1.本发明是指一种光网络优化器及其光网络优化方法,尤指一种可实现路由优化、网络规划及快速故障恢复的光网络优化器及其光网络优化方法。
背景技术:
2.软件定义网络(software-defined network)在网络控制及管理方面提供了前所未有的灵活性,再加上从数据层级(data plane)收集的及时网络测量结果,从而使得实现有效率的线上网络优化成为可能。然而,基于分析模型(例如等候理论(queuing theory))的现有网络建模技术无法处理过于庞大的复杂性,因此,目前的优化方法仅能改善全局性能度量(global performance metric),例如依据从网络演算获得的延迟的最坏情况估计所作的网络规划或网络利用。
3.因此,现有技术有改进的必要。
技术实现要素:
4.因此,本发明主要提供一种光网络优化器及其光网络优化方法,以实现路由优化、网络规划及快速故障恢复。
5.本发明揭露一种光网络优化方法。该光网络优化方法包含有训练一神经网络;调整该神经网络的复数个辅助神经元的复数个辅助输出值中的至少一个;以及利用该神经网络进行推论。
6.本发明另揭露一种光网络优化器。该光网络优化器包含有一储存电路,用来储存一指令;以及一处理电路,耦接至该储存电路,用来执行储存于该储存电路的该指令。该指令包含有训练一神经网络;调整该神经网络的复数个辅助神经元的复数个辅助输出值中的至少一个;以及利用该神经网络进行推论。
附图说明
7.图1为本发明实施例中一系统的示意图。
8.图2及图3分别为本发明实施例一神经网络的示意图。
9.图4及图5分别为本发明实施例一优化方法的示意图。
10.图6为本发明实施例中一优化器的示意图。
11.附图符号说明:
12.10:系统;
13.100:用户端;
14.120:无线电存取网络;
15.140:网状网络;
16.140l:链路;
17.140n:节点;
18.150:网络模型;
19.150f:流量矩阵;
20.150g:拓扑结构;
21.150k:关键绩效指标;
22.150p:功率矩阵;
23.150r:路由;
24.160,60:优化器;
25.170c:配置方式;
26.170p:目标政策;
27.170s:网络状态;
28.190c:控制平面;
29.190d:数据层级;
30.190k:知识层级;
31.20,30:神经网络;
32.40,50:优化方法;
33.650:处理电路;
34.670:储存电路;
35.hl1~hl4:隐藏层;
36.k21~k2c,k31~k3d,x1~xa,y1~y3,z11~z1b,z21~z2c,z31~z3d,z41~z4e:神经元;
37.nl:输入层;
38.s400~s408,s500~s518:步骤;
39.tl:输出层。
具体实施方式
40.在通篇说明书及后续的请求项当中所提及的“第一”、“第二”等叙述,仅用以区别不同的器件,并不对其产生顺序的限制。所述实施例在不抵触的情况下可以以各种方式组合。
41.为了实现路由优化、网络规划及快速故障恢复,本发明利用神经网络(neural network)及注意力机制(attention mechanism)来对网络效能关键绩效指标(key performance indicators,kpi)预测。
42.请参考图1,图1为本发明实施例中一系统10的示意图。系统10可包含有一用户端(user equipment,ue)100、一无线电存取网络(radio access network,ran)120、一网状网络(mesh network)140以及一优化器160。无线电存取网络120用来提供用户端100与网状网络140之间的通讯连接。网状网络140属于一数据层级(data plane)190d,其可为光网状网络(optical mesh network),且可包含有多个节点(node)140n以及链路(link)140l。一个链路140l连接在两个节点140n之间,多个链路140l可构成一个路径(path)。一个节点140n可包含有转发器(transponder)、多路复用器(multiplexer,mux)、放大器(amplifier,amp)、可重构光分插复用器(reconfigurable optical add/drop multiplexer,roadm)、多
路分解器(demultiplexer,demux)或其他的光学装置(optical device)。优化器160属于一知识层级(knowledge plane)190k,其可自一数据层级190d收集网络状态(network state)170s,而能取得例如流量的及时统计信息(例如流量矩阵(traffic matrix)150f)。其中,网络状态170s可包含有每个路径的平均的延迟(delay/latency)、抖动(jitter)或丢包(packet loss)。流量矩阵150f可定义为网状网络140中两个节点140n之间的频宽(bandwidth)。优化器160可利用一网络模型150对网络效能关键绩效指标150k的预测,来实现路由优化、网络规划(例如选择最佳的链路配置)及快速故障恢复。
43.具体而言,网络模型150可分析拓扑结构(topology)150g、路由(routing)150r、对应至输入流量(input traffic)的流量矩阵150f与功率矩阵(power matrix)150p之间的关系,且可准确预测特定配置方式(configuration)170c下的网络效能关键绩效指标150k(例如延迟、抖动或丢包)。其中,功率矩阵150p可利用网状网络140的多个链路140l对应的光功率来定义。借由调整网状网络140的节点140n的光学装置的光功率,本发明实施例可最佳化网络效能关键绩效指标。值得注意的是,网络模型150可将拓扑结构150g、来源端(source)至目的端(destination)的路由150r的方案(例如端到端的路径的列表)、流量矩阵150f与功率矩阵150p作为输入,但也可(例如依据目前的网络状态170s)将其作为输出。
44.在一实施例中,网络模型150可利用图神经网络(graph neural network,gnn)及注意力机制来对图像化结构信息(graph-structured information)进行学习及建模,因此,网络模型150可概括任意的拓扑结构、路由的方案、对应至流量强度(traffic intensity)的流量矩阵及功率矩阵。并且,即使是在训练(training)阶段(例如优化方法40的步骤s402)未出现过的拓扑结构、路由的方案、流量矩阵及功率矩阵,网络模型150也可做出准确预测。
45.举例来说,网络模型150的内部体系结构可参考表一所示的算法。网络模型150可运行表一所示的算法,来反复探索不同/候选的配置方式170c,直到找到满足目标政策(target policy)170p的配置方式170c为止。其中,目标政策170p可包含有多个优化目标(optimization objective)和约束条件(constraint),优化目标例如可为最小化端到端延迟(end-to-end latency),约束条件例如可为安全政策(security policy)。
46.(表一)
47.[0048][0049]
如表一所示,网络模型150可接收初始链路属性/功能xl、初始路径属性/功能xp及路由的方案r作为输入,并输出推论的特征度量yp。其中,初始链路属性/功能xl可与光功率相关。
[0050]
在表一所示的算法中,行号3到行号14的回圈可代表消息传递操作(message-passing operation)。消息传递操作是指在链路与路径之间相互交换编码信息(例如隐藏状态(hidden state))。其中,网络模型150可将链路的链路隐藏状态向量hl及路径的路径链路隐藏状态向量hp重复t次的消息传递操作(例如表一所示的算法的行号3开始的回圈),这代表隐藏状态将从初始链路隐藏状态向量hl0及初始路径链路隐藏状态向量hp0而收敛。
[0051]
在表一所示的算法中,通过将路由的方案r(即端到端路径的集合)直接映射到链路与路径之间的消息传递操作,使得每个路径从此路径所包含的所有链路收集消息(从行号5开始的回圈),每个链路从包含此链路的所有路径接收消息(行号12)。行号6的rnnt递归函数可对应至循环神经网络(recurrent neural network,rnn),其可萃取可变尺寸的序列的依存关系,因此可用来依据路径上的链路顺序进行建模。在一实施例中,对应至rnnt递归函数的神经网络层可包含有可包含有门控循环单元(gated recurrent unit,gru)。
[0052]
在表一所示的算法中,行号9及行号12可代表更新操作,其中分别将新收集的信息编码为路径及链路的隐藏状态。行号12的ut更新函数(update function)可对应至可训练的神经网络。在一实施例中,对应至ut更新函数的神经网络层可包含有可包含有门控循环单元。
[0053]
在表一所示的算法中,行号15的fp读出函数(readout function)可利用路径隐藏状态向量hp作为输入,来预测路径级别的特征度量yp(例如延迟或丢包)。或者,fp读出函数可利用链路隐藏状态向量hl作为输入,来预测链路级别的特征度量yl。
[0054]
在一实施例中,优化器160可支援光功率管理(optical power management)。优化器160可依据目标政策170p来执行算法(例如表一所示的算法),以找出网络效能关键绩效指标最佳的功率矩阵150p。进一步地,优化器160可收集网状网络140的网络状态170s。当优化器160根据网络状态170s判断网状网络140的某个路径上的链路140l的光衰减增加时,优化器160可找出最佳的功率矩阵150p,并在预定的时间提供配置方式170c,以调整网状网络140。
[0055]
在一实施例中,优化器160可支援恢复(recovery)。优化器160可依据目标政策
170p来执行算法(例如表一所示的算法),以找出网络效能关键绩效指标来源端至目的端的最佳的路径。进一步地,优化器160可收集网状网络140的网络状态170s。当优化器160根据网络状态170s判断网状网络140的某个路径上的链路140l或节点140n故障时,优化器160可修改拓扑结构150g,找出来源端至目的端的最佳的路径,并提供配置方式170c,以调整网状网络140。
[0056]
在一实施例中,优化器160可支援频宽时间规划(bandwidth calendaring)。优化器160可依据目标政策170p来执行算法(例如表一所示的算法),以找出网络效能关键绩效指标最佳的流量矩阵150f。并且,当预计需改变网状网络140的路径或链路140l的频宽时,优化器160可找出最佳的流量矩阵150f,并在预定的时间提供配置方式170c,以调整网状网络140。
[0057]
图2为本发明实施例一神经网络20的示意图。神经网络20可对应至表一所示的fp读出函数。
[0058]
神经网络20可为全连接(fully-connected)神经网络。神经网络20可包含有输入层nl、隐藏层(hidden layer)hl1、hl2、hl3及输出层tl。输入层nl可包含有神经元(neuron)x1、x2、
…
、xa,隐藏层hl1可包含有神经元z11、z12、
…
、z1b,隐藏层hl2可包含有神经元z21、z22、
…
、z2c,隐藏层hl3可包含有神经元z31、z32、
…
、z3d,其中,a、b、c、d分别为正整数。输出层tl可包含有神经元y1、y2、y3,但不限于此,输出层tl可包含有其他数量的神经元。
[0059]
在一实施例中,神经网络20的输入层nl的神经元x1~xa(也可称为输入神经元)的输入值与光功率相关。
[0060]
在一实施例中,本发明可利用注意力机制来建构神经网络20。举例来说,隐藏层hl2的神经元z21~z2c可分别连接至神经元y2,且分别对应至超参数p21y2、p22y2、
…
、p2cy2。也就是说,隐藏层hl2的特征的约束/加强程度可利用超参数p21y2~p2cy2来决定。
[0061]
举例来说,神经元y2的输出值ty2例如可满足ty2=g(w31y2*tz31 w32y2*tz32
…
w3dy2*tz3d p21y2*tz21 p22y2*tz22
…
p2cy2*tz2c),也就是说,神经元y2的输出值ty2可等于前一层的神经元的输出值乘以其对应参数(例如神经元z31的输出值tz31乘以神经元z31至神经元y2的参数w31y2、神经元z32的输出值tz32乘以神经元z32至神经元y2的参数w32y2、
…
、神经元z3d的输出值tz3d乘以神经元z3d至神经元y2的参数w3dy2)与某一层的神经元的输出值乘以其对应超参数(例如神经元z21的输出值tz21乘以神经元z21至神经元y2的超参数p21y2、神经元z22的输出值tz22乘以神经元z22至神经元y2的超参数p22y2、
…
、神经元z2c的输出值tz2c乘以神经元z2c至神经元y2的超参数p2cy2)或偏置值(bias)的总和,此后再经过启用函数(activation function)g()。在此情况下,神经元z21~z2c的输出值tz21~tz2c可分别作为距离函数(distance function)。
[0062]
在一实施例中,本发明可利用注意力机制来建构隐藏层hl2。举例来说,隐藏层hl2可包含有神经元k21、k22、
…
、k2c,其分别连接至神经元z21~z2c,且分别对应至超参数p21、p22、
…
、p2c。也就是说,神经元k21~k2c约束/加强隐藏层hl2的特征的程度可利用超参数p21~p2c来决定。
[0063]
举例来说,神经元z21的输出值tz21例如可满足tz21=g(w1121*tz11 w1221*tz12
…
w1b21*tz1b p21*tk21),也就是说,神经元z21的输出值tz21可等于前一层的神经元的输出值乘以其对应参数(例如神经元z11的输出值tz11乘以神经元z11至神经元z21的参数
w1121、神经元z12的输出值tz12乘以神经元z12至神经元z21的参数w1221、
…
、神经元z1b的输出值tz1b乘以神经元z1b至神经元z21的参数w1b21)与偏置值或神经元k21的输出值tk21乘以神经元k21至神经元z21的超参数p21的总和,此后再经过启用函数g()。在此情况下,神经元k21的输出值tk21可作为距离函数。
[0064]
由此可知,神经网络20中受强化的特定神经网络层(例如隐藏层hl2)的一个神经元(例如神经元z21)直接连接至一个神经元(也可称为辅助神经元)(例如神经元k21)及输出层tl的一个神经元(也可称为输出神经元)(例如神经元y2),且辅助神经元与神经元之间对应至一超参数(例如超参数p21),输出神经元与神经元之间对应至另一超参数(例如超参数p21y2)。也就是说,神经网络20可利用两道的注意力机制,来强化特定神经网络层(例如隐藏层hl2)的特征的影响,其有助于神经网络20进行特征萃取,从而提升推论准确度。
[0065]
超参数p21~p2c、p21y2~p2cy2的值可依据不同需求而决定。在一实施例中,超参数p21~p2c、p21y2~p2cy2可为大于等于零的实数(real number)。当超参数p21~p2c、p21y2~p2cy2很大,则形成硬约束(hard constraint),当超参数p21~p2c、p21y2~p2cy2很小,则形成软约束(soft constraint)。在一实施例中,藉由调整超参数p21~p2c、p21y2~p2cy2,可根据例如开放式系统互联模型(open system interconnection model,osi)七层架构,决定特定神经网络层(例如隐藏层hl2)或特定神经元(例如神经元k21)对输出层tl的神经元(例如神经元y2)的影响程度或是否造成影响。
[0066]
在一实施例中,神经元k21~k2c的输出值tk21~tk2c可分别作为距离函数。在一实施例中,神经元k21~k2c的输出值tk21~tk2c可为介于0与1之间的实数。在一实施例中,神经元k21~k2c的输出值tk21~tk2c是将逻辑0或逻辑1转换至可微分的形式。在一实施例中,藉由调整神经元k21~k2c的输出值tk21~tk2c,可根据例如开放式系统互联模型(open system interconnection model,osi)七层架构,调节特定神经网络层(例如隐藏层hl2)或特定神经元(例如神经元k21)对输出层tl的神经元(例如神经元y2)的影响。
[0067]
由此可知,神经网络的隐藏层可分别对应至开放式系统互联模型七层架构的不同层级。
[0068]
图3为本发明实施例一神经网络30的示意图。图3所示的神经网络30类似于图2所示的神经网络20而可用来取代神经网络20,故相同器件沿用相同符号表示。神经网络30可包含有隐藏层hl1、hl2、hl3、hl4,其可分别对应至开放式系统互联模型七层架构的实体层(physical layer)、资料连结层(data link layer)、网络层(network layer)及传输层(transport layer)。
[0069]
在一实施例中,神经元y1的输出值ty1可相关于或对应至(或等于)网络效能关键绩效指标的延迟也就是说,神经元y1的输出值ty1可为延迟的函数。延迟可指封包(data packet)从一位置到达另一位置所花费的时间。若是从来源端到达目的端所花费的时间,则可称为端到端延迟。在一实施例中,延迟主要是由于网络层所引起的,因此可针对隐藏层hl3引入注意力机制。
[0070]
举例来说,隐藏层hl3的神经元z31~z3d可分别连接至神经元y1,且分别对应至超参数p31y1、p32y1、
…
、p3dy1。也就是说,隐藏层hl3的特征的约束/加强程度可利用超参数p31y1~p3dy1来决定。如图3所示,隐藏层hl4可包含有神经元z41、z42、
…
、z4e,其中,e为正整数。因此,类似于神经元y2的输出值ty2,神经元y1的输出值ty1例如可满足ty1=g
(w41y1*tz41 w42y1*tz42
…
w4ey1*tz4e p31y1*tz31 p32y1*tz32
…
p3dy1*tz3d)。在此情况下,神经元z31~z3d的输出值tz31~tz3d可分别作为距离函数。
[0071]
举例来说,隐藏层hl3可包含有神经元k31、k32、
…
、k3d,其分别连接至神经元z31~z3d,且分别对应至超参数p31、p32、
…
、p3d。也就是说,神经元k31~k3d约束/加强隐藏层hl3的特征的程度可利用超参数p31~p3d来决定。类似于神经元z21的输出值tz21,神经元z31的输出值tz31例如可满足tz31=g(w2131*tz21 w2231*tz22
…
w2c31*tz2c p31*tk31)。在此情况下,神经元k31的输出值tk31可作为距离函数。
[0072]
在一实施例中,神经元y3的输出值ty3可相关于或对应至网络效能关键绩效指标的丢包,其可指封包无法通过网络到达目的地。具体而言,在网络中,不可避免地会有一些偶然的封包丢失。此外,随着在网络上移动的封包数量的增加,节点可能无法处理其面临的封包数量,使得部分或全部的封包被拒绝或丢弃。在一实施例中,丢包主要是由于网络层所引起的,因此类似地,可针对隐藏层hl3引入注意力机制,也就是说,位在第三层的隐藏层hl3的神经元(也可称为第三神经元)(例如神经元z31)直接连接至一个输出神经元(例如神经元y3)或一个辅助神经元(也可称为第三辅助神经元)(例如神经元k31)。
[0073]
在一实施例中,神经元y2的输出值ty2可相关于或对应至网络效能关键绩效指标的抖动。抖动可由于多个网络连接(即试图使用同一网络的多个封包)同时启动而引起的拥塞。在一实施例中,抖动主要是由于资料连结层所引起的,因此可针对隐藏层hl2引入注意力机制,也就是说,位在第二层的隐藏层hl2的神经元(也可称为第二神经元)(例如神经元z21)直接连接至一个输出神经元(例如神经元y2)或一个辅助神经元(也可称为第二辅助神经元)(例如神经元k21)。
[0074]
由此可知,神经网络30的隐藏层hl1~hl4可分别萃取出不同的特征,其可分别对应至开放式系统互联模型七层架构的不同层级。因此,当欲利用神经网络30来预测网络效能关键绩效指标时,可利用注意力机制来强化特定神经网络层(例如隐藏层hl2或hl3)的特征的影响,以提升推论准确度。
[0075]
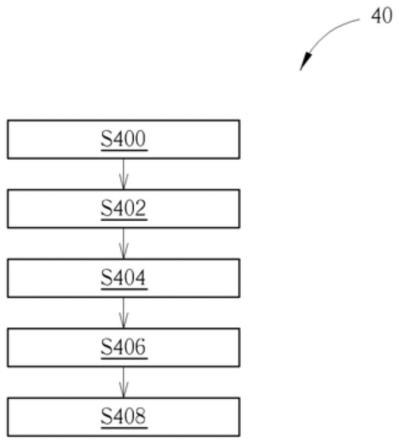
图4为本发明实施例一优化方法40的示意图。优化方法40可被编译成一程式码而由处理电路(例如图6的处理电路650)执行,并储存于储存电路(例如图6的储存电路670)中。优化方法40可包含有以下步骤:
[0076]
步骤s400:开始。
[0077]
步骤s402:训练一神经网络。
[0078]
步骤s404:调整该神经网络的复数个辅助神经元的复数个辅助输出值中的至少一个。
[0079]
步骤s406:利用该神经网络进行推论。
[0080]
步骤s408:结束。
[0081]
在优化方法40,神经网络可为神经网络20或30。或者,神经网络可包含有多个神经网络层,例如对应至fp读出函数的神经网络层(例如输入层nl、隐藏层hl1~hl4或输出层tl)、对应至递归函数rnnt的神经网络层或对应至ut更新函数的神经网络层,但不限于此。
[0082]
举例来说,步骤s402可对应至神经网络的训练(training)阶段。在步骤s402,可输入已知的多个第一资料至未经训练的神经网络,并将神经网络的输出值与第一资料的已知目标值(target)进行比较,如此一来,可重新评估而最佳化神经网络的参数(例如参数
w1121~w1b21、w2131~w2c31、w31y2~w3dy2、w41y1~w4ey1),以对神经网络进行训练,从而提高神经网络对所学习的任务的性能。举例来说,依据前向传播(forward propagation),可对应不同的参数自接收的第一资料计算出神经网络的输出值(例如输出值ty1~ty3)。神经网络的输出值可与目标值之间具有整体误差(total error),藉由例如反向传播(backpropagation,bp),可反复地更新所有的参数,而使神经网络的输出值逐渐接近目标值,来最小化整体误差,以最佳化参数而完成训练。
[0083]
其中,第一资料是指具有已知的目标值的资料。对于包含有对应至fp读出函数的神经网络层(例如神经网络20或30),第一资料可例如为特征度量yp为已知时的路径链路隐藏状态向量hp。
[0084]
在步骤s404,可微调(tune)已完成训练的神经网络的辅助神经元(例如神经元k21~k2c、k31~k3d)的辅助输出值(例如输出值tk21~tk2c、tk31~tk3d)。辅助神经元可指仅直接连接至一个神经元的神经元或仅直接连接至一个神经网络层的一个神经元的神经元。辅助神经元可用来引入注意力机制,而约束/加强特定神经网络层或特定神经元的特征。
[0085]
步骤s406可对应至神经网络的推论(inference)阶段,其是指应用已训练的神经网络的信息来推论结果。在步骤s402,当未知而欲判读的第二资料输入至神经网络时,神经网络可依据其最佳化的参数,对第二资料进行推论,以产生输出值(例如特征度量yp或输出值ty1~ty3),即输出预测。
[0086]
其中,第二资料是指欲判读的资料。对于包含有对应至fp读出函数的神经网络层(例如神经网络20或30),第二资料可例如为特征度量yp为未知时的路径链路隐藏状态向量hp。
[0087]
图5为本发明实施例一优化方法50的示意图。优化方法50可用来取代优化方法40,且可包含有以下步骤:
[0088]
步骤s500:开始。
[0089]
步骤s502:至少一神经网络的复数个辅助神经元的复数个辅助输出值被设定。
[0090]
步骤s504:该至少一神经网络的至少一超参数被设定。
[0091]
步骤s506:训练该至少一神经网络。
[0092]
步骤s508:部分执行一算法,其中,该至少一神经网络对应至该算法。
[0093]
步骤s510:判断该至少一神经网络的一输出值与网络效能关键绩效指标(key performance indicators,kpi)的关联。
[0094]
步骤s512:根据该输出值的类型,调整该至少一神经网络的复数个辅助神经元的复数个辅助输出值中的至少一个。
[0095]
步骤s514:根据该输出值的类型,调整该至少一神经网络的该至少一超参数。
[0096]
步骤s516:完成该算法的执行,其中,执行该算法涉及利用该至少一神经网络进行推论。
[0097]
步骤s518:结束。
[0098]
在步骤s502,本发明实施例可由人工(manual)设定神经网络(例如神经网络20或30)的辅助神经元(例如神经元k21~k2c、k31~k3d)的辅助输出值(例如输出值tk21~tk2c、tk31~tk3d),例如均设定至零。因此,辅助神经元不会影响步骤s506中神经网络的训练阶段。
[0099]
在步骤s504,本发明实施例可由人工设定神经网络(例如神经网络20或30)的超参数(例如超参数p21~p2c、p31~p3d、p21y2~p2cy2、p31y1~p3dy1)。因此,步骤s506中神经网络的训练阶段不会影响神经网络的超参数的值。也就是说,超参数是不受训练的(untrained)。
[0100]
在步骤s508,本发明实施例执行算法的局部(例如表一所示的算法的行号1至行号14)。在一实施例中,该至少一神经网络可为对应至算法的fp读出函数的神经网络(例如神经网络20或30)、对应至算法的rnnt递归函数的神经网络或对应至算法的ut更新函数的神经网络,但不限于此。
[0101]
在步骤s510,本发明实施例判断神经网络的输出值(例如输出值ty1~ty3)是否与网络效能关键绩效指标的延迟、丢包或抖动相关。
[0102]
在一实施例中,当神经网络的输出值相关于延迟或丢包时,则在步骤s512,可维持神经网络(例如神经网络30)中一部分的的辅助神经元(例如神经元k21~k2c)的辅助输出值(例如输出值tk21~tk2c),例如均维持为零。并且,在步骤s512,可调整神经网络(例如神经网络30)中另一部分的的辅助神经元(例如神经元k31~k3d)的辅助输出值(例如输出值tk31~tk3d),使得隐藏层hl3或隐藏层hl3的特定神经元(例如神经元k31)对输出层tl的神经元(例如神经元y1、y3)造成影响。
[0103]
在一实施例中,当神经网络的输出值相关于抖动时,则在步骤s512,可维持神经网络(例如神经网络30)中一部分的的辅助神经元(例如神经元k31~k3d)的辅助输出值(例如输出值tk31~tk3d),例如均维持为零。并且,在步骤s512,可调整神经网络(例如神经网络30)中另一部分的的辅助神经元(例如神经元k21~k2c)的辅助输出值(例如输出值tk21~tk2c),使得隐藏层hl2或隐藏层hl2的特定神经元(例如神经元k21)对输出层tl的神经元(例如神经元y2)造成影响。
[0104]
由此可知,步骤s512是根据神经网络(例如神经网络30)的输出值(例如输出值ty1~ty3)与网络效能关键绩效指标的关联来决定是否调整该神经网络的辅助神经元(例如神经元k21~k2c或k31~k3d)的复数个辅助输出值(例如输出值tk21~tk2c或tk31~tk3d)。
[0105]
在步骤s516,完成算法的执行(例如表一所示的算法的行号15)。
[0106]
上述仅为本发明的实施例,本领域技术人员当可据以做不同的变化及修饰。举例来说,在一实施例中,步骤s502、s504的顺序可以对调,步骤s512、s514的顺序可以对调。在一实施例中,步骤s514可省略。在一实施例中,步骤s508可在步骤s516一并执行。
[0107]
图6为本发明实施例中一优化器60的示意图。优化器60可用来取代优化器160。优化器60包含有一处理电路650以及一储存电路670。处理电路650可为中央处理器(central processing unit,cpu)、微处理器或专用集成电路(application-specific integrated circuit,asic),而不限于此。储存电路670可为用户识别模组(subscriber identity module,sim)、只读存储器(read-only memory,rom)、闪存(flash memory)或随机存取存储器(random-access memory,ram)、光盘只读存储器(cd-rom/dvd-rom/bd-rom)、磁带(magnetic tape)、硬盘(hard disk)、光学资料储存装置(optical data storage device)、非挥发性储存装置(non-volatile storage device)、非暂态电脑可读取介质(non-transitory computer-readable medium),而不限于此。
[0108]
综上所述,本发明利用神经网络及注意力机制来对网络效能关键绩效指标预测,
以实现路由优化、网络规划及快速故障恢复。
[0109]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。