技术特征:
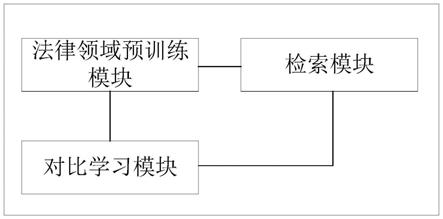
1.一种基于对比学习的长文本检索模型,其特征在于,所述长文本检索模型包括法律领域预训练模块、对比学习模块以及检索模块;其中,所述法律领域预训练模块,用于构建基础的长文本编码器,以及使用法律文书语料对所述长文本编码器进行领域预训练;所述对比学习模块,用于从案例标注数据集中构造训练数据,以及利用所述训练数据对所述长文本编码器进行文本向量训练,其中,所述训练数据包括查询语句及其正样本、负样本;所述检索模块,用于采用训练好的长文本编码器检测长文本查询语句对应的案例。2.根据权利要求1所述的长文本检索模型,其特征在于,所述检索模块,还用于利用所述长文本编码器将查询语句转换为查询向量,与案例库中所有案例的案例向量计算相似度,从而基于相似度得分高低返回检索排序结果。3.根据权利要求2所述的长文本检索模型,其特征在于,所述检索模块,还用于将数据库中的所有案例经过所述长文本编码器编码后得到对应的案例向量,并对所有案例向量进行聚类后,离线存储形成所述案例库。4.根据权利要求2或3所述的长文本检索模型,其特征在于,所述检索模块,还用于计算所述查询向量与所述案例库中的所有聚类中心的距离,获取距离最小的聚类中心对应的聚类,将该聚类中的所有案例向量按照与所述案例向量的距离大小进行排序,并以排序结果返回检索排序结果。5.根据权利要求1所述的长文本检索模型,其特征在于,所述法律领域预训练模块,还用于以中文预训练模型为基础构建所述长文本编码器;其中,所述中文预训练模型事先使用大量法律无标签语料进行全词遮罩预训练。6.根据权利要求5所述的长文本检索模型,其特征在于,所述法律领域预训练模块,还用于将所述中文预训练模型的完全注意力机制替换为滑动窗口注意力机制和全局注意力机制。7.根据权利要求6所述的长文本检索模型,其特征在于,所述法律领域预训练模块,还用于将所述完全注意力机制中的查询参数、键参数以及值参数复制到所述长文本编码器的滑动窗口注意力机制和全局注意力机制中,以实现所述长文本编码器的参数初始化。8.根据权利要求5所述的长文本检索模型,其特征在于,所述全词遮罩预训练为:将法律语料中预设比例的词汇进行遮罩标记处理和替换词汇处理,并采用所述长文本编码器对处理后的法律语料进行编码,得到预测输出词,以所述预测输出词与法律语料的距离对所述长文本编码器进行训练。9.根据权利要求5所述的长文本检索模型,其特征在于,所述中文预训练模型为roberta-wwm-ext模型,所述长文本编码器为longformer模型。10.根据权利要求1所述的长文本检索模型,其特征在于,所述对比学习模块,还用于从所述案例标注数据集中选择查询语句,及其正样本、负样本构造三元组,其中,所述正样本为所述查询语句相关的案例,所述负样本为所述查询语句不相关的案例;所述对比学习模块,还用于将所述三元组输入所述长文本编辑器进行编码,得到所述
三元组的向量表示;基于所述查询语句的向量与所述正样本的向量构建正相似度矩阵,基于所述查询语句的向量与所述负样本的向量构建负相似度矩阵,利用所述正相似度矩阵和所述负相似度矩阵构建交叉熵损失函数对所述长文本编辑器进行训练。
技术总结
本申请提供了一种基于对比学习的长文本检索模型,包括法律领域预训练模块、对比学习模块以及检索模块;其中,法律领域预训练模块,用于构建基础的长文本编码器,以及使用法律文书语料对长文本编码器进行领域预训练;对比学习模块,用于从案例标注数据集中构造训练数据,以及利用训练数据对所述长文本编码器进行文本向量训练,其中,训练数据包括查询语句及其正样本、负样本;检索模块,用于采用训练好的长文本编码器检测长文本查询语句对应的案例。通过上述方式,本申请的长文本检索模型能够有效解决深度模型处理长文本的问题,结合类案检索的特点,使用领域预训练以及对比学习方法对文档编码器进行调整,提高了检索的准确度和效率。率。率。
技术研发人员:钟泽艺 杨敏 贺倩明
受保护的技术使用者:深圳得理科技有限公司
技术研发日:2021.11.29
技术公布日:2022/3/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。