一种面向gpu集群的动态资源调度方法
技术领域
1.本发明涉及一种面向gpu集群的动态资源调度方法,gpu集群上借助分布式深度学习技术利用多个gpu设备对深度神经网络(deep neural networks,dnn)模型进行并行训练,从而加快训练过程。
背景技术:
2.深度学习技术在过去几年被应用于众多业务场景当中,研发人员根据业务场景的目标特征构建dnn模型,并在特定数据集上反复训练直至模型精度维持在一个预期的水平,从而达到业务场景的复杂程度提高,此时需要结构更复杂并且层数越来越多的dnn模型来获得较高的精度,同时数据集的规模也不断地增长,导致训练一个dnn模型需要耗费大量的时间。
3.因此学术界和工业界需要通过分布式并行计算的方式构建分布式深度学习任务,在gpu集群上使用多个gpu设备同时对dnn模型进行训练从而加快训练过程。现在的主流的机器学习框架,如pytorch、tensorflow等,都对分布式深度学习提供了完整的技术支持。
4.多数企业和高校通常会采购多个gpu设备组建一个中小规模的gpu集群来运行多个用户的分布式深度学习任务。他们目前使用现有的gpu集群调度器,例如yarn、mesos和kubernetes,并未对分布式深度学习任务提供良好的调度支持,会导致资源分配不当,运行效率不高,无法满足用户要求。在某实验室使用yarn进行资源管理的gpu集群中,同一机架和跨机架分别采用无线宽带技术和以太网对gpu设备之间进行互联,由于gpu设备间的带宽差异,不同资源布局方式会导致dnn模型的训练效率不同,该gpu集群上的历史调度日志表明该gpu集群的平均资源利用率仅有50%。此外,对于gpu集群用户而言,任务截止时间是衡量用户满意度的关键指标,在大多数情况下,用户可以接受在截止时间之前完成的任务,而当任务结束时间超过截止时间时,用户对于gpu集群的性能满意度会大幅下降。
5.许多专家和学者在gpu集群的资源调度上针对不同的优化指标进行了研究,现有相关工作主要从减少任务完成时间和提升gpu集群性能指标两方面进行资源调度过程。现有相关工作虽然能够较为有效地解决gpu集群的资源调度问题,其中尝试结合资源分配、资源布局和截止时间需求的研究工作较少,但是对于在异构带宽环境下最大化截止时间保证率仍存在一定的局限性。
技术实现要素:
6.本发明的一个目的是针对异构带宽环境下具有截止时间需求的多任务调度问题,提出一种面向gpu集群的动态调度的方法,将资源配置、资源布局和截止时间需求相结合得到调度决策,最大化截止时间保证率并提高gpu集群节点的资源利用率。
7.本发明方法包括以下步骤:
8.一种面向gpu集群的动态资源调度方法,包括以下步骤:
9.步骤(1)、基于分布式机器学习的ring-allreduce通信架构下的dnn模型迭代特征
和gpu设备间的带宽差异,构建资源-时间模型;
10.步骤(2)、基于资源方案使用的资源数量、任务运行时间和任务截止时间构建了资源-性能模型;
11.步骤(3)、在步骤(1)、(2)基础上进行分布式深度学习任务的动态资源方案决策;
12.步骤(4)、在步骤(3)的基础上,根据任务的最优方案执行物理资源节点分配;
13.步骤(5)、在动态资源调度算法每次执行任务调度流程前,将分析已运行任务情况,决定是否进行资源迁移:
14.步骤(6)、调度器执行调度算法选择新的任务至gpu集群运行。
15.本发明的另一个目的是提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的方法。
16.本发明的又一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
17.本发明的有益效果:
18.1)利用时间模型获取任务在不同资源方案下的运行时间,其次利用性能模型指导分布式深度学习任务的最优资源方案生成,然后基于最近截止时间原则选择调度任务,最后进行资源分配确定资源方案的物理资源位置,生成含有gpu集群节点序号和gpu数量的运行方案。借助机器学习框架应用接口在gpu集群服务器上启动任务运行脚本,完成资源调度过程。
19.2)引入迁移机制减少调度过程中出现的资源碎片场景的影响。
20.3)ring-allreduce通信架构能够有效减少参数同步阶段所需要的通信时间。
21.4)使用资源-性能模型对可用资源方案进行筛选,保留可进行有效分布式训练的资源方案,减少出现资源浪费的现象。
22.与现有技术相比,本发明综合考虑了任务自身的完成时间和用户截至完成时间,根据gpu集群负载情况和任务运行情况可实时动态调度gpu工作,有效减少了深度学习训练任务完成时间,最大化截止时间保证率并有效地提高了gpu集群工作效率和gpu集群节点的资源利用率。
23.相关概念定义及符号说明
24.c
free
:表示空闲gpu数量;
25.t
run
:表示在某个资源方案下的实际运行时间;
26.t
cal
:表示单个gpu设备上的计算时间;
27.ls:表示一个单节点资源方案列表;
28.lm:表示跨节点资源方案列表。
附图说明
29.图1:ring-allreduce通信架构示意图。
30.图2:资源配置决策示意图。
31.图3:物理资源分配示意图。
32.图4:资源迁移机制示意图。
33.图5:动态资源调度方法示意图。
具体实施方式
34.下面结合附图对本发明做进一步的分析。
35.本发明面向gpu集群的动态资源调度方法包括以下步骤:
36.一种面向gpu集群的动态资源调度方法,其特征在于包括以下步骤:
37.步骤(1)、基于分布式机器学习的ring-allreduce通信架构下的dnn模型迭代特征和gpu设备间的带宽差异,构建资源-时间模型:
38.所述ring-allreduce通信架构包括互相通信的gpu集群的若干节点,每个节点中包括多个cpu和gpu,同一个节点上的gpu设备借助高速串行计算机扩展总线标准(pcie)和快速通道互联(qpi)进行通信(其中gpu和gpu间采用pcie通信,gpu和cpu间采用pcie通信,cpu和cpu间采用qpi通信),gpu集群中的节点与节点之间则借助无线宽带技术(infiniband)进行通信;
39.所述资源-时间模型包括如下:
40.(1.1)分布式深度学习任务在某个资源方案下的实际运行时间t
run
表示如下:
41.t
run
=t
step
×nstep
×nepoch
ꢀꢀ
式(1)
42.其中,t
step
是dnn模型训练一个批次大小的数据集所花费的时间,n
step
是dnn模型在一个迭代回合中可输入的一个批次大小的数据集个数,n
epoch
表示迭代回合;
43.(1.2)t
step
由单个cpu设备上的计算时间t
cal
、cpu与cpu设备间的通信时间t
comm
所组成,其计算公式如下:
44.t
step
=t
cal
t
comm
ꢀꢀ
式(2)
45.(1.4)n
step
会随着资源方案所包含的gpu总数不同而发生变化,数量越多,则n
step
则相应地减少;n
step
、dnn模型训练数据集大小s
dataset
、批次大小s
batch
和gpu总数n
gpu
在分布式数据并行训练过程中的关系如下:
[0046][0047]
其中,n
gpu
由资源方案上每个节点的c
used
累加得到,c
used
表示训练任务在单个节点上被使用的gpu数量;
[0048]
(1.5)通过将dnn模型放置在单个gpu设备上进行若干批次的迭代并记录对应的运行时间,由于不涉及多设备通信,因此该运行时间仅包含将单个gpu设备上的计算时间表示如下:
[0049][0050]
其中,t'
step
是若干次迭代的运行时间,n'
step
是相应的迭代次数;
[0051]
(1.6)如果不存在通信时间,那么任务的运行时间和资源方案所包含的gpu总数将为正比关系,即随着gpu总数上升,任务的运行时间将会成比例下降.而存在通信时间时,则会导致运行效率的下降;ring-allreduce通信架构下的通信时间t
comm
表示如下:
[0052][0053]
其中,bw是两gpu设备之间的带宽速度,如果两gpu设备处于同一个节点上,则bw就是节点内gpu设备之间的带宽,如果两gpu设备处于不同节点,则bw就是节点间的网络带宽;
[0054]
步骤(2)、基于资源方案使用的资源数量、任务运行时间和任务截止时间构建了资源-性能模型:
[0055]
(2.1)截止时间建模:
[0056]
(2.1.1)设用户对于任务的截止时间需求由任务到达时间、任务优先级以及任务最大运行时间所组成,其中最大运行时间是任务仅在单个gpu设备上的运行时间,定义若干任务优先级,将优先级转换为任务的期望运行时间t
exp
,其计算公式表示如下:
[0057][0058]
其中,α对应任务优先级,表示任务在单个gpu设备上运行的时间;
[0059]
(2.1.2)设任务的到达时间和运行开始时间分别为t
arr
和t
start
,则任务的截止时间t
dl
和运行结束时间t
end
则可分别表示为:
[0060]
t
dl
=t
arr
t
exp
ꢀꢀ
式(7)
[0061]
t
end
=t
start
t
rum
ꢀꢀ
式(8)
[0062]
(2.1.3)当任务的截至时间t
dl
和运行结束时间t
end
满足下述的式(9)时,说明任务结束时满足用户的截止时间需求:
[0063]
t
end
《t
dl
ꢀꢀ
式(9)
[0064]
(2.2)当资源方案所持有的gpu设备都位于同一节点上时,其带宽速度为gpu设备之间的直连带宽,而当资源方案所持有的gpu设备位于不同节点上时,其带宽速度则为节点和节点之间的网络带宽;由式(5)可知,在n
gpu
和n
param
不变时,t
comm
随着bw的减少而增加,将式(2)和式(3)代入式(1)中,并要求多机分布式训练的时间比单机训练的运行时间要来得短,则可以得到如下不等式:
[0065][0066]
其中,不等式前半部分和后半部分分别为dnn模型在多个节点和单个节点上训练一个迭代回合的时间,化简式(10)可得:
[0067]
t
comm
《(n
gpu-1)
×
t
cal
ꢀꢀ
式(11)
[0068]
当dnn模型在进行多机分布式训练时,t
comm
、n
gpu
和t
cal
只有符合式(10)才能达到模型训练加速的目的;
[0069]
(2.3)为衡量任务在不同资源方案下的性能,并在满足截至时间需求的多个资源方案中选择运行效率最高的资源方案,充分发挥资源性能,将资源-性能模型的性能公式定义为:
[0070]
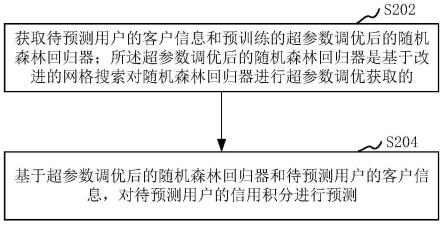
(2.3)为衡量任务在不同资源方案下的性能,并在满足截至时间需求的多个资源方案中选择运行效率最高的资源方案,充分发挥资源性能,将资源-性能模型的性能公式定义为:
[0071][0072]
其中t
dl
表示任务的截至时间;
[0073]
步骤(3)、在步骤(1)、(2)基础上进行分布式深度学习任务的动态资源方案决策的过程如下图2:
[0074]
为等待队列中的每个任务基于集群空闲资源和资源布局生成可用资源方案列表,
根据资源-性能模型并结合集群节点负载情况,确定每个任务的最优资源方案;具体如下:
[0075]
(3.1)获取资源列表r,并设c
free
》0的资源节点数量为n,c
free
表示单个节点中空闲gpu数量,资源节点中c
free
的最大值为max(c
free
)及其累加和为sum(c
free
),并初始化单节点资源方案列表ls和跨节点资源方案列表lm;
[0076]
(3.2)如果n=1,则在资源列表r获取c
used
从1至max(c
free
)的资源方案r
t
添加到ls中,如果n》1,则在资源列表r获取c
used
从1至sum(c
free
)的资源方案r
t
添加到lm中;
[0077]
根据式(1)和式(8)计算ls和lm中r
t
的t
run
和t
end
,并根据式(11)过滤部分低效率的资源方案r
t
;
[0078]
(3.3)根据式(12)得到ls中性能≥0且的值为最大时的资源方案r
t
作为单节点预期方案以及根据式(12)得到ls中t
end
》t
dl
且t
end
的值为最小时的资源方案r
t
作为单节点非预期方案
[0079]
根据式(12)得到从lm中性能且的值为最大时的资源方案r
t
作为跨节点预期方案以及根据式(12)得到lm中t
end
》t
dl
且t
end
的值为最小时的资源方案r
t
作为跨节点非预期方案注意其中和可能不存在;
[0080]
(3.4)判断是否满足跨节点预期方案存在且gpu集群存在0《c
free
《n
gpu
的资源节点,如果满足则说明当前任务存在跨节点资源方案可以利用局部资源并在t
dl
内结束运行,此时最优资源方案如果不满足但存在,则最优资源方案如果不满足且仍不存在,则说明gpu集群当前空闲资源无法令当前任务在t
dl
内运行结束运行,认为此时没有预期方案和可供选择,判断是否满足跨节点非预期方案存在且gpu集群存在0《c
free
《n
gpu
的资源节点,如果满足则说明当前任务存在跨节点资源方案可以利用局部资源并在t
dl
内结束运行,此时最优资源方案如果不满足,则最优资源方案
[0081]
步骤(4)、在步骤(3)的基础上,根据任务的最优方案执行物理资源节点分配过程如下图3:
[0082]
(4.1)获取资源列表r并按照节点的c
free
升序排序;
[0083]
(4.2)如果步骤(3)最优资源方案为单节点预期方案则遍历资源列表r,找到c
free
≥n
gpu
的资源节点node(s,c
free
),从该资源节点node(s,c
free
)移出n
gpu
个gpu设备,将node(s,n
used
)添加到中,结束遍历,其中node(s,c
free
)表示gpu集群中的序号为s并且拥有c
free
个空闲gpu的节点对象,s表示节点对象的序号;node(s,n
used
)表示gpu集群中的序号为s并且拥有n
used
个使用中gpu的节点对象;
[0084]
(4.3)如果步骤(3)最优资源方案为跨节点预期方案则设n
used
=n
gpu
,n
gpu
是由资源方案上每个节点的c
used
累加得到的gpu总数,遍历资源列表r,找到c
free
》0的资源节点对象node(s,c
free
),从该资源节点对象node(s,c
free
)和n
used
分别移出min(c
free
,n
used
)个gpu设备,将资源节点对象node(s,min(c
free
,n
gpu
))添加到中,以此类推,直到n
used
=0,结束遍历;node(s,min(c
free
,n
gpu
))表示node(s,n
used
)表示gpu集群中的序号为s并且拥有min
(c
free
,n
used
)个gpu的节点对象;
[0085]
步骤(5)、在动态资源调度算法每次执行任务调度流程前,将分析已运行任务情况,决定是否进行资源迁移过程如下图4;具体如下:
[0086]
(5.1)初始化任务列表ls和lm;遍历运行任务队列q
run
,将原处于单节点运行的任务t添加到ls中,将原处于跨节点运行的任务t添加到lm中;
[0087]
(5.2)将ls和lm中的任务t根据最优资源方案的gpu总数n
gpu
降序排序;首先遍历ls,对其中的任务t执行步骤(4)的物理资源分配过程,然后遍历lm,对其中的任务t同样执行步骤(4)的物理资源分配过程;
[0088]
步骤(6)、调度器执行调度算法选择新的任务至gpu集群运行;具体如下:
[0089]
(6.1)接收等待任务队列q
wait
、资源列表r和当前时间t
curr
,其中t
curr
以单位时间增加,当分布式深度学习任务的到达时间t
arr
=t
curr
时,将任务添加到队列q
wait
中,此时根据式(7)预先计算任务的截至时间t
dl
;
[0090]
(6.2)动态资源调度的过程如下图5;具体步骤如下:
[0091]
(6.2.1)根据gpu集群资源的负载情况,尝试执行步骤(5)的资源迁移过程;
[0092]
(6.2.2)遍历等待队列q
wait
,对任务t执行步骤(3)的资源方案决策得到t的最优资源方案
[0093]
(6.2.3)初始化预期任务队列q
exp
和非预期任务队列如果任务的运行结束时间t
end
和截止时间t
dl
满足式(9),则将任务t添加到队列q
exp
中,反之添加到队列中;将队列q
exp
中的任务t根据t
dl-t
end
的值升序降序,此时排在队头的任务t在资源方案下的t
end
越接近t
dl
;将队列中的任务t根据t
end
的值升序排序,排在队头的任务t在资源方案下的t
end
越接近t
dl
;注意队列q
exp
可能为空;
[0094]
(6.2.4)如果队列q
exp
不为空,则选择排头任务t作为调度任务t
*
;如果队列q
exp
为空则选择队列中的排头任务t作为调度任务t
*
;对t
*
执行步骤(4)的物理资源分配过程。
[0095]
实验数据
[0096]
(1)参与测量的dnn模型在gpu集群单个gpu设备训练多个迭代回合的时间
[0097][0098][0099]
(2)实验数据对比:
[0100]
(2.1)earliest deadline first(edf):从等待队列中选择截止时间最小的任务并使用整体gpu资源进行资源分配;
[0101]
(2.2)first in first out(fifo):等待任务队列中选择到达时间最小的任务并使用整体gpu资源进行资源分配;
[0102]
(2.3)themis:将gpu资源根据完成时间公平性分配给多个等待任务并一次性调度至gpu集群运行,尽可能保证任务之间具有相近的完成时间;
[0103]
(2.4)no resource migration(norm):为了验证drs引入迁移机制的有效性,将drs中的迁移机制部分移除,比较它和drs的各种性能指标。
[0104]
(2.5)本发明面向gpu集群的动态资源调度方法为dynamic resource scheduling(drs)。
[0105]
(3)不同任务抵达率对于各个调度算法性能的比较:
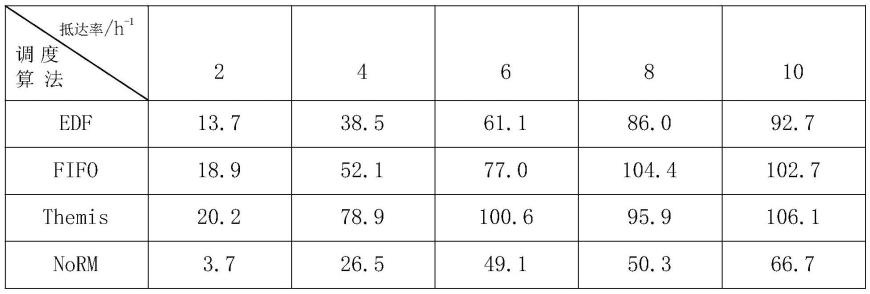
[0106]
(3.1)截止时间保证率/%
[0107][0108]
(3.2)平均等待时间/h
[0109][0110][0111]
(3.3)平均完成时间/h
[0112][0113]
(4)不同资源节点数量下对于各个调度算法性能的比较:
[0114]
(4.1)截止时间保证率/%
[0115][0116]
(4.2)平均等待时间/h
[0117][0118]
(4.3)平均完成时间/h
[0119][0120]
(5)同紧急任务数量下对于各个调度算法性能的比较:
[0121]
(5.1)截止时间保证率/%
[0122][0123]
(5.2)平均等待时间/h
[0124][0125]
(5.3)平均完成时间/h
[0126]
[0127][0128]
(6)不同接收时间下对于各个调度算法性能的比较:
[0129]
(6.1)截止时间保证率/%
[0130][0131]
(6.2)平均等待时间/h
[0132][0133]
(6.3)平均完成时间/h
[0134][0135]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。