1.本技术涉及数据存储技术领域,尤其涉及一种数据存储方法及设备。
背景技术:
2.时序数据是基于某种频率持续产生的一系列数据,在应用性能监测(applicationperformance monitor,apm)、物联网和工业互联网等领域存在海量时序数据,对时序数据的读写、存储管理都提出了很大的挑战。以车辆网为例,假设20000辆车每秒采集60个监测指标,每秒就要产生1200000个数据点,每小时将产生73.8gb左右的数据,这给时序数据的存储带来了极大的挑战。
3.在时序数据库中,时序数据的标签部分用于构建构建时间线索引。在时间线膨胀应用场景中,时间线高基数问题随之产生,导致时间线索引不断膨胀,从而导致在时序数据检索时,查询索引的耗时增加。
技术实现要素:
4.本技术的多个方面提供一种数据存储方法及设备,用以实现动态调整时间窗口的时间分区存储,可降低出现时间线高基数的概率,进而有助于提高后续数据查询效率。
5.本技术实施例提供一种数据存储方法,包括:
6.获取待存储时序数据;
7.在已创建的时间分区存在所述待存储时序数据的时间戳对应的第一时间分区的情况下,获取所述第一时间分区存储的时序数据的数据特征;
8.根据所述第一时间分区存储的时序数据的数据特征,确定目标时间窗口;
9.根据所述待存储时序数据的时间戳,创建具有所述目标时间窗口的第二时间分区;
10.将所述待存储时序数据存储于所述第二时间分区。
11.本技术实施例还提供一种计算设备,包括:存储器和处理器;其中,所述存储器,用于存储计算机程序;所述存储器创建有时间分区;
12.所述处理器耦合至所述存储器,用于执行所述计算机程序以用于执行上述数据存储方法中的步骤。
13.本技术实施例还提供一种存储有计算机指令的计算机可读存储介质,当所述计算机指令被一个或多个处理器执行时,致使所述一个或多个处理器执行上述数据存储方法中的步骤。
14.本技术实施例还提供一种计算机程序产品,包括计算机程序;当所述计算机程序被处理器执行时,致使所述处理器执行上述数据存储方法中的步骤。
15.在本技术实施例中,一方面,可将待存储数据存储于新创建出的第二时间分区,而非直接存储于待存储时序数据的时间戳对应的第一时间分区,有助于降低第一时间分区出现时间线高基数的问题;另一方面,由于待存储时序数据的时间戳对应的第一时间分区的
数据特征,在一定程度上可反映第一时间分区对应的时间范围内的时序数据的时间线基数,因此,根据第一时间分区的数据特征,自适应调整第二时间分区的时间窗口,使得第二时间分区的时间窗口随数据特征弹性伸缩,可降低第二时间分区出现时间线高基数的问题。这样,由于每个时间分区均不存在时间线高基数问题,每个时间分区的索引较少,因此在时序数据查询时,针对每个时间分区进行索引查询效率较高。
附图说明
16.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
17.图1为时序数据库influxdb的数据存储方式示意图;
18.图2为时序数据库influxdb的分片组删除策略示意图;
19.图3为本技术实施例提供的时序数据的数据存储方式示意图;
20.图4为本技术实施例提供的时间分区的删除方式示意图;
21.图5为本技术实施例提供的写入吞吐量随时间的变化曲线示意图;
22.图6为本技术实施例提供的数据存储方法的流程示意图;
23.图7为本技术实施例提供的分区目录存储示意图;
24.图8为本技术实施例提供的另一数据存储方法的流程示意图;
25.图9为本技术实施例提供的数据查询方法的流程示意图;
26.图10为本技术实施例提供的计算设备的结构示意图。
具体实施方式
27.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术具体实施例及相应的附图对本技术技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
28.针对现有时序数据存储中时间线高基数问题,在本技术一些实施例中,一方面,可将待存储数据存储于新创建出的第二时间分区,而非直接存储于待存储时序数据的时间戳对应的第一时间分区,有助于降低第一时间分区出现时间线高基数的问题;另一方面,由于待存储时序数据的时间戳对应的第一时间分区的数据特征,在一定程度上可反映第一时间分区对应的时间范围内的时序数据的时间线基数,因此,根据第一时间分区的数据特征,自适应调整第二时间分区的时间窗口,使得第二时间分区的时间窗口随数据特征弹性伸缩,可降低第二时间分区出现时间线高基数的问题。这样,由于每个时间分区均不存在时间线高基数问题,每个时间分区的索引较少,因此在时序数据查询时,针对每个时间分区进行索引查询效率较高。
29.以下结合附图,详细说明本技术各实施例提供的技术方案。
30.应注意到:相同的标号在下面的附图以及实施例中表示同一物体,因此,一旦某一物体在一个附图或实施例中被定义,则在随后的附图和实施例中不需要对其进行进一步讨论。
31.时序数据是指基于某种频率持续产生的一系列数据。时序数据可包括:标签
(tag)、时间戳、度量(metric)和度量值等信息。其中,标签(tag)由标签键(tagkey)和对应的标签值(tagvalue)组成,用于表示监测对象。度量(metric)表示监测指标;度量值表示监测指标的具体数值。时间戳可表示设备采集到度量值的时间。现结合表1所示的时序数据,对时序数据包含的信息进行说明。
32.表1时序数据示例
33.设备区域时间戳温度湿度d0001华北区2021-12-24t00:00:00112.145d0001华北区2021-12-24t00:00:00212.647
…………………………
d0002华南区2021-12-24t00:00:00113.543d0002华南区2021-12-24t00:00:00213.642
34.在表1中,标签为:设备 区域;标签值为“华北区的d0001号设备”和“华南区的d0002号设备”,即监测对象为“华北区的d0001号设备”和“华南区的d0002号设备”。度量为:温度和湿度。温度和湿度下的值即为度量值。因此,表1可表示华北区的d0001号设备的温度时间序列(time serie)和湿度时间序列(time serie),以及,华南区的d0002号设备的温度时间序列和湿度时间序列。其中,时间序列也可称为时间线。
35.时间线或时间序列表示同一对象的同一指标随时间变化产生的一系列数据。其中,同一对象的一个指标随时间变化产生的一系列数据,即为一条时间线。相应地,表1所示的时序数据包括:4条时间线。即华北区的d0001号设备的温度时间序列和湿度时间序列,以及,华南区的d0002号设备的温度时间序列和湿度时间序列。
36.数据点是指针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点。即数据点每条时间线中的指标值。其中,每条时间线中的一条指标值即为一个数据点,可以“一个度量 n个标签(n≥1) 一个时间戳 一个度量值”定义一个数据点。例如,表1中“华北区的d0001号设备在2021-12-24t00:00:001”的温度为12.1℃即为1个数据点。在本技术实施例中,将时序数据划分为:键值数据和域值数据。其中,键值数据包括:标签及标签值,用于表示监测对象。域值数据包括:时序数据的时间戳和度量数据。度量数据包括度量和度量值。
37.对于时序数据的查询一般需要支持标签(tag)的多维检索,即时序数据的查询一般分成索引查询和实际数据(度量值)的扫描两个步骤。其中索引查询的快慢决定了查询效率的高低。在一些应用场景中,时序数据中时间线会随着时间不断增加。例如,在apm场景中,监测对象为应用的进程,每个进程都一个唯一的进程标识(pid),如果将pid作为标签,当应用的进程增加时,pid也会增加,导致时间线增加。时序数据的时间线不断增加,出现时间线高基数问题,导致索引会不断增加,导致索引查询效率会越来越低。由于时序数据的查询会查询时间范围,随着时序数据不断的写入,存储的时序数据会越来越多,在扫描实际数据(度量值)时,将会在磁盘上读取大量无效数据,导致查询效率低。
38.在一些方案中,如时序数据库influxdb,如图1所示,可对时序数据库设置若干个保留策略(retention policy)和一个序列文件(series file)。每个保留策略下面包含若干个分片组(shard group)。保留策略是指时序数据进行保留的策略,可用于决定哪些数据无需保留,这样,可根据保留策略,删除无需保留的数据,以释放磁盘空间容纳后续的新写
入的时序数据。在默认配置下,时序数据库influxdb按照7天时间范围进行时间分片,即每个分片组保留的数据的时间范围为7天。如图2所示,保留策略下面的分片组随时间不断生成和删除。图2中虚线框表示根据保留策略进行删除的分片组。
39.序列文件,负责存储写入的时序数据的键值部分的数据,并为每个时间线键值分配一个唯一的标识,该标识可用于构建支持多维检索的倒排索引。
40.上述时序数据库influxdb虽然对时序数据的域值部分进行时间分区存储,在一定程度上可解决域值数据高基数问题。但是上述时序数据库influxdb的时序数据存储方式仍然存在以下问题:
41.1、时间线高基数问题:influxdb的时间分区只对时序数据的域值部分进行了时间分区,未对键值部分进行分区,在时间线膨胀型应用场景,会造成序列文件存储的键值数据膨胀,导致索引会不断增加,从而导致索引查询效率下降。
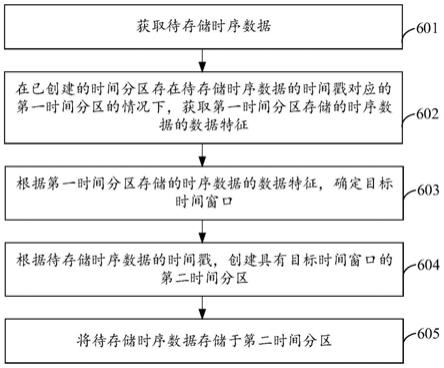
42.2、数据过期问题:在influxdb的时序数据存储方式中,键值数据没有和域值数据一起进行时间分区,在过期删除域值数据时,无法友好删除已经过期的键值数据。
43.3、时间分区的时间窗口调整问题:不支持根据数据特征自适应调整时间分区的时间窗口,且手动调整时间分区的时间窗口无法立即生效,需要等待上一次时间分区存储结束,才能在生效。
44.针对上述技术问题,本技术实施例提出一种新的时序数据存储方式。如图3所示,本技术实施例可将时序数据的键值数据和域值数据一起进行时间分区。具体地,在本技术实施例中,可对时序数据进行时间分区存储。时间分区以时间窗口(interval)进行数据分片。时间窗口也可称为时间间隔。每个时间分区用于存储该时间分区对应时间段的时序数据。如图3所示,数据库可包括:多个时间分区。多个是指2个或2个以上。在本技术实施例中,可将时序数据分为键值数据和域值数据;并将时序数据的键值数据和域值数据一起进行时间分区;根据时序数据的时间戳,将时序数据存储于时间范围包含该时序数据的时间戳的时间分区,即将时序数据的键值数据和域值数据一起存储于时间范围包含该时序数据的时间戳的时间分区。
45.本技术实施例提供的时序数据存储方式可将时序数据的键值数据和域值数据存储在同一时间分区。由于键值数据在每个时间分区内都是独立、互不影响,解决了在时间线膨胀型应用场景下,每个时间分区内的相同时间线对应的时间线id是不同的,因此,每个时间分区可以各自维护各自的索引,有助于降低索引大小,进而有助于提高后续索引查询效率。
46.在本技术实施例中,由于将时序数据的键值数据和域值数据存储于同一个时间分区,当某个时间分区的时序数据不在数据保留周期内时,可将整个时间分区的时序数据从磁盘上删除。其数据删除示意图如图4所示,对于无需保留的时间分区,可将该时间分区的时序数据从磁盘中删除。图4中无需保留的时间分区为:时间范围在20210705-20210711及20210712-20210718的两个时间分区。
47.本技术实施例提供的将时序数据的键值数据和域值数据存储于同一个时间分区的时序数据存储方式,在一定程度上可解决时间数据高基数问题。但是,在实际应用场景中,如图5所示,数据库系统的写入吞吐量并非是固定不变的。数据库系统的写入吞吐量会随时间变化而变化,存在一定的波峰波谷。图5中以tps表示写入吞吐量。因此,在时间维度
上对时序数据进行时序分区存储时,不同时间范围的时间分区存储的数据量是不同的,在波峰时间段的时间分区写入的时序数据的数据较多,在波谷时间段的时间分区写入的时序数据较少。
48.对于时间线膨胀型应用场景,虽然采用时间分区的方式对时序数据进行分片存储,避免了全局时间线高基数问题,但是如果在数据库的写入吞吐量的波峰阶段,短时间内高吞吐写入,依然是有可能造成单个时间分区内出现时间线高基数的问题。例如,在apm场景中,pid随着时间变化而增加。又例如,在容器状态监测场景中,在访问高峰期,容器数量会急剧增加,容器标识也会随着急剧增加。在波谷时间段内,由于写入吞吐较低,多个时间分区内的数据都较少,导致时序数据存储比较分散。这样,在时序数据查询时,导致查询因时序数据存储比较离散而耗时增加。
49.为了解决上述技术问题,本技术实施例提出动态调整时间分区的时间窗口的大小的数据存储方法,以解决上述单个时间分区的时间线高基数问题。下面结合具体实施例进行示例性说明。
50.图6为本技术实施例提供的数据存储方法的流程示意图。如图6所示,该数据存储方法包括:
51.601、获取待存储时序数据。
52.602、在已创建的时间分区存在待存储时序数据的时间戳对应的第一时间分区的情况下,获取第一时间分区存储的时序数据的数据特征。
53.603、根据第一时间分区存储的时序数据的数据特征,确定目标时间窗口。
54.604、根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区。
55.605、将待存储时序数据存储于第二时间分区。
56.在本技术实施例中,数据存储方法的执行主体。可选地,数据存储方法的执行主体可对数据库进行管理的逻辑节点。该逻辑节点可部署于数据库所在设备,也可部署于其它设备。
57.在本技术实施例中,待存储时序数据为执行数据存储方法的设备接收到的时序数据,该时序数据尚未写入数据库。关于时序数据的描述可参见上述实施例的相关内容,在此不再赘述。
58.对于步骤601获取的待存储时序数据,可对待存储时序数据进行时间分区存储,将待存储时序数据存储在时间范围包含待存储时序数据的时间戳的时间分区。时间分区的时间范围是指时间分区对应的起止时间,即该时间分区用于存储时间戳在该时间范围的时序数据。
59.基于此,在本技术实施例中,可根据待存储时序数据的时间戳和已创建的时间分区对应的时间范围,判断已创建的时间分区是否存在待存储时序数据的时间戳对应的时间分区。其中,待存储时序数据的时间戳对应的时间分区是指时间范围包含待存储时序数据的时间戳的时间分区。
60.在一些实施例中,时间分区的时间范围可以起始时间和终止时间进行表示。相应地,可判断待存储时序数据的时间戳是否包含在已创建的时间分区的时间范围内;若判断结果为是,确定已创建的时间分区存在待存储时序数据的时间戳对应的时间分区;并时间范围包含待存储时序数据的时间戳的时间分区,确定为待存储时序数据的时间戳对应的时
间分区。相应地,若待存储时序数据的时间戳未包含在已创建的时间分区的时间范围内,确定已创建的时间分区不存在待存储时序数据的时间戳对应的时间分区。
61.在本技术实施例中,可为时间分区设置分区标识。其中,分区标识是指可唯一表示一个时间分区的信息。在本技术一些实施例中,可以表征时间分区存储的时序数据的时间戳的分区标识。例如,可将时间分区的分区标识设置为以下方式:
62.partition id=timestamp/interval
ꢀꢀꢀꢀ
(1)。
63.在式(1)中,timestamp为时序数据的时间戳,interval为时间分区的时间窗口大小,partition id表示时间分区的分区标识。如果时间窗口相同,则计算出来的分区标识partition id可唯一标识一个时间分区。在时间窗口不同时,对于两个不同时间窗口的时序数据,利用上述确定出的分区标识可能相同。因此,可采用(partition id,interval)的二元组来唯一标识一个时间分区。因此,在本技术实施例中,可以(partition id,interval)的二元组作为分区标识。基于上式可得时间分区的时间范围为[partition id*interval,(partitionid 1)*interval),这个时间范围可为左开右闭。
[0064]
基于上述分区标识,在判断已创建的时间分区是否存在待存储时序数据的时间戳对应的时间分区时,可根据待存储时序数据的时间戳和当前记录的时间窗口,确定待存储时序数据对应的目标分区标识。其中,当前记录的时间窗口可为已创建的时间分区中最晚建立的时间分区的时间窗口。基于上述式(1),可利用待存储时序数据的时间戳除以当前记录的时间窗口,得到分区标识partition id;并确定由得到的分区标识和当前记录的时间窗口组成的二元组,作为目标分区标识。
[0065]
进一步,可将目标分区标识在已创建的时间分区的分区标识中进行查找。其中,已创建的时间分区也可以已创建的时间分区的时间戳计算出的partition id和对应的时间窗口组成的二元组进行表示。若在已创建的时间分区的分区标识中查找到目标分区标识,确定已创建的时间分区存在待存储时序数据的时间戳对应的时间分区。相应地,若未在已创建的时间分区的分区标识中查找到目标分区标识,确定已创建的时间分区不存在待存储时序数据的时间戳对应的时间分区。
[0066]
在本技术实施例中,对于已创建的时间分区存在待存储时序数据的时间戳对应的时间分区,由于无法预测该时间分区未来到来的时序数据的时间线数量,而时间分区已存储的时序数据的数据特征可反映时间分区已有时间线情况。因此,为了防止单个时间分区内时间线高基数的问题,在步骤602中,可已创建的时间分区中待存储时序数据的时间戳对应的时间分区的数据特征。其中,时间分区的数据特征是指可反映时间分区的数据量大小的特征,可包括:时间分区包含的时间线的数量和数据点数量。其中,关于时间线和数据点的释义,可参见上述实施例的相关内容,在此不再赘述。
[0067]
进一步,在步骤603中,可根据已创建的时间分区中待存储时序数据的时间戳对应的时间分区的数据特征,确定目标时间窗口。在本技术各实施例中,时间窗口均是指时间窗口的大小。例如,时间窗口可为1小时、1天、一周等。其中,目标时间窗口为待创建的时间分区的时间窗口,该时间窗口的大小可根据已创建的时间分区中待存储时序数据的时间戳对应的时间分区的数据特征自适应调整。
[0068]
进一步,在步骤604中,可根据待存储时序数据的时间戳,创建具有目标时间窗口的时间分区。为了便于描述和区分,在本技术实施例中,将根据已创建的时间分区存在的待
存储时序数据的时间戳对应的时间分区,定义为第一时间分区;并将创建处的具有目标时间窗口的时间分区,定义为第二时间分区。进一步,在步骤605中,可将待存储时序数据存储于第二时间分区。
[0069]
在本实施例中,一方面,可将待存储数据存储于新创建出的第二时间分区,而非直接存储于待存储时序数据的时间戳对应的第一时间分区,有助于降低第一时间分区出现时间线高基数的问题;另一方面,由于待存储时序数据的时间戳对应的第一时间分区的数据特征,在一定程度上可反映第一时间分区对应的时间范围内的时序数据的时间线基数,因此,根据第一时间分区的数据特征,自适应调整第二时间分区的时间窗口,使得第二时间分区的时间窗口随数据特征弹性伸缩,可降低第二时间分区出现时间线高基数的问题。这样,由于每个时间分区均不存在时间线高基数问题,每个时间分区的索引较少,因此在时序数据查询时,针对每个时间分区进行索引查询效率较高。
[0070]
在本技术实施例中,不限定时间分区的数据特征的具体实现形式。在一些实施例中,时间分区存储的时序数据的数据特征,可以时间分区存储的时序数据包含的时间线数量和数据点数量进行表征。其中,时间线数量越多,说明时间线基数越高,时间分区的数据量越大;数据点数量越多,说明时间分区的数据量越大。相应地,在获取待存储时序数据的时间戳对应的第一时间分区的数据特征时,可获取第一时间分区存储的时序数据包含的时间线数量和数据点数量,作为第一时间分区存储的时序数据的数据特征。相应地,可根据第一时间分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口。
[0071]
在本技术实施例中,可预设一个时间分区最多可包含的时间线数量(maxseries),即时间线数量上限。其中,时间线数量上限可根据实际查询效率需求进行灵活设定。若一个时间分区包含的时间线数量大于时间线数量上限(maxseries),说明该时间分区存在时间线高基数问题。当然,还可预设一个时间分区最少包含的数据点数量(minpoints),即数据点数量下限。若一个时间分区包含的数据点数量小于该数据点数量下限(minpoints),说明该时间分区存储的数据量过少,时序数据存储比较分散。在时序数据查询时,由于时序数据存储比较分散,会导致数据查询耗时较长。
[0072]
在本技术实施例中,数据点数量下限可由时间线数量上限(maxseries)和设定的一个时间分区最少包含的数据点系数(minpointindex)确定。其中,最少包含的数据点系数(minpointindex)数据点系数是指一条数据线最少包含的数据点数量。相应地,一个时间分区的数据点数量下限(minpoints)可等于时间线数量上限(maxseries)和一个时间分区最少包含的数据点系数(minpointindex)的乘积,即minpoints=maxiseries*minpointindex。
[0073]
为了防止单个时间分区时间线基数过高问题,并防止由于时间分区数据量过少导致查询效率低的问题,基于上述一个时间分区对应的时间线数量上限和数据点数量下限,在根据待存储数据的时间戳对应的第一时间分区存储的时序数据包含的时间线数量和数据点数量时,可判断第一时间分区存储的时序数据包含的时间线数量是否小于或等于设定的时间线数量上限;并判断第一时间分区存储的时序数据包含的数据点数量是否小于或等于设定的数据点数量下限。其中,第一时间分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,说明第一时间分区不存在时间线高基数问题。第一时间分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,说明第一时间分区
的数据量较少。因此,若判断结果为:第一时间分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,和/或,第一时间分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,可适当增大第二时间分区的时间窗口。相应地,可增大第一时间分区的时间窗口,作为目标时间窗口。例如,在以天为时间颗粒度时,可将第一时间分区的时间窗口增加1天,作为目标时间窗口等等。
[0074]
第一时间分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,说明第一时间分区存储的数据量满足要求,第一时间分区存储的时序数据存储比较集中,在时序数据检索时,在一定程度上不存在由于时序数据存储分散导致的检索效率低的问题。而第一时间分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,说明第一时间分区的时间线数量较多,若第二时间分区还是使用第一时间分区的时间窗口,第二时间分区也会出现时间线高基数问题。基于此,若判断结果为:第一时间分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,且第一时间分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,可缩小第一时间分区的时间窗口,作为目标时间窗口。例如,对于以天为时间颗粒度的情况,可将第一时间分区的时间窗口缩小1天,作为目标时间窗口等等。
[0075]
在本技术实施例中,为了防止一个时间分区的数据量过大,对于一个时间分区可设置多个子分区,每个子分区用于存储该时间分区对应时间范围内的部分时序数据。多个是指2个或2个以上。时间分区的子分区与时间分区可具有相同的时间窗口,也可具有相同的分区标识。一个时间分区下的多个子分区具有相同的时间窗口和相同的时间标识,以子分区标识进行区分。其中,子分区标识可以该子分区为该时间分区下的第几个子分区的顺序对应的编号等。可以分区标识 子分区标识表示唯一一个子分区。例如,假设时间分区的分区标识为:123-7,该时间分区的时间窗口为7天,partitionid为123。对于标识为:123-7-2的子分区,表示标识为123-7的时间分区的第2个子分区。
[0076]
基于上述时间分区对应的子分区,待存储时序数据的时间戳对应的第一时间分区已存在至少一个子分区。在根据待存储时序数据的时间戳对应的第一时间分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口时,可根据第一时间分区包含的至少一个子分区中创建最晚的子分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口。为了便于描述,将第一时间分区包含的至少一个子分区中创建最晚的子分区,定义为第一子分区。
[0077]
针对时间分区对应的子分区,也可设置一个子分区最多可包含的时间线数量(maxseries),即时间线数量上限。当然,还可预设一个子分区最少包含的数据点数量(minpoints),即数据点数量下限。其中,关于时间线数量上限和数据点数量下限的描述,可参见上述实施例的相关内容,在此不再赘述。
[0078]
基于子分区的时间线数量上限和数据点数量下限,在根据至少一个子分区中创建最晚的第一子分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口时,可判断第一子分区存储的时序数据包含的时间线数量是否小于或等于设定的时间线数量上限;并判断第一子分区存储的时序数据包含的数据点数量是否小于或等于设定的数据点数量下限。
[0079]
其中,第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数
量上限,说明第一子分区不存在时间线高基数问题。第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,说明第一时间分区的数据量较少。因此,在一些实施例中,若判断结果为:第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,和/或,第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,可适当增大第二时间分区的时间窗口。相应地,可增大第一子分区的时间窗口,作为目标时间窗口。
[0080]
可选地,可在第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,且第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限的情况下,可增大第一子分区的时间窗口,作为目标时间窗口。
[0081]
在另一些实施例中,考虑到单个子分区的时间线数量和数据点数量无法准确反映时间分区的时间范围内的数据特征,为了提高时间窗口调整的准确度,在第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,且第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限的情况下,可采用时间分区下的多个连续的子分区包含的时间线数量之和(sumseries)和数据点数量之和(sumpoints),判断是否需要调整时间分区的时间窗口。具体地,针对待存储时序数据的时间戳对应的第一时间分区,可从第一时间分区中,获取多个子分区。多个是指2个或2个以上。例如,可根据第一时间分区包含的子分区的创建时间从晚到早的顺序,依次从第一时间分区包含的子分区中获取多个子分区。例如,多个为2个,从第一时间分区的子分区中,获取创建最晚的两个连续子分区。两个连续子分区包括:上述第一子分区及与第一子分区的创建时间间隔最近的另一子分区。
[0082]
进一步,可确定多个子分区存储的时序数据包含的时间线数量之和(sumseries),及多个子分区存储的时序数据包含的数据点数量之和(sumpoints)。进一步,可判断多个子分区存储的时序数据包含的时间线数量之和(sumseries),是否小于或等于设定的时间线数量上限;并判断多个子分区存储的时序数据包含的数据点数量之和(sumpoints),是否小于或等于设定的数据点数量下限。
[0083]
其中,多个子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,说明多个子分区不存在时间线高基数问题。多个子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,说明多个子分区的数据量较少。因此,若在这种情况下,第二时间分区的时间窗口依然保持第一子分区的时间窗口,可能导致时序数据分区存储过于离散,造成后续时序数据检索需要跨多个分区,导致检索效率低。因此,若判断结果为:多个子分区存储的时序数据包含的时间线数量之和小于或等于设定的时间线数量上限,和/或,多个子分区存储的时序数据包含的数据点数量之和小于或等于设定的数据点数量下限,可适当增大第二时间分区的时间窗口。相应地,可增大第一子分区的时间窗口,作为目标时间窗口。例如,第一子分区的时间窗口为7天,可将时间窗口增大1天,即以8天作为目标时间窗口。
[0084]
在本技术实施例中,为了防止时间窗口无限制的增大,还可设置最大时间窗口。其中,最大时间窗口可根据实际应用需求进行灵活设置。例如,可设置最大时间窗口为1周、1个月、2个月等等。在上述实施例中,增大第一子分区的时间窗口得到目标时间窗口的实施例中,还可判断第一子分区的时间窗口是否大于或等于最大时间窗口,若第一子分区的时
间窗口小于最大时间窗口,则增大第一子分区的时间窗口,得到目标时间窗口。若第一子分区的时间窗口大于或等于最大时间窗口,则以第一子分区的时间窗口为待创建的第二时间分区的目标时间窗口。
[0085]
进一步,可根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区。具体地,可根据待存储时序数据的时间戳,确定第二时间分区的起始时间。在一些实施例中,可以待存储时序数据的时间戳为第二时间分区的起始时间。或者,也可将待存储时序数据的时间戳精确到设定的时间精度,得到第二时间分区的起始时间。例如,设定的时间精度为秒;待存储时序数据的时间戳精确到微秒,则可将待存储时序数据的时间戳精确到秒,作为第二时间分区的起始时间等等。在确定出第二时间分区的起始时间之后,可创建以确定出的起始时间到起始时间 上述目标时间窗口(即增大后的时间窗口)为时间范围,以上述目标时间窗口为时间窗口的第二时间分区。在确定出第二时间分区之后,可将待存储时序数据存储于第二时间分区。
[0086]
在本技术实施例中,如图7所示,时间分区中存储的时序数据需要持久化存储至计算机存储介质中。其中,计算机存储介质可为软盘、光盘、dvd、磁盘、硬盘、闪存、u盘、cf卡、sd卡、mmc卡、sm卡、记忆棒(memory stick)、xd卡等。图7仅以存储介质为磁盘进行图示,但不构成现代。因此,需要对时间分区在存储介质上存储的目录进行命名。在本实施例中,一个时间分区对应一个分区目录;时间分区中的子分区以子分区标识进行表示。例如,时间分区的分区目录可表示为:partitionid_interval_level(分区标识-时间窗口-子分区编号)。
[0087]
相应地,对于第二时间分区,可根据待存储时序数据的时间戳和目标时间窗口,确定第二时间分区的分区标识。具体确定过程可参见确定待存储时序数据对应的目标分区标识的实施方式,在此不再赘述。
[0088]
进一步,可确定用于表征第二时间分区的分区标识和时间窗口的分区目录名,作为第二时间分区的分区目录名;并存储第二时间分区的分区目录名。这样,在时序数据查询时,可根据时间分区的分区目录名中的分区标识和时间窗口,确定时间分区的时间范围;并根据查询请求包含的查询时间范围,确定满足查询时间范围的时间分区。另一方面,将时间分区的时间窗口写入分区目录名,可记录时间分区的时间窗口,在动态调整时间分区的时间窗口时,可方便的获取当前记录的时间窗口。
[0089]
当然,对于上述新创建的第二时间分区,可将其作为第二时间分区的第一个子分区。相应地,可确定用于表征第二时间分区的分区标识、时间窗口和子分区标识的分区目录名,作为第二时间分区的分区目录名。例如,第二时间分区的分区目录名可为123_7_0。
[0090]
在本技术实施例中,为了增加分区目录名的可读性,降低运维复杂度,可对分区标识partitionid进行日期格式化。例如,假设时间戳为时间戳timestamp=1629820800;该时间戳精度为秒,且假设该时间戳对应的日期为2021年8月25日00点00分00秒,时间分区的时间窗口interval=86400秒,即1天,则时间分区标识partitionid=1629820800/86400=18863。
[0091]
若不对分区标识和时间窗口进行格式化,则分区目录名为:18863_86400_0_1,这样不仅可读性较差,而且分区目录名较长。使用日值格式化之后的路径名为:20210825_1_0_1,其中,将18863格式化为20210825,将86400格式化为1,即天粒度。这样不但的减少了分
区名长度,而且可读性较好,包含了足够有效信息。
[0092]
在本技术实施例中,可利用存储引擎将待存储时序数据持久化存储至第二时间分区对应的存储空间。由于不同版本的存储引擎存储数据的数据结构不同,存储引擎无法支持其它存储引擎存储的时序数据的处理。因此,为了便于时序数据查询,还可在时间分区的分区目录名中写入存储引擎的版本号。例如,时间分区的分区目录可表示为:partitionid_interval_level_version(分区标识-时间窗口-子分区编号-版本号)。
[0093]
其中,版本号(version)表示存储待存储时序数据的存储引擎的版本号。这样,在时序数据查询时,可利用时间分区的分区目录名中的版本号,确定存储该时间分区的时序数据的目标存储引擎;并利用该目标存储引擎,对满足查询条件的目标时序数据进行处理,以得到查询结果。
[0094]
在另一实施例中,在第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,和/或,第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限的情况下,多个子分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,说明多个子分区存储的数据量满足要求,多个子分区存储的时序数据存储比较集中,在时序数据检索时,在一定程度上不存在由于时序数据存储分散导致的检索效率低的问题。多个子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,说明多个子分区的时间线数量较多。而第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,说明第一子分区不存在时间线高基数问题。第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,说明第一时间分区的数据量较少。基于此,在第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,和/或,第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限的情况下,若判断结果为:多个子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,且第一子分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,可将待存储时序数据存储至第一子分区。
[0095]
对于上述第一子分区存储的时序数据包含的数据点数量,大于设定的数据点数量下限,说明第一子分区存储的数据量满足要求,第一子分区存储的时序数据存储比较集中,在时序数据检索时,在一定程度上不存在由于时序数据存储分散导致的检索效率低的问题。而第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,说明第一子分区的时间线数量较多,若第二时间分区还是使用第一子分区的时间窗口,第一子分区也会出现时间线高基数问题。基于此,若判断结果为:第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,且第一子分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,可缩小第一子分区的时间窗口,作为目标时间窗口。例如,对于以天为时间颗粒度的情况,可将第一子分区的时间窗口缩小1天,作为目标时间窗口等等。
[0096]
进一步,可根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区。其中,关于创建第二时间分区的具体实施方式,可参见上述实施例的相关内容,在此不再赘述。
[0097]
在一些实施例中,为了防止频繁调整时间分区的时间窗口而影响系统性能,在第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,且第一子分区存
储的时序数据包含的数据点数量大于设定的数据点数量下限的情况下,还可不调整时间窗口大小,而是在第一时间分区创建一新的子分区。在本技术实施例中,为了便于描述和区分,将新创建的子分区定义为第二子分区。
[0098]
为了防止同一时间分区存储的时序数据的数据量过大,针对时间分区可预设包含的子分区数量上限。一个时间分区包含的子分区的数量不宜超过设定的子分区数量上限。在本技术实施例中,不限定一个时间分区包含的子分区数量上限的具体取值,可根据实际需求进行灵活设置。其中,子分区数量上限为大于或等于2的整数。例如,子分区数量上限可为3、4、5等等。
[0099]
为了兼顾系统性能和时间分区的数据量大小,在第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,且第一子分区存储的时序数据包含的数据点数量大于设定的数据点数量下限的情况下,可判断第一时间分区下已建立的子分区的数量是否大于或等于设定的子分区数量上限;若判断结果为是,可缩小第一子分区的时间窗口,作为目标时间窗口。例如,对于以天为时间颗粒度的情况,可将第一子分区的时间窗口缩小1天,作为目标时间窗口等等。
[0100]
进一步,可根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区。其中,关于创建第二时间分区的具体实施方式,可参见上述实施例的相关内容,在此不再赘述。关于对第二时间分区的分区目录进行命名的实施方式,也可参见上述实施例的相关内容,在此不再赘述。
[0101]
相应地,若判断结果为第一时间分区下已建立的子分区的数量小于设定的子分区数量上限,可保持时间窗口不变,创建第一时间分区下的另一子分区(即上述第二子分区)。具体地,可确定第一子分区的时间窗口为目标时间窗口。之后,可根据待存储数据的时间戳,在第一时间分区下创建具有目标时间窗口的第二子分区,作为第二时间分区。
[0102]
具体地,可根据待存储时序数据的时间戳,确定第二时间分区的起始时间;并根据所述第二时间分区的起始时间和第一子分区的时间窗口,创建第一时间分区的第二子分区,作为第二时间分区。进一步,可将待存储数据存储至第二子分区。
[0103]
对于时间分区下的子分区,每个子分区也对应一个分区目录名。在本实施例中,一个时间分区对应一个分区目录;时间分区中的子分区以子分区标识进行表示。例如,子分区的分区目录可表示为:partitionid_interval_level(分区标识-时间窗口-子分区编号)。
[0104]
相应地,对于第二子分区,可确定第二子分区的分区标识为第一时间分区的分区标识;并根据第一时间分区对应的子分区数量,确定第二子分区的子分区标识。其中,第二子分区的子分区标识可为第二子分区在第一时间分区中的顺序编号。进一步,可确定用于表征第二子分区的分区标识、时间窗口及子分区标识的分区目录名,作为第二子分区的分区目录名;并存储第二子分区的分区目录名。当然,对于上述新创建的第二时间分区,可将其作为第二时间分区的第一个子分区。
[0105]
在本技术实施例中,可利用存储引擎将待存储时序数据持久化存储至第二子分区对应的存储空间。因此,为了便于时序数据查询,还可在子分区的分区目录名中写入存储引擎的版本号。例如,子分区的分区目录可表示为:partitionid_interval_level_version(分区标识-时间窗口-子分区编号-版本号)。其中,关于版本号的作用可参见上述实施例的相关内容,在此不再赘述。
[0106]
在本技术实施例中,对于上述第一子分区存储的时序数据包含的数据点数量,大于设定的数据点数量下限,但第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限的情况,说明第一子分区存储的数据量满足要求,第一子分区存储的时序数据存储比较集中,在时序数据检索时,在一定程度上不存在由于时序数据存储分散导致的检索效率低的问题;而第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,说明第一子分区尚不存在时间线高基数问题。为了防止频繁创建新的时间分区或子分区,影响系统性能,在上述情况下,可将待存储时序数据存储至第一子分区。
[0107]
基于相同的原因,对于上述第一子分区存储的时序数据包含的数据点数量,小于或等于设定的数据点数量下限,但第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限的情况,也可将待存储时序数据存储至第一子分区。
[0108]
在本技术实施例中,对于已创建的时间分区不存在待存储时序数据的时间戳对应的时间分区的实施例,可根据当前记录的时间窗口和待存储时序数据的时间戳,创建另一时间分区。在本技术实施例中,为了便于描述和区分,已创建的时间分区不存在待存储时序数据的时间戳对应的时间分区的情况下,创建的时间分区定义为第三时间分区。其中,关于创建第三时间分区的具体实施方式,可参见上述创建第二时间分区的相关内容,在此不再赘述。
[0109]
对于第三时间分区也可设置时间分区对应的分区目录名,具体设置过程可参见上述第二时间分区设置分区目录名的相关内容,在此不再赘述。
[0110]
为了便于理解上述根据第一时间分区存储的时序数据的数据特征,确定目标窗口的具体实施方式,下面以第一时间分区包含子分区为例并结合图8进行示例性说明。
[0111]
图8为本技术实施例提供的数据存储方法的详细流程示意图。如图8所示,该方法主要包括以下步骤:
[0112]
s1、获取待存储时序数据。
[0113]
s2、根据待存储时序数据的时间戳和当前记录的时间窗口,确定待存储时序数据对应的目标分区标识。
[0114]
s3、判断已创建的时间分区是否存在目标分区标识对应的第一时间分区。若判断结果为是,执行步骤s4;并判断结果为否,执行步骤s22。
[0115]
s4、获取第一时间分区中创建最晚的第一子分区存储的时序数据包含的时间线数量和数据点数量,作为第一子分区存储的时序数据的数据特征。
[0116]
s5、判断第一子分区存储的时序数据包含的时间线数量是否小于或等于设定的时间线数量上限;并判断第一子分区存储的时序数据包含的数据点数量是否小于或等于设定的数据点数量下限。若判断结果均为是,执行步骤s6;若判断结果均为否的情况,执行步骤s15;否则,执行步骤s14,即判断结果一是一否,执行步骤14。
[0117]
s6、根据第一时间分区的子分区的创建时间从晚到早的顺序,获取连续的多个子分区。
[0118]
s7、确定多个子分区存储的时序数据包含的时间线数量之和及多个子分区存储的时序数据包含的数据点数量之和。
[0119]
s8、判断时间线数量之和是否小于或等于所述时间线数量上限;并判断数据点数
量之和是否小于或等于数据点数量下限。若判断结果存在为是的情况,执行步骤s9;若判断结果均为否,执行步骤s14。
[0120]
s9、判断当前记录的时间窗口是否小于设定的最大时间窗口。若判断结果为是,执行步骤s10;若判断结果为否,执行步骤s11。
[0121]
在本实施例中,当前记录的时间窗口可为上述第一子分区的时间窗口。
[0122]
s10、增大当前记录的时间窗口,作为目标时间窗口;并继续执行步骤s12。
[0123]
s11、确定当前记录的时间窗口为目标时间窗口;并继续执行步骤s12。
[0124]
s12、根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区。
[0125]
s13、将待存储时序数据存储至第二时间分区。
[0126]
s14、将待存储时序数据存储至第一子分区。
[0127]
s15、判断第一时间分区下已创建的子分区的数量是否大于或等于设定的子分区数量上限。若判断结果为是,执行步骤s16;若判断结果为否,执行步骤s19。
[0128]
s16、判断当前记录的时间窗口是否大于设定的最小时间窗口。若判断结果为是,执行步骤s17;若判断结果为否,执行步骤s18。
[0129]
s17、缩小当前记录的时间窗口作为目标时间窗口;并继续执行步骤s12。
[0130]
s18、确定当前记录的时间窗口为目标时间窗口;并继续执行步骤s12。
[0131]
s19、确定第一子分区的时间窗口为目标时间窗口。
[0132]
s20、根据待存储时序数据的时间戳和第一子分区的时间窗口,创建第一时间分区的第二子分区,作为第二时间分区。
[0133]
s21、将待存储数据存储至第二子分区。
[0134]
s22、根据当前记录的时间窗口和所述待存储时序数据的时间戳,创建第三时间分区。
[0135]
s23、将待存储时序数据存储于第三时间分区。
[0136]
除了上述实施例提供的数据存储方法之外,本技术实施例还提供数据查询方法。下面对本技术实施例提供的数据查询方法进行示例性说明。
[0137]
图9为本技术实施例提供的数据查询方法的流程示意图。如图9所示,数据查询方法包括:
[0138]
901、获取查询请求。
[0139]
902、从查询请求中,获取待查询的时间范围和查询条件。
[0140]
在本实施例中,查询条件是指实际度量数据的查询条件。
[0141]
903、根据待查询的时间范围,从时间分区中确定时间范围与待查询的时间范围重叠的目标时间分区。
[0142]
904、从目标时间分区存储的时序数据中,获取满足上述查询条件的目标时序数据。
[0143]
905、基于目标时序数据,确定查询请求的查询结果。
[0144]
在本实施例中,在从时间分区中确定时间范围与待查询的时间范围重叠的目标时间分区时,可从时间分区对应的分区目录名中获取分区标识和时间窗口;进一步,可根据分区标识和时间窗口,确定该时间分区的时间范围。之后,可将待查询的时间范围在时间分区的时间范围中进行匹配,以得到时间范围与待查询的时间范围重叠的目标时间分区。
[0145]
进一步,可从目标时间分区存储的时序数据中,获取满足上述查询条件的目标时序数据。之后,基于基于目标时序数据,确定查询请求的查询结果。可选地,可按照目标时序数据的时间戳从小到大的顺序,对目标时序数据进行合并,得到查询结果。
[0146]
在一些实施例中,还可从目标时间分区的分区目录名中获取存储目标时序数据的存储引擎的目标版本号。进一步,可利用目标版本号对应的存储引擎对目标时序数据进行处理,以得到查询结果。
[0147]
需要说明的是,上述实施例所提供方法的各步骤的执行主体均可以是同一设备,或者,该方法也由不同设备作为执行主体。比如,步骤601和602的执行主体可以为设备a;又比如,步骤601的执行主体可以为设备a,步骤602的执行主体可以为设备b;等等。
[0148]
另外,在上述实施例及附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如601、602等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。
[0149]
相应地,本技术实施例还提供一种存储有计算机指令的计算机可读存储介质,当计算机指令被一个或多个处理器执行时,致使一个或多个处理器执行上述数据存储方法和/或数据查询方法中的步骤。
[0150]
本技术实施例还提供一种计算机程序产品,包括计算机程序。当计算机程序被处理器执行时,致使一个或多个处理器执行上述数据存储方法和/或数据查询方法中的步骤。在本技术实施例中,不限定计算机程序产品的实现形态。在一些实施例中,计算机程序产品可实现为数据库管理软件等,但不限于此。
[0151]
图10为本技术实施例提供的计算设备的结构示意图。如图10所示,该计算设备包括:存储器100a和处理器100b;其中,存储器100a,用于存储计算机程序。存储器100a创建有时间分区;
[0152]
处理器100b耦合至存储器100a,用于执行计算机程序以用于:获取待存储时序数据;在已创建的时间分区存在待存储时序数据的时间戳对应的第一时间分区的情况下,获取第一时间分区存储的时序数据的数据特征;根据第一时间分区存储的时序数据的数据特征,确定目标时间窗口;根据待存储时序数据的时间戳,创建具有目标时间窗口的第二时间分区;并将待存储时序数据存储于第二时间分区。
[0153]
在一些实施例中,处理器100a还用于:根据待存储时序数据的时间戳和当前记录的时间窗口,确定待存储时序数据对应的目标分区标识;将目标分区标识在已创建的时间分区的分区标识中进行查找;若在已创建的时间分区的分区标识中查找到目标分区标识,确定存在第一时间分区。
[0154]
进一步,处理器100b还用于:在已创建的时间分区不存在第一时间分区的情况下,根据当前记录的时间窗口和待存储时序数据的时间戳,创建第三时间分区;并将待存储时序数据存储于第三时间分区。
[0155]
在一些实施例中,处理器100b在获取第一时间分区存储的时序数据的数据特征时,具体用于:获取第一时间分区存储的时序数据包含的时间线数量和数据点数量,作为第一时间分区存储的时序数据的数据特征。相应地,处理器100b在确定目标时间窗口时,具体
用于:根据第一时间分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口;其中,时序数据中同一对象的一个指标随时间变化产生的一系列数据为一条时间线;每条时间线中的一个指标值为一个数据点。
[0156]
可选地,第一时间分区包括至少一个子分区;至少一个子分区的时间窗口相同。相应地,处理器100b在确定目标时间窗口时,具体用于:根据至少一个子分区中创建最晚的第一子分区存储的时序数据包含的时间线数量和数据点数量,确定目标时间窗口。
[0157]
可选地,处理器100b在确定目标时间窗口,包括执行以下至少一种判断操作:
[0158]
判断第一子分区存储的时序数据包含的时间线数量是否小于或等于设定的时间线数量上限;
[0159]
判断第一子分区存储的时序数据包含的数据点数量是否小于或等于设定的数据点数量下限;
[0160]
若至少一种判断操作的判断结果均为否,在至少一个子分区的数量大于或等于设定的子分区数量上限的情况下,缩小第一子分区的时间窗口,以得到目标时间窗口。若至少一种判断操作的判断结果均为否,在至少一个子分区数量小于设定的子分区数量上限的情况下,确定第一子分区的时间窗口为目标时间窗口。
[0161]
相应地,处理器100b在创建具有目标时间窗口的第二时间分区时,具体用于:根据待存储时序数据的时间戳,确定第二时间分区的起始时间;根据第二时间分区的起始时间和第一子分区的时间窗口,创建第一时间分区的第二子分区,作为第二时间分区。
[0162]
可选地,处理器100b还用于:确定第二子分区的分区标识为第一时间分区的分区标识;根据第一时间分区对应的子分区数量,确定第二子分区的子分区标识;确定用于表征第二子分区的分区标识、时间窗口及子分区标识的第二分区目录名,为第二子分区的分区目录名;存储第二分区目录名。
[0163]
在一些实施例中,处理器100b还用于:若至少一种判断操作的判断结果均为是,从第一时间分区中,获取多个子分区;确定多个子分区存储的时序数据包含的时间线数量之和及多个子分区存储的时序数据包含的数据点数量之和;若时间线数量之和小于或等于时间线数量上限,和/或,数据点数量之和小于或等于数据点数量下限,增大第一子分区的时间窗口,作为目标时间窗口。若时间线数量之和大于设定的时间线数量和上限,且数据点数量之和大于设定的数据点数量和下限,将待存储时序数据存储于第一子分区。
[0164]
可选地,处理器100b还用于:若第一子分区存储的时序数据包含的时间线数量小于或等于设定的时间线数量上限,第一子分区存储的时序数据包含的数据点数量大于设定的数据点数量下限,将待存储时序数据存储于第一子分区。或者,若第一子分区存储的时序数据包含的时间线数量大于设定的时间线数量上限,第一子分区存储的时序数据包含的数据点数量小于或等于设定的数据点数量下限,将待存储时序数据存储于第一子分区。
[0165]
在一些实施例中,处理器100b在创建具有目标时间窗口的第二时间分区时,具体用于:根据待存储时序数据的时间戳,确定第二时间分区的起始时间;根据第二时间分区的起始时间,创建具有目标时间窗口的第二时间分区。
[0166]
可选地,处理器100b还用于:根据待存储时序数据的时间戳和目标时间窗口,确定第二时间分区的分区标识;确定用于表征第二时间分区对应的分区标识和时间窗口的第一分区目录名,为第二时间分区的分区目录名;存储第一分区目录名。
[0167]
可选地,处理器100b在将待存储时序数据存储于第二时间分区时,具体用于:利用存储引擎将待存储时序数据持久化存储至第二时间分区对应的存储空间。相应地,处理器100b还用于:将存储引擎的版本号写入第一分区目录名。
[0168]
在本技术实施例中,处理器100b还用于:获取查询请求;获取满足查询请求的目标时序数据;从目标时序数据对应的分区目录名中,获取存储目标时序数据的存储引擎的目标版本号;利用目标版本号对应的存储引擎对目标时序数据进行处理,以得到查询结果。
[0169]
在本技术实施例中,不限定计算设备的具体实现形态。计算设备可实现为单一的服务器设备,也可以云化的服务器阵列,或者为云化的服务器阵列中运行的虚拟机(virtual machine,vm)。另外,计算设备也可以指具备相应服务能力的其他计算设备,例如电脑等终端设备(运行服务程序)等。
[0170]
在一些可选实施方式中,如图10所示,该计算设备还可以包括:通信组件100c、电源组件100d等组件。对于电脑等终端设备,还可包括:显示组件100e和音频组件100f等组件。图10中仅示意性给出部分组件,并不意味着计算设备必须包含图10所示全部组件,也不意味着计算设备只能包括图10所示组件。
[0171]
本实施例提供的计算设备,一方面,可将待存储数据存储于新创建出的第二时间分区,而非直接存储于待存储时序数据的时间戳对应的第一时间分区,有助于降低第一时间分区出现时间线高基数的问题;另一方面,由于待存储时序数据的时间戳对应的第一时间分区的数据特征,在一定程度上可反映第一时间分区对应的时间范围内的时序数据的时间线基数,因此,根据第一时间分区的数据特征,自适应调整第二时间分区的时间窗口,使得第二时间分区的时间窗口随数据特征弹性伸缩,可降低第二时间分区出现时间线高基数的问题。这样,由于每个时间分区均不存在时间线高基数问题,每个时间分区的索引较少,因此在时序数据查询时,针对每个时间分区进行索引查询效率较高。
[0172]
在本技术实施例中,存储器用于存储计算机程序,并可被配置为存储其它各种数据以支持在其所在设备上的操作。其中,处理器可执行存储器中存储的计算机程序,以实现相应控制逻辑。存储器可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(sram),电可擦除可编程只读存储器(eeprom),可擦除可编程只读存储器(eprom),可编程只读存储器(prom),只读存储器(rom),磁存储器,快闪存储器,磁盘或光盘。
[0173]
在本技术实施例中,处理器可以为任意可执行上述方法逻辑的硬件处理设备。可选地,处理器可以为中央处理器(central processing unit,cpu)、图形处理器(graphics processing unit,gpu)或微控制单元(microcontroller unit,mcu);也可以为现场可编程门阵列(field-programmable gate array,fpga)、可编程阵列逻辑器件(programmable array logic,pal)、通用阵列逻辑器件(general array logic,gal)、复杂可编程逻辑器件(complex programmable logic device,cpld)等可编程器件;或者为先进精简指令集(risc)处理器(advanced risc machines,arm)或系统芯片(system on chip,soc)等等,但不限于此。
[0174]
在本技术实施例中,通信组件被配置为便于其所在设备和其他设备之间有线或无线方式的通信。通信组件所在设备可以接入基于通信标准的无线网络,如wifi,2g或3g,4g,5g或它们的组合。在一个示例性实施例中,通信组件经由广播信道接收来自外部广播管理
系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件还可基于近场通信(nfc)技术、射频识别(rfid)技术、红外数据协会(irda)技术、超宽带(uwb)技术、蓝牙(bt)技术或其他技术来实现。
[0175]
在本技术实施例中,显示组件可以包括液晶显示器(lcd)和触摸面板(tp)。如果显示组件包括触摸面板,显示组件可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。
[0176]
在本技术实施例中,电源组件被配置为其所在设备的各种组件提供电力。电源组件可以包括电源管理系统,一个或多个电源,及其他与为电源组件所在设备生成、管理和分配电力相关联的组件。
[0177]
在本技术实施例中,音频组件可被配置为输出和/或输入音频信号。例如,音频组件包括一个麦克风(mic),当音频组件所在设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器或经由通信组件发送。在一些实施例中,音频组件还包括一个扬声器,用于输出音频信号。例如,对于具有语言交互功能的设备,可通过音频组件实现与用户的语音交互等。
[0178]
需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
[0179]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0180]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0181]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0182]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0183]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0184]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0185]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0186]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0187]
以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。