用于虚拟现实和增强现实的系统和方法
1.相关申请的交叉引用
2.本技术要求于2019年11月14日提交的美国临时专利申请no.62/935,597的优先权,其全部内容通过引用并入本文。
技术领域
3.本发明涉及连接的移动计算系统、方法和配置,并且更具体地涉及以可用于虚拟和/或增强现实操作的至少一个可穿戴组件为特征的移动计算系统、方法和配置。
背景技术:
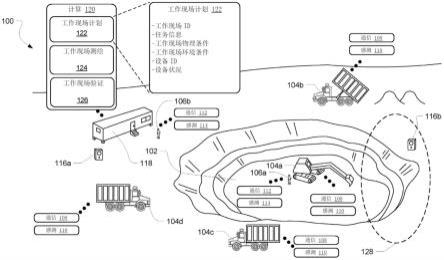
4.希望混合现实或增强现实近眼显示器重量轻、成本低、具有小尺寸、具有宽的虚拟图像视野并且尽可能透明。此外,希望具有在多个焦平面(例如,两个或更多个)中呈现虚拟图像信息的配置,以便在不超过辐辏调节失配的可接受容限的情况下适用于广泛用例。参考图8,示出了增强现实系统,其特征在于头戴式查看组件(2)、手持控制器组件(4)和互连的辅助计算或控制器组件(6),其可被配置为作为用户的腰包等佩戴。这些组件中的每一个组件可以经由有线或无线通信配置(诸如由ieee 802.11、蓝牙(rtm)和其它连接标准和配置指定的那些配置)彼此可操作地耦合(10、12、14、16、17、18)并耦合到其它连接的资源(8),诸如云计算或云存储资源。如例如在美国专利申请序列号14/555,585、14/690,401、14/331,218、15/481,255、62/627,155、62/518,539、16/229,532、16/155,564、15/413,284、16/020,541、62,702,322、62/206,765、15,597,694、16/221,065、15/968,673、62/682,788和62/899,678中所述,其中的每一个都通过引用以其整体并入本文,描述了这种组件的各个方面,诸如两个所描绘的光学元件(20)的各种实施例,用户可以通过该光学元件(20)连同可以由相关联的系统组件产生的视觉组件一起看到他们周围的世界,以用于增强的现实体验。如图8中所示,这种系统还可以包括各种传感器,该传感器被配置为提供与用户周围环境有关的信息,包括但不限于各种相机类型的传感器(诸如单色、彩色/rgb和/或热成像组件)(22、24、26)、深度相机传感器(28)和/或诸如麦克风的声音传感器(30)。需要紧凑且持久连接的可穿戴计算系统和组件,诸如在此所述的那些,它们可用于向用户提供丰富的增强现实体验的感知。
技术实现要素:
5.本文档描述了可称为“深度中间端匹配器”的某些方面,神经网络被配置为通过联合查找对应关系并拒绝不可匹配的点来匹配两组局部特征。这种神经网络配置可以与诸如图8中所示的空间计算资源相关联地使用,包括但不限于包括这种空间计算系统的相机和处理资源。在深度中间端匹配器类型的配置内,可以通过解决最优传输问题来估计分配,其成本由图形神经网络预测。我们描述了一种基于注意力的灵活上下文聚合机制,它使深度中间端匹配器配置能够共同推理底层3d场景和特征分配。与传统的手工设计启发式方法相比,我们的技术通过从图像到对应关系的端到端训练来学习3d世界的几何变换和规律性的
先验。深度中间端匹配器优于其它学习方法,并在具有挑战性的真实世界室内和室外环境中的姿态估计任务上设置了新的最先进技术。这些方法和配置在现代的图形处理单元(“gpu”)上实时匹配,并且可以很容易地集成到现代的运动恢复结构(“sfm”)或同时定位和地图构建(“slam”)系统中,所有这些都可以合并到如图8中所示的系统中。
6.本发明提供一种计算机系统,包括计算机可读介质、连接到计算机可读介质的处理器和计算机可读介质上的一组指令。该组指令可以包括深度中间端匹配器架构,该深度中间端匹配器架构可以包括注意力图神经网络,该注意力图神经网络具有关键点编码器以用于将关键点位置p及其视觉描述符d映射到单个向量中,以及交替自注意力层和交叉注意力层,该自注意力层和交叉注意力层基于向量被重复l次以创建表示f;以及最优匹配层,其从表示f创建m
×
n分数矩阵,并基于m
×
n分数矩阵找到最优部分分配。
7.计算机系统可以进一步包括在关键点编码器中,每个关键点i的初始表示
(0)
xi结合视觉外观和位置,其中相应关键点位置嵌入到具有多层感知器(mlp)的高维向量中,如下:
8.(0)
xi=di mlp(pi).。
9.计算机系统可以进一步包括关键点编码器,其允许注意力图神经网络联合推理外观和位置。
10.计算机系统可以进一步包括在关键点编码器中的具有单个完整图的多路图神经网络,该完整图具有作为两个图像的关键点的节点。
11.该计算机系统可以进一步包括图是多路图,该多路图具有两种类型的无向边,即将关键点i连接到同一图像内的所有其它关键点的图像内边(自身边;e
self
)以及将关键点i连接到另一图像中的所有关键点的图像间边(交叉边,e
cross
),并使用消息传递公式沿两种类型的边传播信息,使得所得的多路图神经网络从每个节点的高维状态开始,并通过同时聚合横跨所有节点的所有给定边的消息,在每一层处计算更新的表示。
12.计算机系统可以进一步包括如果
(l)
x
ai
是在第l层的图像a中的元素i的中间表示,则消息me→i是来自所有关键点{j:(i,j)∈e}的聚合的结果,其中e∈{e
self
,e
cross
},并且a中所有i的剩余消息传递更新为:
[0013][0014]
其中[
·
||
·
]表示级联。
[0015]
计算机系统可以进一步包括具有不同参数的固定数量的层l被链接并且交替地沿着自身边和交叉边聚合,使得从l=1开始,如果l是奇数,则e=e
self
,并且如果l是偶数,则e=e
cross
。
[0016]
计算机系统可以进一步包括交替的自注意力层和交叉注意力层采用注意力机制计算,其计算消息me→i并执行聚合,其中,自身边基于自注意力并且交叉边基于交叉注意力,其中,对于i的表示,查询qi基于一些元素的属性(键kj)取得这些元素的值vj,并将消息计算为值的加权平均值:
[0017][0018]
计算机系统可以进一步包括注意力掩码α
ij
是基于键查询相似性的softmax:
[0019][0020]
计算机系统可以进一步包括将相应的键、查询和值计算为图形神经网络的深度特征的线性投影,其中查询关键点i在图像q中并且所有源关键点在图像s中,(q,s)∈{a,b}2,在方程中:
[0021][0022][0023]
计算机系统可以进一步包括交替的自注意力层和交叉注意力层的最终匹配描述符是线性投影:
[0024][0025]
计算机系统可以进一步包括最优匹配层将集合的成对分数表达为匹配描述符的相似性:
[0026][0027]
其中《
·
,
·
》是内积。与学习到的视觉描述符相反,匹配描述符没有被归一化,并且它们的大小可以每特征以及在训练期间改变,以反映预测置信度。
[0028]
计算机系统可以进一步包括用于遮挡和可见性的最优匹配层抑制被遮挡的关键点,并且采用垃圾箱(dustbin)分数扩充每组关键点,使得将不匹配的关键点明确分配给垃圾箱分数。
[0029]
计算机系统可以进一步包括通过添加采用单个可学习参数填充的新的行和列、点到箱和箱到箱的分数,将分数s扩充到s:
[0030][0031]
计算机系统可以进一步包括最优匹配层使用sinkhorn算法t次迭代基于m
×
n分数矩阵找到最优部分分配。
[0032]
计算机系统可以进一步包括在t次迭代之后,最优匹配层丢弃垃圾箱分数并且恢复p=p-1:m,1:n
,其中
[0033]
p1n≤1m并且
[0034]
是原始分配并且
[0035]
并且
[0036]
是具有扩充的垃圾箱分数的分配。
[0037]
本发明还提供了一种计算机实现的方法系统,该方法系统可以包括采用深度中间端匹配器架构的注意力图神经网络的关键点编码器,将关键点位置p及其视觉描述符d映射到单个向量;以及采用深度中间端匹配器架构的注意力图神经网络的交替自注意力层和交
叉注意力层,基于向量执行重复l次以创建表示f;以及执行深度中间端匹配器架构的注意力图神经网络的最优匹配层,以从表示f创建m
×
n分数矩阵,并基于m
×
n分数矩阵找到最优部分分配。
附图说明
[0038]
参考附图以示例的方式进一步描述本发明,在附图中:
[0039]
图1是示出采用深度中间端匹配器的特征匹配的代表性草图;
[0040]
图2示出由深度中间端匹配器针对两个困难的室内图像对所估计的对应关系;
[0041]
图3是示出我们如何制定深度中间端匹配器来解决优化问题的代表性草图;
[0042]
图4是将掩模显示为射线的图像;
[0043]
图5是示出室内和室外姿态估计的图形;
[0044]
图6示出定性图像匹配;
[0045]
图7示出在不同层和头部的自注意力掩码和交叉注意力掩码中的可视化注意力;以及
[0046]
图8示出增强现实系统。
具体实施方式
[0047]
找出图像中的点之间的对应关系是处理3d重建或视觉定位(诸如同时定位和地图构建(slam)和运动恢复结构(sfm))的计算机视觉任务的重要步骤。它们在匹配局部特征(该过程称为数据关联)后从这种对应关系中估计3d结构和相机姿态。诸如大视点变化、遮挡、模糊和缺乏纹理的因素使得2d到2d数据关联特别具有挑战性。
[0048]
在本描述中,我们提出了一种思考特征匹配问题的新方式。我们建议使用北称为深度中间端匹配器(dmem)的新型神经架构从预先存在的局部特征中学习匹配过程,而不是学习更好的与任务无关的局部特征然后再进行简单的匹配启发式方法和技巧。在通常将问题分解为视觉特征检测前端和捆绑包调节或姿态估计后端的slam上下文中,我们的网络直接位于中间——深度中间端匹配器是可学习的中间端。图1示出采用深度中间端匹配器的特征匹配。我们的方法在具有挑战性的图像对之间建立了逐点对应关系。它采用现成的局部特征作为输入,并使用注意力图神经网络来解决分配优化问题。深度中间端匹配器充当中间端,并且优雅地处理部分点可见性和遮挡,产生部分分配矩阵。
[0049]
在这项工作中,学习特征匹配被视为找到两组局部特征之间的部分分配。我们通过解决线性分配问题重新审视经典的基于图的匹配策略,当放松到最优传输问题时,可以区分地解决[参见下面的参考文献50、9、31]。该优化的成本函数由图神经网络(gnn)预测。受transformer成功启发[参见下面的参考文献48],它使用自我(图像内)和交叉(图像间)注意力来利用关键点的空间关系及其视觉外观。该公式强化了预测的分配结构,同时能够学习复杂的先验,优美地处理遮挡和不可重复的关键点。我们的方法是从图像到对应关系的端到端训练——我们从大型带注释的数据集中学习姿态估计的先验,使深度中间端匹配器能够推理3d场景和分配。我们的工作可以应用于需要高质量特征对应关系的各种多视图几何问题。
[0050]
我们示出深度中间端匹配器与手工匹配器和学习内点分类器相比的优越性。图2
示出由深度中间端匹配器针对两个困难的室内图像对所估计的对应关系。深度中间端匹配器成功地估计准确的姿态,而其它学习或手工的方法失败(绿色的正确对应关系)。当与深度前端superpoint[参见下面的参考文献14]结合使用时,所提出的方法带来了最实质性的改进,从而推进单应性估计和室内外姿态估计任务的最新技术,并为深度slam铺平道路。
[0051]
2.相关工作
[0052]
局部特征匹配通常通过以下方式执行:i)检测兴趣点,ii)计算视觉描述符,iii)将这些与最近邻(nn)搜索进行匹配,iv)过滤不正确的匹配,并且最后v)估计几何变换。2000年代开发的经典管道通常基于sift[参见下面的参考文献25]、具有lowe比率测试的过滤匹配项[参见下面的参考文献25]、交叉检查和启发式算法,如邻域共识[参见下面的参考文献46、8、5、40],并采用如ransac的稳健求解器找到转换[参见下面的参考文献17、35]。
[0053]
最近关于用于匹配的深度学习的工作通常集中在使用卷积神经网络(cnn)从数据中学习更好的稀疏检测器和局部描述符[参见下面的参考文献14、15、29、37、54]。为了提高它们的辨别力,一些工作使用区域特征[参见下面的参考文献26]或对数极坐标补丁[参见下面的参考文献16]明确地关注更广泛的上下文。其它方法通过将匹配分类为内点和异常点来学习过滤匹配项[参见下面的参考文献27、36、6、56]。这些对仍然由nn搜索估计的匹配集进行操作,并且因此忽略分配结构并丢弃视觉信息。迄今为止,实际学习匹配的工作主要集中在密集匹配[参见下面的参考文献38]或3d点云[参见下面的参考文献52],并且仍然表现出这种局限性。相比之下,我们的可学习中间端在单个端到端架构中同时执行上下文聚合、匹配和过滤。
[0054]
图匹配问题通常被表述为二次分配问题,其是np困难的,需要昂贵、复杂且因此不切实际的求解器[参见下面的参考文献24]。对于局部特征,2000年代的计算机视觉文献[参见下面的参考文献4、21、45]使用具有许多启发式方法的手工成本,使其复杂且脆弱。caetano等人[参见下面的参考文献7]学习更简单的线性分配的优化成本,但只使用浅层模型,而我们的深度中间端匹配器使用神经网络学习灵活的成本。与图匹配相关的是最优传输问题[参见下面的参考文献50]——它是一种广义线性分配,具有高效而简单的近似解,即sinkhorn算法[参见下面的参考文献43、9、31]。
[0055]
诸如点云的集合的深度学习旨在通过聚合跨元素的信息来设计置换等变或不变函数。有些工作通过全局池化[参见下面的参考文献55、32、11]或实例归一化[参见下面的参考文献47、27、26]平等对待所有这些问题,而另一些则关注坐标或特征空间中的局部邻域[参见下面的参考文献33,53]。注意力[参见下面的参考文献48、51、49、20]可以通过关注特定元素和属性来执行全局和数据相关的局部聚合,并且因此更加灵活。我们的工作使用了这样的事实,即它可以被视为完整图上的消息传递图神经网络的特定实例[参见下面的参考文献18、3]。通过将注意力应用于多边或多路图,类似于[参见下面的参考文献22、57],深度中间端匹配器可以学习关于两组局部特征的复杂推理。
[0056]
3.深度中间端匹配器架构
[0057]
动机:在图像匹配问题中,可以利用世界的一些规律性:3d世界在很大程度上是平滑的并且有时是平面的,如果场景是静态的,则给定图像对的所有对应关系都来自单个对极变换,并且一些姿态比其它姿态更有可能。此外,2d关键点通常是突出的3d点的投影,如角点或斑点,因此横跨图像的对应关系必须遵守某些物理约束:i)关键点在另一图像中至
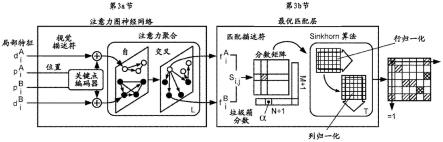
多可具有单个对应关系;以及ii)由于检测器的遮挡和故障,一些关键点将不匹配。有效的特征匹配模型应该旨在找到相同3d点的重投影之间的所有对应关系,并识别没有匹配的关键点。图3示出我们如何将深度中间端匹配器制定为解决优化问题,其成本由深度神经网络预测。深度中间端匹配器由两个主要部分组成:注意力图神经网络(第3a节)和最优匹配层(第3b节)。第一组件使用关键点编码器将关键点位置p及其视觉描述符d映射到单个向量中,并且然后使用交替的自注意力层和交叉注意力层(重复l次)来创建更强大的表示f。最优匹配层创建m
×
n分数矩阵,用垃圾箱对其进行扩充,然后使用sinkhorn算法(用于t次迭代)找到最优部分分配。这减轻了对领域专业知识和启发式方法的需求——我们直接从数据中学习相关的先验。
[0058]
公式化:考虑两个图像a和b,每个图像具有一组关键点位置p和相关联的视觉描述符d——我们将它们联合称为局部特征(p,d)。关键点由x和y图像坐标以及检测置信度c组成,pi:=(x,y,c)i。视觉描述符di∈rd可以是由如superpoint的cnn或如sift的传统描述符提取的那些视觉描述符。图像a和b具有m和n个局部特征,并且它们的关键点索引集分别是a:={1,...,m}和b:={1,...,n}。
[0059]
部分分配:约束i)和ii)意味着对应关系源自两组关键点之间的部分分配。为了集成到下游任务和更好的可解释性,每个可能的对应关系都应该具有置信度值。因此,我们将部分软分配矩阵p∈[0,1]m×n定义为:
[0060]
p1n≤1m并且
[0061]
我们的目标如下:设计从两组局部特征预测分配p的神经网络。
[0062]
3.1.注意力图神经网络
[0063]
深度中间端匹配器的第一主要块(参见第3a节)是注意力图神经网络,其工作如下:给定初始局部特征,通过让特征彼此通信来计算匹配描述符。远程特征通信对于稳健匹配至关重要,并且需要从图像内以及跨图像对的信息聚合。
[0064]
直观地说,关于给定关键点的独特信息取决于其视觉外观和其位置,还取决于其相对于其它共同可见关键点(例如相邻的或突出的关键点)的空间和视觉关系。另一方面,第二图像中关键点的知识可以通过比较候选匹配或从全局和明确线索估计相对光度或几何变换来帮助解决模糊性。
[0065]
当被要求匹配给定的模糊关键点时,人类来回查看两个图像:他们筛选试探性匹配关键点,检查它们中的每一个,并寻找有助于区分真实匹配与其它自相似性的上下文线索。这暗示可以将其注意力集中在特定位置的迭代过程。
[0066]
关键点编码器:每个关键点i的初始表示
(0)
xi结合了视觉外观和位置。我们采用多层感知器(mlp)将关键点位置嵌入到高维向量中,如下:
[0067]
(0)
xi=di mlp(pi).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0068]
编码器允许网络共同推理外观和位置(这对于注意力机制特别强大),并且是transformer中引入的“位置编码器”的实例[参见下面的参考文献48]。
[0069]
多路图神经网络:我们考虑单个完整图,其节点是两个图像的关键点。该图具有两种类型的无向边——它是多路图。图像内边或自身边e
self
将关键点i连接到同一图像内的所有其它关键点。图像间边或交叉边e
cross
将关键点i连接到另一图像中的所有关键点。我们
使用消息传递公式[参见下面的参考文献18、3]沿两种类型的边传播信息。所得的多路图神经网络从每个节点的高维状态开始,并通过同时聚合横跨所有节点的所有给定边的消息,在每一层计算更新的表示。
[0070]
令
(l)
x
ai
为第l层处的图像a中元素i的中间表示。消息me→i是来自所有关键点{j:(i,j)∈e}的聚合的结果,其中e∈{e
self
,e
cross
}。a中所有i的剩余消息传递更新为:
[0071][0072]
其中[
·
||
·
]表示级联。可以同时对图像b中的所有关键点执行类似的更新。具有不同参数的固定数量的层l被链接,并且交替地沿着自身边和交叉边聚合。因此,从l=1开始,如果l是奇数,则e=e
self
,并且如果l是偶数,则e=e
cross
。
[0073]
注意力聚合:注意力机制计算消息me→i并执行聚合。自身边基于自注意力[参见下面的参考文献48],而交叉边基于交叉注意力。类似于数据库取得,对于i的表示,查询qi基于某些元素的属性(键kj)取得这些元素的值vj。我们将消息计算为值的加权平均值:
[0074][0075]
其中注意力掩码α
ij
是键查询相似性上的softmax:
[0076][0077]
键、查询和值被计算为图神经网络的深度特征的线性投影。考虑到查询关键点i在图像q中,并且所有源关键点在图像s中,(q,s)∈{a,b}2,我们可以写:
[0078][0079][0080]
每个层l具有其自己的投影参数,并且它们对于两个图像的所有关键点都是共享的。在实践中,我们通过多头注意力来提高表达能力[参见下面的参考文献48]。
[0081]
我们的公式提供了最大的灵活性,因为网络可以学习基于特定属性关注关键点的子集。在图4中,掩模α
ij
示为射线。注意力聚合在关键点之间构建动态图。自注意力(顶部)可以关注同一图像中的任何位置,例如,独特的位置,并且因此不限于附近的位置。交叉注意力(底部)关注另一图像中的位置,诸如具有相似局部外观的潜在匹配。深度中间端匹配器可以基于外观和关键点位置二者取得或参与,因为它们在表示xi中编码。这包括关注附近的关键点并取得相似或突出关键点的相对位置。这使得几何变换和分配的表示成为可能。最终的匹配描述符是线性投影:
[0082][0083]
对于b中的关键点是类似的。
[0084]
3.2.最优匹配层
[0085]
深度中间端匹配器的第二主要块(参见第3b节)是最优匹配层,其产生部分分配矩
阵。与标准图匹配公式一样,分配p可以通过计算所有可能匹配的分数矩阵s∈rm×n并在方程1中的约束条件下最大化总分数来获得。这相当于解决线性分配问题。
[0086]
分数预测:针对所有(m 1)
×
(n 1)个潜在匹配建立单独的表示将是禁止性的。相反,我们将成对分数表达为匹配描述符的相似性:
[0087][0088]
其中《
·
,
·
》是内积。与学习到的视觉描述符相反,匹配描述符没有被归一化,并且它们的大小可以每特征以及在训练期间改变,以反映预测置信度。
[0089]
遮挡和可见性:为了让网络抑制遮挡的关键点,我们采用垃圾箱扩充每个集合,使得将不匹配的关键点显式分配给它。该技术在图匹配中很常见,并且superpoint[参见下面的参考文献14]也使用垃圾箱来处理可能没有检测到的图像单元。我们通过添加新的行和列、点到箱和箱到箱分数,采用单个可学习参数填充,将分数s扩充到s-:
[0090][0091]
虽然a中的关键点将被分配给b中的单个关键点或垃圾箱,但每个垃圾箱具有与另一组中的关键点一样多的匹配:n、m分别用于a、b中的垃圾箱。我们将a和b中每个关键点和垃圾箱的预期匹配数表示为并且扩充分配现在具有约束:
[0092]
并且
[0093]
sinkhorn算法:上述优化问题的解决方案对应于具有分数s-的离散分布a和b之间的最优传输[参见下面的参考文献31]。可以采用sinkhorn算法[参见下面的参考文献43、9]来近似求解,这是hungarian算法的可微分版本[参见下面的参考文献28],经典地用于二分匹配。它解决了正则化传输问题,自然导致软分配。该归一化相当于沿行和列迭代地执行交替的softmax,并且因此很容易在gpu上并行化。在t次迭代之后,我们丢弃垃圾箱并恢复p=p-1:m,1:n
。
[0094]
3.3.损失
[0095]
通过设计,图神经网络和最优匹配层二者都是可微分的——这使得从匹配到视觉描述符的反向传播成为可能。深度中间端匹配器以监督方式从基础事实匹配进行训练。这些是根据基础事实相对变换估计的——使用姿态和深度图或单应性。如果它们附近没有任何重投影,这也让我们可以将一些关键点和标记为不匹配。给定标签,我们最小化分配p-的负对数似然:
[0096][0097]
该监督旨在同时最大化匹配的精度和召回率。
[0098]
3.4.与相关工作的比较
[0099]
深度中间端匹配器对比内部分类器[参见下面的参考文献27、56]:深度中间端匹配器通过关于图像和局部特征二者完全置换等变而受益于强归纳偏差。它另外将常用的相互检查约束直接嵌入到训练中:概率p
i,j
大于0.5的任何匹配必然是相互一致的。
[0100]
深度中间端匹配器对比实例归一化[参见下面的参考文献47]:如深度中间端匹配器使用的注意力是一种比实例归一化更灵活和强大的上下文聚合机制,它平等地对待所有关键点并且被以前的特征匹配工作使用[参见下面的参考文献27、56、26]。
[0101]
深度中间端匹配器对比contextdesc[参见下面的参考文献26]:深度中间端匹配器可以共同推理外观和位置,而contextdesc分别处理它们。此外,contextdesc是前端,其另外需要更大的区域提取器,以及关键点评分的损失。深度中间端匹配器只需要学习或手工的局部特征,并且因此可以简单地随时替代现有匹配器。
[0102]
深度中间端匹配器对比transformer[参见下面的参考文献48]:深度中间端匹配器借用了transformer的自注意力,但将其嵌入到图神经网络中并另外引入了对称的交叉注意力。这简化了架构并导致更好的跨层重用特征。
[0103]
4.实现方式细节
[0104]
深度中间端匹配器可以与任何局部特征检测器和描述符组合,但与superpoint[参见下面的参考文献14]一起工作特别好,它产生可重复和稀疏的关键点——实现非常有效的匹配。视觉描述符是从可微分的半密集特征图中双线性采样的。局部特征提取和随后的“粘合”二者都直接在gpu上执行。在测试时,为了从软分配中提取匹配,可以使用置信度阈值来保留一些,或者在后续步骤(诸如加权姿态估计)中简单地使用所有匹配及其置信度。
[0105]
架构细节:所有中间表示(键、查询值、描述符)具有与superpoint描述符相同的维度d=256。我们使用l=9层交替的多头自注意力和交叉注意力,每层具有4个头,并在对数空间中执行t=100次sinkhorn迭代以实现数值稳定性。该模型在pytorch[参见下面的参考文献30]中实现,并在gpu上实时运行:前向传递平均需要150ms(7fps)。
[0106]
训练细节:为了允许数据扩充,superpoint检测和描述步骤作为训练期间的批次即时执行。进一步添加了许多随机关键点,以实现高效的批处理和增强的鲁棒性。附录a中提供了更多详细信息。
[0107]
5.实验
[0108]
5.1.单应性估计
[0109]
我们采用鲁棒(ransac)和非鲁棒(dlt)估计器使用真实图像和合成单应性执行大规模单应性估计实验。
[0110]
数据集:我们通过采样随机单应性并将随机光度失真应用到真实图像来生成图像
对,遵循类似于[参见下面的参考文献12、14、37、36]的配方。底层图像来自牛津和巴黎数据集[参见下面的参考34]中的100万张干扰图像集,其被分为训练集、验证集和测试集。
[0111]
基线:我们将深度中间端匹配器与应用于superpoint局部特征的几个匹配器进行比较——最近邻(nn)匹配器和各种异常值拒绝器:相互检查(或交叉检查)、pointcn[参见下面的参考文献27]和order-aware网络(oanet)[参见下面的参考文献56]。所有学习的方法,包括深度中间端匹配器,都在基础事实对应关系上进行训练,通过将关键点从一个图像投影到另一图像来找到。我们即时生成单应性和光度失真——在训练期间,一个图像对从未出现过两次。
[0112]
度量:匹配精度(p)和召回率(r)是根据基础事实对应关系计算的。采用ransac和直接线性变换[参见下面的参考文献19](dlt)二者执行单应性估计,后者具有直接最小二乘解。我们计算图像四个角的平均重投影误差,并报告至多10个像素值的累积误差曲线(auc)下的面积。
[0113]
结果:深度中间端匹配器具有足够的表现力来掌握单应性,实现98%的召回率和高精度。表1示出深度中间端匹配器、dlt和ransac的单应性估计。深度中间端匹配器恢复了几乎所有可能的匹配,同时抑制了大多数异常值。由于深度中间端匹配器对应关系是高质量的直接线性变换(dlt),一种没有鲁棒性机制的基于最小二乘的优于ransac的解决方案。估计的对应关系非常好,以至于不需要稳健的估计器——深度中间端匹配器在dlt上的工作甚至比ransac更好。如pointcn和oanet的异常值拒绝方法无法预测比nn匹配器本身更正确的匹配,过度依赖初始描述符。
[0114][0115][0116]
表1
[0117]
5.2.室内姿态估计
[0118]
由于缺乏纹理、丰富的自相似性、场景的复杂3d几何形状以及大的视点变化,室内图像匹配非常具有挑战性。正如我们在下面所示的,深度中间端匹配器可以有效地学习先验来克服这些挑战。
[0119]
数据集:我们使用scannet[参见下面的参考文献10],这是大规模的室内数据集,由具有基础事实姿态和深度图像的单目序列以及与不同场景对应的明确定义的训练、验证和测试分割组成。过去的工作基于时间差[参见下面的参考文献29、13]或sfm共可见性[参见下面的参考文献27、56、6]选择训练和评估对,通常使用sift计算。我们认为这限制了对的难度,而是基于仅使用基础事实姿态和深度为给定序列中所有可能的图像对计算的重叠分数来选择这些对。这导致了明显更宽的基线对,其对应于真实世界室内图像匹配的当前
前沿。丢弃重叠过小或过大的对,我们获得2.3亿个训练对并对1500个测试对采样。附录a中提供了更多详细信息。
[0120]
度量:与以前的工作一样[参见下面的参考文献27、56、6],我们报告了阈值(5
°
、10
°
、20
°
)处的姿态误差的auc,其中姿态误差是旋转和平移的角度误差。采用ransac从基本矩阵估计中获得相对姿态。我们还报告了匹配精度和匹配分数[参见下面的参考文献14、54],其中基于其对极距离认为匹配是正确的。
[0121]
基线:我们使用根归一化sift[参见下面的参考文献25、2]和superpoint[参见下面的参考文献14]特征二者来评估深度中间端匹配器和各种基线匹配器。深度中间端匹配器采用从基础事实姿态和深度派生的对应关系和不匹配的关键点进行训练。所有基线都基于最近邻(nn)匹配器和可能的异常值拒绝方法。在“手工”类别中,我们考虑了简单的交叉检查(相互)、比率测试[参见下面的参考文献25]、描述符距离阈值和更复杂的gms[参见下面的参考文献5]。“学习”类别中的方法是pointcn[参见下面的参考文献27],及其后续oanet[参见下面的参考文献56]和ng-ransac[参见下面的参考文献6]。我们使用上述定义的正确性标准及其相应的回归损失在scannet上针对具有分类损失的superpoint和sift二者重新训练pointcn和oanet。对于ng-ransac,我们使用原始的训练模型。我们不包括任何图匹配方法,因为它们对于我们考虑的关键点数量来说太慢了几个数量级。我们报告其它局部特征作为参考:orb[参见下面的参考文献39]与gms、d2-net[参见下面的参考文献15]和使用公开可用的训练模型的contextdesc[参见下面的参考文献26]。
[0122]
结果:与手工匹配器和学习匹配器相比,深度中间端匹配器实现了显著更高的姿态准确度。表2示出scannet上的宽基线室内姿态估计。我们报告姿态误差的auc、匹配分数(ms)和精度(p),所有这些都以姿态估计auc百分比表示。当应用于sift和superpoint二者时,深度中间端匹配器优于所有手工和学习匹配器。当应用于sift和superpoint二者时,这些益处是巨大的。图5示出室内和室外姿态估计。与最先进的异常值拒绝神经网络oanet相比,深度中间端匹配器显著提高了姿态精度。它具有比其它学习匹配器显著更高的精度,展示了其更高的表示能力。它还产生了更多数量的正确匹配——当应用于sift时,它比比率测试高出至多10倍,因为它对所有可能的匹配进行操作,而不是对有限的最近邻集进行操作。superpoint和深度中间端匹配器一起在室内姿态估计方面取得了最先进的结果。它们彼此补充,因为即使在非常具有挑战性的情况下,可重复的关键点也可以估计更多数量的正确匹配-参见图2。
[0123]
[0124][0125]
表2
[0126]
在图6中示出定性图像匹配。我们在三种环境中将深度中间端匹配器与最近邻(nn)匹配器进行比较,其中包含手工和学习的两个异常值拒绝器。深度中间端匹配器始终估计更正确的匹配(绿线)和更少的不匹配(红线),以应对重复的纹理、大视点和照明变化。
[0127]
5.3.户外姿态估计
[0128]
由于室外图像序列呈现出它们自己的一组挑战(例如,光照变化和遮挡),我们训练和评估深度中间端匹配器以在室外设定中进行姿态估计。我们使用与室内姿态估计任务相同的评估度量和基线方法。
[0129]
数据集:我们对phototourism数据集进行评估,该数据集是cvpr'19图像匹配挑战的一部分[参见下面的参考文献1]。它是yfcc100m数据集的一个子集[参见下面的参考文献44],并且具有从现成的sfm工具获得的基础事实姿态和稀疏3d模型[参见下面的参考文献29、41、42]。对于训练,我们使用megadepth数据集[参见下面的参考文献23],其还具有采用多视图立体计算的干净深度图。位于phototourism测试集中的场景将从训练集中移除。
[0130]
结果:表3示出对phototourism数据集的户外姿态估计。将superpoint和sift特征与深度中间端匹配器相匹配,与手工或其它学习方法相比,可以产生显著更高的姿态准确度(auc)、精度(p)和匹配分数(ms)。当应用于superpoint和sift二者时,深度中间端匹配器在所有相对姿态阈值处都优于所有基线。最值得注意的是,最终匹配的精度非常高(84.9%),这强化了深度中间端匹配器“粘合”局部特征的类比。
[0131][0132]
表3
[0133]
5.4.了解深度中间端匹配器
[0134]
消融研究:为了评估我们的设计决策,我们重复了室内scannet实验,但这次关注的是不同的深度中间端匹配器变体。表4示出具有super-point局部特征的scannet上深度中间端匹配器的消融。所有深度中间端匹配器块都是有用的,并带来了可观的性能提升。示出了相对于完整模型的差异。虽然最优匹配层单独改进了基线最近邻匹配器,但gnn解释了由深度中间端匹配器带来的大部分增益。交叉注意力和位置编码对于强粘合都至关重要,而更深的网络进一步提高了精度。
[0135][0136]
表4
[0137]
可视化注意力:在没有尝试在整个匹配中可视化深度中间端匹配器的注意力模式的情况下,对所提出的技术的理解将是不完整的。自注意力模式和交叉注意力模式的广泛多样性在图7中示出,并且反映了学习行为的复杂性。图7示出可视化注意力:自注意力和交叉注意力在各个层和头部掩盖了α
ij
。深度中间端匹配器学习多种模式,并且可以专注于全局或局部上下文、自相似性、独特特征和匹配候选者。
[0138]
6.结论
应允许包含任何附加元素——无论在这种权利要求中是否列举了给定数量的元素,或者特征的添加可以被认为是改变了这种权利要求中阐述的元素的性质。除本文特别定义外,在此使用的所有技术和科学术语都应尽可能广泛地赋予普遍理解的含义,同时保持权利要求的有效性。
[0147]
本发明的广度不限于所提供的示例和/或主题说明,而是仅受限于与本公开相关联的权利要求语言的范围。
[0148]
7.附录a-进一步的实验细节
[0149]
单应性估计:
[0150]
测试集包含1024对640
×
480图像。通过对原始全尺寸图像应用随机透视、缩放、旋转和平移来生成单应性,以避免边界伪影。我们采用由superpoint检测到的512个分数最高的关键点进行评估,其中非最大抑制(nms)半径为4像素。如果对应关系的重投影误差低于3个像素,则认为对应关系是正确的。在采用ransac估计单应性时,我们使用具有3000次迭代和3个像素的内部阈值的opencv函数寻找单应性。
[0151]
室内姿态估计:
[0152]
在考虑了缺失的深度值和遮挡(通过使用相对误差检查深度的一致性)之后,两个图像a和b之间的重叠分数是a中的像素在b中可见的平均比率(反之亦然)。我们以0.4到0.8的重叠范围进行训练和评估。对于训练,我们在每个时期每个场景采样200对,类似于文献[15]。测试集是通过对序列进行15次抽样并随后对300个序列中的每一个序列抽样15对来生成的。我们将所有scannet图像和深度图调整尺寸为vga 640
×
480。我们检测到至多1024个superpoint关键点(使用nms半径为4的公开可用训练模型)和2048个sift关键点(使用opencv的实现方式)。在计算精度和匹配分数时,我们使用5.10e-4的对极阈值。通过首先使用opencv的findessentialmat和ransac估计基本矩阵来计算姿态,其中内点阈值为1像素除以平均焦距,然后是恢复姿态。与之前的工作[28,59,6]相比,我们使用显式积分而不是粗直方图来计算更准确的auc。
[0153]
室外姿态估计:
[0154]
对于megadepth上的训练,重叠分数是在两个图像中可见的三角剖分关键点的比率,如[15]中所示。我们在每个时期对具有[0.1,0.7]重叠分数的对进行采样。对于phototourism数据集的评估,我们使用所有11个场景和ono[30]计算的重叠分数,选择范围为[0.1,0.4]。重新调整图像大小,使其最长边小于1600像素。我们检测了sift和superpoint二者的2048个关键点(nms半径为3)。其它评估参数与室内评估中使用的参数相同。
[0155]
深度中间端匹配器的训练:
[0156]
对于单应性/室内/室外数据的训练,我们使用adam优化器,前200000/100000/50000次迭代的初始恒定学习率为10e-4,然后以指数衰减0.999998/0.999992/0.999992直到迭代900000次。在使用superpoint特征时,我们采用具有32/64/16个图像对和每图像固定数量的512/400/1024个关键点的批次。当使用sift特征时,我们使用1024个关键点和24对。由于有限数量的训练场景,室外模型采用单应性模型进行初始化。在关键点编码之前,关键点通过图像的最大边进行归一化。
[0157]
通过使用基础事实单应性或姿态和深度图首先计算所有检测到的关键点之间的m
×
n重投影矩阵来生成基础事实对应关系m和未匹配集i和j。对应关系是具有沿行和列二者的最小重投影误差且低于给定阈值的单元:单应性、室内和室外匹配分别为3、5和3个像素。对于单应性,未匹配的关键点只是那些没有出现在m中的关键点。对于室内和室外匹配,由于深度和姿态的误差,未匹配的关键点必须另外具有分别大于15和5个像素的最小重投影误差。这允许忽略其对应关系不明确的关键点的标签,同时仍然通过sinkhorn归一化提供某种监督。
[0158]
8.参考文献
[0159]
以下参考文献中的每一个都通过引用整体并入本文,并在上述描述中引用:
[0160]
[1]phototourism challenge,cvpr 2019image matching workshop.https://image matching-workshop.github.io.2019年11月8日访问.7
[0161]
[2]reljaand andrew zisserman.three things everyone should know to improve object retrieval.in cvpr,2012.6
[0162]
[3]peter w battaglia,jessica b hamrick,victor bapst,alvaro sanchez-gonzalez,vinicius zambaldi,mateusz malinowski,andrea tacchetti,david raposo,adam santoro,ryan faulkner,et al.relational inductive biases,deep learning,and graph networks.arxiv:1806.01261,2018.2,3
[0163]
[4]alexander c berg,tamara l berg,and jitendra malik.shape matching and object recognition using low distortion correspondences.in cvpr,2005.2
[0164]
[5]jiawang bian,wen-yan lin,yasuyuki matsushita,sai-kit yeung,tan-dat nguyen,and ming-ming cheng.gms:grid-based motion statistics for fast,ultra-robust feature correspondence.in cvpr,2017.2,6
[0165]
[6]eric brachmann and carsten rother.neural-guided ransac:learning where to sample model hypotheses.in iccv,2019.2,6
[0166]
[7]tib
é
rio s caetano,julian j mcauley,li cheng,quoc v le,and alex j smola.learning graph matching.ieee tpami,31(6):1048
–
1058,2009.2
[0167]
[8]jan cech,jiri matas,and michal perdoch.efficient sequential correspondence selection by cosegmentation.ieee tpami,32(9):1568
–
1581,2010.2
[0168]
[9]marco cuturi.sinkhorn distances:lightspeed computation of optimal transport.in nips,2013.1,2,4
[0169]
[10]angela dai,angel x chang,manolis savva,maciej halber,thomas funkhouser,and matthias nieβner.scannet:richly-annotated 3d reconstructions of indoor scenes.in cvpr,2017.6
[0170]
[11]haowen deng,tolga birdal,and slobodan ilic.ppfnet:global context aware local features for robust 3d point matching.in cvpr,2018.2
[0171]
[12]daniel detone,tomasz malisiewicz,and andrew rabinovich.deep image homography estimation.in rss work-shop:limits and potentials of deep learning in robotics,2016.5
[0172]
[13]daniel detone,tomasz malisiewicz,and andrew rabinovich.self-improving visual odometry.arxiv:1812.03245,2018.6
[0173]
[14]daniel detone,tomasz malisiewicz,and andrew rabinovich.superpoint:self-supervised interest point detection and description.in cvpr workshop on deep learning for visual slam,2018.2,4,5,6
[0174]
[15]mihai dusmanu,ignacio rocco,tomas pajdla,marc pollefeys,josef sivic,akihiko torii,and torsten sattler.d2-net:a trainable cnn for joint detection and description of local features.in cvpr,2019.2,6
[0175]
[16]patrick ebel,anastasiia mishchuk,kwang moo yi,pascal fua,and eduard trulls.beyond cartesian representations for local descriptors.in iccv,2019.2
[0176]
[17]martin a fischler and robert c bolles.random sample consensus:a paradigm for model fitting with applications to image analysis and automated cartography.communications of the acm,24(6):381
–
395,1981.2
[0177]
[18]justin gilmer,samuel s schoenholz,patrick f riley,oriol vinyals,and george e dahl.neural message passing for quantum chemistry.in icml,2017.2,3
[0178]
[19]richard hartley and andrew zisserman.multiple view geometry in computer vision.cambridge university press,2003.6
[0179]
[20]juho lee,yoonho lee,jungtaek kim,adam kosiorek,seungjin choi,and yee whye teh.set transformer:a frame-work for attention-based permutation-invariant neural networks.in icml,2019.2
[0180]
[21]marius leordeanu and martial hebert.a spectral technique for correspondence problems using pairwise constraints.in iccv,2005.2
[0181]
[22]yujia li,chenjie gu,thomas dullien,oriol vinyals,and pushmeet kohli.graph matching networks for learning the similarity of graph structured objects.in icml,2019.2
[0182]
[23]zhengqi li and noah snavely.megadepth:learning single-view depth prediction from internet photos.in cvpr,2018.7
[0183]
[24]eliane maria loiola,nair maria maia de abreu,paulo oswaldo boaventura-netto,peter hahn,and tania querido.a survey for the quadratic assignment problem.european journal of operational research,176(2):657
–
690,2007.2
[0184]
[25]david g lowe.distinctive image features from scale-invariant keypoints.international journal of computer vision,60(2):91
–
110,2004.2,6
[0185]
[26]zixin luo,tianwei shen,lei zhou,jiahui zhang,yao yao,shiwei li,tian fang,and long quan.contextdesc:local descriptor augmentation with cross-modality context.in cvpr,2019.2,5,6
[0186]
[27]kwang moo yi,eduard trulls,yuki ono,vincent lepetit,mathieu salzmann,and pascal fua.learning to find good correspondences.in cvpr,2018.2,5,6
bmvc,2019.
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。