1.本技术属于图像检索技术领域,尤其涉及一种基于深度学习的织物图像检索方法及装置。
背景技术:
2.中国是一个纺织生产大国,丝绸织物从古代起就开始出口到国外,随着不断发展,纺织工业在制作技艺上已取得了很大的进步,但在丝绸织物的检索上仍然存在需要解决的问题。当工厂从消费者那里获取样品进行仿制时,需要人工分析样品并在仓库中搜索相同或相似的现有织物,然后获得指导以供生产。此方法非常耗时,费力,并且容易产生失误,效率低下而精度不高。
3.目前织物检索采用基于文本的图像检索(tbir)来实现,需要借助手动注释文本关键字,该方法非常耗时,乏味且主观。也有采用基于内容的图像检索(cbir)方法,cbir的方法主要是基于纹理、颜色和形状,在一定程度上克服了tbir的缺点。cbir的方法通常涉及两个关键组成部分:(1)设计用于表示图像的特征提取算法;(2)选择合适的相似度计算方法。传统的特征提取方法通常使用手工制作的图像描述,例如等利用sift、gist对花边和刺绣织物提取特征并检索,这种方法取得了一定的成功,但在面对复杂场景时,这些基于低级特征的方法,往往由于提取的特征不足而效果不佳。
技术实现要素:
4.本技术的目的是提供一种基于深度学习的织物图像检索方法及装置,针对现有织物图像检索时,速度较慢或者准确性较低等不足,提高检索速度和准确性。
5.为了实现上述目的,本技术技术方案如下:
6.一种基于深度学习的织物图像检索方法,包括:
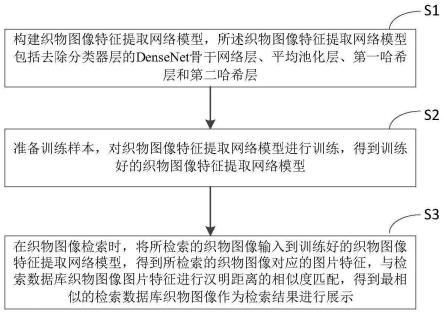
7.构建织物图像特征提取网络模型,所述织物图像特征提取网络模型包括去除分类器层的densenet骨干网络层、平均池化层、第一哈希层和第二哈希层;
8.准备训练样本,对织物图像特征提取网络模型进行训练,得到训练好的织物图像特征提取网络模型;
9.在织物图像检索时,将所检索的织物图像输入到训练好的织物图像特征提取网络模型,得到所检索的织物图像对应的图片特征,与检索数据库织物图像图片特征进行汉明距离的相似度匹配,得到最相似的检索数据库织物图像作为检索结果进行展示。
10.进一步的,所述织物图像特征提取网络模型的损失函数为:
11.lf=l αq βl012.其中,lf表示织物图像特征提取网络模型的损失函数,α、β是损失的权重参数,l0是第一哈希层的损失,l和q是第二哈希层的损失;
13.其中:
[0014][0015][0016][0017]
其中,n为训练样本的批量,ci表示第一哈希层输出特征,mi属于[mk,-mk],mk为哈达玛矩阵,mi表示ci对应于[mk,-mk]中的标签信息,k为输出特征的维度;w
ij
是权重系数,s
ij
表示图像对xi、xj的相似性,i和j属于n,γ为汉明距离参数,hi、hj为图像对xi、xj经过第二哈希层输出的哈希码,d(hi,hj)表示hi和hj之间的汉明距离;d(|hi|,1)代表hi的绝对值和1的汉明距离。
[0018]
进一步的,所述权重系数w
ij
,满足如下公式:
[0019][0020]
其中,s为相似性集合,s1={s
ij
∈s:s
ij
=1},s0={s
ij
∈s:s
ij
=0}。
[0021]
进一步的,所述d(hi,hj)计算公式如下:
[0022][0023]
进一步的,所述图像对xi、xj为从一个批量的训练样本中随机挑选其中两个训练样本组成的图像对。
[0024]
本技术还提出了一种基于深度学习的织物图像检索装置,包括处理器以及存储有若干计算机指令的存储器,所述计算机指令被处理器执行时实现所述基于深度学习的织物图像检索方法的步骤。
[0025]
本技术提出的一种基于深度学习的织物图像检索方法及装置,通过构造两个哈希层,既充分利用了标签信息,又使得分类中心不受哈希码长度的限制,同时通过使用较短的哈希码,解决了织物检索过程中速度慢的问题,从而实现了丝绸织物图像在真实场景中省时省力又准确的有效检索。
附图说明
[0026]
图1为本技术基于深度学习的织物图像检索方法流程图;
[0027]
图2为本技术实施例织物图像特征提取网络模型结构表示图。
具体实施方式
[0028]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
[0029]
在一个实施例中,如图1所示,提出了一种基于深度学习的织物图像检索方法,包括:
[0030]
步骤s1、构建织物图像特征提取网络模型,所述织物图像特征提取网络模型包括去除分类器层的densenet骨干网络层、平均池化层、第一哈希层和第二哈希层。
[0031]
本实施例采用改进的densenet网络,使用densenet121的网络结构,在原来的基础上去除了分类器层,形成骨干网络层,用于提取特征。
[0032]
如图2所示,本技术织物图像特征提取网络模型在骨干网络层(features)之后,添加平均池化层(adaptiveavgpool2d)、第一哈希层(hash1)和第二哈希层(hash2),最后用hash2层输出的哈希码来进行检索。通过构造两个哈希层,既充分利用了标签信息,又使得分类中心不受哈希码长度的限制,同时通过使用较短的哈希码,解决了织物检索过程中速度慢的问题。
[0033]
步骤s2、准备训练样本,对织物图像特征提取网络模型进行训练,得到训练好的织物图像特征提取网络模型。
[0034]
本实施例采用相机拍摄真实场景中织物图像,然后对织物图像进行标注,生成训练样本。
[0035]
无论是训练样本,还是对于需要进行检索的织物图像,以及检索数据库中的织物图像,都需要进行归一化操作,将图像大小置为256*256,使值分布在0到1之间,以便于进行训练和检索。
[0036]
一般网络模型的训练,就是将批量的训练样本输入到网络中得到预测出的结果,然后与标注(真实值)进行对比计算损失,再进行反向传播来更新网络参数,完成训练。关于网络模型的训练,为本领域比较成熟的技术,这里不再赘述。
[0037]
一个优秀的网络模型,取决于其网络结构以及设计的损失函数,在上个步骤中,已经描述本实施例织物图像特征提取网络模型的网络结果,本步骤将阐述该网络模型对应的损失函数。
[0038]
在一个具体的实施例中,本技术织物图像特征提取网络模型的损失函数表示为:
[0039]
lf=l αq βl0[0040]
其中,lf表示本技术织物图像特征提取网络模型的损失函数,α、β是损失的权重参数。l0是第一哈希层的损失,l和q是第二哈希层的损失。
[0041]
本实施例提出了新的损失函数,具体表现在hash1层和hash2层。作为改进,hash1层的损失函数利用hadamard矩阵(哈达玛矩阵),从而使得输出的特征的更加靠近某个中心,扩大不同类别之间的距离。hadamard的形式如下公式所示,其中a,k表示阶数,a的值是k的一半,并且a取值都是2的次方数,这也是hadamard矩阵的特性:
[0042]
[0043][0044][0045]
交叉熵损失是机器学习中常用的针对概率之间的损失函数,在各类模型中都表现出一定的性能,如下所示:
[0046][0047]
公式4中,p
i,1
,p
i,2
分别表示训练样本的标签信息以及输出特征,在其上面进行改善用于表示分类损失,所做的改变有:
[0048]
去掉了softmax层,从hash1层得到的n个样本输出特征向量c=[c1,
…
,cn],此时每个ci的维度为k,此时必须保证k是2的次方数,如(512,1024,2048)等,其中每个ci对应样本的标签为yi,用onehot编码表示。
[0049]
然后构造维度为k的hadamard矩阵,得到一个[mk,-mk]=[m1,
…
,m
2k
]的矩阵,并为每个不同的yi选择一个mi,具体方式为onehot编码中数字1所在位置的索引数即为矩阵中的i,从而使得相同的类别对应的mi相同,不同类别对应的mi不相同,由此得到类别数量个维度为k的mi,将mi作为标签信息,ci作为预测得到的特征进行替换,得到的损失函数l0如下公式所示:
[0050][0051]
其中,n为训练样本的批量,ci表示第一哈希层输出特征,mi属于[mk,-mk],mk为哈达玛矩阵,mi表示ci对应于[mk,-mk]中的标签信息,k为特征的维度。
[0052]
hash2层的损失函数主要利用数据之间的相似性产生合适的哈希码,用于表示相似性损失,首先给定一组训练的图像对,用{(xi,xj,s
ij
):s
ij
∈s}来表示,xi,xj,s
ij
分别表示,图像对xi,xj,以及他们的相似性s
ij
,s为所有相似性的集合,图像对用如下的方式获取:模型训练时期,读取一个批量的图像,随机挑选其中两张组成图像对xi,xj,i和j属于n。
[0053]
那么对于图像中n个样本产生的哈希码h=[h1,h2,
…
,hn]的最大后验估计可以表示为logp(h|s)。利用贝叶斯学习框架可以得到logp(h|s)正比于logp(s|h)p(h),其中似然函数p(s|h)可以如公式6表示,并由此可得到公式7:
[0054]
[0055][0056]
其中w
ij
是权重系数,用于相似对与不相似对之间的数据平衡,由公式8表示:
[0057][0058]
s1={s
ij
∈s:s
ij
=1}表示相似对的集合,s0={s
ij
∈s:s
ij
=0}表示不相似对的集合,p(s
ij
|hi,hj)是表示的是相似性标签s
ij
给出了一对哈希代码(hi,hj)的条件概率,由公式9表示:
[0059][0060]
σ是明确定义的概率函数,比较常用的是使用sigmod函数,而本技术用修改后的柯西分布概率密度函数来定义σ,原柯西分布由公式10表示,其中x0是定义分布峰值位置的位置参数,δ是最大值一半处的一半宽度的尺度参数,修改后的表示用公式11表示,其中γ为汉明距离参数,用于控制不同的汉明距离半径,并得到公式12:
[0061][0062][0063][0064]
汉明距离的值d(hi,hj)表示为:
[0065][0066]
本技术期望最大化似然估计,即最小化负对数似然函数,则在hash2层中,通过将上述公式代入到公式(7)中,最后希望被最小化的损失函数表示为l q,其中:
memory,prom),可擦除只读存储器(erasable programmable read-only memory,eprom),电可擦除只读存储器(electric erasable programmable read-only memory,eeprom)等。其中,存储器用于存储程序,所述处理器在接收到执行指令后,执行所述程序。
[0079]
所述处理器可能是一种集成电路芯片,具有数据的处理能力。上述的处理器可以是通用处理器,包括中央处理器(central processing unit,cpu)、网络处理器(network processor,np)等。可以实现或者执行本发明实施例中公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0080]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。