1.本发明属于计算机视觉技术领域,具体涉及一种城市内涝淹水深度估计方法。
背景技术:
2.近年来,城市管理日趋智能化,城市中与民生相关的信息也可以推送给市民用于预警或者便民。城市内涝也是很多城市经常遇到的问题,如果不能及时发现及预警的话可能会对市民生命财产造成损失,而通过市政人员现场勘查十分耗时费力,因此通过智能化手段自动检测和估计淹水深度,将整个城市的淹水情况进行汇总,用于抢险救灾或者对市民进行预警都极具现实意义。
技术实现要素:
3.本发明的技术目的是设计一种基于视频数据内行人进行评估的城市内涝淹水深度评估方法,用于抢险救灾或者对市民进行洪涝预警。
4.用于实现上述技术目的技术方案为:一种城市内涝淹水深度估计方法,其特征在于,包括以下步骤:s1:接入数据源所述数据源为视频数据;s2:视频解码对所述视频数据进行解码,获得包含行人的城市道路图像;s3:行人检测利用人脸识别模型对所述城市道路图像进行人脸检测,根据人脸所在的位置利用预设的anchor boxes识别出包含个体行人的第一行人区域;s4:行人姿态估计提取步骤s3行人检测的结果,将第一行人区域作为姿态估计模型的输入,利用姿态估计模型检测行人躯干的关键点;s5:行人区域分割提取步骤s3行人检测的结果,将第一行人区域作为图像分割模型的输入,利用图像分割模型进一步去掉第一行人区域中的背景区域后,将识别出的行人区域作为第二行人区域;s6:行人真实身高估计提取步骤s4行人姿态估计的结果,取行人肩部和腰部关键点的垂直距离作为上身高度,利用统计公式估算出该行人的整体身高;所述统计公式为:整体身高=上身身高m;上式中,m为该地区人口上身身高占整体身高的比例系数平均值;s7:行人水面上高度估计基于步骤s5行人区域分割的结果,提取第二行人区域的轮廓,计算筛选后的第二
行人区域的轮廓外接框,并以所述轮廓外接框的高度作为行人水面上的高度;s8:淹水深度估计结合步骤s6计算的行人整体身高以及步骤s7计算的行人水面上的高度,计算各行人被淹没的高度及其占其整体身高的比例,之后取所有行人被淹没比例的均值与该地区人口的平均身高n相乘作为该地区淹水深度的估计值;上述步骤s6和步骤s8中,所述比例系数平均值m、平均身高n根据对该地区人口身高参数的预先抽样统计获得。
5.在上述方案的基础上,优选的技术方案还包括:进一步的,步骤s3采用改进的ssd模型进行行人检测,所述改进的ssd模型在ssd模型的基础上,在连续池化操作后添加了对应的转置卷积操作。所述改进的ssd模型通过所述转置卷积操作生成深层特征图,然后将所述深层特征图与通过前序操作获得的相同尺寸的浅层特征图相加,实现特征融合,之后将特征融合的特征图作为模型的输出。
6.进一步的,所述改进的ssd模型的模型架构包括依次连接的mobilenetv2模块、第一池化层、第二池化层、第三池化层、第一转置卷积层和第二转置卷积层,通过第一转置卷积层获得的深层特征图与通过第二池化层获得的浅层特征图相加,通过第二转置卷积层获得的深层特征图与通过第三池化层获得的浅层特征图相加,然后将两次相加的结果进行特征融合后输出。
7.进一步的,步骤s4采用改进的实时姿态估计模型进行行人姿态的估计,所述改进的实时姿态估计模型以mobilenetv2为主干网络,通过以下方式获得:改进训练模型的损失函数,通过增加上身躯干关键点的定位损失权重来提高肩部及腰部关键点的定位准确率,具体为:在所有关键点定位损失权重为1的默认设置上,将上身躯干关键点的定位损失提高至1.5~2.0。
8.进一步的,步骤s5采用改进的unet模型进行行人区域分割,所述改进的unet模型在卷积时通过填充零值来确保卷积后特征图尺寸不减小,并在同尺寸特征图融合时使用逐点相加计算。
9.进一步的,步骤s6对行人整体身高的估计根据行人姿态估计的结果进行计算,若行人腰部被淹没在水面以下腰部关键点缺失,则跳过后续计算并给出报警信息。
10.进一步的,步骤s2以抽帧的方式对所述视频数据进行解码。
11.进一步的,在步骤s3和步骤s5中,利用预设的阈值排除干扰区域,将筛选后的第一、第二行人区域作为结果作为输出。
12.进一步的,所述预设的anchor boxes包括高宽比为1、2、3的三种anchor boxes进一步的,步骤s3中,将利用anchor boxes识别出的行人区域外扩后获得的行人区域作为第一行人区域, 所述外扩是指在anchor boxes识别区域的基础上,上下方向分别向外扩展高度的5%~10%,左右方向分别向外扩展宽度的5%~10%。
13.有益效果:本发明方法可以自动评估城市区域的淹水深度,应用于对城市洪涝灾害及道路积水情况的监测,为城市排水、交通管制、抢险救灾等提供决策依据,减轻了巡查人员的工作强度,加快发现问题、解决问题的速度,并可以指导公众出行及避险。同时,本发明基于摄像头采集的包含行人的视频数据即可实施,所述视频数据可以是城市监控系统采集的数据,
也可以是市民上传网络的视频数据,相较于其它需要专门设置硬件设施参照物的监测方法,本发明方法即避免了市政工作人员实地勘测的耗时费力,也解决了在没有设置硬件设施参照物的地方仅通过摄像头无法准确实施内涝监控的问题。
附图说明
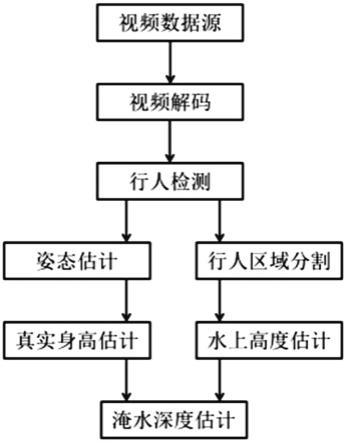
14.图1为本发明方法的流程图;图2为本发明方法中所述改进的ssd模型的架构图。
具体实施方式
15.现在结合附图对本发明作进一步详细的说明。
16.如图1所示,一种城市内涝淹水深度估计方法,包括以下步骤:s1:接入数据源所述数据源为视频数据。
17.本发明实施例优选使用的数据源是城市区域内已有或者按需求安装的监控摄像头所提供的视频数据,原因如下:(1)城市内监控摄像头基本会覆盖主要的城市区域,覆盖面和数量上有保障;(2)城市内监控摄像头天然的有地理信息,可以有效掌握不同区域的淹水情况;(3)本发明方法基于行人来对淹水深度进行评估,城市内摄像头可以采集到有行人通过的画面,保障本方法可行。
18.s2:视频解码对所述视频数据进行解码,获得包含行人的城市道路图像。
19.视频解码主要作用于行人检测、行人姿态估计以及行人区域分割,由于视频数据中图片帧数过多,冗余量过大,为了降低时间复杂度和空间复杂度,本发明实施例优选采取抽帧的方式进行视频解码。
20.s3:行人检测利用人脸识别模型对所述城市道路图像进行人脸检测,并根据人脸所在的位置利用预设的anchor boxes识别出一个或多个包含个体行人的第一行人区域。
21.本实施例中采用改进的ssd模型对抽取的每一帧图片进行人脸检测,所述改进的ssd模型在现有ssd模型的基础上,在连续池化操作后添加了对应的转置卷积操作,并针对行人检测问题的特征对anchor boxes的设置进行优化,以提升检测性能。
22.所述改进的ssd模型通过转置卷积操作生成深层特征图,然后将所述深层特征图与通过前序操作获得的相同尺寸的浅层特征图相加,实现特征融合,之后将特征融合的特征图作为模型的输出。具体架构如图2所示,改进的ssd模型的模型架构包括依次连接的mobilenetv2模块、第一池化层、第二池化层、第三池化层、第一转置卷积层和第二转置卷积层,通过第一转置卷积层获得的深层特征图与通过第二池化层获得的浅层特征图相加,通过第二转置卷积层获得的深层特征图与通过第三池化层获得的浅层特征图相加,然后将两次相加的结果进行特征融合后输出。融合后的特征与原ssd模型中的特征在维度方面保持一致,但是包含了更加丰富的特征,兼顾了浅层特征的定位准确性和深层特征的识别准确性。
23.在训练时优化anchor boxes,减少宽高比大的anchor boxes的数量,增加宽高比
小的anchor boxes的数量,更符合行人检测任务。本实施例中anchor boxes高宽比的选取为1、2、3,确保包含绝大多数行人区域的高宽比。同时,对利用上述anchor boxes检测到的行人区域进行筛选,利用预设的阈值去除不合理的干扰区域后,再对筛选后的行人区域进行适当的扩充,将扩充后的行人区域作为第一行人区域提取作为后续行人姿态估计和行人区域分割的输入数据。
24.为了减少周围环境及可能的相邻其他行人的干扰,本实施例中,所述外扩是指在anchor boxes识别区域的基础上,上下方向分别向外扩展高度的5%~10%,左右方向分别向外扩展宽度的5%~10%。
25.s4:行人姿态估计提取步骤s3行人检测的结果,将外扩后获得的第一行人区域作为姿态估计模型的输入,利用姿态估计模型检测行人躯干的关键点。
26.本实施采用改进的实时姿态估计模型进行行人姿态的估计,所述改进的实时姿态估计模型以mobilenetv2为主干网络,通过以下方式获得:改进训练该模型的损失函数,通过增加上身躯干关键点的定位损失权重来提高肩部及腰部关键点的定位准确率,具体为:在所有关键点定位损失权重为1的默认设置上,将上身躯干关键点的定位损失提高至1.5~2.0。即在训练姿态估计模型时,对人体关键点的检测更关注于上身躯干,以提高肩部及腰部关键点对定位准确率,而这并不会过于影响对躯干其他位置关键点定位的性能。
27.s5:行人区域分割提取步骤s3行人检测的结果,将外扩后获得的第一行人区域作为图像分割模型的输入,利用图像分割模型进一步去掉第一行人区域的背景区域,之后将识别出的行人区域作为第二行人区域。该区域相较于初始检测的第一行人区域更加准确,减少了周围环境或相邻行人的干扰。
28.本实施例采用改进的unet模型进行行人区域分割,所述改进的unet模型在卷积时通过填充零值来确保卷积后特征图尺寸不减小,并在同尺寸特征图融合时使用逐点相加计算。
29.本实施例中,图像分割模型的前景只需识别出人,并且行人区域已经是经过初步检测获取的结果了,所以分割任务比较简单,可以减小分割模型输入尺寸。例如,若外扩的第一行人区域的高宽像素均为256m,则可将输入图像分割模型的高宽都减半至128像素。在精简模型复杂度的同时保证性能不会下降,可降低算法运行时的时间复杂度和gpu显存使用量。
30.s6:行人真实身高估计提取步骤s4行人姿态估计的结果,取行人肩部和腰部关键点的垂直距离作为上身高度,利用统计公式估算出该行人的整体身高;所述统计公式为:整体身高=上身身高m;上式中,m为该地区人口上身身高占整体身高的比例系数平均值,根据对该地区人口身高参数的预先抽样统计获得。例如,根据对该地区成人的抽样统计的结果,该地区人口的m取值为3.38,则整体身高等于上身身高的3.38倍。
31.在该步骤中对行人整体身高的估计根据行人姿态估计的结果进行计算,若行人腰
部被淹没在水面以下腰部关键点缺失,则可跳过后续计算给出报警信息。
32.s7:行人水面上高度估计基于步骤s5行人区域分割的结果,提取第二行人区域的轮廓,根据预设的阈值剔除干扰区域,例如高小于50像素或宽小于25像素的行人区域,以及宽高比大于1或者小于0.2的行人区域等。之后计算筛选后的第二行人区域的轮廓外接框,并以所述轮廓外接框的高度作为行人水面上的高度。
33.s8:淹水深度估计结合步骤s6计算的行人整体身高以及步骤s7计算的行人水面上的高度,计算各行人被淹没的高度及淹没高度占其整体身高的比例,之后取所有被行人被淹没比例的均值与该地区人口的平均身高n相乘作为该地区淹水深度的估计值。
34.所述平均身高n根据对该地区人口身高参数的预先抽样统计获得。假设根据抽样统计,该地区成人人口平均身高为170cm,则将所有行人被淹没比例的均值与170cm相乘,作为该区域淹水深度估计值。
35.以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。