1.本发明涉及计算机数据分析领域,特别是涉及一种公司名称匹配方法。
背景技术:
2.对于b2b商业模式的公司,所对应的客户也就是公司,而进行客户分析的前提便是客户的基本属性。公司的基本数据往往是利用公司名称作为主键作为关联匹配,所以能够有效处理公司名称匹配带来的问题,对于b2b商业模式的公司是一条重要些必须要克服的问题。公司名称数据信息不准确,数据错误,数据模糊的问题来源多种多样,有些是销售人员手工录入存在同音字问题,数据存入业务库含有特殊字符,输入法全角半角问题,公司名称简化录入等问题。都对公司名称的匹配产生了重大影响,因此如何处理对于后续的分析及挖掘尤为重要。
3.匹配本质还是一种数据加工技术,它能为客户管理业务提供多种维度的拓展数据。如何在大数据时代面对大量的数据能够很快的得到匹配结果并有效利用这些数据来提升业务能力,直接决定了匹配的用途和价值。
4.现有技术中已有通过形式化公司名称(rxio)进行匹配的一些案例,但在实际应用中,尤其是在b2b领域中,尤其是在面对庞大的数据量时,仍运行的十分吃力,效率达不到预期,如不加以改进,则难以实际部署使用。
5.因此,需要一种性能更优越更适用的的公司名称匹配方法。
技术实现要素:
6.本发明所要解决的技术问题是克服现有技术的不足,提供一种公司名称匹配方法,主要针对大数据体系中公司名称数据不标准、数据错误、数据模糊的情况提供了相应的处理方法,提高匹配度和数据利用度。
7.为解决上述技术问题,本发明提供一种公司名称匹配方法,其特征在于,包括如下步骤:
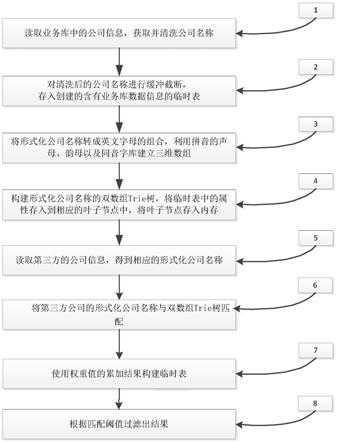
8.步骤一,读取业务库中的公司信息,获取并清洗公司名称;
9.步骤二,对清洗后的公司名称进行缓冲截断,用以获得形式化公司名称,存入创建的含有业务库数据信息的临时表;
10.步骤三,将形式化公司名称转成英文字母的组合,利用拼音的声母、韵母以及同音字库建立三维数组,用以表达形式化公司名称;
11.步骤四,构建形式化公司名称的双数组trie树,将临时表中的属性存入到相应的叶子节点中,将叶子节点存入内存;
12.步骤五:读取第三方的公司信息,按照步骤一到步骤四处理,得到相应的形式化公司名称;
13.步骤六:将第三方公司的形式化公司名称与双数组trie树匹配,设置双数组trie树中的每个类别的权重,一个类别双数组trie树匹配完成,则将结果作为一条数据行并跳
出,并在内部累加权重值后进入下一个类别的双数组trie树,当全部类别双数组trie树匹配结束,开始下一条公司信息的匹配;
14.步骤七:使用步骤六匹配后的权重值的累加结果构建临时表;根据匹配阈值过滤出结果。
15.所述步骤一中,所述读取公司信息包括通过读取公司信息中构造的公司全称与简称的映射,用以将简称转化为公司全称;所述清洗包括通过正则表达式去除特殊符号、全角、半角。
16.所述步骤二中,所述缓冲截断具体为将公司名称拆分成预设关键词,所述预设关键词包括地区、关键词、行业和公司后缀,并将除公司后缀以外的预设关键词组合成形式化公司名称。
17.所述步骤三中,将形式化公司名称转成英文字母的组合具体为:将步骤二拆分出来的预设关键词分别转成英文字母的组合,用以表达由预设关键词组成的形式化公司名称。
18.所述步骤四中,构建形式化公司名称的双数组trie树包括:构建以预设关键词为类别的双数组trie树。
19.所述步骤六中,所述将第三方公司的形式化公司名称与双数组trie树匹配包括:将第三方公司的形式化公司名称中的预设关键词逐条与双数组trie树匹配,设置以每个预设关键词为类别的双数组trie树的权重。
20.所述步骤七中,使用权重值的累加结果构建临时表包括:根据权重值的累加结果,取达到预设阈值的公司名称匹配结果,通过scala语言插入指定临时表中。
21.本发明所达到的有益效果:本发明提出了一种公司名称匹配方法,利用全拼并建立三维数组作为映射将汉字分为元音,辅音,同音字三部分,将拼音带来的字母匹配变成三个数字的匹配提高效率,构建双数组防止了构建hash树时占用大量空间,在数据量大的情况下很难保证o(1),而且hash含有大量指针,对于含有gc语言来说并不友好,使得在大量数据环境下也能很快的匹配出结果。
附图说明
22.图1为本发明的示例性实施例的方法流程示意图;
23.图2为本发明的示例性实施例中的模块结构示意图;
24.图3为本发明的示例性实施例中的数据流向示意图。
具体实施方式
25.以下结合附图和具体实施例对本发明作进一步详细说明。
26.在本发明中,从读取配置文件数据通过自定义的规则从地区、关键词、行业和公司后缀形式化公司名称,并通过将中文字符转成数字的方法映射公司名称及创建含有业务库公司信息的字典树从而实现匹配的同时匹配数据其他信息,最终再将匹配完数据构建临时表插入制定表中,如图1所示的一种本发明实施例的数据处理流程,包括如下步骤:
27.步骤1,读取业务库中的公司信息,获取并清洗公司名称;
28.步骤2,对清洗后的公司名称进行缓冲截断,用以获得形式化公司名称,存入创建
的含有业务库数据信息的临时表;
29.步骤3,将形式化公司名称转成英文字母的组合,利用拼音的声母、韵母以及同音字库建立三维数组,用以表达形式化公司名称;
30.步骤4,构建形式化公司名称的双数组trie树,将临时表中的属性存入到相应的叶子节点中,将叶子节点存入内存;
31.步骤5:读取第三方的公司信息,按照步骤一到步骤四处理,得到相应的形式化公司名称;
32.步骤6:将第三方公司的形式化公司名称与双数组trie树匹配,设置双数组trie树中的每个类别的权重,一个类别双数组trie树匹配完成,则将结果作为一条数据行并跳出,并在内部累加权重值后进入下一个类别的双数组trie树,当全部类别双数组trie树匹配结束,开始下一条公司信息的匹配;
33.步骤7:使用步骤六匹配后的权重值的累加结果构建临时表;
34.步骤8:根据匹配阈值过滤出结果。
35.在本发明的一个示例性实施例中,其具体步骤为:
36.步骤11:读取业务库中的公司信息,获取并清洗公司名称,所述清洗包括通过正则表达式去除特殊符号、全角、半角,通过读取公司信息中构造的公司全称与简称的映射,用以将可能出现的简称转化为公司全称,比如“中海油”对应“中国海洋石油集团有限公司”,有效防止形式或公司名称关键信息丢失。
37.步骤12:清洗完的数据做缓冲截断,业务库中的公司名称经过清洗和映射(简称初始化),变为标准公司名称,因此将标准公司名称拆分成以地区(region)、关键词(x)、行业(industry)和公司后缀(org_suffix)组合的形式化公司名称,并将结果创建含有业务库数据信息的临时表。在本发明实施例中,临时表关于公司名称信息一行数据如下:
38.地区(南京)关键词(xxx)行业(科技)公司后缀(有限公司)
39.步骤13:拆分出来的公司名称关键词转成英文拼音并根据汉语拼音特性,利用声母、韵母以及同音字库,形成基于数字对应的三维数组,将一个汉字巧妙的利用数字表达,有效的缩短了公司名称所占字节,提高执行效率,缓解程序压力。示例如下,以“科”对应“868”为例:
40.声母数组:
41....k......8...
42.韵母数组:
43....e......6...
44.同音字表:
45....科......8...
46.步骤14:构建以预设关键词为类别的双数组trie树,将形式化公司名称在临时表中相应的属性存入到相应的叶子节点中,将叶子节点存入内存。
47.步骤15:读取将第三方需要与业务库匹配的公司信息,按照步骤11到步骤14清洗转换。
48.步骤16:将处理好的第三方公司信息逐条与双数组trie树匹配,设置每棵类别双数组trie树权重。若匹配完成则直接将相关信息作为一条数据行并跳出,并在内部累加权重值进入下一个类别的双数组trie树,全部类别双数组trie树匹配结束,开始下一条数据。
49.步骤17:将上述处理完的结果构建临时表并根据权重累加值取达到预设阈值的匹配结果,通过scala语言插入指定表中。
50.步骤18:根据匹配阈值过滤出结果。
51.如图2所示,本发明的示例性实施例中公开一种基于前述方法的公司名称匹配系统,包括:依次相连的数据源模块、数据预处理模块、字典树构建及数据匹配模块、和数据过滤模块。
52.所述数据源模块,用于读取业务库相关数据、第三方库数据及读取公司名称截断初始化条件配置,可能来自于业务系统、文本日志及其它数据结构源。
53.所述数据预处理模块,对业务库公司名称以及第三方公司名称做数据的清洗以及标准化,为字段树构建模块和数据匹配模块做好数据的预处理。
54.所述字典树构建模块及数据匹配模块,通过数字表达模块表达公司名称,通过双数组trie树匹配模块对每个预处理过的业务库公司名称进行构建双数组trie树,为避免处理完之后需再次关联第三方公司信息表和业务库公司信息表得到对应信息导致的再次匹配,故再构建双数组trie树时将业务库相对应的公司信息通过叶子节点模块一并存入树的叶子节点中,即使用叶子节点储存公司基本信息。根据预设的匹配逻辑,若匹配成功,则通过计算模块计算权重值,一并作为一行记录用于后面构建临时表。如成功匹配则跳出开始下一条匹配。
55.所述数据过滤模块,将匹配模块生成的一行行数据通过scala的样例类构建临时表,最后经过阈值过滤插入相应的库表中。
56.如图3所示,是数据匹配模块具体的例子将南京老王水产按照关键词拆分为“南京”,“老王”,“水产”,利用拼音的声母、韵母以及同音字库转换为数字,如“456789”、“545668”、“851999”,分别匹配按照地区、关键词和行业构建的双数组trie树,判断是否命中,若命中则累加相应的权重,反之记为0,算出权重和。
57.本发明中因为trie树本质是一个确定的有限状态自动机(dfa),核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。但由于trie树的稀疏现象严重,空间利用率较低为了让trie树实现占用较少的空间,同时还要保证查询的效率,最后提出了用2个线性数组来进行trie树的表示,即双数组trie(double array trie)。
58.本发明中除了基于双数组进行构建外还对叶子节点进行了压缩,缩短了为孩子节点寻找未被占用空间的时间,减少构建时间。缩小了数组占用的空间,提升了查询速度。
59.本发明提出了一种基于全拼及aho-corasick算法的公司名称匹配方法,利用全拼并建立三维数组作为映射将汉字分为声母,韵母,同音字三部分,继而将英文字母转成更简洁的数字组合,将拼音带来的字母匹配变成三个数字的匹配提高效率,构建双数组改善了由于构建hash树时占用大量空间,在数据量大的情况下很难保证o(1),而且hash含有大量
指针,对于含有gc语言来说并不友好的缺陷,使得在大量数据环境下也能很快的匹配出结果。
60.以上实施例不以任何方式限定本发明,凡是对以上实施例以等效变换方式做出的其它改进与应用,都属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
