1.本技术涉及自然语言处理技术领域,更具体的说,是涉及一种文本摘要生成模型训练方法、相关设备及可读存储介质。
背景技术:
2.随着互联网信息时代的到来,人们能接收到的信息越来越多,但是人们平常处理文本数据的时间有限,如何在有限的时间内接收到更多有意义的信息,文本摘要则是一个很好的解决方法。考虑到对长文本进行人工摘要生成是一个非常费时费力的工作,文本摘要自动生成显得尤为必要。
3.文本摘要自动生成即通过将长文本中重要的主旨提取出来,并生成能够表达该主旨相对较短的文本,目前可分为抽取式和生成式。抽取式是从长文本中抽取关键句和关键词组成摘要,摘要内容全部来源于原文,在语法、句法上有一定的保证,但是也可能存在内容选择错误、连贯性差、灵活性差等问题。生成式摘要根据长文本,逐字地生成摘要,其允许生成新的词语、短语,灵活性高。随着神经网络模型的发展,常常采用文本摘要生成模型用于生成式摘要任务。目前,多采用基于长短时记忆网络(lstm)的序列到序列 (seq2seq)模型作为文本摘要生成模型。
4.基于长短时记忆网络(lstm)的序列到序列(seq2seq)模型是采用有监督方法训练的,需要依赖大量的人工标注数据,而现实中人工标注数据的数量往往不足。而且,该模型是采用固定的词向量作为每个词的表达,无法解决一词多义的问题,另外,长短时记忆网络(lstm)对于长句子会存在梯度消失的问题。此外,不同类别的文本、不同语言风格的文本,其摘要内容也会存在一定差异,而该模型并未考虑到上述差异对摘要内容的影响。利用该模型生成的文本摘要精确率较低。
5.因此,如何提升生成的文本摘要的精确率,成为本领域技术人员亟待解决的技术问题。
技术实现要素:
6.鉴于上述问题,本技术提出了一种文本摘要生成模型训练方法、相关设备及可读存储介质。具体方案如下:
7.一种文本摘要生成模型训练方法,所述方法包括:
8.获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;
9.获取训练用文本;
10.基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;
11.以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述
文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
12.可选地,在所述文本摘要生成模型训练过程中:
13.所述编码层对所述训练用文本进行编码,得到所述训练用文本的编码特征向量;
14.所述交互层对所述训练用文本的编码特征向量进行解码,得到所述训练用文本的解码特征向量;
15.所述文本摘要自动生成层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测摘要,所述训练用文本的预测摘要与所述训练用文本标注的摘要标签之间的误差表征所述文本摘要自动生成层对应的损失;
16.所述文本类别自适应层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测类别,所述训练用文本的预测类别与所述训练用文本标注的类别标签之间的误差表征所述文本类别自适应层对应的损失;
17.所述文本风格自适应层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测风格,所述训练用文本的预测风格与所述训练用文本标注的风格标签之间的误差表征所述文本风格自适应层对应的损失。
18.可选地,所述训练用文本是采用如下方式确定的:
19.获取网络爬虫爬取的数据;
20.基于预设的正则表达式规则,对所述爬取的数据进行数据清洗,得到所述训练用文本。
21.可选地,所述基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签,包括:
22.利用外部平台对所述训练用文本标注的摘要、文本类别、文本风格,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签。
23.可选地,所述文本摘要生成模型中的编码层采用gpt-2网络的嵌入层实现,所述文本摘要生成模型中的交互层采用所述gpt-2网络的交互层实现;所述文本摘要生成模型中的文本类别自适应层以及文本风格自适应层采用自注意力机制实现。
24.一种文本摘要生成模型训练装置,所述装置包括:
25.文本摘要生成模型获取单元,用于获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;
26.训练用文本获取单元,用于获取训练用文本;
27.标签确定单元,用于基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;
28.训练单元,用于以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
29.可选地,所述标签确定单元,具体用于利用外部平台对所述训练用文本标注的摘要、文本类别、文本风格,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签。
30.可选地,所述文本摘要生成模型中的编码层采用gpt-2网络的嵌入层实现,所述文本摘要生成模型中的交互层采用所述gpt-2网络的交互层实现,所述文本摘要生成模型中
的文本类别自适应层以及文本风格自适应层采用自注意力机制实现。
31.一种文本摘要生成模型训练设备,包括存储器和处理器;
32.所述存储器,用于存储程序;
33.所述处理器,用于执行所述程序,实现如上所述的文本摘要生成模型训练方法的各个步骤。
34.一种可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上所述的文本摘要生成模型训练方法的各个步骤。
35.借由上述技术方案,本技术公开了一种文本摘要生成模型训练方法、相关设备及可读存储介质。获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;获取训练用文本;基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。采用上述方法训练文本摘要生成模型时,由于采用了远监督思想确定训练用文本的摘要标签、文本类别标签和文本风格标签,无需依赖人工标注数据,利用编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层组成的文本摘要生成模型可以解决基于长短时记忆网络的序列到序列模型的一词多义、梯度消失问题。而且,在训练时考虑了文本类别、文本风格对摘要内容的影响。因此,采用上述训练得到的文本摘要生成模型自动生成文本摘要,能提升生成的文本摘要的精确率。
附图说明
36.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本技术的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
37.图1为本技术实施例公开的一种文本摘要生成模型训练方法的流程示意图;
38.图2为本技术实施例公开的一种文本摘要生成模型的结构示意图;
39.图3为本技术实施例公开的文本摘要生成模型的训练及应用示意图;
40.图4为传统的gpt-2网络框架示意图;
41.图5为gpt-2网络transformer decoder layer的结构示意图;
42.图6为本技术实施例公开的一种文本摘要生成模型的结构示例图;
43.图7为本技术实施例公开的一种训练用文本的确定方法的流程示意图;
44.图8为本技术实施例公开的一种文本摘要生成模型训练装置结构示意图;
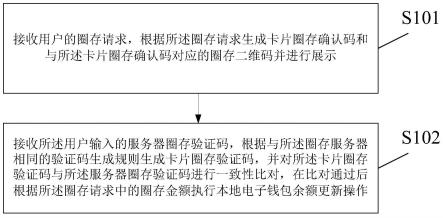
45.图9为本技术实施例公开的一种文本摘要生成模型训练设备的硬件结构框图。
具体实施方式
46.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他
实施例,都属于本技术保护的范围。
47.接下来,通过下述实施例对本技术提供的文本摘要生成模型训练方法进行介绍。
48.参照图1,图1为本技术实施例公开的一种文本摘要生成模型训练方法的流程示意图,该方法可以包括:
49.步骤s101:获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层。
50.为便于理解,请参照图2,图2为本技术实施例公开的一种文本摘要生成模型的结构示意图,该文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层。各个模块可以采用预训练的神经网络结构实现,具体将通过后面的实施例详细说明。
51.步骤s102:获取训练用文本。
52.在本技术中,训练用文本可以为任意文本
53.步骤s103:基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签。
54.考虑到人工标注数据,这是一个十分费时费力的过程,尤其是对文本摘要任务而言,每获得一个标注结果,需要阅读大量的文章段落。同时不同人的摘要生成标准不同,总结的方法也不同,最终会造成输出的结果分布不同,从而影响实验结果。为了解决上述问题,在本技术中,可以基于远监督思想,确定所述训练用文本的摘要标签。作为一种可实施方式,可以利用外部平台对所述训练用文本标注的摘要、文本类别、文本风格,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签。
55.在本技术中,文本类别用于表征文本所属的类别,比如文学类、科学类等,文本风格用于表征文本的文字风格,比如搞笑风格、新闻发布风格等。训练用文本标注的文本类别标签和文本风格标签可以是人工标注的。
56.步骤s104:以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
57.需要说明的是,所述文本摘要生成模型性能满足之后即可利用该文本摘要生成模型执行文本摘要生成任务,即输入文本至文本摘要生成模型,文本摘要生成模型生成摘要。如果采用已经爬取的数据训练得到的文本摘要生成模型性能不满足,可以再次爬取数据、数据清洗、利用远监督思想得到标签,继续对文本摘要生成模型进行训练,直至文本摘要生成模型性能满足为止。具体可参照图3所示,图3为本技术实施例公开的文本摘要生成模型的训练及应用示意图。
58.本实施例公开了一种文本摘要生成模型训练方法。获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;获取训练用文本;基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。采用上述方法训练文本摘要生成模型时,由于采用了远监督思想确定训练用文本的摘要标
签、文本类别标签和文本风格标签,无需依赖人工标注数据,利用编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层组成的文本摘要生成模型可以解决基于长短时记忆网络的序列到序列模型的一词多义、梯度消失问题。而且,在训练时考虑了文本类别、文本风格对摘要内容的影响。因此,采用上述训练得到的文本摘要生成模型自动生成文本摘要,能提升生成的文本摘要的精确率。
59.在本技术的另一个实施例中,对文本摘要生成模型训练过程中,各个模块的功能实现进行介绍,具体如下:
60.所述编码层对所述训练用文本进行编码,得到所述训练用文本的编码特征向量;
61.所述交互层对所述训练用文本的编码特征向量进行解码,得到所述训练用文本的解码特征向量;
62.所述文本摘要自动生成层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测摘要,所述训练用文本的预测摘要与所述训练用文本标注的摘要标签之间的误差表征所述文本摘要自动生成层对应的损失;
63.所述文本类别自适应层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测类别,所述训练用文本的预测类别与所述训练用文本标注的类别标签之间的误差表征所述文本类别自适应层对应的损失;
64.所述文本风格自适应层用于基于所述训练用文本的解码特征向量得到所述训练用文本的预测风格,所述训练用文本的预测风格与所述训练用文本标注的风格标签之间的误差表征所述文本风格自适应层对应的损失。
65.作为一种可实施方式,所述文本摘要生成模型中的编码层采用gpt-2网络的嵌入层(embeddinglayer)实现,所述文本摘要生成模型中的交互层采用所述gpt-2网络的交互层(transformerdecoderlayer)实现。
66.为便于理解,在本技术中对gpt-2网络进行了如下介绍,参照图4,图4为传统的gpt-2网络框架示意图。如图4所示,gpt-2网络主要由嵌入层(embeddinglayer)和交互层(transformerdecoderlayer)组成,embeddinglayer包括tokenembedding和positionembedding,transformerdecoderlayer包括堆叠的多个autoregressivetransformerdecoderblock。gpt-2网络输入(input)为文本分词后得到的不同token,不同的token经过embeddinglayer,即可得到transformerdecoderlayer的输入,最终可由transformerdecoderlayer解码得到下游输出。
67.对于tokenembedding和positionembedding,均基于一个embeddingmatrix,对不同索引进行embedding。以tokenembedding为例,设词库为v,嵌入维度为d
model
,则embeddingmatrix即尺寸为|v|
×dmodel
的张量,不同的token在词库中具有不同的索引值,根据索引值对embeddingmatrix做行索引,即可得到token的embedding嵌入张量,即如下式所示:
[0068][0069]
其中,ei是tokeni的嵌入表示,j是tokeni在v中的索引,m是embeddingmatrix,m(j)表示m的第j行元素。
[0070]
参照图5,图5为gpt-2网络transformerdecoderlayer的结构示意图。如图5所示,transformerdecoderlayer由采用掩码的多头自注意力网络层(maskedmulti-head
self-attention)、ln归一化层(layer norm)和前馈网络层(feedforward)组成,其中,采用掩码的多头自注意力网络层主要基于自注意力机制对文本进行处理。
[0071]
注意力机制是一种输入信息基于其上下文context信息进行重赋权更新的机制,一般地,在注意力中设置查询query、键key和值value,输入信息做查询query,上下文信息做键key和值value,以query去查询key,获取相关性,根据相关性从值value中获取更新。自注意力机制,即query、key和value均为输入信息x,如下式所示,相关性获取如下:
[0072][0073][0074][0075]
其中,q、k和v分别表示注意力机制中的query、key和value,a是query 查询key对应的相关性矩阵,l是输入文本的长度,α
ij
是矩阵a中第i行、第 j列元素,w
ij
是用softmax函数归一化后的α
ij
,共同组成权重矩阵w。
[0076]
根据人类的阅读习惯可知,模型对文本前部进行处理时不应该获知文本后部的信息,因此,在注意力当中,transformer decoder layer使用了掩码(mask) 机制,保证在整个文本一起输入时文本后部信息对前部不可见,掩码(mask) 机制如下所示:
[0077][0078][0079]
整体地,输入x给transformer decoder layer,其按照以下顺序依次进行以下处理:
[0080]
x=x attention(q:ln(x),k:ln(x),v:ln(x))
[0081]
x=x gelu(w
·
ln(x) b)
[0082]
其中,ln表示layer normalization。
[0083]
作为一种可实施方式,所述文本摘要生成模型中的文本类别自适应层以及文本风格自适应层采用自注意力机制实现。
[0084]
参照图6,图6为本技术实施例公开的一种文本摘要生成模型的结构示例图,该示例中,文本摘要生成模型中的编码层采用gpt-2网络的嵌入层实现,交互层采用所述gpt-2网络的交互层实现,文本类别自适应层以及文本风格自适应层采用自注意力机制实现.
[0085]
需要说明的是,文本摘要自动生成层对应的损失为loss
generate
、文本类别自适应层对应的损失为loss
class
、文本风格自适应层对应的损失loss
style
,联合损失loss具体为loss=loss
generate
αloss
class
βloss
style
,其中,α和β分别表示文本类别自适应层对应的损失和文本风格自适应层对应的损失的调节值。文本类别自适应层对应的损失和文本风格自适应
层对应的损失可以使用交叉熵损失,文本摘要自动生成层对应的损失可以为最大化似然概率,具体可以通过如下公式表示:
[0086][0087][0088][0089]
其中y表示对应任务的真实标签,p表示对应任务的预测概率。
[0090]
作为一种可实施方式,所述文本摘要生成模型中的文本摘要自动生成层在单词选择时,往往采用softmax对输出的词进行归一化,并基于束搜索(beamsearch)得到句子输出。通过将每个时刻输出的句子进行组合,并且输出模型认为最可靠的多个句子(依据beam width决定数量),即可得到生成的摘要。
[0091]
束搜索(beam search)是指在当前级别的状态下计算所有输出单词可能性,并按照递增顺序对他们进行排序,但只保留一定数量的可能结果(依据 beam width决定数量),接着根据这些可能结果进行扩展,迭代以上的动作直到搜索结束并返回最佳解(具有最高概率的候选项)。
[0092]
在本技术的另一个实施例中,对训练用文本的确定方式进行说明,参照图7,图7为本技术实施例公开的一种训练用文本的确定方法的流程示意图,该方法可以包括:
[0093]
步骤s201:获取网络爬虫爬取的数据。
[0094]
在本技术中,可以根据项目需求,利用网络爬虫技术对相关数据进行爬取。网络爬虫,即是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。首先通过http请求,获得目标服务器的响应,然后利用相关脚本对返回的相应进行解析,并且获取其中重要的资源。
[0095]
步骤s202:基于预设的正则表达式规则,对所述爬取的数据进行数据清洗,得到所述训练用文本。
[0096]
由于网络爬取的数据往往存在无关数据、特殊字符、乱码等情况,需要对爬取的数据进行数据清洗。数据清洗是指对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
[0097]
利用相关的正则表达式规则来对爬取的数据进行数据清洗,能够使得最终输出的文本尽量能够通顺,并且人通过阅读能够理解文本含义。
[0098]
为便于理解,比如,原始文本中存在大量无关的网址时,可以利用re. (https?|ftp|file)://[-a-za-z0-9 &@#/%?=~_|!:,.;] [-a-za-z0-9 &@#/%=~_|]等正则表达范式来对网址进行匹配,然后删除。
[0099]
为便于理解本技术的文本摘要生成模型训练方法,本技术给出如下示例进行说明:
[0100]
通过网络爬虫爬取的一个案例数据如下:
[0101]“当前位置:全球无人机网》无人机新闻》技术动态》正文麻省理工学院为无人机配
备rfid技术,进行仓库货物管理发布日期:2017-09-03来源:cnbeta.com我要投稿我要评论麻省理工学院的研究团队为无人机在仓库中使用rfid技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。使用rfid标签更换仓库中的条形码,将帮助提升自动化并提高库存管理的准确性。与条形码不同,rfid标签不需要对准扫描,标签上包含的信息可以更广泛和更容易地更改。它们也可以很便宜,尽管有优点,但是它具有局限性,对于跟踪商品没有设定rfid标准,“标签冲突”可能会阻止读卡器同时从多个标签上拾取信号。扫描rfid标签的方式也会在大型仓库内引起尴尬的问题。固定的rfid阅读器和阅读器天线只能扫描通过设定阈值的标签,手持式读取器需要人员出去手动扫描物品。几家公司已经解决了无人机读取rfid 的技术问题。配有rfid读卡器的无人机可以代替库存盘点的人物,并以更少的麻烦更快地完成工作。一个人需要梯子或电梯进入的高箱,可以通过无人机很容易地达到,无人机可以被编程为独立地导航空间,并且他们比执行大规模的重复任务的准确性和效率要比人类更好。目前市场上的rfid无人机需要庞大的读卡器才能连接到无人机的本身。这意味着它们必须足够大,以支持附加硬件的尺寸和重量,使其存在坠机风险。麻省理工学院的新解决方案,名为rfly,允许无人机阅读rfid标签,而不用捆绑巨型读卡器。相反,无人机配备了一个微小的继电器,它像wi-fi中继器一样。无人机接收从远程 rfid读取器发送的信号,然后转发它读取附近的标签。由于继电器很小,这意味着可以使用更小巧的无人机,可以使用塑料零件,可以适应较窄的空间,不会造成人身伤害的危险。麻省理工学院的rfly系统本质上是对现有技术的一个聪明的补充,它不仅消除了额外的rfid读取器,而且由于它是一个更轻的解决方案,允许小型无人机与大型无人机做同样的工作。研究团队正在马萨诸塞州的零售商测试该系统。本文链接: https://www.81uav.cn/uav-news/201709/03/25635.html标签:rfid技术仓库货物管理下一篇:英国皇家海军将研发各式水下概念无人机上一篇:大疆的漏洞奖励计划来了,美国的“安全控诉”是不是可以歇会儿了?0条相关评论免责声明:凡注明来源全球无人机网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,请注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。“[0102]
爬取的数据中含有无关信息、网址等如下:
[0103]
发布日期:2017-09-03
[0104]
来源:cnbeta.com我要投稿我要评论
[0105]
本文链接:https://www.81uav.cn/uav-news/201709/03/25635.html
[0106]
标签:rfid技术仓库货物管理
[0107]
本文来源:全球无人机网(www.81uav.cn),原文链接:https://www.81uav.cn/uav-news/201709/03/25635.html
[0108]
以及其他多余的符号等噪声数据。
[0109]
对爬取的数据进行数据清洗,去掉无关数据、乱码字符、网址等,输出训练用文本如下:
[0110]“麻省理工学院的研究团队为无人机在仓库中使用rfid技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。
[0111]
使用rfid标签更换仓库中的条形码,将帮助提升自动化并提高库存管理的准确性。与条形码不同,rfid标签不需要对准扫描,标签上包含的信息可以更广泛和更容易地更改。它们也可以很便宜,尽管有优点,但是它具有局限性,对于跟踪商品没有设定rfid标准,“标签冲突”可能会阻止读卡器同时从多个标签上拾取信号。扫描rfid标签的方式也会在大型仓库内引起尴尬的问题。固定的rfid阅读器和阅读器天线只能扫描通过设定阈值的标签,手持式读取器需要人员出去手动扫描物品。
[0112]
几家公司已经解决了无人机读取rfid的技术问题。配有rfid读卡器的无人机可以代替库存盘点的人物,并以更少的麻烦更快地完成工作。一个人需要梯子或电梯进入的高箱,可以通过无人机很容易地达到,无人机可以被编程为独立地导航空间,并且他们比执行大规模的重复任务的准确性和效率要比人类更好。
[0113]
目前市场上的rfid无人机需要庞大的读卡器才能连接到无人机的本身。这意味着它们必须足够大,以支持附加硬件的尺寸和重量,使其存在坠机风险。麻省理工学院的新解决方案,名为rfly,允许无人机阅读rfid标签,而不用捆绑巨型读卡器。相反,无人机配备了一个微小的继电器,它像wi-fi 中继器一样。无人机接收从远程rfid读取器发送的信号,然后转发它读取附近的标签。由于继电器很小,这意味着可以使用更小巧的无人机,可以使用塑料零件,可以适应较窄的空间,不会造成人身伤害的危险。
[0114]
麻省理工学院的rfly系统本质上是对现有技术的一个聪明的补充,它不仅消除了额外的rfid读取器,而且由于它是一个更轻的解决方案,允许小型无人机与大型无人机做同样的工作。研究团队正在马萨诸塞州的零售商测试该系统。“[0115]
标注文本的属性,包括:
[0116]
文本类别:“科技发展”[0117]
文本风格:“新闻发布”[0118]
外部平台对上述数据标注的摘要、文本类别、文本风格即可作为训练用文本的摘要标签、文本类别标签和文本风格标签。
[0119]
在利用上述训练用文本、训练用文本的摘要标签、文本类别标签和文本风格标签对模型进行训练时,编码层对所述训练用文本进行编码,其中,得到所述训练用文本的token embedding如下:
[0120]
{'input_ids':[101,8792,5763,5515,3584,3365,8222,5718,5832,6003, 3001,8192,2110,4346,2179,4482,3031,2193,3660,2104,2275,5605,72148, 28895,4030,4478,7701,7069,3660,3355,4547,4028,6069,3584,2259,10064, 2546,7740,2146,2072,5953,6485,4368,5718,4333,4335,3709,1882,3374, 2425,7313,2452,2763,2275,5605,4449,3459,10064,4449,3378,2448,5718, 4346,2179,4482,3031,3587,3069,3697,6074,5407,2104,4028,2555,2120, 2568,4346,4941,4028,2555,5718,2092,7138,1882,2275,5605,72148,28895, 4561,6087,4449,4135,2193,3660,2104,5718,4499,3745,5828,10064,3451, 3620,2602,4181,2669,6621,2601,2649,3643,4181,8595,3660,3355,6098, 5515,5718,2503,5854,3824,1882,2081,4499,3745,5828,2080,2773,10064, 72148,28895,4561,6087,2080,8301,
…
],'attention_mask':[1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,
…
]}
[0121]
得到所述训练用文本的position embedding采用gpt2默认的absolute
positionalembeddings形式创建位置编码向量。
[0122]
tokenembedding和positionembedding向量均是长度为512维的特征向量,每一维代表该输入文档中每个词对应的编码id。
[0123]
经过交互学习层,模型输出[cls]特征位对应的全文特征映射张量如下:
[0124]
tensor([[[-2.0168e-01,1.2241e-01,-1.1327e-01,...,9.0967e-03,0.0000e 00,4.8988e-03],
[0125]
[4.9234e-04,0.0000e 00,-1.1636e-01,...,1.9934e-01,-2.1552e-01,2.0362e-01],
[0126]
[2.9533e-01,-2.2012e-01,0.0000e 00,...,1.1334e-02,0.0000e 00,1.2453e-01],
[0127]
...,
[0128]
[1.7502e-01,0.0000e 00,7.2783e-01,...,1.1320e-01,1.8025e-02,1.4273e-01],
[0129]
[5.6781e-02,-5.5947e-01,5.9945e-01,...,2.1933e-01,9.8164e-02,0.0000e 00],
[0130]
[4.2173e-02,-3.1645e-01,0.0000e 00,...,-3.1639e-01,3.3263e-01,-4.9326e-02]]],device='cuda:0',
[0131]
grad_fn=《slicebackward》),
[0132]
其是[1,512,768]维的特征张量,表征全局的特征信息。接下来,文本摘要自动生成层、文本类别自适应层和文本风格自适应层基于该特征进行微调学习。
[0133]
文本摘要自动生成层对每个词进行概率预测,直到预测出
″
endofsentence
″
(句子结束标志符),则表示摘要生成结束,最后将多个词的输出按照束搜索串联起来,输出预测结果如下:
[0134]“麻省理工学院的研究团队为无人机在仓库中使用rfid技术进行库存查找等工作,创造了一种聪明的新方式。它允许公司使用更小,更安全的无人机在巨型建筑物中找到之前无法找到的东西。麻省理工学院的新解决方案,名为rfly,允许无人机阅读rfid标签,而不用捆绑巨型读卡器。”[0135]
文本类别自适应层对训练用文本的类别进行预测,输出预测结果如下:
[0136]“科技发展”。
[0137]
文本风格自适应层对训练用文本的风格进行预测,输出预测结果如下:
[0138]“新闻发布”。
[0139]
需要说明的是,针对每个训练用文本均可以采用上述方法进行处理,基于各训练用文本的预测结果和标注结果计算文本摘要生成模型的损失函数,待文本摘要生成模型收敛即可得到训练好的文本摘要生成模型。
[0140]
下面对本技术实施例公开的文本摘要生成模型训练装置进行描述,下文描述的文本摘要生成模型训练装置与上文描述的文本摘要生成模型训练方法可相互对应参照。
[0141]
参照图8,图8为本技术实施例公开的一种文本摘要生成模型训练装置结构示意图。如图8所示,该文本摘要生成模型训练装置可以包括:
[0142]
文本摘要生成模型获取单元11,用于获取预先构建的文本摘要生成模型,所述文
本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;
[0143]
训练用文本获取单元12,用于获取训练用文本;
[0144]
标签确定单元13,用于基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;
[0145]
训练单元14,用于以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
[0146]
作为一种可实施方式,所述标签确定单元,具体用于利用外部平台对所述训练用文本标注的摘要、文本类别、文本风格,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签。
[0147]
作为一种可实施方式,所述文本摘要生成模型中的编码层采用gpt-2网络的嵌入层实现,所述文本摘要生成模型中的交互层采用所述gpt-2网络的交互层实现,所述文本摘要生成模型中的文本类别自适应层以及文本风格自适应层采用自注意力机制实现。
[0148]
参照图9,图9为本技术实施例提供的文本摘要生成模型训练设备的硬件结构框图,参照图9,文本摘要生成模型训练设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线 4;
[0149]
在本技术实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
[0150]
处理器1可能是一个中央处理器cpu,或者是特定集成电路asic (application specific integrated circuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
[0151]
存储器3可能包含高速ram存储器,也可能还包括非易失性存储器 (non-volatile memory)等,例如至少一个磁盘存储器;
[0152]
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
[0153]
获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;
[0154]
获取训练用文本;
[0155]
基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;
[0156]
以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
[0157]
可选的,所述程序的细化功能和扩展功能可参照上文描述。
[0158]
本技术实施例还提供一种可读存储介质,该可读存储介质可存储有适于处理器执行的程序,所述程序用于:
[0159]
获取预先构建的文本摘要生成模型,所述文本摘要生成模型包括编码层、交互层、文本摘要自动生成层、文本类别自适应层以及文本风格自适应层;
[0160]
获取训练用文本;
[0161]
基于远监督思想,确定所述训练用文本的摘要标签、文本类别标签和文本风格标签;
[0162]
以所述训练用文本为训练样本,以所述训练用文本的摘要标签、文本类别标签和文本风格标签为样本标签,以所述文本摘要自动生成层、所述文本类别自适应层以及所述文本风格自适应层对应的联合损失训练所述文本摘要生成模型。
[0163]
可选的,所述程序的细化功能和扩展功能可参照上文描述。
[0164]
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0165]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
[0166]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。