lda算法的α和β参数以及研发设计资源全局主题的最优主题数k,构建具有k个主题数的研发设计资源全局主题g
i∈[1,k]
。
[0054]
2)基于研发设计子流程,构建研发设计资源局部主题。
[0055]
根据研发设计全流程中的各个子流程阶段,将研发设计资源文本语料库划分成为分属于各个研发设计子流程的研发设计资源文本子语料库,并对每一个研发设计资源文本子语料库进行lda处理。其中参数α和β参数均设置为0.1的默认值。
[0056]
各个研发设计资源文本子语料库最优主题数r
t
(t∈1,2,3,...)通过困惑度(perplexity)计算得到,困惑度(perplexity)通常在自然语言处理中用来衡量训练出的语言模型的好坏,在lda的最优主题数的选择中,通过困惑度(perplexity)计算可以量化得到在不同主题数下的lda模型效果,其中困惑度值perplexity(w)越低,对应主题数为最优主题数,且对应主题数所在训练得到的lda模型效果越好。相应研发设计资源子语料库困惑度的计算具体公式如下:
[0057][0058]
其中,m表示研发设计资源文本子语料库;
[0059]
nm表示在单个研发设计子流程下研发设计资源文本子语料库m中总词数;
[0060]
p(w)表示词w在研发设计资源文本m中的概率;
[0061]
p(z|m)表示主题z在研发设计资源文本m中的概率分布;
[0062]
p(w|z)表示词w在主题z中的概率分布。
[0063]
最后利用lda算法以及研发设计资源局部主题的最优主题数(r1,r2,..)构建具有r1,r2,..个主题数的研发设计资源局部主题
[0064]
第四步:主题向量化
[0065]
对生成的研发设计资源全局主题和研发设计资源局部主题进行word2vec向量化构建,向量化方案如图2所示。具体内容如下:
[0066]
1)分别将研发设计资源全局主题g
i∈[1,k]
和研发设计资源局部主题中的各个主题词作为输入,将研发设计资源文本语料库中的文本作为输出。经过训练,得到word2vec模型。其中研发设计资源全局主题g
i∈[1,k]
和研发设计资源局部主题中的每个主题词都在word2vec模型中以100-300维度的向量形式表达。
[0067]
2)通过lda处理得到的研发设计资源全局主题g
i∈[1,k
]和研发设计资源局部主题中的各个主题均以“主题词*权重 主题词*权重
…”
的形式呈现,因此将研发设计全局主题g
i∈[1,k]
和研发设计资源局部主题中的各主题词向量及其权重加权求和,最终得到100-300维度向量空间的研发设计资源全局主题向量和研发设计资源局部主题向量计算公式如下:
[0068][0069]
许多有关主题建模的研究一般只考虑主题词,而忽略了主题中主题词所占的权重,通过加权求和得到的主题向量,充分考虑了主题词在主题中的权重和文档上下文关系,将所在主题进行了准确的表达,为下一步主题间关联计算做了良好的准备。
[0070]
第五步:主题关联性计算
[0071]
通过余弦相似度公式,分别计算每一个研发设计资源全局主题向量和局部主题之间的关联性。余弦相似度计算公式如下:
[0072][0073]
其中关联性计算包括:研发设计资源全局主题向量间的关联性计算;研发设计资源局部主题向量间的关联性计算;研发设计资源全局主题向量与研发设计资源局部主题向量的关联计算。
[0074]
第六步:主题关联关系图谱绘制
[0075]
设定余弦相似度阈值用以表示主题间关联程度,当阈值大于0.5,则表明两个主题间具有关联关系,反之则表明两个主题间无关联关系。其中在阈值大于0.5的关联中又进一
步分为三个关联强度间隔,分别以强、中、弱关联程度表示。
[0076]
1)首先,计算相邻研发设计子流程中的研发设计资源局部主题向量间的关联性,按照研发设计资源局部主题向量间的强中弱关联强度将相邻研发设计子流程中的研发设计资源局部主题关联关系构建。生成研发设计资源局部主题间关联关系图谱。(图5)。
[0077]
2)计算研发设计资源全局主题向量与研发设计资源局部主题向量的关联性,生成研发设计资源全局主题的关联关系图谱。
[0078]
3)根据研发设计资源全局主题的关联关系图谱以及相对应的主题词构建研发设计资源全景空间,为研发设计人员提供支持。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。