1.本发明涉及流量数据增强领域,具体涉及一种面向样本不均衡的网络流量数据增强方法。
背景技术:
2.人工智能是指使用某种算法来实现机器模拟人的智能甚至是超越人的智能,而机器学习代表了使用算法来指导计算机利用已知数据得出适当的模型,并利用此模型对新的情境给出判断的过程。截止目前,机器学习方法已被广泛应用于网络入侵检测。纵观整个机器学习过程,最至关重要的便是数据,一个机器学习模型是否鲁棒、是否具有较高的泛化能力,与训练数据集的质量密不可分。
3.大数据时代下,网络流量数据的统计和分析凸显重要性,实时采集到的真实网络环境中的流量数据可以借助机器学习方法来进行入侵识别,网络流量数据集的样本质量将直接决定识别的性能。网络流量数据难于获取且大部分数据往往彼此间差异性很小,因而时常出现数据类别严重不平衡的情况,过采样数据增强方法是用于解决样本不均衡问题的常用方法。该类方法通过对少数类样本进行采样以增加少数类样本个数,最终实现平衡网络流量数据中多数类与少数类的效果。大量现有的过采样方法基于smote算法,直接采用随机抽取的方式进行样本选取,分布稀疏的样本极易被忽视。此外,位于边界处样本具有更高的错分率,其信息也需要被增强。
4.相较于一般的图像以及语言文本数据,网络流量数据难于获取且大部分数据往往彼此间差异性很小,因而时常出现数据类别严重不平衡的情况,最终使得训练后的模型泛化能力不足。数据增强是解决上述问题的一个可行方案,其本质是通过引入先验知识来增加数据集中的数据,从而提高模型的泛化能力。常见的用于改善类别不平衡的数据增强方式包括欠采样方法、过采样方法、数据集扩容、代价敏感学习等。其中,过采样是解决网络流量数据样本不均衡问题的比较有效、快捷的方法,代表性算法是smote和adasyn,其本质是通过对少数类样本进行采样来增加少数类的数据样本个数,最终实现平衡网络流量数据中多数类与少数类的效果。
5.为了解现有技术的发展状况,对已有的专利和文献进行了检索、比较和分析,筛选出如下与本发明相关度比较高的技术信息:
6.专利方案1:cn112036515a基于smote算法的过采样方法、装置和电子设备,提供了一种基于smote算法的过采样方法、装置和电子设备。该方法包括:获取历史样本数据集,确定正、负样本及其对应数量;确定多数类样本数据和少数类样本数据,并进行数据向量化处理;使用离异点监测方法,从所述少数类样本数据集中筛选目标样本数据;基于smote算法,对所述目标样本数据进行过采样,以生成特定数量的新样本数据;根据所生成的新样本数据和原始的少数类样本数据,得到扩增后的少数类样本数据集。本方法在优化采样方法的同时,解决了数据不均衡的问题,还提升了模型预测的精确度,有效减少了数据不均衡引入的偏差。缺陷:该方案基于传统的smote算法进行数据合成,但值得注意的是,聚类结果中通
常边界及边界附近的样本比远离边界的样本更容易被错误分类,因此在数据合成前应更加关注那些边界及边界附近的少数类样本,增强其信息。
7.专利方案2:cn111832664a基于borderline smote的电力变压器故障样本均衡化和故障诊断方法,公开了一种基于borderline smote的电力变压器故障样本均衡化和故障诊断方法,均衡化方法包括搜索少数类样本、分类少数样本、生成新样本步骤,故障诊断方法还包括故障诊断步骤。本方法增加了边界样本附近的少数样本,降低了边界样本的误判率,从而提高了分类准确性;适用于多种人工智能算法对非均衡数据集的处理,可直接移植和扩展到分类算法中,具有较强的普适性和泛化性。缺陷:该方案的过采样数据增强方法基于borderline-smote算法,重点关注于增强边界的样本信息,根据少数类样本近邻的同类样本数量来识别哪些是处于少数类和多数类边界的样本,然后生成边界处的少数类样本,但由于直接采用随机抽取的方式进行样本选取,过采样前的数据经常存在分布不均匀的情况,分布稀疏的样本易被忽视。
技术实现要素:
8.本发明针对网络流量数据难于获取且大部分数据往往彼此间差异性很小,因而时常出现数据类别严重不平衡的难题,提出了一种面向样本不均衡的网络流量数据增强方法。
9.本发明采用的技术方案为:
10.一种面向样本不均衡的网络流量数据增强方法,包括以下步骤:
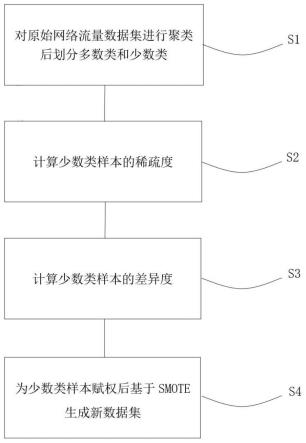
11.s1、对原始网络流量数据集进行聚类,根据聚类结果簇中流量数据的数量,将聚类结果簇划分为少数样本集合和多数样本集合;
12.s2、计算每个少数类样本集合中所有少数类样本之间的欧几里得距离,得到的欧氏距离矩阵,根据欧氏距离矩阵,获取每个少数类样本集合中每个少数类样本到其他少数类样本的距离占比,并进行归一化得到每个少数类样本间的稀疏因子;
13.s3、计算每个少数类样本集合中所有少数类样本到多数类样本集合中所有多数类样本的欧几里得距离,得到欧氏距离矩阵,根据欧氏距离矩阵得到少数类样本到多数类样本的距离占比,并进行归一化得到少数类样本与多数类样本间的差异度;
14.s4、根据每个少数类样本集合中少数类样本间的稀疏因子和少数类样本与多数类样本间的差异度,为少数类样本赋予初始权重,并基于smote合成新样本并生成新的数据集。
15.进一步的,步骤s1具体包括:
16.s11、将原始网络流量数据集通过k-means聚类算法进行聚类,得到一定数量的聚类结果簇;
17.s12、针对任一聚类结果簇ck,当簇内所包含的样本数量小于等于阈值θ时,标记为少数类样本集合c
k,min
;当簇内所包含的样本数量大于阈值θ时,标记为多数类样本集合c
k,maj
。
18.进一步的,步骤s2具体包括:
19.s21、对于每一个少数类样本集合c
k,min
,计算所有少数类样本之间的欧几里得距离,得到欧氏距离矩阵
[0020][0021]
式中,n为少数类样本集合c
k,min
中的样本数量;
[0022]
s22、根据欧氏距离矩阵获取少数类样本集合c
k,min
中每个少数类样本xi到其他少数类样本的距离占比
[0023]
其中,步骤s22具体包括:
[0024]
s221、计算少数类样本集合c
k,min
中任一少数类样本xi到所有其他少数类样本的距离之和,即对欧氏距离矩阵中的每一行元素进行求和,用表示;
[0025]
s222、计算少数类样本集合c
k,min
中所有少数类样本之间的距离之和,即对欧氏距离矩阵的上三角元素进行求和,用表示;
[0026]
s223、计算少数类样本集合c
k,min
中任一少数类样本xi到所有其他少数类样本的距离之和占所有少数类样本间距离之和的比例即计算欧氏距离矩阵中第i行元素之和除以欧氏距离矩阵的上三角元素之和;
[0027][0028]
s23、当的标准差不为0时,采用z-score的方式对进行标准化,得到标准化分数标准化的过程中采用3σ准则进行噪声清洗,将用于计算稀疏因子的数据范围锁定在因子的数据范围锁定在随后对进行归一化计算,即计算在少数类样本标准化分数之和中的占比,得到少数类样本xi的稀疏因子sparsityi;当的标准差为0时,直接对进行归一化计算,得到少数类样本xi的稀疏因子;计算公式如下:
[0029][0030][0031]
s24、重复s21-s23,得到所有少数类样本集合中所有少数类样本的稀疏因子。
[0032]
进一步的,步骤s3具体包括:
[0033]
s31、对于某一少数类样本集合c
k,min
,首先计算所有少数类样本到所有多数类样本集合c
k,maj
中所有多数类样本的欧几里得距离,得到欧氏距离矩阵
[0034][0035]
式中,n为少数类样本集合c
k,min
中的样本数量,m为所有多数类样本集合c
k,maj
中所有多数类样本的数量;
[0036]
s32、获取少数类样本集合c
k,min
中少数类样本xi到多数类样本的距离占比得到少数类样本与多数类样本间的差异度;
[0037]
其中,步骤s32具体包括:
[0038]
s321、计算少数类样本集合c
k,min
中任一少数类样本xi到多数类样本集合c
k,maj
中所有多数类样本的距离之和,即,对欧氏距离矩阵中的每一行元素进行求和,用表示;
[0039]
s322、计算少数类样本集合c
k,min
中所有少数类样本到多数类样本集合c
k,maj
中所有多数类样本的距离之和,即,欧氏距离矩阵中的所有元素之和,用表示;
[0040]
s323、计算少数类样本集合c
k,min
中任一少数类样本xi到多数类样本集合c
k,maj
中所有多数类样本的距离之和占所有少数类样本到所有多数类样本的距离之和的比例即,计算欧氏距离矩阵中第i行元素之和除以欧氏距离矩阵中所有元素之和;
[0041][0042]
s33、当的标准差不为0时,采用z-score的方式对进行标准化,得到标准化分数标准化的过程中采用3σ准则进行噪声清洗,将用于计算稀疏因子的数据范围锁定在于计算稀疏因子的数据范围锁定在随后对进行归一化计算,即,计算在少数类样本标准化分数之和中的占比,得到少数类样本xi与多数类样本间的差异度diversityi;当的标准差为0时,对进行归一化计算,得到少数类样本xi与多数类样本间的差异度diversityi;计算公式如下:
[0043][0044]
[0045]
s34、重复s31-s33,得到所有少数类样本集合中所有少数类样本的差异度;
[0046]
进一步的,步骤s4具体包括:
[0047]
s41、根据任一少数类样本集合c
k,min
中少数类样本的稀疏因子和差异度,使用sigmoid函数进行归一化后为少数类样本赋予初始权重,让周围稀疏和处于边界处的样本获得更高的权重weighti;
[0048][0049]
s42、在已赋值权重的样本中进行随机抽取,基于smote算法合成新样本,采用三角重心采样对少数类样本集合c
k,min
进行样本合成;
[0050]
s43、重复s41-s42,直到所有少数类样本集合完成样本合成后,得到数据增强后的数据集。
[0051]
本发明相比现有技术具有如下优点:
[0052]
(1)对原始数据集进行聚类后,数据经常存在分布不均匀的情况,本发明通过计算聚类结果中少数类样本的稀疏度以帮助选择出稀疏处的样本。
[0053]
(2)本发明对原始数据集进行聚类后,通过计算聚类结果中少数类样本与多数类样本的差异度以帮助选择出边界处的样本,以任一少数类样本的稀疏度与差异度共同作为标准进行客观赋权后进行数据合成,有效的提升了生成数据的质量。
[0054]
(3)通过本发明提出的过采样数据增强方法,可以更有效地选择出数据集中分布稀疏处样本和边界处样本,提升生成数据的质量。
附图说明
[0055]
图1为本发明实施例的方法流程图。
[0056]
图2为原始网络流量数据图。
[0057]
图3为数据增强结果图。
具体实施方式
[0058]
本发明的实例中,以公有数据集kddcup99作为原始输入数据,如图1所示,具体分析步骤如下:
[0059]
s1、对原始网络流量数据集进行k-means聚类(k=3),划分聚类结果中的少数类样本集合和多数类样本集合;具体包括:
[0060]
s11、将原始网络流量数据集通过k-means聚类算法进行聚类,得到一定数量的聚类结果簇;
[0061]
s12、针对任一聚类结果簇ck,当簇内所包含的样本数量小于等于阈值θ时,标记为少数类样本集合c
k,min
;当簇内所包含的样本数量大于阈值θ时,标记为多数类样本集合c
k,maj
。
[0062]
原始网络流量数据集如图2所示,划分结果如表1所示:
[0063]ck
num(ck)c
1,maj
1321c
2,min
12c3,min6[0064]
表1聚类中多数类和少数类划分表
[0065]
s2、计算每个少数类样本集合中所有少数类样本之间的欧几里得距离,得到的欧氏距离矩阵,根据欧氏距离矩阵,获取每个少数类样本集合中每个少数类样本到其他少数类样本的距离占比,并进行归一化得到每个少数类样本间的稀疏度;
[0066]
步骤s2具体包括:
[0067]
s21、对于每一个少数类样本集合c
k,min
,首先计算所有少数类样本之间的欧几里得距离,得到欧氏距离矩阵
[0068][0069]
式中,n为少数类样本集合c
k,min
中的样本数量;
[0070]
s22、根据欧氏距离矩阵获取少数类样本集合c
k,min
中每个少数类样本xi到其他少数类样本的距离占比
[0071]
其中,步骤s22具体包括:
[0072]
s221、计算少数类样本集合c
k,min
中任一少数类样本xi到所有其他少数类样本的距离之和,即,对欧氏距离矩阵中的每一行元素进行求和,用表示;
[0073]
s222、计算少数类样本集合c
k,min
中所有少数类样本之间的距离之和,即,对欧氏距离矩阵的上三角元素进行求和,用表示;
[0074]
s223、计算少数类样本集合c
k,min
中任一少数类样本xi到所有其他少数类样本的距离之和占所有少数类样本间距离之和的比例即,计算欧氏距离矩阵中第i行元素之和除以欧氏距离矩阵的上三角元素之和;
[0075][0076]
s23、当的标准差不为0时,采用z-score的方式对进行标准化,得到标准化分数标准化的过程中采用3σ准则进行噪声清洗,将用于计算稀疏度的数据范围锁定在于计算稀疏度的数据范围锁定在随后对进行归一化计算,即,计算在少数类样本标准化分数之和中的占比,得到少数类样本xi的稀疏度sparsityi;当的标准差为0时,直接对进行归一化计算,得到少数类样本xi的稀疏度;计算公式如下:
[0077]
[0078][0079]
s24、重复s21-s23,得到所有少数类样本集合中所有少数类样本的稀疏度。
[0080]
由公式(1)、(2)和(3)计算少数类样本的稀疏度,结果如下表2所示:
[0081][0082]
表2少数类样本稀疏度记录表
[0083]
s3、计算每个少数类样本集合中所有少数类样本到多数类样本集合中所有多数类样本的欧几里得距离,得到欧氏距离矩阵,根据欧氏距离矩阵得到少数类样本到多数类样本的距离占比,并进行归一化得到少数类样本与多数类样本间的差异度;
[0084]
步骤s3具体包括:
[0085]
s31、对于某一少数类样本集合c
k,min
,首先计算所有少数类样本到所有多数类样本集合c
k,maj
中所有多数类样本的欧几里得距离,得到欧氏距离矩阵
[0086][0087]
式中,n为少数类样本集合c
k,min
中的样本数量,m为所有多数类样本集合c
k,maj
中所有多数类样本的数量;
[0088]
s32、获取少数类样本集合c
k,min
中少数类样本xi到多数类样本的距离占比得到少数类样本与多数类样本间的差异度;
[0089]
其中,步骤s32具体包括:
[0090]
s321、计算少数类样本集合c
k,min
中任一少数类样本xi到多数类样本集合c
k,maj
中所有多数类样本的距离之和,即,对欧氏距离矩阵中的每一行元素进行求和,用表示;
[0091]
s322、计算少数类样本集合c
k,min
中所有少数类样本到多数类样本集合c
k,maj
中所有多数类样本的距离之和,即,欧氏距离矩阵中的所有元素之和,用表示;
[0092]
s323、计算少数类样本集合c
k,min
中任一少数类样本xi到多数类样本集合c
k,maj
中所有多数类样本的距离之和占所有少数类样本到所有多数类样本的距离之和的比例即,计算欧氏距离矩阵中第i行元素之和除以欧氏距离矩阵中所有元素之和;
[0093][0094]
s33、当的标准差不为0时,采用z-score的方式对进行标准化,得到标准化分数标准化的过程中采用3σ准则进行噪声清洗,将用于计算稀疏因子的数据范围锁定在于计算稀疏因子的数据范围锁定在随后对进行归一化计算,即,计算在少数类样本标准化分数之和中的占比,得到少数类样本xi与多数类样本间的差异度diversityi;当的标准差为0时,对进行归一化计算,得到少数类样本xi与多数类样本间的差异度diversityi;计算公式如下:
[0095][0096][0097]
s34、重复s31-s33,得到所有少数类样本集合中所有少数类样本的差异度;由公式(4)、(5)和(6)计算少数类样本的差异度,结果如下表3所示:
[0098][0099]
表3少数类样本差异度记录表
[0100]
s4、根据每个少数类样本集合中少数类样本间的稀疏度和少数类样本与多数类样本间的差异度,为少数类样本赋予初始权重,并基于smote合成新样本并生成新的数据集。
[0101]
步骤s4具体包括:
[0102]
s41、根据任一少数类样本集合c
k,min
中少数类样本的稀疏度和差异度,使用sigmoid函数进行归一化后为少数类样本赋予初始权重,让周围稀疏和处于边界处的样本获得更高的权重;
[0103][0104]
s42、在已赋值权重的样本中进行随机抽取,基于smote算法合成新样本,采用三角重心采样对少数类样本集合c
k,min
进行样本合成;
[0105]
s43、重复s41-s42,直到所有少数类样本集合完成样本合成后,得到数据增强后的数据集。其中原始数据集共包含1339个样本,进行过采样数据增强后的数据集共包含2643个样本。数据增强结果图如图3所示。
[0106]
由公式(7)为少数类样本赋予初始权重,结果如下表4:
[0107][0108]
表4少数类样本权重记录表。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
