基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法
技术领域
1.本发明属于雷达信号处理领域,具体涉及一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法。
背景技术:
2.安检作为机场、火车站、港口、大型活动场所等检查的关键一环,一直备受重视,随着我国安全检查技术得到前所未有的发展,安检智慧化日益提上日程,使用更加高科技的手段保障社会公共安全也成为共识。常见的金属安检门和手持式金属探测器等人体安检设备,存在着只能探测金属物品、效率低、人体触摸侵犯隐私等明显缺点。为了解决安检中这些问题,基于阵列雷达后向投影三维成像算法的视频安检仪获得了普遍关注。
3.雷达后向投影三维成像bp(back projection)算法是在垂直于二维阵列雷达成像平面的方向增加了新的合成孔径从而进行三维成像。两维的阵列雷达平面图是通过对回波信号作二维匹配滤波得到的,存在叠掩、阴影、伸缩等几何失真,造成空间三维信息的缺失。三维阵列雷达成像系统能够对观测场景进行三维重建,除具备距离-方位向的分辨能力之外,还能确定散射点在高度维的分布。
4.雷达后向投影三维成像算法串行成像过程如图1所示,基本的串行三维bp成像过程分为视频安检仪三维bp成像数据预加载、网卡响应函数pcap模块实时数据接收、三维bp成像、调用imagesc.dll对处理后回波数据成像。然而,三维bp算法的运算量正比于成像规模。每个雷达prf接收一帧图像数据,每帧图像的成像网格点数为n
×n×
n,后向投影成像算法的运算复杂度接近为o(n^4)。用串行方式实现雷达后向投影三维成像算法难以适用于数据规模较大以及实时性要求高的场合,不满足视频安检仪的高帧率要求。雷达成像方法往往采用基于多fpga(field programmable gate array)或dsp(digital signal processing)的硬件设计,由于fpga、dsp计算单元的限制,基于fpga、dsp架构设计出的雷达回波信号处理方法仍然存在时间较长的问题,难以满足视频工程需求。
技术实现要素:
5.为了解决现有技术中存在的上述问题,本发明提供了一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法。本发明要解决的技术问题通过以下技术方案实现:
6.本发明提供了一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,包括:
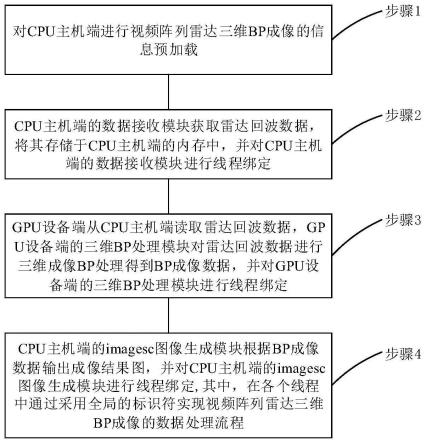
7.步骤1:对cpu主机端进行视频阵列雷达三维bp成像的信息预加载;
8.步骤2:所述cpu主机端的数据接收模块获取雷达回波数据,将其存储于所述cpu主机端的内存中,并对所述cpu主机端的数据接收模块进行线程绑定;
9.步骤3:gpu设备端从所述cpu主机端读取所述雷达回波数据,所述gpu设备端的三维bp处理模块对所述雷达回波数据进行三维成像bp处理得到bp成像数据,并对所述gpu设备端的三维bp处理模块进行线程绑定;
10.步骤4:所述cpu主机端的imagesc图像生成模块根据所述bp成像数据输出成像结果图,并对所述cpu主机端的imagesc图像生成模块进行线程绑定;
11.其中,在各个线程中通过采用全局的标识符实现视频阵列雷达三维bp成像的数据处理流程。
12.在本发明的一个实施例中,所述步骤1包括:
13.在所述cpu主机端载入三维bp参数,gpu设备端信息和雷达回波信号的背景信息,并预先调用matlb生成的imagesc.dll生成一副空图,同时对所述gpu设备端的核函数进行线程分块和三维网格划分。
14.在本发明的一个实施例中,所述步骤2包括:
15.步骤2.1:所述cpu主机端的数据接收模块利用网口响应函数pcap类中的相关函数,对视频阵列雷达端口数据进行过滤和数据重排后得到所述雷达回波数据,并将其存储于所述cpu主机端的内存中;
16.步骤2.2:通过thread类的相关函数对所述cpu主机端的数据接收模块进行线程绑定,绑定的线程记为thread1。
17.在本发明的一个实施例中,所述网口响应函数pcap类中的相关函数包括:pcap_findalldevs函数、pcap_freealldevs函数、pcap_open_live函数、pcap_compile函数、pcap_setfilter函数、pcap_loop函数和packet_handler回调函数。
18.在本发明的一个实施例中,在步骤2.1中,所述cpu主机端的数据接收模块通过乒乓操作,将获取的所述雷达回波数据存储于所述cpu主机端的内存中对应的第一数据缓冲模块和第二数据缓冲模块中。
19.在本发明的一个实施例中,所述步骤3包括:
20.步骤3.1:所述gpu设备端从所述cpu主机端读取所述雷达回波数据;
21.步骤3.2:所述gpu设备端的三维bp处理模块利用核函数对所述雷达回波数据进行背景校验和相位补偿,构建雷达与目标的坐标系,计算雷达与目标的位置信息,实现雷达和目标的投影得到所述bp成像数据;
22.步骤3.2:通过thread类的相关函数对所述gpu设备端的三维bp处理模块进行线程绑定,绑定的线程记为thread2。
23.在本发明的一个实施例中,所述核函数包括kernel_sub核函数、kernel_exp核函数和kernel_3dbp核函数,其中,
24.所述kernel_sub核函数,用于对所述雷达回波数据进行背景校验处理;
25.所述kernel_exp核函数,用于对背景校验处理后的雷达回波数据进行距离向相位补偿;
26.所述kernel_3dbp核函数,用于构建雷达与目标的三维坐标系,计算雷达与目标的位置信息,实现雷达和目标的投影得到所述bp成像数据。
27.在本发明的一个实施例中,所述核函数还包括kernel_gnr核函数,若所述雷达回波数据为实部虚部分离的形式,利用所述kernel_gnr核函数对所述雷达回波数据的实部虚部进行结合,得到复数信号形式的雷达回波数据。
28.在本发明的一个实施例中,所述步骤4包括:
29.步骤4.1:所述cpu主机端获取所述gpu设备端的bp成像数据,并生成imagesc.dll
文件,所述cpu主机端的imagesc图像生成模块调用matlab生成的imagesc.dll文件输出成像结果图;
30.步骤4.2:通过thread类的相关函数对所述cpu主机端的imagesc图像生成模块进行线程绑定,绑定的线程记为thread3。
31.与现有技术相比,本发明的有益效果在于:
32.1.本发明的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,避免了串行处理阵列雷达回波数据耗时较长,处理效率不足无法实时处理的问题;
33.2.本发明的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,选择gpu设备端进行三维bp成像的并行计算,针对数据之间有依赖性导致不适合在数据处理时进行gpu加速的操作,通过cpu主机端的多线程进行数据加速处理,针对与实时处理无关的数据处理以及线程分块,尽量在预加载模块进行,避免视频阵列雷达处理过程中的冗余,针对无法在gpu实现的收数模块与imagesc模块,通过绑定cpu主机端的线程进行数据处理,减少各个cpu主机端线程并行处理的效率损失,减少了运算耗时,从而实现实时处理;
34.3.本发明的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,在雷达后向投影成像算法中对由gpu处理的处理流程进行任务划分,通过各个线程之间的异步处理,隐藏各个线程的访存延迟,在各个绑定的线程处理实时流程中的不同任务,减少运行时间。
35.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
36.图1是本发明实施例提供的一种由cpu主机端串行处理阵列雷达回波数据的流程图;
37.图2是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法的示意图;
38.图3是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理系统的结构连接图;
39.图4是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法的流程示意图;
40.图5是本发明实施例提供的openmp工作模型示意图;
41.图6是本发明实施例提供的gpu内存与线程关系示意图;
42.图7a是本发明实施例提供的核函数kernel1-kernel3的线程分配示意图;
43.图7b是本发明实施例提供的核函数kerne4的线程分配示意图;
44.图7c是本发明实施例提供的aos和soa两种数据结构体组织方式对应距离向和方位向优先存储方式示意图;
45.图8a是本发明实施例提供的一种待成像的雷达回波数据的示意图;
46.图8b是采用本发明成像处理方法得到的成像结果图;
47.图9是采用cpu主机端串行处理方法得到的成像结果图。
具体实施方式
48.为了进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及具体实施方式,对依据本发明提出的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法进行详细说明。
49.有关本发明的前述及其他技术内容、特点及功效,在以下配合附图的具体实施方式详细说明中即可清楚地呈现。通过具体实施方式的说明,可对本发明为达成预定目的所采取的技术手段及功效进行更加深入且具体地了解,然而所附附图仅是提供参考与说明之用,并非用来对本发明的技术方案加以限制。
50.实施例一
51.请结合参见图2-4,图2是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法的示意图;图3是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理系统的结构连接图;图4是本发明实施例提供的一种基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法的流程示意图。如图所示,本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,包括:
52.步骤1:对cpu主机端进行视频阵列雷达三维bp成像的信息预加载;
53.步骤2:cpu主机端的数据接收模块获取雷达回波数据,将其存储于cpu主机端的内存中,并对cpu主机端的数据接收模块进行线程绑定;
54.步骤3:gpu设备端从cpu主机端读取雷达回波数据,gpu设备端的三维bp处理模块对雷达回波数据进行三维成像bp处理得到bp成像数据,并对gpu设备端的三维bp处理模块进行线程绑定;
55.步骤4:cpu主机端的imagesc图像生成模块根据bp成像数据输出成像结果图,并对cpu主机端的imagesc图像生成模块进行线程绑定。
56.在本实施例中,在各个线程中通过采用全局的标识符实现视频阵列雷达三维bp成像的数据处理流程。
57.本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法适用于基于cpu与gpu异构平台的视频安检仪,该视频安检仪包括连接的cpu主机端和gpu设备端,具体地,cpu主机端包括:cpu主机端的视频阵列雷达数据预加载模块,cpu主机端的数据接收模块,以及cpu主机端的imagesc图像生成模块;gpu设备端包括:gpu设备端的三维bp处理模块。
58.需要说明的是,在本实施例中,cpu主机端控制gpu设备端,一个cpu主机端可以读取多个gpu设备端信息,一个cpu主机端具体控制gpu设备端的数目取决于cpu主机端主机上接口数目。
59.每个gpu设备端根据对应的cpu主机端为其分配的内存按照方位向分块从对应的cpu主机端读取相应数据块大小的雷达回波数据(距离向优先存储)以及三维bp参数,将三维bp参数从对应的cpu主机端读取至gpu设备端的常量存储区中,将自适应分块雷达回波数据从对应的cpu主机端读取至gpu设备端的全局内存中;通过多个cpu主机端控制多个gpu设备端,在每个gpu设备端上完成距离向脉冲压缩、进行bp成像所需的参数计算、利用插值实现回波脉冲的升采样,cpu主机端将各个cpu服务器的雷达后向投影成像算法中的参数计算结果以及升采样后的回波脉冲分给不同的gpu设备端,通过gpu设备端反复执行投影与积
累,实现三维bp成像,然后利用cpu主机端的imagesc图像生成模块输出成像结果图。
60.进一步地,对本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法进行具体说明。
61.在本实施例中,利用cpu主机端的视频阵列雷达数据预加载模块实现视频阵列雷达三维bp成像的信息预加载。
62.具体地,步骤1包括:
63.在cpu主机端载入三维bp参数,gpu设备端信息和雷达回波信号的背景信息,并预先调用matlb生成的imagesc.dll生成一副空图,同时对所述gpu设备端的核函数进行线程分块和三维网格划分。
64.其中,gpu设备端信息包括显卡型号、设备计算能力、全局内存总量、设备的网格块线程划分的上下限。
65.需要说明的是,利用cpu主机端的视频阵列雷达数据预加载模块实现视频阵列雷达三维bp成像的信息预加载,只需在最开始进行数据处理时执行一次,后续不再执行该步骤。
66.在本实施例中,通过在cpu主机端预先加载雷达回波信号的背景信息,对后续补偿的相位预先进行计算,方便后续处理;在cpu主机端预先调用matlb生成的imagesc.dll生成一副空图,可以防止后续调用中出现调用时间过长,无法满足视频阵列雷达处理流程;另外,根据三维bp处理模块的数据量的大小事先对gpu设备端的核函数进行线程分块以及完成三维网格的划分,可以最大程度上减少视频阵列雷达实时处理过程中的冗余。
67.可选地,可以根据雷达三维后向投影成像算法的性能要求,将雷达后向投影成像算法相关参数封装为类,后续使用过程中可以根据具体的成像需求更改这部分成像相关参数。
68.进一步地,步骤2包括:
69.步骤2.1:cpu主机端的数据接收模块利用网口响应函数pcap类中的相关函数,对视频阵列雷达端口数据进行过滤和数据重排后得到雷达回波数据,并将其存储于cpu主机端的内存中;
70.在本实施例中,网口响应函数pcap类中的相关函数包括:pcap_findalldevs函数、pcap_freealldevs函数、pcap_open_live函数、pcap_compile函数、pcap_setfilter函数、pcap_loop函数和packet_handler回调函数。
71.其中,pcap_findalldevs函数的功能是获取本地机器设备列表,并选择进入捕获到的设备;pcap_freealldevs函数的功能是释放设备列表,结束程序;pcap_open_live函数的功能是进入pcap_findalldevs函数选择的设备中,并打开该设备的嗅探会话,捕获不同数据链路层的每个数据包的全部内容;pcap_compile函数的功能是编译数据过滤规则,并利用pcap_setfilter函数设置具体的过滤类型,在本实施例中,选择的过滤规则为ip地址过滤以及数据包类型过滤,即只接收过滤得到的固定ip地址上发送的udp数据包;pcap_loop函数的功能是令设备保持实时嗅探状态,即只要满足上述过滤规则,就利用编写的packet_handler回调函数将每一包udp数据保存在cpu主机端的内存中。
72.在本实施例中,cpu主机端的数据接收模块通过乒乓操作,将获取的雷达回波数据存储于cpu主机端的内存中对应的第一数据缓冲模块和第二数据缓冲模块中。
73.具体地,在cpu主机端的内存中开辟两个大小相同地址不同的内存作为第一数据缓冲模块和第二数据缓冲模块,当第一数据缓冲模块接收足够的数据后,第二数据缓冲模块开始接收数据,在缓冲模块内部通过标识符控制,相应地,在后续步骤3的三维成像bp处理过程中,通过一个全局的标识符予以确定gpu设备端从cpu主机端读取雷达回波数据时读取第一数据缓冲模块或是第二数据缓冲模块中的雷达回波数据。在cpu主机端完成乒乓数据的搬移,可以避免在帧头校验与数据的重新排列中对收数线程效率产生影响。
74.在本实施例中,在数据重排中可以通过openmp进行多线程加速,openmp是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括c、c 和fortran。请结合参见图5,图5是本发明实施例提供的openmp工作模型示意图,如图所示,开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。openmp提供了对并行算法的高层抽象描述,特别适合在多核cpu机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用openmp降低了并行编程的难度和复杂度。当编译器不支持openmp时,程序会退化成普通(串行)程序,而且程序中已有的openmp指令不会影响程序的正常编译运行。在本实施例中,openmp采用fork-join的执行模式。
75.需要说明的是,在本实施例中,对没有数据依赖性且循环体量较大的操作流程选择gpu设备端使用cuda加速。
76.步骤2.2:通过thread类的相关函数对cpu主机端的数据接收模块进行线程绑定,绑定的线程记为thread1。
77.在本实施例中,通过利用thread类的相关函数对cpu主机端的数据接收模块进行线程绑定,无论其他线程的状态如何,该线程(thread1)保持实时接收数据,避免了实时处理过程中的线程阻塞导致效率损失的问题。
78.进一步地,步骤3中所述的三维成像bp处理是通过雷达后向投影三维成像bp(back projection)算法实现三维成像。后向投影算法是根据雷达回波信号时间延迟在雷达回波信号的脉压回波中执行反向插值操作,可以对任意成像几何构型下的回波数据进行目标重建。三维bp算法通过斜距建立了雷达回波信号与成像场景之间的映射关系,可以直接在目标区对区域进行成像网格区域设置,随后以网格点到雷达间的距离为纽带,反向寻找当前回波脉冲网格点的贡献。每执行一次反投影操作,即可得到雷达回波信号对网格点处场景信息的一次描述。遍历所有方位脉冲,并将不同回波脉冲的投影结果进行相干累积,即可重建目标场景,完成图像聚焦。bp算法基于斜距逐脉冲逐网格点执行反向投影,只要能精确获知雷达天线相位中心在目标网格点p的距离(瞬时斜距)与成像网格点坐标,即可实现回波数据的无失真图像聚焦,因此,bp算法能结合场景信息实现三维成像。
79.具体地,步骤3包括:
80.步骤3.1:gpu设备端从cpu主机端读取雷达回波数据;
81.步骤3.2:gpu设备端的三维bp处理模块利用核函数对雷达回波数据进行背景校验和相位补偿,构建雷达与目标的坐标系,计算雷达与目标的位置信息,实现雷达和目标的投影得到bp成像数据;
82.在本实施例中,核函数包括kernel_sub核函数、kernel_exp核函数和kernel_3dbp核函数。其中,kernel_sub核函数(kernel2)用于对雷达回波数据进行背景校验处理,即在
雷达回波数据的基础上对其进行背景数据相减即可得到;kernel_exp核函数(kernel3)用于对背景校验处理后的雷达回波数据进行距离向相位补偿,即针对做完距离向傅里叶变化的雷达回波数据,复乘一个相位,完成雷达回波数据的距离向相位补偿;kernel_3dbp核函数(kernel4)用于构建雷达与目标的三维坐标系,计算雷达与目标的位置信息,实现雷达和目标的投影得到bp成像数据,即构建雷达与目标的三维坐标系,计算目标距离雷达位置信息;完成雷达天线中心相位与目标瞬时斜距的计算;针对雷达和目标实现投影,以完成距离向相位补偿,并最终完成bp成像得到bp成像数据。
83.进一步地,核函数还包括kernel_gnr核函数,若雷达回波数据为实部虚部分离的形式,利用kernel_gnr核函数(kernel1)对雷达回波数据的实部虚部进行结合,得到复数信号形式的雷达回波数据。
84.具体地,在为雷达位置建立三维坐标时,有两种数据组织方式,不同的数据组织方式会对核性能有不同的影响,请参见图7c,图7c是本发明实施例提供的aos和soa两种数据结构体组织方式对应距离向和方位向优先存储方式示意图,如图所示,第一种方式为数据结构体(aos),对应着雷达回波数据的方位向优先存储;第二种方式为结构体数组(soa),对应着雷达回波数据的距离向优先存储。aos数据组织方式会导致在访问雷达坐标位置x数组、y数组、z数组过程中出现非对齐非连续访存,严重影响内存的读写速度,降低核性能。而使用soa数据组织方式有效避免aos的弊端,在存储雷达位置坐标的同时可以进行对齐连续的内存访问,使得核性能更加高效。
85.请结合参见图7a和图7b,图7a是本发明实施例提供的核函数kernel1-kernel3的线程分配示意图;图7b是本发明实施例提供的核函数kerne4的线程分配示意图。如图所示,gpu设备端的核函数内部存在两种索引,第一种是索引线程的横向分布,表示目标场景距离向的目标点,记作idx,计算方式为nrn=blockidx.x*blockdim.x threadidx.x,其中blockidx.x对应各个线程块,blockdim.x对应各个线程块所对应的维度,threadidx.x则对应各个维度线程块中的线程束索引,线程束数量为16的倍数即可。第二种是索引线程的纵向分布,表示目标场景方位向分块的目标点,记作idy,计算方式为nan=blockidx.y*blockdim.y threadidx.y;其中blockidx.y对应各个线程块,blockdim.y对应各个线程块所对应的维度,threadidx.y则对应各个维度线程块中的线程束索引,线程束数量为16的倍数即可。
86.在本实施例中,由线程的索引确定雷达目标点的三维坐标,将计算结果按行存储在gpu显存中开辟好的数组里,调用核函数计算时按行调用,形成对齐连续的访存,减少了跨内存访问,保证了处理距离向优先存储数据的核函数有良好的核性能,根据线程索引确定每个雷达回波数据方位向分块的起始点坐标。
87.如图3和图4所示,在本实施例中,可选地,对视频阵列雷达三维bp成像进行任务划分,并分析数据依赖性,若kernel1、kernel2、kernel3、kernel4所处理的数据具有数据依赖性,可以先将其分配到的gpu设备端上通过逐个核函数依次运行。kernel4需要等待前面三个核函数完成运算后再进行运算,可以将kernel1与kernel2、kernel3置于同一工作流下,尽可能减少gpu设备端与cpu主机端数据传输的耗时,在完成上述核函数操作后,利用kernel4完成视频阵列雷达三维bp成像。
88.步骤3.2:通过thread类的相关函数对gpu设备端的三维bp处理模块进行线程绑
定,绑定的线程记为thread2。
89.需要说明的是,gpu设备端的三维bp成像模块完全在gpu设备端进行,用于构建针对雷达以及目标的坐标系,计算雷达目标的位置信息,以便于针对目标和雷达实现投影;根据预先设定的bp成像的有效成像区域,确定回波相干积累的区域;划分地面网格,即对所有的网格点执行同样的投影和积累操作,实现图像聚焦;确定回波脉冲对各个网格点的贡献,进行距离向相位补偿,实现bp成像。
90.进一步地,步骤4包括:
91.步骤4.1:cpu主机端获取gpu设备端的bp成像数据,并生成imagesc.dll文件,cpu主机端的imagesc图像生成模块调用matlab生成的imagesc.dll文件输出成像结果图;
92.具体地imagesc.dll文件生成步骤如下:进入要生成dll文件的matlab文件所在的路径,在matlab命令行输入mex-setup与mex-mbuild,后续通过deploytool工具选择library compiler编译,分别生成release与debug运行版本下的dll文件,根据程序运行需求,将各个运行版本的lib、h、dll三种文件分别放在不同的运行版本下即可。
93.步骤4.2:通过thread类的相关函数对cpu主机端的imagesc图像生成模块进行线程绑定,绑定的线程记为thread3。
94.在本实施例中,通过对各个计算模块的线程绑定,可以实现实时处理流程中任务级别并行。gpu内存与线程关系示意图如图6所示,为避免线程冲突,在各个线程中正确采用全局的标识符,通过while(1)实现视频阵列雷达三维bp成像的数据处理流程,thread1通过对端口的实时监听保持工作状态,而thread2与thread3内部通过while(1)的添加保持视频阵列雷达三维bp成像的流水工作。
95.本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,避免了避免了串行处理阵列雷达回波数据耗时较长,处理效率不足无法实时处理的问题。选择gpu设备端进行三维bp成像的并行计算,针对数据之间有依赖性导致不适合在数据处理时进行gpu加速的操作,通过cpu主机端的多线程进行数据加速处理,针对与实时处理无关的数据处理以及线程分块,尽量在预加载模块进行,避免视频阵列雷达处理过程中的冗余,针对无法在gpu实现的收数模块与imagesc模块,通过绑定cpu主机端的线程进行数据处理,减少各个cpu主机端线程并行处理的效率损失,减少了运算耗时,从而实现实时处理;
96.本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法,在雷达后向投影成像算法中对由gpu处理的处理流程进行任务划分,通过各个线程之间的异步处理,隐藏各个线程的访存延迟,在各个绑定的线程处理实时流程中的不同任务,减少运行时间。
97.进一步地,通过仿真实验对本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法的效果进行进一步说明。
98.仿真实验1
99.采用cpu主机端串行处理方法设计实测数据仿真。
100.仿真实验参数:脉冲回波点数128*128*30、脉冲回波周期20e-6s、脉冲回波带宽7.2e 9、脉冲回波频率6e 6、成像点数为96*96*12。
101.仿真步骤如图1所示的由cpu主机端串行处理阵列雷达回波数据的流程图,在cpu主机端上串行处理雷达回波信号数据时,1)首先在cpu主机端进行视频安检仪三维bp成像
的数据预加载;将阵列雷达回波形成需要的仿真参数封装为类,程序中包含头文件直接调用即可,另外完成相位计算以及背景信息的预先加载;2)cpu主机端利用网口响应函数pcap类接收每一帧图像对应的回波数据;3)对接收的每一帧图像的数据进行背景校验以及相位补偿、包括构建针对雷达以及目标的坐标、根据三维网格的划分投影、其中三维bp成像有效区域的划分通过事先定义直接读取,并最终利用三维bp成像,得到bp成像数据;4)cpu主机端直接调用imsgesc函数输出成像结果图。
102.仿真实验1对如图8a所示的一种待成像的雷达回波数据进行处理后的结果如图9所示,图9是采用cpu主机端串行处理方法得到的成像结果图。
103.仿真实验2
104.采用本实施例一的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法设计实测数据仿真。
105.仿真实验参数:脉冲回波点数128*128*30、脉冲回波周期20e-6s、脉冲回波带宽7.2e 9、脉冲回波频率6e 6、成像点数为96*96*12。
106.仿真步骤为:
107.1)cpu主机端进行视频阵列雷达三维bp成像的数据预加载;
108.2)cpu主机端利用网口响应函数pcap类接收视频阵列雷达回波数据;
109.3)gpu设备端bp成像的参数计算:包括对接收的每一帧图像的数据进行背景校验以及相位补偿、包括构建针对雷达以及目标的坐标、根据三维网格的划分投影、其中三维bp成像有效区域的划分通过事先定义直接读取、并最终利用三维bp成像,得到bp成像数据;
110.4)cpu主机端调用matlab生成的imsgesc.dll输出成像结果图。
111.具体地,对整个数据处理流程中的核函数进行说明,包括gpu设备端针对各个核函数中网格和块的划分:trdnum和blknum;各个核函数的意义以及核函数各个接口的封装,以及分配的gpu设备端内存大小。
112.其中trdnum和blknum分别代指cuda软件架构中的网格和线程块,相当于将gpu计算资源分为若干网格,每个网格中人为可以划分最多三维的若干线程块,每个线程块则可以人为的划分最多三维的若干线程,最终一个cuda的并行程序会被多个划分好的线程来执行。
113.gpu设备端数量为1,gpu的显存大小为10g,该配置足够处理目前条件下的雷达回波数据量,考虑到在相位补偿时会临时计算一些辅助数据,辅助数据的计算占用额外的gpu内存,此时需要考虑显存的最大利用率,利用cpu主机端读取的gpu设备端信息,合理分配gpu设备端内存。
114.为每个核函数配置线程,实现线程级并行,在遵循一定原则的基础上保证核函数拥有最优的性能;明确核内索引内容和数据组织方式,优化核函数内部计算,使核函数性能达到最优。为每个核函数配置网格块线程,进行配置应遵循以下原则,保证核函数有较好的性能:
115.(1)为核函数配置的网格和块在x,y,z各个维度的长度不应超过gpu设备端的极限,需要注意的是,并不是配置越接近gpu设备极限性能就越好。
116.(2)为每个核函数配置的线程数应为32的整倍数,优选地,大于4*32个线程。因为gpu在硬件流多处理器sm上处理线程是以一个线程束(warp)为单位来处理的。一个线程束
由32个线程组成,将四个线程束置于硬件流多处理器sm上来并行处理,可以有效隐藏访存延迟,提升核性能。放置在硬件流多处理器sm上的线程束越多,隐藏访存延迟的效果越好。
117.(3)每个核函数的性能会受到配置的影响,使用不同的配置运行核函数,利用工具多次测试核函数的运行时间,可得到耗时最短时的配置。
118.gpu设备端的内存分布与网格、块、线程之间的关系如图7a和图7b所示。对在gpu设备端上所使用的核函数、核函数功能、核函数变量和核函数分配空间进行说明:
119.kernel1核函数名称为kernel_gnr,功能为将读取得到的雷达回波信号数据的实部和虚部进行组合,生成完整的复数信号。其块内配置线程为genechothread(512,1),网格内配置块为genechoblocks(((nan genechothread))/(genechothread.x),genechothread.y),含义是创建一个大小为((nan genechothread))/(genechothread.x)*genechothread.y)的线程网格,其中线程网格的单位是线程块,块内配置128*1个线程,可根据线程的配置而自动对块的配置进行调整,示意图如图7a。在核内建立线程索引,设置线程索引为idx、idy,分别对应距离向和方位向索引,根据核的配置,idx索引由线程x方向偏移、块x方向偏移以及块的大小共同决定,核函数idx索引计算方式为idx=blockidx.x*blockdim.x threadidx.x,其中blockidx.x对应genechoblocks.x中各个线程块索引,blockdim.x对应genechoblocks.x中各个线程块所对应的维度,threadidx.x则对应genechoblocks.x中各个维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,nr]为距离向索引;idy索引由块的大小数目决定,核函数idy索引计算方式为idy=blockidx.y,其中blockidx.y对应genechoblocks.y中各个线程块索引,blockdim.y对应genechoblocks.y中各个线程块所对应的维度,threadidx.y则对应genechoblocks.y中各个维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,na]为方位向索引,代表方位向。使用上述索引遍历gpu显存中的变量地址空间,为gpu显存所开辟数组的数组元素赋值和数据计算。使用此索引遍历数据地址空间,为数组元素赋值和进行数据计算。为该kernel1核函数分配的数组变量分别为d_recho,d_iecho,d_echo,nr,其中recho代表数据实部,iecho代表数据虚部,echo代表复数数据,nr代表数据存储的距离向长度;分配的gpu显存空间为sizeof(float)*na*nr,sizeof(float)*na*nr,sizeof(c_float)*na*nr;其中c_float为cuda_complex.cuh定义的实部虚部为float的复数信号。
[0120]
kernel2核函数名称为kernel_sub,功能为针对做完校验与重排的视频阵列雷达回波数据,做背景校验,即在现有回波的基础上对数据进行背景数据相减即可。其中,为该函数分配的数组变量是d_echo,d_echo_0、nr,na,其中,echo为每一帧图像对应的回波数据,nr为方位向长度,na为距离向长度、echo_0为该处理流程下的背景信息;分配的空间为sizeof(c_float)*na*nr,sizeof(c_float)*na*nr,c_float表示复数的float信号,nr与na分别表示距离向和方位向大小,利用每一帧回波数据与背景信息相减,完成背景校验。
[0121]
其在块内配置线程为kernel_subthread(512,1),网格内配置块为kernel_subblocks(((nan pkernel_subthread))/(kernel_subthread.x),kernel_subthread.y),含义是创建一个大小为((nan kernel_subthread))/(kernel_subthread.x)*kernel_subthread.y的线程网格,其中线程网格的单位是线程块,块内配置512*1个线程,可根据线程的配置而自动对块的配置进行调整,示意图如图7a所示。在核内建立线程索引,设置线程索引为idx、idy,分别对应距离向和方位向索引,根据核的配置,idx索引由线程x方向偏移、
块x方向偏移以及块的大小共同决定,核函数idx索引根据核的配置该索引由线程x方向偏移、块x方向偏移以及块的大小共同决定;计算方式为idx=blockidx.x*blockdim.x threadidx.x,其中blockidx.x对应kernel_subblocks.x中各个线程块,blockdim.x对应kernel_subblocks.x中各个线程块所对应的维度,threadidx.x则对应kernel_subblocks.x中各维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,nr];核函数idy索引计算方式idy=blockidx.y,其中blockidx.y对应kernel_subblocks.y中各个线程块索引,blockdim.y对应kernel_subblocks.y中各个线程块所对应的维度,threadidx.y则对应kernel_subblocks.y中各个维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,na]。使用上述索引遍历gpu显存中的变量地址空间,为gpu显存所开辟数组的数组元素赋值和数据计算。
[0122]
kernel3核函数名为kernel_exp,功能为完成针对做完距离向傅里叶变化的雷达回波数据,复乘一个相位,完成雷达回波数据的方位向相位补偿,其中,为该函数分配的数组变量是d_echo,xz_coe、nr,na,其中,echo为每一帧图像对应的回波数据,nr为方位向长度,na为距离向长度、xz_coe为该处理流程下的各个方位向需要补偿的相位;分配的空间为sizeof(c_float)*na*nr,sizeof(c_float)*na,c_float表示复数的float信号,nr与na分别表示距离向和方位向大小。
[0123]
其块内配置线程为kernel_expthread(512,1),网格内配置块为kernel_expblocks(((nan kernel_expthread))/(kernel_expthread.x),kernel_expthread.y),含义是创建一个大小为((nan kernel_expthread))/(kernel_expthread.x)*kernel_expthread.y的线程网格,其中线程网格的单位是线程块,块内配置128*1个线程,可根据线程的配置而自动对块的配置进行调整,示意图如图7a所示。在核内建立线程索引,设置线程索引为idx、idy,分别对应距离向和方位向索引,根据核的配置,idx索引由线程x方向偏移、块x方向偏移以及块的大小共同决定,核函数idx索引计算方式为idx=blockidx.x*blockdim.x threadidx.x在核内建立线程索引,设置线程索引为idx、idy,根据核的配置,索引由线程x方向偏移、块x方向偏移以及块的大小共同决定,计算方式为idx=blockidx.x*blockdim.x threadidx.x,其中blockidx.x对应kernel_expposblocks.x中各个线程块索引,blockdim.x对应kernel_expblocks.x中各个线程块所对应的维度,threadidx.x则对应kernel_expblocks.x中各个维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,nr]为距离向索引;核函数idy索引计算方式为idy=blockidx.y,其中blockidx.y对应kernel_expblocks.y中各个线程块索引,blockdim.y对应kernel_expblocks.y中各个线程块所对应的维度,threadidx.y则对应kernel_expblocks.y中各个维度线程块中的线程束索引,线程束数量为16的倍数即可,索引范围是[0,na]为方位向索引,代表方位向。使用上述索引遍历gpu显存中的变量地址空间,为gpu显存所开辟数组的数组元素赋值和数据计算。使用此索引遍历数据地址空间,为数组元素赋值和进行数据计算。
[0124]
kernel4核函数名称为kernel_3dbp,通过该核函数计算目标距离雷达位置信息,构建雷达与目标的三维坐标系;完成雷达天线中心相位与目标瞬时斜距的计算;针对雷达和目标实现投影;完成距离向相位补偿;并最终完成bp成像。
[0125]
其块内配置线程为kernel_3dbpthread(128,1,1),网格内配置块为kernel_
3dbpblocks(((nan kernel_3dbpthread))/(kernel_3dbpthread.x),kernel_3dbpthread.y,kernel_3dbpthread.z),含义是创建一个大小为((nan kernel_3dbpthread))/(kernel_3dbpthread.x)*kernel_3dbpthread.y*kernel_3dbpthread.z的线程网格,其中线程网格的单位是线程块,块内配置128*1*1个线程;可根据线程的配置而自动对块的配置进行调整,示意图如图7b所示。在核内建立线程索引,设置线程索引为idx、idy、idz,根据核的配置,该索引各个线程索引由线程方向偏移、块方向偏移以及块的大小共同决定;核函数idx索引计算方式为idx=blockidx.x*blockdim.x threadidx.x、idy=blockidx.y、idz=blockidx.z索引范围是[0,2*len],len为方位向选取的有效长度,其中blockidx.x、blockidx.y、blockidx.z对应kernel_3dbpblocks.x、kernel_3dbpblocks.y、kernel_3dbpblocks.z中不同维度各个线程块索引,blockdim.x、blockdim.y对应kernel_3dbpblocks.x、kernel_3dbpblocks.y中各个线程块所对应的维度,threadidx.x、threadidx.y则对应kernel_3dbpblocks.x、kernel_3dbpblocks.y中各个维度线程块中的线程束索引。使用上述索引遍历gpu显存中的变量地址空间,为gpu显存所开辟数组的数组元素赋值和数据计算。使用此索引遍历数据地址空间,为数组元素赋值并计算数据。
[0126]
分析视频阵列雷达三维bp成像的流程,明确各个任务之间的关系,依据任务的依赖性和独立性对任务进行划分。依赖性是指两个任务之间存在因果关系,部分或全部的数据互用。独立性是指两个任务交换处理顺序,对结果没有任何影响。将经过上述bp成像处理的雷达回波数据由matlab生成的dll文件中读取展示,如图8a所示,是本发明实施例提供的一种待成像的雷达回波数据的示意图,对回波信号进行处理得到的图像如图8b所示,图8b是采用本发明成像处理方法得到的成像结果图。
[0127]
相对于cpu主机端串行处理雷达回波数据,在gpu设备端并行处理雷达回波数据时,gpu设备端与cpu主机端不共享内存,且gpu不适合直接大量地读取cpu内存数据,所以需要通过cpu主机端将雷达回波数据传输至gpu设备端内存中,在多个gpu设备端存在的情况下,需要将仿真参数根据需要从cpu主机端传输至gpu设备端中的全局内存。在雷达回波数据计算过程中,结合gpu特点,利用gpu核函数调用gpu核函数并给核函数分配大量设备端线程,每个线程对应于每个雷达目标点在某个雷达扫描时刻的雷达回波数据,这些线程可在gpu核函数内部并行计算,完成大量数据的并行处理。
[0128]
对仿真实验1和仿真实验2的实验结果(图9和图8b)进行对比,可以看出,两者的成像结果无明显差别。但是,针对相同点数的天线回波数据仿真,串行三维bp成像耗时46.18s,而本实施例的基于cpu与gpu异构平台的视频安检仪三维实时成像处理方法耗时46ms,可以达到每秒十五帧的处理速度,达到视频安检仪的效果,加速比1003.9倍,有效减少运行耗时。
[0129]
应当说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的物品或者设备中还存在另外的相同要素。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的
还是间接的。
[0130]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。