1.本发明涉及代码搜索技术领域,具体地说,涉及一种代码搜索方法。
背景技术:
2.在现代社会中,软件系统是不可或缺的,而且已经无处不在了。在开发一个新的软件项目时,开发人员将重用大量设计良好和经过充分测试的代码片段。开源社区,如github和stackoverflow,在公共场合提供了数百万个源代码。代码搜索任务的关键挑战在于学习代码片段和查询文本的对应关系,从而能够准确地反映代码-查询对的相似性。为了支持代码搜索任务,早期的代码搜索模型利用信息检索(ir)技术返回与搜索查询的意图相匹配的代码片段列表。然儿,这些方法通常将源代码视为文本文档,并利用信息检索模型来检索匹配给定查询的相关代码片段。这主要依赖于源代码和自然语言查询之间的文本相似性。它们缺乏对查询和源代码语义的深入理解。
3.随着今天大量开源代码的公开,代码搜索对软件开发变得越来越重要。早期的代码搜索模型主要依赖于源代码和自然语言查询之间的文本相似性。它们缺乏对查询和源代码的语义的深入理解。开发人员开始应用深度学习技术对搜索模型进行代码编码。然而这些模型要么是对代码跟查询语句分别进行训练来获得全局对应关系,忽略了他们之间的交互。要么只是粗略的交互,没有系统的探讨代码特征与查询特征是如何相互影响的。
技术实现要素:
4.本发明的内容是提供一种代码搜索方法,其能够克服现有技术的某种或某些缺陷。
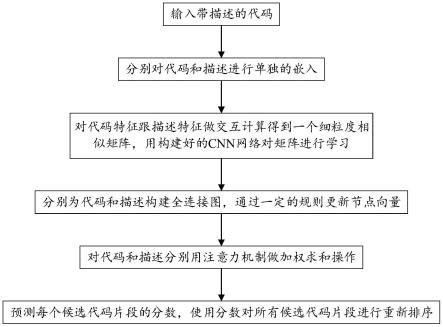
5.根据本发明的一种代码搜索方法,其包括以下步骤:
6.一、输入带描述的代码;
7.二、分别对代码和描述进行单独的嵌入;
8.三、对代码特征跟描述特征做交互计算得到一个细粒度相似矩阵,用构建好的cnn网络对矩阵进行学习;
9.四、分别为代码和描述构建全连接图,通过一定的规则更新节点向量;
10.五、对代码和描述分别用注意力机制做加权求和操作;
11.六、预测每个候选代码片段的分数,使用分数对所有候选代码片段进行重新排序。
12.作为优选,代码部分用code tokens、methodname、api sequence作为特征进行嵌入,其中code tokens表示为t=t_{1},...,t_{n_{t}},methon name表示为m=m_{1},...,m_{n_{m}},api sequence表示为a=a_{1},...,a_{n_{a}};
13.通过一个多层感知器mlp嵌入,以获得初始的特征信息:
[0014][0015][0016]
[0017]
其中ti∈rd,mi∈rd,ai∈rd分别表示令牌ti,mi,ai的嵌入式表示,w
t
,wm,wa为mlp中可训练的参数矩阵;
[0018]
在将三个代码特征嵌入到三个矩阵中之后,最终将它们合并成一个矩阵v∈rk×d作为代码的特征矩阵:
[0019][0020]
其中表示上下拼接操作。
[0021]
作为优选,描述特征用mlp对其进行嵌入:
[0022][0023]
其中ei∈rd表示描述词t=ei的嵌入式表示,we为mlp中可训练的参数矩阵。
[0024]
作为优选,步骤三中,首先计算代码特征v和描述特征e之间的相似度,相似度s
ij
衡量每个代码特征对应于每个描述特征:
[0025][0026]sij
表示第i个代码特征和第j个描述特征之间的细粒度交互关系,即相似度,k表示代码特征数,n表示描述特征数;
[0027]
然后,使用细粒度匹配矩阵作为代码-描述关系cnn网络的输入,使用多层cnn来捕获代码和描述之间的局部相关性和长期依赖关系;
[0028]
接着,对每个描述构造注意代码级特征,对每个代码特征构造注意描述级特征,以测量代码-描述相似度;
[0029]
对于第i个代码特征,在s
′
上使用逐列注意操作来计算每个描述特征到第i个代码特征的权重;然后,通过描述特征表示的加权求和提取相应的参与描述级向量:
[0030][0031]
其中,λ为softmax函数的逆温度;同样,通过对s
′
进行行注意力操作得到第j个描述特征对应的参与的代码特征级向量:
[0032][0033]
作为优选,cnn网络中,引入四种不同的卷积核来扩展区域和单词的感知域;第一个卷积层用2个大小为1
×
1的内核过滤n
×
k输入;第二个卷积层具有2个大小为1
×
3的内核;第三卷积层具有2个大小为3
×
1的内核;第四个卷积层有2个大小为3
×
3的内核;relu非线性应用于每个卷积层的输出;每层的操作情况如下:
[0034]st
=relu(conv(s
t-1
))
[0035]
用一个1
×
1的卷积核对第三个卷积层的输出进行滤波,得到最终的矩阵
[0036]
作为优选,步骤四中,为每个代码特征构造一个无向全连接图g1=(v1,e1);使用矩阵a来表示每个节点的相邻矩阵,并添加自循环;边权值表示为矩阵wa,表示节点之间的相互依赖关系:
[0037]
[0038]
利用所构造的图节点和边,通过更新节点和边来得到新的代码特征表示:
[0039][0040]
同样的,为每个描述特征构造一个无向全连接图g2=(v2,e2);使用矩阵b来表示每个节点的相邻矩阵,并添加自循环;边权值表示为矩阵wa,表示节点之间的相互依赖关系:
[0041][0042]
利用所构造的图节点和边,通过更新节点和边来得到新的描述特征表示:
[0043][0044]
作为优选,步骤五中,每个代码特征节点的权重计算如下:
[0045][0046]
其中wa是代码注意参数矩阵,ca是代码计算的上下文向量:
[0047][0048]
利用注意力权值,计算最终代码表示的加权平均值:
[0049][0050]
同样的,应用注意机制来学习每个描述节点的权重,计算方式如下:
[0051][0052]
其中,cb为查询的上下文向量,计算方法为:
[0053][0054]
利用注意力权值,我们计算节点嵌入向量的加权平均值来表示整个描述:
[0055][0056]
本发明从代码特性和描述特性中提取代码和查询信息。然后将提取的代码特征与描述特征进行细粒度相似度计算,可以探索每个代码特征和每个描述特征之间的交互匹配。接着分别为代码特征以及描述特征构造图结构,这可以获取各自特征之间的前后依赖
关系,从而实现更加复杂的联合交互匹配工作。
附图说明
[0057]
图1为实施例1中一种代码搜索方法的流程图;
[0058]
图2为实施例1中相似度匹配示意图。
具体实施方式
[0059]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0060]
实施例1
[0061]
如图1所示,本实施例提供了一种代码搜索方法(fsgcs的深度模型),其包括以下步骤:
[0062]
一、输入带描述的代码;
[0063]
二、分别对代码和描述进行单独的嵌入;
[0064]
三、对代码特征跟描述特征做交互计算得到一个细粒度相似矩阵,用构建好的cnn网络对矩阵进行学习;
[0065]
四、分别为代码和描述构建全连接图,通过一定的规则更新节点向量;
[0066]
五、对代码和描述分别用注意力机制做加权求和操作;
[0067]
六、预测每个候选代码片段的分数,使用分数对所有候选代码片段进行重新排序。
[0068]
代码部分用code tokens、methodname、api sequence作为特征进行嵌入,考虑一个输入代码片段c=[t,m,a],其中code tokens表示为t=t_{1},...,t_{n_{t}},methon name表示为m=m_{1},...,m_{n_{m}},api sequence表示为a=a_{1},...,a_{n_{a}};将所有token信息标记分解为子标记,例如arraylist可以细化为array和list,这可以让不同token获取更加显式的区分;对于描述部分则表示为e=e_{1},...,e_{n_{e}}。
[0069]
通过一个多层感知器mlp嵌入,以获得初始的特征信息:
[0070][0071][0072][0073]
其中ti∈rd,mi∈rd,ai∈rd分别表示令牌ti,mi,ai的嵌入式表示,w
t
,wm,wa为mlp中可训练的参数矩阵;
[0074]
在将三个代码特征嵌入到三个矩阵中之后,最终将它们合并成一个矩阵v∈rk×d作为代码的特征矩阵:
[0075][0076]
其中表示上下拼接操作。
[0077]
对于描述特征,为了跟代码特征做后续的细粒度短语匹配操作,描述特征同样用mlp对其进行嵌入:
[0078][0079]
其中ei∈rd表示描述词t=ei的嵌入式表示,we为mlp中可训练的参数矩阵。
[0080]
基于代码特征v和描述特征e,需要捕获代码-查询细粒度对应关系。首先计算代码特征v和描述特征e之间的相似度,如图2所示,相似度s
ij
衡量每个代码特征对应于每个描述特征:
[0081][0082]sij
表示第i个代码特征和第j个描述特征之间的细粒度交互关系,即相似度,k表示代码特征数,n表示描述特征数;
[0083]
然后,使用细粒度匹配矩阵作为代码-描述关系cnn网络的输入,使用多层cnn来捕获代码和描述之间的局部相关性和长期依赖关系。
[0084]
这里,需要捕捉潜在的代码-描述对应关系。受卷积神经网络的启发,可以有效地提取像素之间的关系,并分层构建表达性表示。因此,目标是使用多层cnn来捕获代码和单词之间的局部相关性和长期依赖关系。与现有的将cnn应用于图像处理或文本处理不同,输入的每个元素表示一个像素或单词之间的相关性,每个元素意味着每个代码特征-单词特征的交互信息。
[0085]
cnn网络中,引入四种不同的卷积核来扩展区域和单词的感知域;第一个卷积层用2个大小为1
×
1的内核过滤n
×
k输入;第二个卷积层具有2个大小为1
×
3的内核;第三卷积层具有2个大小为3
×
1的内核;第四个卷积层有2个大小为3
×
3的内核;relu非线性应用于每个卷积层的输出;每层的操作情况如下:
[0086]st
=relu(conv(s
t-1
))
[0087]
用一个1
×
1的卷积核对第三个卷积层的输出进行滤波,得到最终的矩阵请注意,这里删除了降采样操作为了避免信息丢失,并保持匹配矩阵的维度。通过分层卷积操作,可以捕获从代码-描述之间潜在的对齐关系。
[0088]
借助学习到的代码-描述特征之间细粒度的对齐关系,可以更准确的度量代码-描述相似性。
[0089]
接着,对每个描述构造注意代码级特征,对每个代码特征构造注意描述级特征,以测量代码-描述相似度;
[0090]
对于第i个代码特征,在s
′
上使用逐列注意操作来计算每个描述特征到第i个代码特征的权重;然后,通过描述特征表示的加权求和提取相应的参与描述级向量:
[0091][0092]
其中,λ为softmax函数的逆温度;同样,通过对s
′
进行行注意力操作得到第j个描述特征对应的参与的代码特征级向量:
[0093][0094]
为了实现更全面的相似性匹配,构建了一个推理图,在局部和全局各级可能的对齐之间传播相似性消息。更具体地说,将所有经过细粒度匹配模块得到的代码以及描述向量作为图节点分别构建全连接图。
[0095]
为每个代码特征构造一个无向全连接图g1=(v1,e1);使用矩阵a来表示每个节点
的相邻矩阵,并添加自循环;边权值表示为矩阵wa,表示节点之间的相互依赖关系:
[0096][0097]
利用所构造的图节点和边,通过更新节点和边来得到新的代码特征表示:
[0098][0099]
同样的,为每个描述特征构造一个无向全连接图g2=(v2,e2);使用矩阵b来表示每个节点的相邻矩阵,并添加自循环;边权值表示为矩阵wa,表示节点之间的相互依赖关系:
[0100][0101]
利用所构造的图节点和边,通过更新节点和边来得到新的描述特征表示:
[0102][0103]
步骤五中,每个代码特征节点的权重计算如下:
[0104][0105]
其中wa是代码注意参数矩阵,ca是代码计算的上下文向量:
[0106][0107]
利用注意力权值,计算最终代码表示的加权平均值:
[0108][0109]
同样的,应用注意机制来学习每个描述节点的权重,计算方式如下:
[0110][0111]
其中,cb为查询的上下文向量,计算方法为:
[0112][0113]
利用注意力权值,我们计算节点嵌入向量的加权平均值来表示整个描述:
[0114]
[0115]
模型训练
[0116]
如果代码片段和描述具有相似的语义,那么它们的嵌入式向量应该彼此接近。换句话说,给定任意代码片段c和任意描述d,如果d是对c的精确描述,我们希望它能够预测具有高相似性的距离,否则则有点相似性。我们将每个训练实例构建为一个$《c,d_{ },d_{-}》$用于监督训练。对于每个代码片段c,都有一个积极的描述$d_{ }$(正确的描述)和一个由其他d
集合中随机选取的负的描述d-(错误的描述)。在训练过程中,搜索模型都预测了《c,d
》和《c,d-》的余弦相似性,并将排序损失最小化,定义如下:
[0117][0118]
其中θ表示模型参数,p表示训练语料库,∈为恒定边距,将其设置为1.0。c,d
和d-分别为c,d
和d-的嵌入式向量。函数l(θ)会增加代码片段与其正确描述之间的相似性,而代码片段与其错误描述之间的相似性则会减少。
[0119]
代码搜索的模型预测
[0120]
经过模型训练后,可以通过嵌入一个大规模的代码库来部署模型在线进行代码搜索,其中每个代码都由一个向量c表示。对于开发人员的搜索查询,模型将描述嵌入为一个向量q。然后,描述q和代码c之间的语义相似性可以通过它们的余弦相似性来衡量;最后,该模型推荐了与代码搜索查询高度相关的top-k个代码:
[0121][0122]
数据集
[0123]
hu等人的数据集是从github从2015年至2016年创建的java存储库中收集过来的。为了过滤掉低质量的项目,hu等人只考虑了那些有超过十颗星的项目。然后,他们从这些java项目中提取了java方法及其相应的javadoc。javadoc的第一句话被认为是查询。然而,这个数据集中的一些代码片段有无用的注释,例如,只有参数描述的注释。因此,过滤掉查询语句未超过两个单词的代码片段。经过过滤后,得到了一个包含69k注释函数对的训练集,一个包含8k注释函数对的测试集和一个包含8k注释函数对的验证集,详细的统计数据见表1。
[0124]
表1统计数据
[0125]
training settesting setvalidation set6968787128714
[0126]
对比
[0127]
本实施例比较了最先进的模型deepcs、unif、mpcat、carlcs-cnn和fsgcs模型之间的代码搜索有效性。结果表明,fsgcs优于四种基于dl的模型(即deepcs、unif、mpcat、carlcs-cnn)。
[0128]
deepcs,这是由gu等人提出的第一个将深度学习用于代码搜索的模型。deepcs使用lstm和max-pooling来编码代码特性和查询。实验结果表明,deepcs的性能优于基于信息检索的模型。
[0129]
carlcs-cnn,最近由shuai等人提出的carlcs-cnn是一种使用共同注意机制的最
先进的模型。它利用cnn和lstm学习代码和查询的嵌入表示并且引入了一种协同注意机制来学习代码标记和查询标记之间的内部语义关联。
[0130]
unif,cambronero等人提出了一种先进的监督代码搜索模型unif。unif对代码token以及查询token都用fasttext嵌入初始化。再分别使用注意力机制和平均法将代码嵌入和查询嵌入组合起来。
[0131]
mpcat,一种使用分层遍历方法编码代码抽象语法树并合并文本匹配模型bimpm的模型。
[0132]
为了评估模型fgsdcs,使用了两个常见的评估指标successrate@k和mrr。具体来说,对于测试数据集中的每一对代码片段和描述,将描述作为查询,并将相应的代码片段与测试集中的其他代码片段一起作为代码检索任务的候选对象。用这两种常用于信息检索的评估指标来衡量我们的模型和基线模型的性能。
[0133]
successrate@k(sr@k)相关代码方法可以在排名前k的列表中找到的查询的比例。具体计算方法如下:
[0134][0135]
其中q是我们测试集中的8712个查询,s是一个指示函数。如果可以在排名前k的列表中找到第i个查询(qi),则返回1,否则返回0。我们分别评估successrate@1,successrate@5和successrate@10。
[0136]
mrr测试查询结果的倒数秩的平均值,计算方法如下:
[0137][0138]
其中,是第i个查询的结果列表中正确代码片段的排名位置。与successrate@k不同,mrr使用倒数秩作为测量的权重。换句话说,当qi的排名超过10时,那么等于0。
[0139]
所有的实验都是在服务器上进行的,有16核cpu的cpu和gpu加速。该框架构建在python3.6和cuda9.0以上。所有的词嵌入大小都是128。为了训练我们的fgsdcs模型,使用了adam[9]优化器,学习率为0.0003,批处理大小为32。cnn的详细设置参考上面模型描述部分。
[0140]
对于hu等人的数据集,如表2所示,fsgcs实现了mrr为0.5048,sr@1/5/10为0.4214/0.6204/0.6812。fsgcs在mrr方面分别优于基线模型deepcs、unif、mpcat和calcs-cnn 21.69%、10.96%、9.24%和7.01%;在sr@1/5/10方面分别超过16.12%/22.90%/16.25%,11.12%/11.07%/10.26%,4.36%/7.72%/8.98%和3.59%/4.67%/6.00%。
[0141]
表2对比表
[0142]
modelsr@1sr@1sr@1mrrdeepcs0.26020.39140.51870.2879unif0.31020.50970.57860.3952
macat0.36880.54320.59140.4124calcs-cnn0.37650.57370.62120.4347fsgcs0.42140.62040.68120.5048
[0143]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
