一种基于android手机数据的轨迹异常分析方法
技术领域
1.本发明涉及电子取证与数据分析领域,具体的说,涉及了一种基于android手机数据的轨迹异常分析方法。
背景技术:
2.在近些年的智能手机发展中,android系统手机已占据超过70%的全球智能手机市场份额,国内更是高达90%,而手机更是近些年来网络犯罪的重要作案工具,手机中存在着调查取证的重要数据线索。
3.手机取证,从字面理解,可以分为“取”和“证”两个过程。取,把数据原原本本的从手机中提取出来。证,通过数据检索、挖掘、分析,寻找与案件有关的线索和证据。研究数据分析技术,挖掘提取手机中的有价值信息,可以更快地为司法办案人员提供办案线索
4.手机用户每天会产生大量的轨迹信息,用户的行为具有很强的时空关联性,如果能够在手机应用数据的基础上获取,并提取用户的轨迹数据,然后对轨迹数据进行有效的分析,就可以推测出用户的行为特征。
5.目前市面上手机取证工具的功能大多集中在电子数据提取上,很少对提取数据进行分析,即使有此数据功能也仅是简单的统计分析,如何能够从提取的手机数据中获取有价值的信息变得越来越值得关注。
6.为了解决以上存在的问题,人们一直在寻求一种理想的技术解决方案。
技术实现要素:
7.本发明要解决的技术问题是:针对手机用户轨迹数据的多样性和分散性的问题,采集所有可能涉及用户轨迹的手机数据,提出了一种基于数据挖掘的轨迹异常分析方法、提取手机应用数据里面所有的所涉轨迹信息,利用数据挖掘方法对获取数据进行数据聚类分析,并结合用户的其他个人数据进行行为分析。
8.为实现上述目的,本发明提供的技术解决方案为:
9.一种基于android手机数据的轨迹异常分析方法,包括以下步骤:
10.步骤1:数据采集:对android手机进行数据采集,获取手机基本信息以及手机上安装的软件中所有可能包含位置的数据信息及事件信息;
11.步骤2:数据预处理:将收集到的手机基本信息、导航软件、购物软件、外卖软件、聊天软件等数据进行格式化,对其中的重要位置信息及事件信息进行提取,去除冗余数据,并将预处理后的格式化数据统一放至sqlite数据库中;
12.步骤3:数据分析:采用dbscan算法结合k-means算法对用户的位置信息进行数据分析,识别出行为异常点;
13.其中,行为异常点识别算法实现流程如下:
14.步骤3.1:遍历数据库中相应的数据表获取某用户的位置数据样本d,对样本数据集d首先用k-means算法做预处理,算法的初始质心随机数k初始值取2,目标是识别出用户
的常规位置并得到质心位置;
15.步骤3.2:对k-means算法所形成的2个簇中所有位置点计算到质心的距离,并计算出每个簇中的点到质心的平均距离avgdist,统计距离小于avgdist的点的个数存储在变量minpoint中;
16.步骤3.3:选择2个簇中avgdist最小的和minpoint中最小的,作为dbscan算法执行的参数,执行dbscan算法,输出可能的异常行为点。
17.所述步骤1中进行的数据采集,包括手机基本信息采集和手机位置信息采集:
18.步骤1.1:手机基本信息包括手机短信、通讯录、通话记录、imei、序列号等设备信息,主要通过相应权限获取;
19.步骤1.2:手机位置信息数据来源于手机上安装的软件,包括导航软件、购物软件、外卖软件、聊天软件等,通过获取应用数据,从应用数据里面提取位置相关信息。
20.所述步骤2中的数据预处理包括手机基本信息的预处理和位置信息数据的预处理:
21.步骤2.1:手机基本信息预处理包括手机短信预处理、手机通讯录预处理、手机通话记录预处理,将手机基本信息分别统一格式化放在不同的表格里面,便于后续异常行为的参考;
22.步骤2.2:手机位置信息预处理包括所有涉及位置信息的事件和位置统一放在同一个表格内,便于后续的位置轨迹分析。
23.所述步骤3.1的k-means算法,具体步骤如下:
24.步骤3.1.1:根据采集到的地理位置信息的特点,从集合中选取2个位置点作为初始质心;
25.步骤3.1.2:计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去。对于每一个样例i,计算其所述的簇类的方法如下:
26.c(i)=minj||x
(i)-uj||;
27.步骤3.1.3:计算每个簇类中所有点到经度和纬度的平均值,并将新的经纬度信息作为新的聚类中心。具体计算公式如下:
[0028][0029]
步骤3.1.4:判断偏移距离,偏移距离大于设置的值则重复步骤3.2.2,否则继续下一步;
[0030]
步骤3.1.5:计算每个簇类中的点到新的质心的距离的平均值。具体计算公式如下:
[0031][0032]
步骤3.1.6:输出最终的聚类结果以及平均值。
[0033]
所述步骤3.2中计算dbscan算法的参数,具体步骤如下:
[0034]
步骤3.2.1:计算步骤3.2.2中的质心1的簇类c1的簇类中的所有位置点到质心的距离的平均距离avgdist1;
[0035]
步骤3.2.2:统计簇类c1中的位置点到质心的距离小于平均距离的位置点的数据
minpiont1;
[0036]
步骤3.2.3:计算所述步骤3.2.2中质心2为质心的簇类中夫人所有位置点到质心的距离的平均距离avgdist2;
[0037]
步骤3.2.4:统计簇类c2中的位置点到质心的距离小于平均距离的位置点的数目minpiont2;
[0038]
步骤3.2.5:比较avgdist1和avgdist2去其中的最小值作为dbscan算法的聚类半径e;
[0039]
步骤3.2.6:比较minpiont1与minpiont2取其中的最小值作为dbscan算法的聚类的最小核心对象的数目minpiont。
[0040]
所述步骤3.3中的dbscan算法,具体步骤如下:
[0041]
步骤3.3.1:连接数据库,并将数据库中位置信息表里的经纬信息遍历获取到list表单中,作为算法分析的数据样本d。并设置算法执行所需要的两个参数:聚类半径e和影响核心对象的最少位置点数目minpiont;
[0042]
步骤3.3.2:将数据样本d中的所有位置点都初始化为未访问状态并添加标记;
[0043]
步骤3.3.3:算法首次执行是随机从数据样本d中抽取一个位置点p作为分析对象,并将位置点p标记为已访问状态,计算数据样本d内未访问状态的位置点与正在进行分析处理位置点p之间的距离,若其邻域内点的数目不少于minpiont,则建立一个新的簇c和候选集n,并将邻域内的所有点加入候选集n中。若位置点p邻域内点的数目少于minpiont,则将p点标记为噪声点;
[0044]
步骤3.3.4:随机从候选集n中抽取一个位置点q并标记点q的状态为已访问状态,计算数据样本d内未访问状态的位置点与正在进行分析处理位置点q之间的距离,若q点邻域内位置点的数目不少于minpiont,则将点q邻域内的所有点候选集n;并将位置点q加入簇c;
[0045]
步骤3.3.5:重复步骤3.3.4,继续处理候选集n中尚未被标记的位置点,直到候选集n中的位置都被处理过为止;
[0046]
步骤3.3.6:重复步骤3.3.3-3.3.5,算法结束的标志是所有的位置点都被划分到了相对应的簇中,或者已经被标记成了噪声;
[0047]
步骤3.3.7:输出聚类后所形成的簇c和噪声点;
[0048]
其中,所述用户的行为点可分为高频度行为点和低频度行为点,对位置数据流进行k-means和dbscan算法处理后,输出位置簇和噪声位置点。其中噪声位置点就是低频度行为点,也就是所述的可能有异常行为发生的行为异常点。获取到这个位置点之后就可以确定用户到达该位置点的具体时间,利用这个参考时间点分析从用户手机端提取的其他相关信息,例如手机短信信息、手机通话记录的相关信息进行综合分析,就能够较为准确的推测出行为异常点上具体时间段的行为是否异常。
[0049]
本发明的有益效果在于:
[0050]
本发明结合数据挖掘技术进行数据分析,有较高的识别精度和识别效率。本发明将聚类分析算法应用到手机电子数据分析中,并结合用户相关信息对用户轨迹数据进行分析,与现有手机数据分析方法相比,准确度更高、分析范围更广,能识别出用户特定时间段的异常行为。
附图说明
[0051]
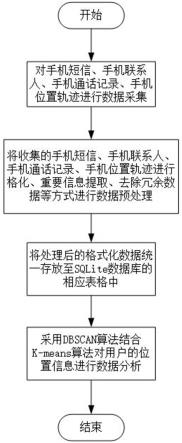
图1是本发明实施例提供的一种基于android手机数据的轨迹异常分析方法的流程示意图。
[0052]
图2是本发明实施例提供的数据库表格组成示意图。
[0053]
图3是本发明实施例提供的k-means聚类算法流程图。
[0054]
图4是本发明实施例提供的dbscan聚类算法流程图。
具体实施方式
[0055]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
[0056]
本发明建立一种基于日志与文件结构的手机数据恢复方法,参见图1,本发明中对用户行为轨迹进行分析的流程图,包括以下三个实施步骤:
[0057]
步骤1:对android手机进行数据采集,获取手机基本信息以及手机上安装的软件中所有可能包含位置的数据信息及事件信息;
[0058]
步骤2:数据预处理:将收集到的导航软件信息、手机信息、即时聊天通讯、购物软件等数据进行格式化、重要位置信息及事件信息提取,去除冗余数据,并将预处理后的格式化数据统一放至sqlite数据库的同一表格中;
[0059]
步骤3:采用dbscan算法结合k-means算法对用户的位置信息进行数据分析。
[0060]
参见图2,步骤1中进行的数据采集,包括手机基本信息采集和手机位置信息采集:
[0061]
步骤1.1:手机基本信息包括手机短信、通讯录、通话记录、imei、序列号等设备信息,主要通过相应权限获取;
[0062]
步骤1.2:手机位置信息数据来源于手机上安装的软件,包括导航软件、购物软件、外卖软件、聊天软件等,通过获取应用数据,从应用数据里面提取位置相关信息。
[0063]
所述步骤2中的数据预处理,包括手机基本信息的预处理和位置信息数据的预处理:
[0064]
步骤2.1:手机基本信息预处理包括手机短信预处理、手机通讯录预处理、手机通话记录预处理,将手机基本信息分别统一格式化放在不同的表格里面,便于后续异常行为的参考;
[0065]
步骤2.2:手机位置信息预处理包括所有涉及位置信息的事件和位置统一放在同一个表格内,便于后续的位置轨迹分析。
[0066]
所述步骤3中行为异常点识别算法实现流程如下:
[0067]
步骤3.1:遍历数据库中相应的数据表获取某用户的位置数据样本d。对样本数据集d首先用k-means算法做预处理,算法的初始质心随机数k初始值取2,目标是识别出用户的常规位置并得到质心位置。
[0068]
步骤3.2:对k-means算法所形成的2个簇中所有位置点计算到质心的距离,并计算出每个簇中的点到质心的平均距离avgdist。统计距离小于avgdist的点的个数存储在变量minpoint中。
[0069]
步骤3.3:选择2个簇中avgdist最小的和minpoint中最小的,作为dbscan算法执行的参数,执行dbscan算法,输出可能的异常行为点。
[0070]
参见图3,本发明中使用的k-means聚类算法,包括以下步骤:
[0071]
步骤3.1.1:根据采集到的地理位置信息的特点,从集合中选取2个位置点作为初始质心。
[0072]
步骤3.1.2:计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去。对于每一个样例i,计算其所述的簇类的方法如下:
[0073]
c(i)=minj||x
(i)-uj||;
[0074]
步骤3.1.3:计算每个簇类中所有点到经度和纬度的平均值,并将新的经纬度信息作为新的聚类中心。具体计算公式如下:
[0075][0076]
步骤3.1.4:判断偏移距离,偏移距离大于设置的值则重复步骤3.2.2,否则继续下一步。
[0077]
步骤3.1.5:计算每个簇类中的点到新的质心的距离的平均值。具体计算公式如下:
[0078][0079]
步骤3.1.6:输出最终的聚类结果以及平均值。
[0080]
所述步骤3.2计算dbscan算法的参数,具体步骤如下:
[0081]
步骤3.2.1:计算步骤3.2.2中的质心1的簇类c1的簇类中的所有位置点到质心的距离的平均距离avgdist1。
[0082]
步骤3.2.2:统计簇类c1中的位置点到质心的距离小于平均距离的位置点的数据minpiont1。
[0083]
步骤3.2.3:计算所述步骤3.2.2中质心2为质心的簇类中夫人所有位置点到质心的距离的平均距离avgdist2。
[0084]
步骤3.2.4:统计簇类c2中的位置点到质心的距离小于平均距离的位置点的数目minpiont2。
[0085]
步骤3.2.5:比较avgdist1和avgdist2去其中的最小值作为dbscan算法的聚类半径e。
[0086]
步骤3.2.6:比较minpiont1与minpiont2取其中的最小值作为dbscan算法的聚类的最小核心对象的数目minpiont。
[0087]
参见图4,本发明中使用的dbscan聚类算法,包括以下步骤:
[0088]
步骤3.3.1:连接数据库,并将数据库中位置信息表里的经纬信息遍历获取到list表单中,作为算法分析的数据样本d。并设置算法执行所需要的两个参数:聚类半径e和影响核心对象的最少位置点数目minpiont。
[0089]
步骤3.3.2:将数据样本d中的所有位置点都初始化为未访问状态并添加标记。
[0090]
步骤3.3.3:算法首次执行是随机从数据样本d中抽取一个位置点p作为分析对象,并将位置点p标记为已访问状态,计算数据样本d内未访问状态的位置点与正在进行分析处理位置点p之间的距离,若其邻域内点的数目不少于minpiont,则建立一个新的簇c和候选集n,并将邻域内的所有点加入候选集n中。若位置点p邻域内点的数目少于minpiont,则将p
点标记为噪声点。
[0091]
步骤3.3.4:随机从候选集n中抽取一个位置点q并标记点q的状态为已访问状态,计算数据样本d内未访问状态的位置点与正在进行分析处理位置点q之间的距离,若q点邻域内位置点的数目不少于minpiont,则将点q邻域内的所有点候选集n;并将位置点q加入簇c。
[0092]
步骤3.3.5:重复步骤3.3.4,继续处理候选集n中尚未被标记的位置点,直到候选集n中的位置都被处理过为止。
[0093]
步骤3.3.6:重复步骤3.3.3-3.3.5,算法结束的标志是所有的位置点都被划分到了相对应的簇中,或者已经被标记成了噪声。
[0094]
步骤3.3.7:输出聚类后所形成的簇c和噪声点。
[0095]
用户的行为点可分为高频度行为点和低频度行为点,对位置数据流进行k-means和dbscan算法处理后,输出位置簇和噪声位置点。其中噪声位置点就是低频度行为点,也就是所述的可能有异常行为发生的行为异常点。获取到这个位置点之后就可以确定用户到达该位置点的具体时间,利用这个参考时间点分析从用户手机端提取的其他相关信息,例如手机短信信息、手机通话记录的相关信息进行综合分析,就能够较为准确的推测出行为异常点上具体时间段的行为是否异常。
[0096]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
