技术特征:
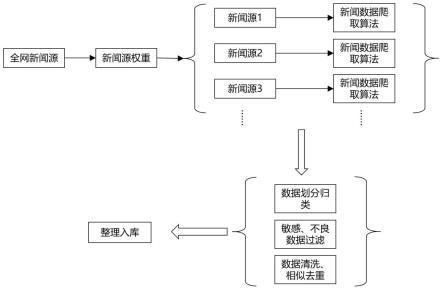
1.基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,包括:步骤1、对各大新闻网站进行数据爬取,对爬取后的新闻数据进行分类以及过滤;步骤2、对过滤后的新闻数据进行信息抽取,获取实体关系属性、事件数据、实体词以及领域词;步骤3、根据实体词与领域词得到正样本,对正样本进行处理得到负样本,正样本与负样本构成正负样本数据集;步骤4、根据实体关系属性与事件数据构建新闻领域图谱知识库;步骤5、根据新闻领域的不同应用场景搭建不同的文本纠错模型以及图谱知识库搜索引擎;步骤6、对于待纠错的文本,进行分词处理、实体抽取及语义分析,获取上下位词语及实体关系,然后利用搜索引擎在图谱知识库进行图谱检索;步骤7、对文本纠错模型的类型进行判断,若是基于规则的模型,则进入步骤8;若是基于语言模型或预训练模型,则进入步骤9;步骤8、召回待纠错词的相似词集和事件集,并计算与上下文的相似关系来选取相似得分最高的k个相似词或事件作为正确建议,结束流程,k为大于0的整数;步骤9、利用正负样本数据集来训练和微调文本纠错模型,然后由文本纠错模型自动检测和纠错,同时结合规则纠错,并给出最后的正确建议,结束流程。2.根据权利要求1所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,步骤1中,对各大新闻网站进行数据爬取的具体方法包括:梳理全网各大新闻网站,选取某段时间内各大新闻网站的数据进行分析,通过对各个属性维度人工抽样评估打分后进行计算平均得分,得到不同数据源各自的权重得分;对梳理出来的新闻源,根据权重得分分配抓取资源,所述属性包括新闻质量、数量、多样性以及时效属性。3.根据权利要求1所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,步骤1中,对爬取后的新闻数据进行分类,并对分类后的数据进行过滤的具体方法包括:对爬取后的新闻数据,进行划分归类,过滤掉无法归类和信息残缺的新闻数据;再对分好类别的新闻数据进行敏感以及不良过滤,最后对新闻数据进行脏数据的清洗、相似新闻去重,并全量字段结构化处理后存入数据库。4.根据权利要求1所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,步骤2中,所述信息抽取包括实体抽取、领域词抽取以及领域事件抽取。5.根据权利要求4所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,所述实体抽取的具体方法包括:使用领域词典和深度学习结合的方式进行实体识别抽取,基于中文预训练模型与条件随机场算法进行句子级别的实体关系联合抽取,获得实体与属性,实体与关系的三元组,并计算抽取出来实体在新闻语料中的得分,将实体得分进行归一化,选取得分之和大于设置值的实体词作为新闻文本的实体词并保存整理存入数据库。6.根据权利要求5所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,所述事件抽取的具体方法包括选取领域事件三元组,选取领域事件三元组的具体方法包括:对分类过滤后的新闻文本进行分句处理,将新闻标题、正文句子转换为语义向量,再以
标题内容作为中心向量,并对正文句子进行建模打分,得到每个句子重要程度分数;对句子中抽取的事件三元组、实体得分以及每个句子重要程度分数进行加权排序,选取得分最高的三元组作为领域事件三元组。7.根据权利要求4所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,所述领域词抽取的具体方法包括:通过领域词典进行领域词的抽取,对获取的领域词与实体词进行去重处理,保存去重后的领域词。8.根据权利要求1所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,步骤3中,得到正样本的具体方法包括:将包含实体词和领域词的句子作为正样本。9.根据权利要求8所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,得到负样本的具体方法包括:将正样本中的实体词和领域词替换成对应的相似词得到的句子作为负样本;或将正样本句子转换成语音,然后随机加入噪音,再转换成文本,转换成的文本即为负样本。10.根据权利要求1所述的基于知识图谱的新闻领域多场景文本纠错方法,其特征在于,步骤4中,根据实体关系属性与事件数据构建新闻领域图谱知识库的具体方法包括:爬取各百科网站包含领域实体和领域事件的结构化数据,筛选、过滤后作为实体与事件数据的补充;然后对获取的实体词和领域词的相似词数据以及补充的实体与事件数据进行指代消解以及实体消歧操作;再以实体词和事件为主体,实体间的关系、实体的各个属性、实体和事件的关系以及事件和事件的关系作为实体词和事件的属性字段构建实体和事件的知识库;或以领域词汇和领域事件为本体建立知识图谱,包含实体词和领域词的句子集作为词汇的延伸属性,同时建立词与事件间的关系。
技术总结
本发明涉及文本纠错领域,具体涉及一种基于知识图谱的新闻领域多场景文本纠错方法,技术方案包括:对各大新闻网站进行数据爬取、分类以及过滤;然后进行信息抽取,获取实体关系属性、事件数据、实体词以及领域词;根据实体词与领域词得到正样本,对正样本进行处理得到负样本,正样本与负样本构成正负样本数据集;根据实体关系属性与事件数据构建新闻领域图谱知识库;根据新闻领域的不同应用场景搭建不同的文本纠错模型以及图谱知识库搜索引擎;对于待纠错的文本,进行分词处理、实体抽取及语义分析,获取上下位词语及实体关系,然后利用搜索引擎在图谱知识库进行图谱检索;根据文本纠错模型的类型进行不同的处理。本发明适用于新闻领域文本纠错。闻领域文本纠错。闻领域文本纠错。
技术研发人员:陈功彬 徐桢虎 高登科 李少博 陈涵宇
受保护的技术使用者:四川封面传媒科技有限责任公司
技术研发日:2022.05.11
技术公布日:2022/7/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。