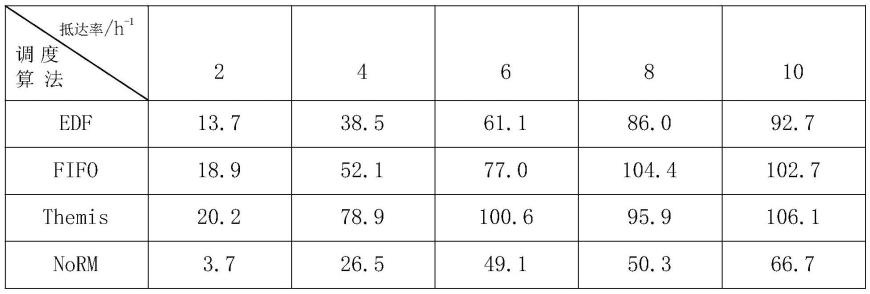
技术特征:
1.一种面向gpu集群的动态资源调度方法,其特征在于包括以下步骤:步骤(1)、基于分布式机器学习的ring-allreduce通信架构下的dnn模型迭代特征和gpu设备间的带宽差异,构建资源-时间模型:所述资源-时间模型包括如下:(1.1)分布式深度学习任务在某个资源方案下的实际运行时间t
run
表示如下:t
run
=t
step
×
n
step
×
n
epoch
ꢀꢀꢀꢀ
式(1)其中,t
step
是dnn模型训练一个批次大小的数据集所花费的时间,n
step
是dnn模型在一个迭代回合中可输入的一个批次大小的数据集个数,n
epoch
表示迭代回合;(1.2)t
step
由单个cpu设备上的计算时间t
cal
、cpu与cpu设备间的通信时间t
comm
所组成,其计算公式如下:t
step
=t
cal
t
comm
ꢀꢀꢀꢀ
式(2)(1.4)n
step
会随着资源方案所包含的gpu总数不同而发生变化,数量越多,则n
step
则相应地减少;n
step
、dnn模型训练数据集大小s
dataset
、批次大小s
batch
和gpu总数n
gpu
在分布式数据并行训练过程中的关系如下:其中,n
gpu
由资源方案上每个节点的c
used
累加得到,c
used
表示训练任务在单个节点上被使用的gpu数量;(1.5)通过将dnn模型放置在单个gpu设备上进行若干批次的迭代并记录对应的运行时间,由于不涉及多设备通信,因此该运行时间仅包含将单个gpu设备上的计算时间表示如下:其中,t
′
step
是若干次迭代的运行时间,n
′
step
是相应的迭代次数;(1.6)如果不存在通信时间,那么任务的运行时间和资源方案所包含的gpu总数将为正比关系,即随着gpu总数上升,任务的运行时间将会成比例下降.而存在通信时间时,则会导致运行效率的下降;ring-allreduce通信架构下的通信时间t
comm
表示如下:其中,bw是两gpu设备之间的带宽速度,如果两gpu设备处于同一个节点上,则bw就是节点内gpu设备之间的带宽,如果两gpu设备处于不同节点,则bw就是节点间的网络带宽;步骤(2)、基于资源方案使用的资源数量、任务运行时间和任务截止时间构建资源-性能模型:(2.1)截止时间建模:(2.1.1)设用户对于任务的截止时间需求由任务到达时间、任务优先级以及任务最大运行时间所组成,其中最大运行时间是任务仅在单个gpu设备上的运行时间,定义若干任务优先级,将优先级转换为任务的期望运行时间t
exp
,其计算公式表示如下:其中,α对应任务优先级,表示任务在单个gpu设备上运行的时间;
(2.1.2)设任务的到达时间和运行开始时间分别为t
arr
和t
start
,则任务的截止时间t
dl
和运行结束时间t
end
则可分别表示为:t
dl
=t
arr
t
exp
ꢀꢀꢀ
式(7)t
end
=t
start
t
run
ꢀꢀꢀ
式(8)(2.1.3)当任务的截至时间t
dl
和运行结束时间t
end
满足下述的式(9)时,说明任务结束时满足用户的截止时间需求:t
end
<t
dl
ꢀꢀꢀ
式(9)(2.2)当资源方案所持有的gpu设备都位于同一节点上时,其带宽速度为gpu设备之间的直连带宽,而当资源方案所持有的gpu设备位于不同节点上时,其带宽速度则为节点和节点之间的网络带宽;由式(5)可知,在n
gpu
和n
param
不变时,t
comm
随着bw的减少而增加,将式(2)和式(3)代入式(1)中,并要求多机分布式训练的时间比单机训练的运行时间要来得短,则可以得到如下不等式:其中,不等式前半部分和后半部分分别为dnn模型在多个节点和单个节点上训练一个迭代回合的时间,化简式(10)可得:t
comm
<(n
gpu-1)
×
t
cal
ꢀꢀꢀ
式(11)当dnn模型在进行多机分布式训练时,t
comm
、n
gpu
和t
cal
只有符合式(10)才能达到模型训练加速的目的;(2.3)为衡量任务在不同资源方案下的性能,并在满足截至时间需求的多个资源方案中选择运行效率最高的资源方案,充分发挥资源性能,将资源-性能模型的性能公式定义为:(2.3)为衡量任务在不同资源方案下的性能,并在满足截至时间需求的多个资源方案中选择运行效率最高的资源方案,充分发挥资源性能,将资源-性能模型的性能公式定义为:其中t
dl
表示任务的截至时间;步骤(3)、在步骤(1)、(2)基础上进行分布式深度学习任务的动态资源方案决策:为等待队列中的每个任务基于集群空闲资源和资源布局生成可用资源方案列表,根据资源-性能模型并结合集群节点负载情况,确定每个任务的最优资源方案;步骤(4)、在步骤(3)的基础上,根据任务的最优方案执行物理资源节点分配;步骤(5)、在动态资源调度算法每次执行任务调度流程前,将分析已运行任务情况,决定是否进行资源迁移;步骤(6)、调度器执行调度算法选择新的任务至gpu集群运行。2.如权利要求1所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(1)中所述ring-allreduce通信架构包括互相通信的gpu集群的若干节点,每个节点中包括多个cpu和gpu,同一个节点上的gpu设备借助高速串行计算机扩展总线标准pcie和快速通道互联qpi进行通信,其中gpu和gpu间采用pcie通信,gpu和cpu间采用pcie通信,cpu和cpu间采用qpi通信;gpu集群中的节点与节点之间则借助无线宽带技术进行通信。
3.如权利要求1所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(3)中具体如下:(3.1)获取资源列表r,并设c
free
>0的资源节点数量为n,c
free
表示单个节点中空闲gpu数量,资源节点中c
free
的最大值为max(c
free
)及其累加和为sum(c
free
),并初始化单节点资源方案列表l
s
和跨节点资源方案列表l
m
;(3.2)如果n=1,则在资源列表r获取c
used
从1至max(c
free
)的资源方案r
t
添加到l
s
中,如果n>1,则在资源列表r获取c
used
从1至sum(c
free
)的资源方案r
t
添加到l
m
中;根据式(1)和式(8)计算l
s
和l
m
中r
t
的t
run
和t
end
,并根据式(11)过滤部分低效率的资源方案r
t
;(3.3)根据式(12)得到l
s
中性能且的值为最大时的资源方案r
t
作为单节点预期方案以及根据式(12)得到l
s
中t
end
>t
dl
且t
end
的值为最小时的资源方案r
t
作为单节点非预期方案根据式(12)得到从l
m
中性能且的值为最大时的资源方案r
t
作为跨节点预期方案以及根据式(12)得到l
m
中t
end
>t
dl
且t
end
的值为最小时的资源方案r
t
作为跨节点非预期方案注意其中和可能不存在;(3.4)判断是否满足跨节点预期方案存在且gpu集群存在0<c
free
<n
gpu
的资源节点,如果满足则说明当前任务存在跨节点资源方案可以利用局部资源并在t
dl
内结束运行,此时最优资源方案如果不满足但存在,则最优资源方案如果不满足且仍不存在,则说明gpu集群当前空闲资源无法令当前任务在t
dl
内运行结束运行,则认为此时没有预期方案和可供选择,则判断是否满足跨节点非预期方案存在且gpu集群存在0<c
free
<n
gpu
的资源节点,如果满足则说明当前任务存在跨节点资源方案可以利用局部资源并在t
dl
内结束运行,此时最优资源方案如果不满足,则最优资源方案4.如权利要求3所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(4)具体是:(4.1)获取资源列表r并按照节点的c
free
升序排序;(4.2)如果步骤(3)最优资源方案为单节点预期方案则遍历资源列表r,找到c
free
≥n
gpu
的资源节点node(s,c
free
),从该资源节点node(s,c
free
)移出n
gpu
个gpu设备,将node(s,n
used
)添加到中,结束遍历,其中node(s,c
free
)表示gpu集群中的序号为s并且拥有c
free
个空闲gpu的节点对象,s表示节点对象的序号;node(s,n
used
)表示gpu集群中的序号为s并且拥有n
used
个使用中gpu的节点对象;(4.3)如果步骤(3)最优资源方案为跨节点预期方案则设n
used
=n
gpu
,n
gpu
是由资源方案上每个节点的c
used
累加得到的gpu总数,遍历资源列表r,找到c
free
>0的资源节点对象node(s,c
free
),从该资源节点对象node(s,c
free
)和n
used
分别移出min(c
free
,n
used
)个gpu设备,将资源节点对象node(s,min(c
free
,n
gpu
))添加到中,以此类推,直到n
used
=0,结束遍历;node(s,min(c
free
,n
gpu
))表示node(s,n
used
)表示gpu集群中的序号为s并且拥有min(c
free
,n
used
)个gpu的节点对象。5.如权利要求4所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(5)具
体是:(5.1)初始化任务列表l
s
和l
m
;遍历运行任务队列q
run
,将原处于单节点运行的任务t添加到l
s
中,将原处于跨节点运行的任务t添加到l
m
中;(5.2)将l
s
和l
m
中的任务t根据最优资源方案的gpu总数n
gpu
降序排序;首先遍历l
s
,对其中的任务t执行步骤(4)的物理资源分配过程,然后遍历l
m
,对其中的任务t同样执行步骤(4)的物理资源分配过程。6.如权利要求5所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(6)具体是:(6.1)接收等待任务队列q
wait
、资源列表r和当前时间t
curr
,其中t
curr
以单位时间增加,当分布式深度学习任务的到达时间t
arr
=t
curr
时,将任务添加到队列q
wait
中,此时根据式(7)预先计算任务的截至时间t
dl
;(6.2)动态资源调度。7.如权利要求6所述的一种面向gpu集群的动态资源调度方法,其特征在于步骤(6.2)具体是:(6.2.1)根据gpu集群资源的负载情况,尝试执行步骤(5)的资源迁移过程;(6.2.2)遍历等待队列q
wait
,对任务t执行步骤(3)的资源方案决策得到t的最优资源方案(6.2.3)初始化预期任务队列q
exp
和非预期任务队列如果任务的运行结束时间t
end
和截止时间t
dl
满足式(9),则将任务t添加到队列q
exp
中,反之添加到队列中;将队列q
exp
中的任务t根据t
dl-t
end
的值升序降序,此时排在队头的任务t在资源方案下的t
end
越接近t
dl
;将队列中的任务t根据t
end
的值升序排序,排在队头的任务t在资源方案下的t
end
越接近t
dl
;注意队列q
exp
可能为空;(6.2.4)如果队列q
exp
不为空,则选择排头任务t作为调度任务t
*
;如果队列q
exp
为空则选择队列中的排头任务t作为调度任务t
*
;对t
*
执行步骤(4)的物理资源分配过程。8.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现权利要求1-7任一项所述的方法。9.一种机器可读存储介质,其特征在于,该机器可读存储介质存储有机器可执行指令,该机器可执行指令在被处理器调用和执行时,机器可执行指令促使处理器实现权利要求1-7任一项所述的方法。
技术总结
本发明公开一种面向GPU集群的动态资源调度方法。构建资源-时间模型和资源-性能模型;进行分布式深度学习任务的动态资源方案决策;根据任务的最优方案执行物理资源节点分配;在动态资源调度算法每次执行任务调度流程前,将分析已运行任务情况,决定是否进行资源迁移:调度器执行调度算法选择新的任务至GPU集群运行。本发明综合考虑了任务自身的完成时间和用户截至完成时间,根据GPU集群负载情况和任务运行情况可实时动态调度GPU工作,有效减少了深度学习训练任务完成时间,最大化截止时间保证率并有效地提高了GPU集群工作效率和GPU集群节点的资源利用率。GPU集群节点的资源利用率。GPU集群节点的资源利用率。
技术研发人员:胡海洋 宋建飞 傅懋钟 李忠金
受保护的技术使用者:杭州电子科技大学
技术研发日:2022.04.12
技术公布日:2022/6/21
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。