1.本发明涉及构音障碍检测技术领域,尤其是一种基于模态分解的构音障碍快速检测方法。
背景技术:
2.构音障碍是由于发音器官或神经系统病变、形态异常而导致的呼吸、发声、发音、共鸣和韵律异常,表现为发声困难、发音不准、咬字不清、声响、音调及速率、节律等异常,以及鼻音过重等言语听觉特征的改变。临床上常见于帕金森症等神经性疾病中,严重影响了患者的生活质量和社会生活能力。
3.目前构音障碍没有专门的评定标准,临床上多数采用听觉感知的主观方法,如frenchay评价法。这需要由专业的言语治疗师或神经科、康复科医师检查、记录、评分,所需时间和人工成本高,且评分者之间存在内部差异,限制了其在临床上的广泛推广。构音障碍患者的言语中表现出的语音颤动、节律紊乱以及音调低沉等特征,均可以基于语音信号分析进行表征,从而实现自动化识别构音障碍。
4.语音信号处理技术提供了一种非侵入性的自动化构音障碍检测方法,公开号为cn112927696a的专利介绍了一种基于语音识别的构音障碍自动评估系统和方法,结合深度学习技术实现了构音障碍的客观准确评估,但这种方法需要大量构音障碍患者的连续语音数据样本,进行特定的语音识别系统训练,同时提取的声学特征均为设定的手工特征,这导致该方法存在极大的时间成本,且检测鲁棒性严重依赖所训练的语音模型。在学术领域上,已经将发音和韵律相关特征应用在构音障碍的检测中。然而,这些特征没有考虑到声音的时频特性。对此,另外一些研究基于谱和倒谱特征,但是,这些特征仅能反映语音信号的静态特性,且直接处理非线性非平稳的语音信号存在局限性,忽略了声音的隐式信息,导致检测不够准确,鲁棒性较差。
技术实现要素:
5.本发明的目的在于提供一种能够提高构音障碍检测的准确性和鲁棒性,进一步提高构音障碍的检测效果,操作便捷、耗时短且成本低,有利于大范围推广应用的基于模态分解的构音障碍快速检测方法。
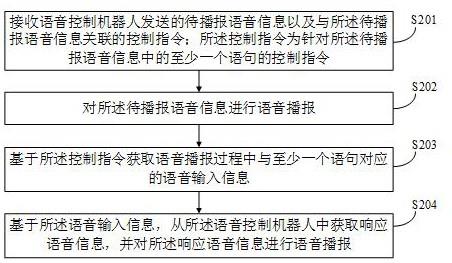
6.为实现上述目的,本发明采用了以下技术方案:一种基于模态分解的构音障碍快速检测方法,该方法包括下列顺序的步骤:(1)通过标准化的施测流程执行言语范式,收集原始语音信号,原始语音信号为一个由多个采样点组成时间序列,
푡
为采样点的序数,,为自然数集,即由正整数组成的集合;(2)对原始语音信号进行预处理:包括端点检测、预加重、分帧和加窗,得到分帧和加窗之后的信号s;(3)基于模态分解对分帧和加窗之后的信号s进行声学特征提取,得到统计学特
征;(4)将统计学特征输入至机器学习分类器中,输出构音障碍检测结果,所述机器学习分类器为支持向量机svm模型。
7.在步骤(1)中,所述施测流程包括测试环境、音频采集装置、数据传输和保存方式的标准化;所述言语范式为持续元音发音任务。
8.在步骤(2)中,所述端点检测采用双门限算法,利用短时能量和短时过零率特征确定原始语音信号的起始点和终止点,获得有效语音段,避免非语音段信号对后续分析造成干扰;所述预加重用于平衡频谱和提高信噪比,采用下式的一阶滤波器作为预加重方式:其中,
훼
为预加重系数;
푦
(
푡
)为预加重处理后的语音信号;
푡
为采样点的序数,,为自然数集;所述分帧和加窗是通过对
푦
(
푡
)的每一帧信号应用汉明窗
푤
(
푛
)来实现:其中,
푠
(
푛
)为
푦
(
푡
)分帧后的信号;
푁
为帧长,;
푤
(
푛
)为汉明窗:。
9.所述步骤(3)具体包括以下步骤:(3a)对分帧和加窗之后的信号s进行模态分解:采用ceemdan算法即集合经验模态分解算法将分帧和加窗之后的信号s分解成
푘
个本征模态分量imf;(3b)对每个本征模态分量imf应用短时傅里叶变换stft,并将结果按照模态分量的频率值正序堆叠得到频谱矩阵d(ω);(3c)计算频谱矩阵d(ω)对应的基于周期图功率谱估计,接着应用梅尔滤波器组,并对梅尔滤波器组的每个滤波器的频率窗范围内的能量求和,得到梅尔频谱s
mel
;(3d)对梅尔频谱s
mel
取对数并执行离散余弦变换dct,得到l维倒谱系数c;(3e)分别计算l维倒谱系数c对应的一阶差分系数
∆
和二阶差分系数
∆2,一阶差分系数
∆
和二阶差分系数
∆2附加到l维倒谱系数c上形成3l维特征向量;(3f)在话语层面计算3l维特征向量的每个维度所有帧上的统计学特征。
10.在步骤(3a)中,所述ceemdan算法具体包括以下步骤:(3a1)在分帧和加窗之后的信号s上叠加一个均值为0、标准差为1的高斯白噪声,计算完备集合平均得到第一个模态分量:其中,为通过经验模态分解得到的第n个分量;
퐼
为集合平均的试次;为
第
푖
个集合叠加的白噪声,其振幅为;(3a2)计算第一个残差成分并再次叠加经过模态分解的白噪声的第1个分量,得到新信号::(3a3)利用步骤(3a1)中的计算方法分解新信号,得到第二个模态分量:(3a4)以此类推,依次计算第n个残差和第n 1个模态分量::(3a5)重复步骤(3a4),直到残差信号无法再被分解为止,此时,分帧和加窗之后的信号s表示为:其中,
푘
为经ceemdan算法分解得到的本征模态分量imf的个数;
푟
为最终的残差分量。
11.在步骤(3b)中,所述频谱矩阵d(ω)的计算公式为:其中,
푘
为经ceemdan算法分解得到的本征模态分量imf的个数;为第
푘
个本征模态分量imf经过角频率为
휔
的短时傅里叶变换stft之后的复值频谱矩阵。
12.在步骤(3c)中,所述梅尔频谱s
mel
的计算公式为:其中,
푀
为滤波器的数量;为第
푛
个频点对应梅尔尺度的三角滤波器函数;
푃
为短时傅里叶变换stft的点数。
13.在步骤(3d)中,所述l维倒谱系数c的第
푖
个系数c
푖
的计算公式为:
其中,
푀
为滤波器的数量;l为一阶差分系数
∆
的维数。
14.在步骤(3e)中, 所述一阶差分系数
∆
为l维,第
푖
个系数
∆
푖
的定义为:其中,
푄
为计算差分的时间差;,l为一阶差分系数
∆
的维数;所述二阶差分系数
∆2为l维,第i个系数定义为:其中,。
15.在步骤(3f)中,所述统计学特征包括均值、标准差、偏度和峰度。
16.由上述技术方案可知,本发明的有益效果为:第一,基于模态分解的时频分析理论的引入,克服了传统声学特征在非线性时变系统中的局限性,分解得到的imf包含了原始音频信号在不同层次上的时频信息,能够很好地捕捉构音障碍患者的语音生理信息,反映了发声器官的病理性改变,提高了构音障碍检测的准确性和鲁棒性;第二,梅尔尺度特征能够反映语音的产生机制和听觉感知的非线性特性,结合模态分解,使得本发明能够适应非线性非平稳的语音信号,进一步提高了构音障碍的检测效果;第三,基于ceemdan的信号分解方法,避免了传统模态分解方法的模态混叠、时频分布错误的缺陷,从而能够准确表征构音信息,且具备良好完备性,同时有效提高了计算效率;第四,本发明施测流程标准化、自动化程度高,同时测试范式精简、操作便捷、耗时短且成本低,有利于大范围推广应用。
附图说明
17.图1为本发明的方法流程图;图2为图1中基于模态分解的声学特征提取方法示意图。
具体实施方式
18.如图1所示,一种基于模态分解的构音障碍快速检测方法,该方法包括下列顺序的步骤:(1)通过标准化的施测流程执行言语范式,收集原始语音信号,原始语音信号为一个由多个采样点组成时间序列,
푡
为采样点的序数,,为自然数集,即由正整数组成的集合;通过标准化的施测流程来执行言语范式,并采集语音数据,所述施测流程包括测试环境、音频采集装置、数据传输和保存方式的标准化,在一个具有较低环境背景噪音的房
间中(小于45db),通过一个放置于距离被检测对象口腔正前方约10厘米的电容式麦克风录音。所述麦克风连接到专业级声卡,转换为音频信号并被传输至一台电脑,同时采样至44.1khz的频率和16bit的分辨率,保存为单声道的wav格式。
19.(2)对原始语音信号进行预处理:包括端点检测、预加重、分帧和加窗,得到分帧和加窗之后的信号s;(3)基于模态分解对分帧和加窗之后的信号s进行声学特征提取,得到统计学特征;(4)将统计学特征输入至机器学习分类器中,输出构音障碍检测结果,所述机器学习分类器为支持向量机svm模型。
20.在步骤(1)中,所述施测流程包括测试环境、音频采集装置、数据传输和保存方式的标准化;所述言语范式为持续元音发音任务。要求被检测对象深吸一口气,然后以一个舒适的音调和响度尽可能长、稳定地发出一个元音,并重复多次测量。所述元音为单元音/a/,所述多次测量为3次。
21.在步骤(2)中,所述端点检测采用双门限算法,利用短时能量和短时过零率特征确定原始语音信号的起始点和终止点,获得有效语音段,避免非语音段信号对后续分析造成干扰;所述预加重用于平衡频谱和提高信噪比,采用下式的一阶滤波器作为预加重方式:其中,
훼
为预加重系数;
푦
(
푡
)为预加重处理后的语音信号;
푡
为采样点的序数,,为自然数集;所述分帧和加窗是通过对
푦
(
푡
)的每一帧信号应用汉明窗
푤
(
푛
)来实现:其中,
푠
(
푛
)为
푦
(
푡
)分帧后的信号;
푁
为帧长,;
푤
(
푛
)为汉明窗:。
22.如图2所示,所述ceemdan算法是一种通过对原始信号多次叠加高斯白噪声的改进模态分解方法,只需较少的迭代次数便能够实现分解完备性,从而降低了计算成本。所述步骤(3)具体包括以下步骤:(3a)对分帧和加窗之后的信号s进行模态分解:采用ceemdan算法即集合经验模态分解算法将分帧和加窗之后的信号s分解成
푘
个本征模态分量imf;(3b)对每个本征模态分量imf应用短时傅里叶变换stft,并将结果按照模态分量的频率值正序堆叠得到频谱矩阵d(ω);(3c)计算频谱矩阵d(ω)对应的基于周期图功率谱估计,接着应用梅尔滤波器组,并对梅尔滤波器组的每个滤波器的频率窗范围内的能量求和,得到梅尔频谱s
mel
;(3d)对梅尔频谱s
mel
取对数并执行离散余弦变换dct,得到l维倒谱系数c;(3e)分别计算l维倒谱系数c对应的一阶差分系数
∆
和二阶差分系数
∆2,一阶差
分系数
∆
和二阶差分系数
∆2附加到l维倒谱系数c上形成3l维特征向量,以表征语音的动态信息;(3f)在话语层面计算3l维特征向量的每个维度所有帧上的统计学特征。
23.在步骤(3a)中,所述ceemdan算法具体包括以下步骤:(3a1)在分帧和加窗之后的信号s上叠加一个均值为0、标准差为1的高斯白噪声,计算完备集合平均得到第一个模态分量:其中,为通过经验模态分解得到的第n个分量;
퐼
为集合平均的试次;为第
푖
个集合叠加的白噪声,其振幅为;(3a2)计算第一个残差成分并再次叠加经过模态分解的白噪声的第1个分量,得到新信号::(3a3)利用步骤(3a1)中的计算方法分解新信号,得到第二个模态分量:(3a4)以此类推,依次计算第n个残差和第n 1个模态分量::(3a5)重复步骤(3a4),直到残差信号无法再被分解为止,此时,分帧和加窗之后的信号s表示为:其中,
푘
为经ceemdan算法分解得到的本征模态分量imf的个数;
푟
为最终的残差分量。
24.在步骤(3b)中,所述频谱矩阵d(ω)的计算公式为:
其中,
푘
为经ceemdan算法分解得到的本征模态分量imf的个数;为第
푘
个本征模态分量imf经过角频率为
휔
的短时傅里叶变换stft之后的复值频谱矩阵。
25.在步骤(3c)中,所述梅尔频谱s
mel
的计算公式为:其中,
푀
为滤波器的数量,
푀
为26;为第
푛
个频点对应梅尔尺度的三角滤波器函数;
푃
为短时傅里叶变换stft的点数,
푃
为256。
26.在步骤(3d)中,所述l维倒谱系数c的第
푖
个系数c
푖
的计算公式为:其中,
푀
为滤波器的数量;l为一阶差分系数
∆
的维数,l为13。
27.在步骤(3e)中, 所述一阶差分系数
∆
为l维,第
푖
个系数的定义为:其中,
푄
为计算差分的时间差,
푄
为2;,l为一阶差分系数
∆
的维数;所述二阶差分系数
∆2为l维,第
푖
个系数定义为:其中,。
28.在步骤(3f)中,所述统计学特征包括均值、标准差、偏度和峰度。
29.实施例一采集120例语音样本,包括60名构音障碍患者,以及性别和年龄匹配的60名健康对照。提取了全部的声学特征并划分为训练集和测试集,接着将训练集输入支持向量机svm模型训练和交叉验证,最后在测试集上进行实验测试,最终的实验结果如下表1所示。在本实施例一中,检测准确率达到86.1%。
30.表1 构音障碍检测实验结果评价指标准确率f1 分数auc数值0.86110.87180.8302综上所述,本发明克服了传统声学特征在非线性时变系统中的局限性,分解得到的imf包含了原始音频信号在不同层次上的时频信息,能够很好地捕捉构音障碍患者的语音生理信息,反映了发声器官的病理性改变,提高了构音障碍检测的准确性和鲁棒性;梅尔
尺度特征能够反映语音的产生机制和听觉感知的非线性特性,结合模态分解,使得本发明能够适应非线性非平稳的语音信号,进一步提高了构音障碍的检测效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。