1.本发明属于图像修复技术领域,尤其涉及一种基于注意力跨层转移机制的生成式图像修复方法。
背景技术:
2.图像修复是指在图像缺损区域内生成与真实图像色彩、结构、语义一致的内容的工作,是计算机视觉重要的研究方向之一。
3.现有的图像修复方法大致分为传统的修复方法和基于深度学习的修复方法。传统的修复方法大多依靠像素扩张的方法或纹理匹配的方法进行修复,在小面积缺损区域和纯色区域的修复效果较好,但当缺损区域较大,且图像内结构复杂、语义目标较多时修复结果往往出现模糊、语义丢失、结构连通性差等问题,针对传统图像修复方法的局限性,许多学者将深度学习技术应用于图像修复领域,在大面积缺损区域修复等高难度图像修复工作中取得了令人惊叹的效果。
4.基于深度学习的图像修复方法,通过对海量图像数据的学习训练,建立起从缺损图像到修复图像的完整映射,能够在缺损区域内生成缺损区域周围没有的像素信息。而随着生成对抗网络的提出,深度学习在图像修复领域更是大放异彩。通过生成器与判别器的不断对抗,逐步提升生成图像与真实图像的一致性,最终获得优异的图像修复性能。但是目前基于深度学习的主流图像修复算法在修复大面积缺区域时,仍存在伪影、语义丢失、结构连通性不足等问题。
技术实现要素:
5.本发明的目的在于:为了解决上述现有的图像修复方法大致分为传统的修复方法和基于深度学习的修复方法,传统的修复方法大多依靠像素扩张的方法或纹理匹配的方法进行修复,在小面积缺损区域和纯色区域的修复效果较好,但当缺损区域较大,且图像内结构复杂、语义目标较多时修复结果往往出现模糊、语义丢失、结构连通性差等问题,而提出的一种基于注意力跨层转移机制的生成式图像修复方法。
6.为了实现上述目的,本发明采用了如下技术方案:一种基于注意力跨层转移机制的生成式图像修复方法,包括如下步骤:
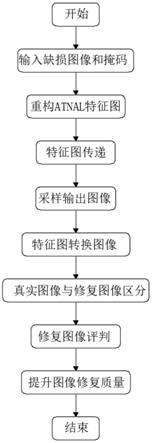
7.s1、将缺损图像和掩码一起输入网络;
8.s2、重构atnal特征图;
9.s3、通过跳跃连接将各级atnal特征图传递至多尺度解码器对应的解码层;
10.s4、输出下一层解码特征图;
11.s5、通过上采样得到输出图像;
12.s6、在解码完成后将各级输出特征图转为rgb图像;
13.s7、区分真实图像与修复图像;
14.s8、对修复图像进行评判;
15.s9、提升图像修复质量。
16.作为上述技术方案的进一步描述:
17.所述s1中,将缺损图像和掩码一起输入网络,进行编码。
18.作为上述技术方案的进一步描述:
19.所述s2中,atnal编码器在编码完成后,由深到浅逐层重构atnal特征图。
20.作为上述技术方案的进一步描述:
21.所述s3中,通过跳跃连接将各级atnal特征图传递至多尺度解码器对应的解码层,其中最深层解码特征图由对应的编码特征图反卷积而来。
22.作为上述技术方案的进一步描述:
23.所述s4中,与对应尺度的atnal特征图融合后进行解码输出下一层解码特征图。
24.作为上述技术方案的进一步描述:
25.所述s5中,通过上采样得到尺寸大小为256*256的输出图像。
26.作为上述技术方案的进一步描述:
27.所述s6中,在解码完成后将多尺度解码器各级输出特征图转为rgb图像。
28.作为上述技术方案的进一步描述:
29.所述s7中,使用对抗损失对图像判别器进行约束,区分真实图像与修复图像。
30.作为上述技术方案的进一步描述:
31.所述s8中,引用风格损失和感知损失对修复图像进行评判。
32.作为上述技术方案的进一步描述:
33.所述s9中,最小化各级解码层最终输出的rgb图像与真实图像之间的l1损失对生成器进行约束,提升图像修复质量。
34.综上所述,由于采用了上述技术方案,本发明的有益效果是:
35.本发明中,通过提出注意力跨层转移网络,在生成器对缺损图像编码完成后由深入浅逐层重构编码特征图,为解码工作提供指导,提出多尺度解码器,使用跳跃连接将atnal重构特征图连接至多尺度解码器对应解码层,与上一级潜在特征融合进行解码,最大限度减少解码过程中上下文信息丢失,创新应用l1损失,将解码过程中的各尺度特征图转为rgb图像后使用l1损失进行约束,促使多尺度解码器生成上下文语义一致的精细内容。
附图说明
36.图1为一种基于注意力跨层转移机制的生成式图像修复方法的流程图。
具体实施方式
37.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
38.本发明提供一种技术方案:一种基于注意力跨层转移机制的生成式图像修复方法,包括如下步骤:
39.s1、将缺损图像和掩码一起输入网络,进行编码;
40.s2、atnal编码器在编码完成后,由深到浅逐层重构atnal特征图;
41.s3、通过跳跃连接将各级atnal特征图传递至多尺度解码器对应的解码层,其中最深层解码特征图由对应的编码特征图反卷积而来;
42.s4、与对应尺度的atnal特征图融合后进行解码输出下一层解码特征图;
43.s5、通过上采样得到尺寸大小为256*256的输出图像;
44.s6、在解码完成后将多尺度解码器各级输出特征图转为rgb图像;
45.s7、使用对抗损失对图像判别器进行约束,区分真实图像与修复图像;
46.s8、引用风格损失和感知损失对修复图像进行评判;
47.s9、最小化各级解码层最终输出的rgb图像与真实图像之间的l1损失对生成器进行约束,提升图像修复质量。
48.本实施例中,提出注意力跨层转移网络,能够在生成器对缺损图像编码完成后由深到浅逐层重构编码特征图(即atnal特征图),通过跳跃连接将atnal特征图与对应潜在特征融合进行解码得到修复图像。通过atnal特征图与跳跃连接的组合使用,充分利用了包含更多语义信息的高级特征和带有更多结构及纹理细节的低级特征。为了保证解码过程中上下文信息的顺利传递,引入了重构l1损失对各级解码层输出的rgb图像进行评判,并结合感知损失、风格损失、对抗损失对网络的整个训练过程进行约束,该模型能够生成与真实图像语义一致,结构合理且富含细节纹理特征的内容。
49.本实施例中,需要说明的是:
50.s2中,atnal编码器在编码完成后,由深到浅逐层重构atnal特征图,具体而言为:注意力跨层转移网络从高级语义特征中学习缺失区域内外的补丁之间的区域有效性,并且在其先前的具有更高分辨率的特征图中将学习的注意力转移到当前特征图缺损区域。从深到浅将编码过程输出的特征图标记为α6、α5、α4、α3、α2、α1、。以f(
·
)表示atnal操作,则各级重构特征为:
51.β5=f(α5,α6);
52.β4=f(α4,β5);
53.β3=f(a3,β4);
54.β2=f(α2,β3);
55.β1=f(α1,β2)。
56.s3中,多尺度解码器将atnal特征图以跳跃连接的方式和来自编码器的潜在特征一起作为输入进行解码。将多尺度解码器各层输出的解码特征图表示为γ5、γ4、γ3、γ2、γ1,具体操作如下:
[0057][0058][0059][0060][0061][0062]
其中l表示转置卷积运算,表示特征拼接。在解码工作中,atnal特征图能够为缺失区域提供更多低级信息,这样的设计使得多尺度解码器能够利用颗粒级的细节生成视觉
上逼真的结果。同时,即使缺损区域外不能找到对应像素内容,通过卷积从紧凑的潜在特征获得的特征也能够在缺失区域中合成新的目标。结合两方面影响,多尺度解码器能够利用图像的上下文信息合成语义和纹理高度一致的新内容。
[0063]
多尺度解码器解码完成后,分别将各级解码层输出的特征图与对应atnal特征图融合后转为rgb图像,并将最后一层的解码层输出与对应尺度的atnal特征图融合进行一次上采样的到修复图像。
[0064]
图像判别器采用path gan架构,path gan实则为全卷积网络,将输入映射为n
×
n的矩阵x,x
ij
的值代表对应path为真实样本的概率,最终将x
ij
求均值,即为判别器输出。判别器输入图片尺寸为256*256,使用的path gan能判断70*70的重叠图像块是否真实。
[0065]
s7中,使用对抗损失对图像判别器进行约束,区分真实图像与修复图像,其中损失函数定义真实图片为i
gt
,m表示掩码(缺损区域为1,背景区域为0),则缺损图像为i
brk
=i
gt
⊙
(1-m),生成图像为i
pre
=g(i
brk
,m),其中g(
·
)表示图像生成网络,此外d(
·
)表示图像判别网络。整个修复网络的最终输出图像为融合图像:i
comp
=i
brk
i
pre
⊙
m。
[0066]
本文网络使用的损失函数分为对抗损失风格损失感知损失l1重构损失四部分。整体损失函数公式如下:
[0067][0068]
本文选择将上式中各损失函数权重参数设置如下:λ
adv
=0.1,λs=250,λ
p
=0.1,
[0069]
传统gan的损失函数形式为:
[0070][0071]
其中,x、z分别表示真实样本与噪声,p
data
、pz分别表示表示真实样本和噪声的分布。gan的对抗损失是一个最大最小优化问题,可分解为对生成器g与判别器d的两个优化问题。
[0072]
对于判别器d,损失函数可表示为:
[0073][0074]
对于生成器g,损失函数可表示为:
[0075][0076]
对判别器d而言,判别真实样本时得到的结果越大越好,即d(x)越大越好;判别假样本时得到的结果越小越好,即d(g(z))越小越好;此时前后项矛盾,则将等价代换为这样两者合起来则判别器结果越大越好。对生成器g而言,判别器判断生成的假样本的结果越大越好,即d(g(z))越大越好,为了统一形式,将等价代换为
[0077]
本文对抗损失设定如下:
[0078]
[0079]
通过最小化对抗损失,使得判别器不断提升判别图像真伪的准确性,进而促进生成器生成与真实图像更一致的内容。
[0080]
在计算机视觉中,风格损失可以定义为通道间激活值之间的相关系数,使用i层的激活来度量这个系数。本文用σi代表图像在imagenet上训练的vgg-19网络中relu_1_1、relu_2_1、relu_3_1、relu_4_1、relu_5_1的对应激活特征图,通过计算对应尺度不同激活图之间的偏心协方差来表示其相关性。具体来说,定义风格损失如下:
[0081][0082]
其中,是一个ci×ci
的gram矩阵,由σi构成。通过现有研究表明,使用可以有效对抗由转置卷积引起的模糊效应。
[0083]
具体而言,感知损失是将真实图片卷积得到的特征图与生成图片通过卷积得到的特征图进行比较,通过最小化感知损失使得两类图片的高层语义接近。本文感知损失的计算过程中选择和风格损失计算工作中用到的vgg-19网络,并且选择同样的激活层。具体定义如下:
[0084][0085]
其中,nj表示第j个激活层中的元素个数,同风格损失一致,σj是vgg-19网络中的对应层的激活特征图。
[0086]
为了保证解码工作中语义信息和细节特征的完整传递,保持上下文特征一致性,将l1损失应用于各级解码层输出的rgb图像,具体如下:
[0087][0088]
通过将真实图像缩放至与各尺度rgb图像相同大小,并计算两者之间的l1归一化距离,来表示生成图片与真实图片之间的l1重构损失。其中i
gtl
是缩放到与γ
l
相同大小的真实图片,r(
·
)表示1
×
1卷积,它将γ
l
解码为具有相同大小的rgb图像。
[0089]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。