一种quic协议下基于深度强化学习的视频流自适应传输方法
技术领域
1.本发明属于视频传输技术领域,特别涉及一种quic协议下基于深度强化学习的视频流自适应传输方法。
背景技术:
2.随着多媒体技术和智能终端的广泛应用,视频服务已经成为人们的学习工作以及娱乐生活的主要方式之一。在线视频服务商在视频流传输时通常根据网络和用户观看情况来自动调整视频传输的参数,以提升用户的观看体验(qoe)。在视频服务中,由于网络状态处于时刻变化中,动态的网络带宽影响着视频传输的码率决策过程,进而直接影响用户体验(qoe)。因此,如何准确预测用户端的网络带宽,以及如何制定最优的自适应传输策略以提升用户的观看体验是需要解决的主要难点。同时,现有方法也通过结合传输协议优化用户体验,quic连接建立延时低,改进了拥塞控制机制,支持连接迁移,在理论上具有比tcp更优的传输效果,正逐渐被应用于流媒体服务中。而现有方法集中于验证quic相比于http/2的传输高效性,在quic多路复用特性和视频传输的结合以及quic下的码率自适应算法研究较为缺乏。
3.在用户端带宽预测问题上,为了降低视频质量切换延迟并提升用户qoe,需要通过预测用户端的未来网络带宽,并结合当前网络状况来预取相关码率版本的视频块,这是一个时间序列预测问题。在带宽预测中,采用基于门控循环单元(gru)和基于卷积(cnn)的神经网络提取带宽数据的自相关特征,引入时间戳用来反映带宽数据存在的周期性,并通过注意力机制学习特征权重,进一步提高长期预测的性能,从而为后续视频自适应传输与播放提供较好的带宽估计,保证用户良好的体验质量。
4.在quic协议下的视频流自适应传输与播放问题上,为了提升quic下视频流传输的用户qoe,关键在于制定合理的自适应传输策略。基于固定规则的自适应码率算法无法实现自适应码率传输系统的性能最优化,具有一定的局限性。随着机器学习技术的不断发展,另一类基于强化学习的自适应码率实现方法受到关注。这类方法将不同形式的qoe模型定义为奖励函数,基于qoe奖励和网络环境进行码率决策,客户端能够从服务器端获取到当前网络状态下的最优码率的视频文件进行播放。但是由于网络带宽时变,这样容易导致视频的缓冲持续出现,在此基础上,结合quic协议0-rtt、多路复用等多种特性,在传输层对视频流的自适应进行进一步优化,很好地满足用户观看需求,提高用户视频观看体验。
5.据申请人检索和查新,检索到的以下几篇与本发明相关的属于视频传输领域的专利,它们分别是:
6.1.cn108063961a,一种基于强化学习的自适应码率视频传输方法以及系统。
7.2.cn112422441a,基于quic传输协议的拥塞控制方法和系统。
8.上述专利1提供了一种基于强化学习的自适应码率视频传输方法以及系统。该方法基于深度神经网络进行码率预测,将需要下载的视频块所对应的状态空间输入到码率预测神经网络,码率预测神经网络输出码率策略;根据码率预测神经网络输出的码率策略下
载需要下载的视频块;在每个视频块下载完毕后,计算其所对应的视频播放质量指标并返回给码率预测神经网络;码率预测神经网络依据返回的视频播放质量指标以及最近下载完成的视频块所对应的状态空间进行训练。该发明降低了规则设置和参数调优的人工时间成本,较大提高了视频质量体验。
9.上述专利2提供了基于quic传输协议的拥塞控制方法和系统。所述拥塞控制方法包括:从多个拥塞控制策略中选择目标拥塞控制策略;基于quic传输协议与目标终端建立目标quic连接;为所述目标quic连接匹配所述目标拥塞控制策略,以根据所述目标拥塞控制策略执行拥塞控制操作。也可以为每个待建立的quic连接动态选择一个拥塞控制策略,即在复杂易变的网络环境下动态地提供最优的拥塞控制策略,提升网络qos。
10.上述相关专利1利用深度强化学习预测将需要下载的视频块对应的状态空间输入到码率预测神经网络,输出码率策略,根据码率策略下载所需视频块。专利1所述状态空间包括视频块吞吐率、下载时间等信息,忽略了网络带宽信息对于视频观看质量的影响以及精确量测,因此当网络带宽变化剧烈时,该方法难以给出较好码率策略,影响用户qoe。专利2提供一种基于quic传输协议的拥塞控制策略,适应复杂多变的网络环境,提升网络服务质量。该专利仅在传输层进行优化,缺少将quic协议应用到视频自适应流的真实场景中。
技术实现要素:
11.为了克服上述现有技术的缺点,本发明的目的在于提供一种quic协议下基于深度强化学习的视频流自适应传输方法,通过在quic协议下用户端带宽预测、视频流码率自适应决策,以有效减少视频缓冲时间,提高用户观看体验。
12.为了实现上述目的,本发明采用的技术方案是:
13.一种quic协议下基于深度强化学习的视频流自适应传输方法,其特征在于,包括如下步骤:
14.步骤1,服务器端和客户端建立quic连接;
15.步骤2,在服务器端预测网络带宽;
16.步骤3,将带宽预测结果作为码率自适应决策的状态输入,客户端基于服务器端的码率自适应决策结果,选择码率对应的视频文件下载到缓冲区并解码;并在quic协议下,联合优化视频传输与播放,减少播放缓冲时间,提高qoe。
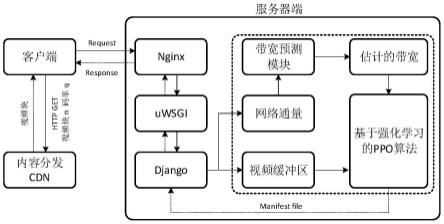
17.所述步骤1中,nginx接收到浏览器发送的http请求,将包进行解析;对于静态文件请求,直接访问客户端nginx配置的静态文件目录,返回客户端请求静态文件;对于动态接口请求,nginx将请求转发给uwsgi,最后到达django进行后续处理。
18.所述步骤2,在服务器端构建长窗口带宽预测模型,利用带宽历史数据预测网络带宽,所述长窗口带宽预测模型包括两个gru以及一个cnn,并添加注意力机制;其预测方法为:
19.步骤2.1,将带宽数据抽象为时间序列,利用第一个gru和cnn提取带宽数据特征,得到包含带宽数据时域特征和空域特征的时空特征矩阵利用连续的第一个和第二个gru提取带宽数据特征,得到包含带宽数据时域特征的时域特征矩阵h
′
t
;
20.步骤2.2,将时空特征矩阵作为注意力机制的输入向量,将时域特征矩阵h
′
t
作为注意力机制的查询向量,学习时空特征对于预测值的权重贡献,从而得到t 1时刻的带宽
预测结果y
t 1
。
21.所述长窗口带宽预测模型利用历史时间窗口中不同时间步的带宽历史数据预测网络带宽。
22.所述步骤2.1,包括:
23.将当前时刻t的历史带宽序列x
t
输入到第一个gru中,得到用于带宽预测的中间向量h
t
,表征为h
t
=gru(x
t
,θ
t
),其中,θ
t
表示gru内部gate的参数,包含了权重矩阵及偏置;
24.将h
t
作为cnn的输入,进行卷积处理,提取出历史带宽数据的周期性特征,计算式为其中,w表示过滤器的权重参数,b表示过滤器的偏置项,*表示卷积操作,σ表示激活函数;cnn的输出即将表示为行向量形式如下:
[0025][0026]
表示的第i维,对h
t
进行卷积操作后,得到的矩阵中包含带宽数据的时域特征和空域特征,称为时空特征矩阵;
[0027]
同时,将h
t
作为第二个gru的输入,得到h
′
t
,将表示为行向量形式如下:
[0028]h′
t
=[h
′
t1
,h
′
t2
,
…
,h
′
ti
,
…
]
[0029]h′
ti
表示h
′
t
的第i维;
[0030]
所述步骤2.2包括输入向量和查询向量h
′
t
的打分计算、权重值计算以及根据权重计算输出向量三个部分,其中:
[0031]
采用注意力打分机制中的加性模型计算得到分数集合s=[s1,s2,
…
,si,
…
,s
t
]的各元素,元素其中t是s中的元素个数,vs、w
ls
、w
cs
为注意力机制的待学习参数;
[0032]
采用sigmoid函数对元素si进行归一化,得到注意力分布,表示为αi=sigmoid(si),αi为元素si对应的权重;结合各元素的权重大小,将注意力分布附加在输入向量上,计算得到注意力机制模型的输出
[0033]
将h
′
t
与进行融合,得到t 1时刻的预测结果y
t 1
,计算式如下:
[0034][0035][0036]
其中wh,wa,wf表示需要学习的权重参数,表示模型输出的中间结果。
[0037]
所述步骤3包括:
[0038]
步骤3.1,将视频编码并分割成等长度的视频块,将视频块封装成视频文件,将全部视频文件以及媒体描述文件放置在配置好的流媒体服务器上;
[0039]
步骤3.2,服务器端将带宽预测结果作为码率自适应决策的一个状态空间,码率的选择基于actor-critic框架的强化学习算法ppo实现,通过状态state、动作action和奖励reward三个要素的交互,最终得到一个最优的码率自适应策略
[0040]
步骤3.3,客户端选择码率对应的视频文件下载到缓冲区并解码;并基于nginx的
平台,将quic协议的0-rtt特性与多路复用特性应用到视频码率自适应过程中,联合优化视频传输与播放。
[0041]
所述步骤3.1,采用h.264进行编码,封装的视频文件格式为mped-dash。
[0042]
所述步骤3.2,强化学习算法中,存在agent和环境两个交互对象,当agent采取一个动作action作用在环境上,环境会给予一个奖励reward作为反馈,以表明当前行动的价值;状态state包括第k次请求时的带宽预测值、第k次带宽占用率、第k次请求时剩余未传输的视频块数、过去若干次传输的视频块质量、过去若干个视频块的下载时间和第k次请求时可选择的码率列表;
[0043]
动作action指下一个视频块可选的视频码率级别,视频码率级别的集合构成动作空间a={300,750,1200,1850,2850,4300}kbp;
[0044]
为获取奖励reward,对奖励函数建模如下:
[0045]
qoek=λq(rk)-μ((b
k-dk)
l-δtk)-v|q(rk)-q(r
k-1
)|
[0046]
s.t.size(k)《n
[0047]
其中,qoek表示第k个视频块的质量,rk表示第k个视频块的码率级别,bk表示开始下载的第k个视频块时播放器缓冲区大小,bk∈(0,b
max
),b
max
表示播放器最大缓冲区大小,dk表示下载第k个视频块的时间,nk表示下载的第k个视频块的平均网络吞吐量,通过网络带宽预测模块计算得到,δtk=((b
k-bk)
l-b
max
)
,表示因为缓冲区溢出的等待时延,函数(x)
=max(x,0),(b
k-bk)
表示缓冲区缓存时间;λ、μ、v分别表示视频质量q(rk)、缓存时间((b
k-dk)
l-δtk)和视频平滑度|q(rk)-q(r
k-1
)|的加权参数,λ=1,μ=4.3,v=1;size(k)表示第k个视频块的大小,约束条件size(k)《n保证第k个视频块的大小不能超过当前的实际网络带宽n。
[0048]
利用构建的视频块的质量表示模型定义奖励函数,质量表示模型表示为rk=qoek,基于一个策略所获得的累计折扣奖励如下:
[0049][0050]
式中,k表示考虑k个连续动作,t表示第t时刻,γ为折扣因子,γ∈[0,1];
[0051]
定义随机策略π
θ
作为可选动作上的一个概率分布,定义策略的状态价值函数,表示对当前策略的期望总回报,如下:
[0052][0053]
最终目标是找到一个最优策略目标函数如下所示:
[0054][0055]
最优策略表示在k个时刻状态选择动作ak的概率,最优策略是使得期望总回报最大的策略。
[0056]
使用基于actor-critic框架的ppo算法寻找所述最优策略ppo算法对于策略的折扣累计回报的梯度计算如下所示:
[0057][0058]
其中,π
θ
(ak|sk)表示当前状态为sk时选择动作ak的概率是多少,π
θ
(ak|sk)取值范围在0~1之间;
[0059]
表示基于状态价值函数定义的动作优势函数,计算如下所示:
[0060][0061]
将agent和环境交互若干次形成的三元组《state,action,reward》组合成轨迹集合dk={s1,a1,r1;s2,a2,r2;
…
;sk,ak,rk},对于actor网络,基于目标策略的actor网络根据轨迹集合进行策略学习,并根据两个actor网络的kl距离来更新其参数,最大化目标函数和网络参数θ更新如下所示:
[0062][0063][0064]
其中,π
′
θ
(a
t
|s
t
)表示通过采样的数据得到的选择动作ak的概率,r(θ)衡量了采样前后两个分布的一致性,g(r(θ),ε)表示将r(θ)限制在[1-ε,1 ε]区间之内,ε为超参数,设置为0.2;
[0065]
对于critic网络,基于时序差分的方法更新其参数φ,具体计算如下所示:
[0066][0067]
至此,在ppo算法的基础上实现了视频自适应传输的框架与现有技术相比,本发明的有益效果是:
[0068]
本发明构建了一种高效的长窗口带宽预测模型,采用gru与cnn模块并结合注意力机制,提出一种高效的神经网络框架提取网络带宽特征,为后续基于深度强化学习的码率自适应决策提供有效特征输入。通过公开数据集以及真实环境验证,跟当下最新的方法进行比较,验证了所提方法的有效性,可以有效提取带宽特征,提高用户qoe。
[0069]
本发明首次将quic协议的特性与码率自适应决策结合使用。基于强化学习与ppo算法的码率决策方法,能够在复杂网络情况下,在尽可能提高带宽利用率情况下,减少视频缓冲时间,提高视频观看质量。结合quic协议优良特性,进一步优化视频传输与播放,为用户提供更好的视频观看体验。
附图说明
[0070]
图1是本发明结构示意图。
[0071]
图2是本发明算法流程图。
[0072]
图3是本发明带宽预测结果图,其中(a)为ghent数据集预测,(b)为ucc数据集预测。
[0073]
图4是本发明自适应决策效果对比示意图,其中(a)为单路传输性能对比,(b)为多路传输性能对比。
具体实施方式
[0074]
下面结合附图和实施例详细说明本发明的实施方式。
[0075]
如附图1和图2所示,本发明为一种quic协议下基于深度强化学习的视频流自适应传输方法,在搭建的基于nginx的平台上,主要实现高效的长窗口带宽预测,进而基于深度强化学习实现自适应码率决策,并结合quic协议的0-rtt、多路复用等特性减少视频缓冲,为用户良好的视频观看体验提供保障。
[0076]
具体地,本发明包括如下步骤:
[0077]
step1,服务器端和客户端建立quic连接,nginx接收到浏览器发送的http请求,将包进行解析。对于静态文件请求,直接访问客户端nginx配置的静态文件目录,返回客户端请求静态文件;对于动态接口请求,nginx将请求转发给uwsgi,最后到达django进行后续处理。
[0078]
step2,将视频采用h.264等方式进行编码并分割成固定大小(例如4s)的视频块,封装成mped-dash或其它格式的视频文件,将生成的全部视频文件以及媒体描述文件mpd放置在配置好的流媒体服务器上。
[0079]
step3,在服务器端构建长窗口带宽预测模型,利用带宽历史数据预测网络带宽。
[0080]
本步骤中,长窗口带宽预测模型包括两个gru以及一个cnn,利用历史时间窗口中不同时间步的带宽历史数据预测网络带宽。示例地,一般可以根据过去8个历史时刻的带宽数据预测未来4个时刻的带宽信息。
[0081]
其预测方法为:
[0082]
将带宽数据抽象为时间序列,序列包含了时间戳的特征,将过去的单维特征预测转化为多维特征预测。本发明利用第一个gru和cnn提取带宽数据特征,得到包含带宽数据时域特征和空域特征的时空特征矩阵利用连续的第一个和第二个gru提取带宽数据特征,得到包含带宽数据时域特征的时域特征矩阵h
′
t
。
[0083]
具体地,将当前时刻t的历史带宽序列x
t
输入到第一个gru中提取带宽数据的时域特征,得到用于带宽预测的中间向量h
t
,表征为h
t
=gru(x
t
,θ
t
),其中,θ
t
表示gru内部gate的参数,包含了权重矩阵及偏置,x
t
={x1,x2,
…
,x
t
},x
t
的每一个元素xi=[x
′1,x
′2,
…
,x
′
p
,yi]∈rn,yi表示i时刻的带宽数据。目标是根据历史带宽序列来预测t 1时刻的带宽数据y
t 1
,表达式为y
t 1
=γ(x
t
),γ(
·
)表示预测函数。
[0084]
将h
t
作为cnn的输入,进行卷积处理,提取出历史带宽数据的周期性特征,计算式为其中,w表示过滤器的权重参数,b表示过滤器的偏置项,*表示卷
积操作,σ表示激活函数;cnn的输出即将表示为行向量形式如下:
[0085][0086]
表示的第i维,对h
t
进行卷积操作后,得到的矩阵中包含带宽数据的时域特征和空域特征,称为时空特征矩阵;
[0087]
同时,将h
t
作为第二个gru的输入,得到h
′
t
,将表示为行向量形式如下:
[0088]h′
t
=[h
′
t1
,h
′
t2
,
…
,h
′
ti
,
…
]
[0089]h′
ti
表示h
′
t
的第i维。
[0090]
step4,添加注意力机制,将得到的时空特征矩阵和经过连续两个gru层提取得到的时域特征矩阵作为注意力机制的两个向量,学习时空特征对于预测值的权重贡献。
[0091]
具体地,将时空特征矩阵作为注意力机制的输入向量,将时域特征矩阵h
′
t
作为注意力机制的查询向量,学习时空特征对于预测值的权重贡献,从而得到t 1时刻的带宽预测结果y
t 1
。
[0092]
本步骤包括输入向量和查询向量h
′
t
的打分计算、权重值计算以及根据权重计算输出向量三个部分,其中:
[0093]
采用注意力打分机制中的加性模型计算得到分数集合s=[s1,s2,
…
,si,
…
,s
t
]的各元素,元素其中t是s中的元素个数,vs、w
ls
、w
cs
为注意力机制的待学习参数;
[0094]
接着采用sigmoid函数对元素si进行归一化,得到注意力分布,表示为αi=sigmoid(si),αi为元素si对应的权重;结合各元素的权重大小,将注意力分布附加在输入向量上,计算得到注意力机制模型的输出
[0095]
考虑到t时刻的带宽值与预测点的带宽值相关,将h
′
t
与进行融合,得到t 1时刻的预测结果y
t 1
,计算式如下:
[0096][0097][0098]
其中wh,wa,wf表示需要学习的权重参数,表示模型输出的中间结果。
[0099]
图3示出了采用本发明方法的带宽预测结果,结合其(a)和(b)可知,与现有方法相比,本发明在用户带宽预测偏差上降低了约10%,这是因为该发明采用lstm网络和卷积神经网络相结合的模型,很好地提取了带宽数据的时域特征和空域特征,同时基于注意力机制实现了特征的融合,以优化预测精度。
[0100]
step5,将得到的带宽预测结果作为码率自适应决策的状态输入,选择合适的码率。
[0101]
本步骤中,服务器端将带宽预测结果作为码率自适应决策的一个状态空间,码率的选择基于actor-critic框架的强化学习算法ppo实现,通过状态state、动作action和奖
励reward三个要素的交互,最终得到一个最优的码率自适应策略
[0102]
在强化学习中,存在agent和环境两个交互对象,agent和环境之间的交互过程可以看作一个马尔可夫决策过程;当agent采取一个动作action作用在环境上,环境会给予一个奖励reward作为反馈,以表明当前行动的价值。
[0103]
在本发明中,状态state包括第k次请求时的带宽预测值、第k次带宽占用率、第k次请求时剩余未传输的视频块数、过去若干次传输的视频块质量、过去若干个视频块的下载时间和第k次请求时可选择的码率列表。
[0104]
动作action指下一个视频块可选的视频码率级别,本发明视频码率级别的集合构成的动作空间a={300,750,1200,1850,2850,4300}kbp。
[0105]
为获取奖励reward,对于第k个视频块,考虑到视频块质量、播放器缓冲区的rebuffering时间、视频块质量切换的平滑度与等待时延的联合优化,建立第k个视频块的质量模型,即奖励函数,建模如下:
[0106]
qoek=λq(rk)-μ((b
k-dk)
l-δtk)-v|q(rk)-q(r
k-1
)|
[0107]
s.t.size(k)《n
[0108]
奖励函数分析如下,在视频流自适应传输过程中,视频进行多个码率编码后,在时间域上分割成k个固定时长(4s)的视频块,考虑每个视频块的qoe奖励。其中,qoek表示第k个视频块的质量,用符号r表示视频块的码率集合,rk表示第k个视频块的码率级别,第k个视频块的质量qk表示为:qk=q(rk),q(
·
)表示视频块的质量表示函数。定义了两种不同的质量表示模型:qoe
lin
:q
lin
(rk)=rk,qoe
ln
:q
ln
(rk)=ln(rk/r
min
),其中,r
min
表示r中最小的码率。
[0109]dk
表示下载第k个视频块的时间,nk表示下载的第k个视频块的平均网络吞吐量,通过网络带宽预测模块计算得到。因此,客户端下载完的第k个视频块时,播放器缓冲区占用b
k 1
可用b
k 1
=(b
k-bk)
l-δtk计算得出。
[0110]
δtk=((b
k-bk)
l-b
max
)
,表示因为缓冲区溢出的等待时延,bk表示开始下载的第k个视频块时播放器缓冲区大小,bk∈(0,b
max
),b
max
表示播放器最大缓冲区大小,函数(x)
=max(x,0)。(b
k-bk)
表示缓冲区缓存时间;λ、μ、v分别表示视频质量q(rk)、缓存时间((b
k-dk)
l-δtk)和视频平滑度|q(rk)-q(r
k-1
)|的加权参数,λ=1,μ=4.3,v=1;size(k)表示第k个视频块的大小,约束条件size(k)《n保证第k个视频块的大小不能超过当前的实际网络带宽n。
[0111]
在视频播放过程中,视频块相邻质量的切换也会影响用户的qoe,因此,在质量模型中加入视频平滑度,由sk=|q
k-q
k-1
|计算得出。
[0112]
本发明利用构建的视频块的质量表示模型定义奖励函数,质量表示模型表示为rk=qoek,由于强化学习关注的是基于一个策略所获得的长期累计回报,因此,引入折扣因子γ∈[0,1],得到累计折扣奖励如下:
[0113][0114]
k表示考虑k个连续动作,t表示第t时刻;
[0115]
根据随机策略的思想,agent选择一个码率去执行相关的操作,定义随机策略π
θ
作为可选动作上的一个概率分布;为了评估一个策略π
θ
的好坏,定义策略的状态价值函数,表示对当前策略的期望总回报,如下:
[0116][0117]
最终目标是找到一个最优的策略表示在k个时刻状态选择动作ak的概率,最终要找的策略是使得期望总回报最大的策略,目标函数如下所示:
[0118][0119]
使用基于actor-critic框架的强化学习算法ppo来训练神经网络,找到最优策略
[0120]
ppo算法采用off-policy的方式,分别采用行为策略和目标策略实现不同任务。基于行为策略的actor网络基于一定的概率选择动作,critic网络基于该actor的动作评判当前动作的得分,然后该actor网络根据critic网络的评分修改所选动作的概率,更新动作策略。而基于目标策略的actor网络则借助行为策略的采样结果提升算法性能,并最终称为最佳策略。为找到最佳策略,需要不断更新actor网络参数θ和critic网络参数φ;
[0121]
其中,actor网络和critic网络的1d-cnn层包含128个filters,每个filter的大小设置为4,且基于目标策略的actor网络仅用于保存数据,不进行其他计算操作;全连接fc层包含128个units。qoe模型中的参数均设置为1,超参数设置为0.2。
[0122]
基于policy gradients方法,ppo算法对于策略的折扣累计回报的梯度计算如下所示:
[0123][0124]
其中,π
θ
(ak|sk)表示当前状态为sk时选择动作ak的概率是多少,π
θ
(ak|sk)取值范围在0~1之间。
[0125]
表示基于状态价值函数定义的动作优势函数,具体计算如下所示:
[0126][0127]
在该模型中,将agent和环境交互若干次形成的三元组《state,action,reward》组合成轨迹集合dk={s1,a1,r1;s2,a2,r2;
…
;sk,ak,rk}。对于actor网络,基于目标策略的actor网络根据轨迹集合进行策略学习,并根据两个actor网络的kl(kullback-leibler)距离来更新其参数,需要最大化目标函数和网络参数θ更新如下所示:
[0128]
[0129][0130]
其中,π
′
θ
(a
t
|s
t
)表示通过采样的数据得到的选择动作ak的概率,r(θ)衡量了采样前后两个分布的一致性,g(r(θ),ε)表示将r(θ)限制在[1-ε,1 ε]区间之内,ε为超参数,设置为0.2。
[0131]
对于critic网络,基于时序差分的方法更新其参数φ,具体计算如下所示:
[0132][0133]
至此,在ppo算法的基础上实现了视频自适应传输的框架。
[0134]
在该评估中,为了验证所所提自适应传输方法的有效性,在quic下与目前具有代表性的码率自适应算法进行比较,将发明提出的基于深度学习的自适应码率算法称为ppo-bp-q,将其与mpc算法和pensieve算法进行比较,均采用标准化的qoe作为奖励reward指标,定义公式如下所示:
[0135][0136]
首先评估了在quic的单路传输情况下三种算法的性能表现,如图4中(a)所示,在两种不同的qoe评价模型中,基于强化学习的码率自适应方法比基于固定规则的码率自适应方法,其性能有较大提升,这也说明了quic下基于强化学习的码率自适应方法的有效性。在基于强化学习的两种方法中,ppo-bp-q相比于pensieve的表现略好,在qoe指标上平均提升了9%。这是由于ppo-bp-q基于更加精确的带宽预测结果,有效提升了码率决策的性能。
[0137]
由图4中(b),在多路传输情况下,ppo-bp-q和pensieve均在三路传输时取得最优性能,并且本发明提出方法效果最优。
[0138]
step6,客户端基于服务器端的码率自适应决策结果,选择合适码率版本的视频文件下载到缓冲区,对视频文件进行解码。并结合步骤1中基于nginx的平台,将quic协议的0-rtt特性与多路复用等特性应用到视频码率自适应过程中,联合优化视频传输与播放行为,减少播放缓冲时间,最大限度提高用户观看体验。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。