1.本发明涉及计算机视觉、人工智能技术领域,具体涉及一种基于视觉转化器的人群密度估计方法及系统。
背景技术:
2.在当前机器学习技术及计算机硬件性能高速提升的情况下,近年来计算机视觉、自然语言处理和语音检测等应用领域取得了突破性进展。人群密度估计作为计算机视觉领域一项基础的任务,其精度也得到了大幅提升。
3.人群密度估计任务可具体描述如下:
4.对于拍摄的图片或者录制的视频以及摄像头下的人群场景,生成密度图用以表示单位面积内人群的密度,再以该密度图为基础,将密度图中单位面积人群密度加和,得到最终整体场景的人群密度,或者是整个视频的人群密度变化。
5.人群密度估计对计算机视觉领域和实际应用具有重要意义,在过去几十年里激励大批研究人员密切关注并投入研究。随着强劲的机器学习理论和特征分析技术的发展,近十几年人群密度估计课题相关的研究活动有增无减,每年都有最新的研究成果和实际应用发表和公布。不仅如此,人群密度估计也被应用到很多实际任务,例如智能视频监控、人群态势分析等。然而,现有技术的多种人群密度估计方法的检测准确率仍然较低而不能应用于实际通用的估计任务。因此,人群密度估计还远未被完美解决,仍旧是重要的挑战性的研究课题。
6.为了提高密度估计的准确率,目前常用的方法是增加预测模型训练时的训练数据。然而,一方面,收集大量的训练数据是一件极其困难的工作,另一方面,训练数据量增多也导致模型训练时间延长,甚至有可能然后训练无法实际完成。
技术实现要素:
7.本发明是为了解决上述问题而进行的,目的在于提供一种基于视觉转化器的人群密度估计方法及系统。
8.本发明提供了一种基于视觉转化器的人群密度估计方法,具有这样的特征,包括以下步骤:步骤1,对待测图像进行预处理获得预处理图像,然后搭建编码解码层;步骤2,搭建基于视觉转化器的神经网络模型;步骤3,把训练数据输入基于视觉转化器的神经网络模型进行模型训练,得到训练完成的基于视觉转化器机制神经网络模型;步骤4,将预处理图像输入训练完成的基于视觉转化器机制神经网络模型,分别得出各个预处理图像中的人群密度结果并进行输出,其中,基于视觉转化器的神经网络模型包括前端以卷积神经网络为基础的局部信息提取模块和后端以视觉转化器为基础的全局信息提取模块。
9.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,基于视觉转化器的神经网络模型还引入多级卷积机制,每级卷积操作之后都跟着一个visual transformer提取全局联系。
10.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,待测图像为高密度人群图像。
11.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,步骤1中,预处理的步骤为:步骤1-1,从待测图像中进行图像分割;步骤1-2,将分割得到的图像进行正则化,图像分割的方法为将待测图像按照一定规模,随机选取待测图像中一点作为中心点,以一定比例切割待测图像。
12.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,步骤1中,编码解码层以vgg-16网络和visual transformer网络为基础。
13.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,步骤2中,搭建视觉转化器的神经网络模型时,在前端多级卷机层后增加visual transformer结构。
14.在本发明提供的基于视觉转化器的人群密度估计方法中,还可以具有这样的特征:其中,步骤3包括以下步骤:步骤3-1,构建基于视觉转化器神经网络模型,其包含的模型优化器为随机梯度下降,学习率为10-7
;步骤3-2,将训练集中的各个训练图像依次输入基于视觉转化器神经网络模型并进行一次迭代;步骤3-3,进行迭代后,采用最后一层的模型参数分别计算出损失误差,然后将计算得到的损失误差反向传播,从而更新模型参数;步骤3-4,重复步骤3-2~步骤3-3直至达到训练完成条件,得到训练后的基于视觉转化器神经网络模型。
15.本发明提供了一种基于视觉转化器的人群密度估计系统,具有这样的特征,包括:采用基于视觉转化器的神经网络模型从待测图像中检测出人群密度,包括:预处理部,对待测图像进行预处理获得预处理图像;密度预测部,搭建视觉转化器的神经网络模型,把训练数据输入搭建好的基于视觉转化器的神经网络模型,从而进行模型训练,将预处理图像输入训练完成的基于视觉转化器机制神经网络模型,从而得出各个预处理图像中的人群密度结果并进行输出,其中,基于视觉转化器的神经网络模型包括前端以卷积神经网络为基础的局部信息提取模块和后端以视觉转化器为基础的全局信息提取模块。
16.发明的作用与效果
17.根据本发明所涉及的基于视觉转化器的人群密度估计方法,因为估计步骤为:步骤1,对待测图像进行预处理获得预处理图像,然后搭建编码解码层;步骤2,搭建基于视觉转化器的神经网络模型;步骤3,把训练数据输入基于视觉转化器的神经网络模型进行模型训练,得到训练完成的基于视觉转化器机制神经网络模型;步骤4,将预处理图像输入训练完成的基于视觉转化器机制神经网络模型,分别得出各个预处理图像中的人群密度结果并进行输出,其中,基于视觉转化器的神经网络模型包括前端以卷积神经网络为基础的局部信息提取模块和后端以视觉转化器为基础的全局信息提取模块。
18.因此,根据本发明提供的基于视觉转化器的人群密度估计方法,由于引入了多级卷积融合网络和视觉转化器结合的神经网络模型作为预测模型,该预测模型的混合神经网络结构可以使模型更好的定位到人群和识别人群的密度,因此,此模型能够学习到更多的特征,更好地进行特征表达,更加适合高密度人群的人群密度估计任务,能够最终提高人群密度估计的精度。
19.另外,该模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法,
因此,与现有的高精度模型相比,本发明的模型构建快速方便,且训练过程所消耗的计算量也较小。
附图说明
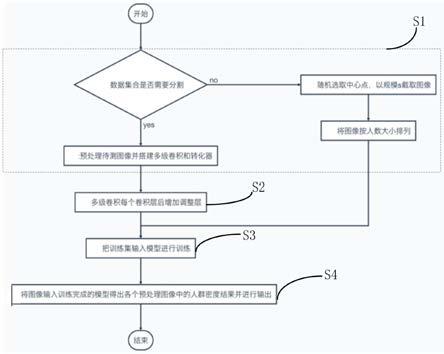
20.图1是本发明的实施例中基于视觉转化器的人群密度估计方法的流程图;
21.图2是本发明的实施例中基于视觉转化器的人群密度估计方法的结构示意图;
22.图3是本发明的实施例中视觉转化器模块的结构图;
23.图4是本发明的实施例中多级融合卷积的结构图。
具体实施方式
24.为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明一种基于视觉转化器的人群密度估计方法及系统作具体阐述。
25.在本实施例中,提供了一种基于视觉转化器的人群密度估计方法。
26.本实施例可以采用的数据集为ucf-qnrf。ucf-qnrf是一个具有挑战性的高密度场景的数据集,该数据集包含了1535张标记图片和总数为1251642个人头的标注信息,该数据集中每张图片的人数范围为49到12865,并且该数据集图片的平均分辨率为2013乘2902,是一个高分辨率的数据集。
27.本实施例还可以采用的数据集为shangehaitech。shangehaitech是一个具有挑战性的高密度场景的数据集,该数据集包含了1198张标记图片和总数为330165个人头的标注信息,这个数据集由两部分组成:a部分和b部分。a部分包括482张从互联网上随机下载的图片。列车组有300幅图像,试验组有182幅图像。b部分共有716幅无人机在上海拍摄的不同场景的图像。
28.本实施例还可以采用的数据集为ucf cc 50。ucf cc 50是一个具有挑战性的高密度场景的数据集,包含50幅极密集人群的注释图像,每个图像中注释的人数从94到4543不等,平均为1280人。另外,本实施例实现的硬件平台需要一张nvidia 1080ti显卡(gpu加速)。
29.本实施例首先对数据集图片进行预处理,然后训练基于注意力机制的卷积神经网络模型,最后通过该神经网络模型得到图片的人群密度。具体包括4个过程:预处理、搭建模型、训练模型及密度预测。
30.图1是本发明实施例中基于视觉转化器的人群密度估计方法的流程图。
31.如图1所示,本实施例所涉及的一种基于视觉转化器的人群密度估计方法包括以下步骤:
32.步骤s1,对待测图像进行预处理获得预处理图像,然后搭建编码解码层。
33.本实施例中,待测图像为从ucf-qnrf数据集中得到的图像,由于该数据集的高分比率,无法将图像直接输入到模型中,进行降采样,并选取随机中心点分割出多个子块,然后输入模型中。
34.本实施例的上述过程中,降采样是针对图像分辨率过高的措施;选取随机中心点分割出多个子块训练数据是为了增加获取的图像数量,实现数据扩充从而让从待测图像中获取的数据量更为丰富,进而增加迭代的epoch。在其他实施例中,待测图像也可以是单张
图像(例如照片等),这种情况下不需要分割操作。另外,在其他实施例中也可以不对图像进行复制,或者采用其他的现有技术中的数据扩充方式(例如垂直翻转、水平翻转与垂直翻转结合等)。
35.构建编码解码层,编码层以vgg-16前十层为基础,后四层每层由一个最大池化和两个膨胀卷积组成,每层的核大小均为3x3,膨胀系数为2,其中第三层的输出通道为512,第四层的输出通道分别为512和256,第五层的输出通道为128和64。为了调整每层的输出特征,2、3、4、5层分别连接了一个卷积层,这四个卷积层输出通道均为128。
36.步骤s2,搭建基于视觉转化器的神经网络模型。
37.首先,利用现有的深度学习框架pytorch,搭建基于视觉转化器神经网络模型。该基于视觉转化器神经网络模型是引入包括多级融合的卷积和视觉转化器结合的神经网络。
38.具体地,本实施例的模型由基于多级融合的卷积局部信息提取器和transformer的全局信息提取器组成,其中在多级融合的卷积局部信息模块中,每一个卷积层卷积操作后都跟着视觉转化器。
39.图2是本发明实施例的视觉转化器的神经网络模型的结构示意图。
40.如图2所示,本发明的视觉转化器神经网络模型包括依次设置的输入层i、基于vgg-16前端多级融和卷积层、visual transformer模块。
41.如图2所示,基于视觉提取器的神经网络模型具体包括如下结构:
42.(1)输入层i,用于输入各个经过预处理和编码的图像
43.(2)网络cnn部分的前两层使用预训练好的vgg16的前10层作为backbone,后四层每层由一个最大池化和两个膨胀卷积组成,每层的核大小均为3x3,膨胀系数为2,其中第三层的输出通道为512,第四层的输出通道分别为512和256,第五层的输出通道为128和64。为了调整每层的输出特征,2、3、4、5层分别连接了一个卷积层,这四个卷积层输出通道均为128。
44.(3)visual transformer模块:多级卷积的输出送入到该模块中。最后将所有结果合并为最终的结果图。
45.图3是本发明实施例的视觉转化器模块的结构图。
46.如图3所示,基于视觉转化器神经网络模型中,每个多级融合卷积层后都要进行通道调整操作。
47.图4是本发明实施例的多级融合卷积的结构图。
48.如图4所示,每层多级卷积后都跟着一个调整层,调整层将输出的特征图调成后端视觉转化器需要的大小和规模。
49.如图4所示,首先对输入的图像随机选取中心点截图子图像,然后将子图像和原图一起送入到模型中进行训练。
50.步骤s3,把训练数据输入基于视觉转化器的神经网络模型进行模型训练,得到训练完成的基于视觉转化器机制神经网络模型。
51.本实施例采用人群数据集ucf-qnrf作为训练数据。采用与步骤s1相同的方法,从该数据集中获得了包含1251642个人头的1535张图像;将这些图像做分割,以实现数据增强,然后再进行正则化处理,得到的多张图像即为本实施例的训练集。
52.上述训练集中的图像分批次进入网络模型进行训练,每次进入网络模型的训练图
像批次大小为1,一共迭代训练2000次。
53.其中,步骤s3包括以下步骤:
54.步骤s3-1,构建基于视觉转化器神经网络模型,其包含的模型优化器为随机梯度下降,学习率为10-7
。
55.步骤s3-2,将训练集中的各个训练图像依次入基于视觉转化器神经网络模型并进行一次迭代。
56.步骤s3-3,进行迭代后,采用最后一层的模型参数分别计算出损失误差,然后将计算得到的损失误差反向传播,从而更新模型参数。
57.步骤s3-4,重复步骤s3-2~步骤s3-3直至达到训练完成条件,得到训练后的基于视觉转化器神经网络模型。
58.步骤s4,将预处理图像输入训练完成的基于视觉转化器机制神经网络模型,分别得出各个预处理图像中的人群密度结果并进行输出,
59.其中,基于视觉转化器的神经网络模型包括前端以卷积神经网络为基础的局部信息提取模块和后端以视觉转化器为基础的全局信息提取模块。
60.本实施例中采用ucf-qnrf测试集作为待测图像来对本实施例的模型进行测试,其中场景就是高密度人群场景。
61.具体过程为:利用ucf-qnrf数据集,对其数据集中的多个图像进行如步骤s1所描述的预处理,得到334张图像(即预处理后的预处理图像)作为测试集,依次输入训练好的基于注意力机制的卷积神经网络模型,生成对应的密度图并计算得到人群密度结果。
62.本实施例中,训练好的基于视觉转化器的神经网络模型对该测试集的人群密度估计生成的平均绝对误差(mae)为99.7,均方误差(mse)为172.3。
63.本实施例中还采用现有技术中的其他人群密度估计模型对同样的测试集进行了对比测试,结果如下表1所示。
64.表1为本实施例的方法以及现有技术的其他方法在ucf-qnrf数据集上人群密度估计的对比测试结果。
65.表1
[0066][0067]
表1中,mcnn、cp-cnn、tdf-cnn、ic-cnn、d-convnet、csrnet为现有技术中常见人群密度估计准确率较高的几种模型。另外,mae代表平均绝对误差,mse代表均方误差。
[0068]
上述测试过程表明,本实施例的基于视觉转化器神经网络模型的人群密度估计方法能够在ucf-qnrf数据集上取得很高的准确率。
[0069]
本实施例中还提供了一种基于视觉转化器的人群密度估计系统,采用基于视觉转
化器的神经网络模型从待测图像中检测出人群密度,包括:
[0070]
预处理部,利用本实施例中步骤s1中的方法进行预处理。
[0071]
密度预测部,利用本实施例中步骤s1~步骤s4中的方法进行密度预测,得到预测结果。
[0072]
实施例的作用与效果
[0073]
根据本实施例所涉及的基于视觉转化器的人群密度估计方法及系统,因为,步骤1,对待测图像进行预处理获得预处理图像,然后搭建编码解码层;步骤2,搭建基于视觉转化器的神经网络模型;步骤3,把训练数据输入基于视觉转化器的神经网络模型进行模型训练,得到训练完成的基于视觉转化器机制神经网络模型;步骤4,将预处理图像输入训练完成的基于视觉转化器机制神经网络模型,分别得出各个预处理图像中的人群密度结果并进行输出,其中,基于视觉转化器的神经网络模型包括前端以卷积神经网络为基础的局部信息提取模块和后端以视觉转化器为基础的全局信息提取模块。
[0074]
因此,根据上述实施例提供的基于视觉转化器的人群密度估计方法及系统,由于引入了多级卷积融合网络和视觉转化器结合的神经网络模型作为预测模型,该预测模型的混合神经网络结构可以使模型更好的定位到人群和识别人群的密度,因此,此模型能够学习到更多的特征,更好地进行特征表达,更加适合高密度人群的人群密度估计任务,能够最终提高人群密度估计的精度。
[0075]
另外,该模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法,因此,与现有的高精度模型相比,上述实施例的模型构建快速方便,且训练过程所消耗的计算量也较小。
[0076]
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。