1.本发明属于数据安全技术领域,具体涉及一种基于条件隐私集合求交的联邦学习模型训练方法。
背景技术:
2.在现实生活中,如果各个机构中,能够将它们的数据共享进行数据挖掘或机器学习,那么将会有越来越大的潜在收益。为了打破数据壁垒,采用联邦学习的方法使各个参与方在无需共享其隐私数据的前提下获得全局模型。2017年,mcmahan等首次正式提出了联邦学习的概念,即利用分散在移动设备上的训练数据进行本地计算,然后通过聚合这些本地计算更新学习共享模型。联邦学习通常借助客户端-服务器这样的基本架构,实现分散数据的协同模型训练。其中许多客户端(可以是移动设备或独立的组织、机构等)在中央服务器的协调下以协作方式训练模型,而客户端无需上传或交换数据,始终保持着对其本地私有数据的控制权。和传统机器学习方式相比,这种方式减轻了先将数据收集在一起再进行模型训练所带来的潜在数据存储、数据管理等多方面的成本,同时满足了越来越严格的数据隐私安全保护的要求。联邦学习可以在不损害数据隐私和安全的前提下,对来自多方的数据进行统一建模。
3.在纵向联邦学习中,要进行后续的联合训练模型,必须先进行样本对齐。为了保护双方的数据隐私,现有的方案一般是通过隐私集合求交(private set intersection,psi)协议来完成样本对齐操作。条件隐私集合求交技术(conditional private set intersection,cpsi)是psi协议的一种变种,它可以让客户端提出一个条件(该条件对于服务端不可见),最后得到的交集是既满足条件也是双方交集的数据。当cpsi协议用于样本对齐时,还可使双方得到服务端满足条件的交集秘密份额,进而双方进行两方纵向联邦学习。在这种场景下,客户端甚至可以发起一个服务端完全不知道客户端意图的联邦学习,保护了客户端的意图。比如,在风控场景中,一家机构很明显不想让其他机构(特别是竞争对手)知晓其下一步的动向。而cpsi协议的优越性能够做到使服务端完全不知道客户端的意图,因此如何基于条件隐私集合求交进行联邦学习是亟待解决的问题。
技术实现要素:
4.为解决以上现有技术存在的问题,本发明提出了一种基于条件隐私集合求交的联邦学习模型训练方法,该方法包括:客户端和服务端采用条件隐私集合求交协议对各自的数据进行处理,得到训练数据集;客户端和服务端分别初始化模型训练参数;根据初始化模型训练参数以及训练数据集进行模型训练。
5.优选的,采用条件隐私集合求交协议对各自的数据进行处理包括:客户端设置条件ρ,根据客户端设置的条件客户端和服务端对各自的数据执行条件隐私集合求交协议,客户端得到满足条件的标识符交集ic,服务端得到得到满足条件的服务端数据份额客户
端根据标识符交集ic得到客户端训练数据xc、满足条件的客户端数据份额
6.优选的,对模型进行训练的过程包括:
7.s1:设置训练轮次t;
8.s2:客户端采用自己的公钥对训练集中的数据进行加密,得到密文并将加密后的密文发送给服务端;其中,表示客户端数据份额,pkc表示客户端公钥;
9.s3:根据服务端初始参数和服务端的数据份额计算ωsx
s1
,并采用客户端公钥对计算出的进行加密,得到密文服务端接收客户端的密文并根据自身加密后的密文计算密文参数将计算的密文参数发送给客户端;其中,ωs表示服务端的初始模型参数
10.s4:客户端对密文参数进行解密,得到明文ωsxs;根据解密后的明文、客户端的训练集数据以及客户端的初始模型训练参数计算客户端的残差ωx-2y;并将计算的残差发送给服务端;计算残差的公式为:ωx-2y=ωcxc ωsx
s-2y,其中y表示数据集的标签,xs表示客户端和服务端的数据份额,xc表示客户端的训练数据,ω表示模型参数;
11.s5:客户端计算本轮的梯度,并根据计算的梯度对模型训练参数进行更新;
12.s6:客户端根据更新的参数生成满足拉普拉斯机制的噪声z
t
;根据噪声计算参数更新后的客户端残差将计算结果发送给服务端;
13.s7:服务端根据客户端发送的残差ωx-2y和计算服务端的梯度,并根据计算出的梯度对服务端的训练参数进行更新;
14.s8:重复步骤s2~7,直到训练轮次结束,客户端得到模型wc、服务端得到模型ws;服务端将模型ws发送给客户端;
15.s9:客户端根据服务端发送的模型得到完整的模型。
16.进一步的,客户端计算梯度的公式为:
[0017][0018]
x=xc xs[0019]
其中,b表示每一轮训练的数据量大小,xc表示客户端的训练数据,xs表示客户端和服务端的数据份额,x表示客户端和服务端共有的数据集。
[0020]
进一步的,客户端对模型训练参数进行更新包括:
[0021]
ωc=ω
c-gc[0022]
其中,ωc表示客户端模型的训练参数,gc表示客户端计算的梯度。
[0023]
进一步的,计算服务端的梯度公式为:
[0024][0025]
其中,b表示每一轮训练的数据量大小,表示服务端数据份额,表示客户端数据份额,z
t
表示满足ε-差分隐私的噪声。
[0026]
服务端对模型训练参数进行更新包括:
[0027]
ωs=ω
s-gs[0028]
其中,ωs表示服务端模型的训练参数,gs表示服务端计算的梯度。
[0029]
为实现上述目的,本发明还提供一种计算机可读存储介质,其上存储有联邦学习模型训练程序,所述联邦学习模型训练程序被处理器执行时实现任一上述基于条件隐私集合求交的联邦学习模型训练方法。
[0030]
为实现上述目的,本发明还提供一种基于条件隐私集合求交的联邦学习模型训练装置,包括处理器和存储器;所述存储器用于存储联邦学习模型训练程序;所述处理器与所述存储器相连,用于执行所述存储器存储的联邦学习模型训练程序,以使所述一种基于条件隐私集合求交的联邦学习模型训练装置执行任一上述基于条件隐私集合求交的联邦学习模型训练方法。
[0031]
本发明的优点:
[0032]
本发明提出的联邦学习模型训练方法中加入了差分隐私技术,使服务端无法从得到的模型推测其训练数据,安全的保护了两方数据,同时也帮助客户端得到目标模型;在模型使用时,可由服务端帮助客户端共同使用该模型,也可在训练结束时服务端把模型交于客户端,由客户端单独使用,提高了模型的训练效率和训练精度。
附图说明
[0033]
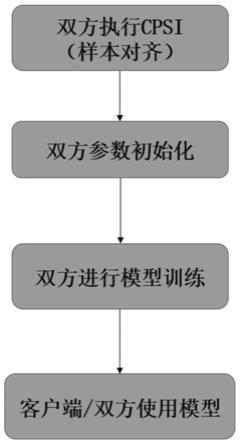
图1表示本发明的一种基于条件隐私集合求交的联邦学习模型训练方法整体流程图。
[0034]
图2表示本发明的联邦学习模型训练流程图。
具体实施方式
[0035]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0036]
一种基于条件隐私集合求交的联邦学习模型训练方法,如图1,以两方纵向逻辑回归为例,介绍本发明提出的联邦学习模型训练方法,该方法包括:客户端与服务端利用条件隐私集合求交协议得到训练数据;客户端与服务端分别初始化模型训练参数;客户端与服务端进行模型训练。
[0037]
采用条件隐私集合求交协议对各自的数据进行处理包括:客户端设置条件ρ(该条件对于客户端是不可见的),根据客户端设置的条件客户端和服务端对各自的数据执行条件隐私集合求交协议,客户端得到满足条件的标识符交集ic,服务端得到得到满足条件的服务端数据份额客户端根据标识符交集ic得到客户端训练数据xc、满足条件的客户端数据份额设置的条件可以是任意条件,需要根据客户的需求来确定,比如要求得到年龄《35且收入》100000的数据。
[0038]
服务端与客户端分别初始化各自的模型训练参数ω等。其中,服务端的初始模型
为ωs,客户端的初始模型为ωc,采用mini-batch梯度下降进行模型训练,sigmod函数拟合采用泰勒扩展,设模型训练的轮数为t,每一轮训练的数据量大小为b。客户端持有加法同态加密方案(如exp-elgamal方案、ou方案等)密钥(pkc,skc)。
[0039]
如图2所示,对模型进行训练的过程包括:
[0040]
s1:设置训练轮次t;
[0041]
s2:客户端采用自己的公钥对训练集中的数据进行加密,得到密文并将加密后的密文发送给服务端;其中,表示客户端数据份额,pkc表示客户端公钥;
[0042]
s3:根据服务端初始参数和服务端的数据份额计算并采用客户端公钥对计算出的进行加密,得到密文服务端接收客户端的密文并根据自身加密后的密文计算密文参数将计算的密文参数发送给客户端;其中,ωs表示服务端的初始模型参数
[0043]
s4:客户端对密文参数进行解密,得到明文ωsxs;根据解密后的明文、客户端的训练集数据以及客户端的初始模型训练参数计算ωx-2y=ωcxc ωsx
s-2y,并将计算的ωx-2y发送给服务端;其中y表示数据集的标签,xs表示客户端和服务端的数据份额,ω表示模型参数;
[0044]
s5:客户端计算本轮的梯度,并根据计算的梯度对模型训练参数进行更新;客户端计算梯度的公式为:
[0045][0046]
x=xc xs[0047]
其中,b表示每一轮训练的数据量大小,xc表示客户端的训练数据,x表示客户端和服务端共有的数据集,xs表示客户端和服务端的数据份额。
[0048]
客户端对模型训练参数进行更新包括:
[0049]
ωc=ω
c-gc[0050]
其中,ωc表示客户端模型的训练参数,gc表示客户端计算的梯度。
[0051]
s6:客户端根据更新的参数以拉普拉斯机制或高斯机制生成满足ε-差分隐私的噪声z
t
,并计算将计算结果发送给服务端;
[0052]
s7:服务端根据客户端发送的ωx-2y和计算服务端的梯度,并根据计算出的梯度对服务端的训练参数进行更新;
[0053][0054]
其中,b表示每一轮训练的数据量大小,表示服务端数据份额,表示客户端数据份额,z
t
表示满足ε-差分隐私的噪声。
[0055]
服务端的参数更新公式为:
[0056]
ωs=ω
s-gs[0057]
其中,ωs表示服务端的模型训练参数,gs表示服务端进行模型训练的梯度。
[0058]
s8:重复步骤s2~7,直到训练轮次结束,客户端得到模型wc、服务端得到模型ws;服务端将模型ws发送给客户端;
[0059]
s9:客户端根据服务端发送的模型得到完整的模型。
[0060]
在完成t轮以上的训练过程后,客户端得到模型wc,服务端得到模型ws。此时,服务端可以把模型ws直接发送给客户端,让客户端得到完整模型w=wc ws,也可以在后续的模型使用中,辅助客户端进行模型使用。
[0061]
于本发明一实施例中,本发明还包括一种计算机可读存储介质,其上存储有联邦学习模型训练程序,该程序被处理器执行时实现上述任一所述基于条件隐私集合求交的联邦学习模型训练方法。
[0062]
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过联邦学习模型训练程序相关的硬件来完成。前述的联邦学习模型训练程序可以存储于一计算机可读存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0063]
一种基于条件隐私集合求交的联邦学习模型训练装置,包括处理器和存储器;所述存储器用于存储联邦学习模型训练程序;所述处理器与所述存储器相连,用于执行所述存储器存储的联邦学习模型训练程序,以使所述一种基于条件隐私集合求交的联邦学习模型训练装置执行任一上述基于条件隐私集合求交的联邦学习模型训练方法。
[0064]
具体地,所述存储器包括:rom、ram、磁碟、u盘、存储卡或者光盘等各种可以存储程序代码的介质。
[0065]
优选地,所述处理器可以是通用处理器,包括中央处理器(central processing unit,简称cpu)、网络处理器(network processor,简称np)等;还可以是数字信号处理器(digital signal processor,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现场可编程门阵列(field programmable gate array,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
[0066]
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
