1.本技术涉及终端控制技术领域,特别涉及一种图形处理单元的控制方法、装置、终端设备及存储介质。
背景技术:
2.随着信息技术和互联网技术的发展,用户在日常生活中对终端设备使用的现象已经非常普遍,终端设备在使用过程中如何提高续航能力是人们较为关注的问题。
3.目前,大多数的终端设备在进行功耗降低时,会采用动态电压频率调节(dynamicvoltage and frequencyscaling,dvfs)机制对图形处理单元(graphic process unit,gpu)的工作频率和工作电压进行调整。其中,该dvfs机制是根据当前gpu的利用率情况,调整gpu的工作频率,使得gpu的利用率维持在某一个目标值,以满足当前图形处理任务的计算能力需求。
4.对于上述已有的dvfs机制来说,基于gpu的功率对频率进行调整之后,虽然可以降低gpu的功率,但是gpu的耗电量依然会出现增加的现象,存在终端设备电量浪费的问题。
技术实现要素:
5.为了解决现有技术的问题,提高终端设备的续航能力,减少终端设备对电量的浪费,本技术实施例提供了一种图形处理单元的控制方法、装置、终端设备及存储介质。所述技术方案如下:
6.一个方面,本技术提供了一种图形处理单元的控制方法,应用于终端设备,所述方法包括:
7.获取所述图形处理单元gpu的工作周期以及工作电压;
8.根据所述工作周期以及所述工作电压,获取所述gpu在所述工作周期内的耗电量;
9.调整所述gpu的工作频率以及所述gpu的工作电压,以使得所述gpu在所述工作周期内的耗电量达到最小值。
10.一个方面,本技术提供了一种终端设备控制装置,应用于终端设备,所述装置包括:
11.第一获取模块,用于获取所述图形处理单元gpu的工作周期以及工作电压;
12.第二获取模块,用于根据所述工作周期以及所述工作电压,获取所述gpu在所述工作周期内的耗电量;
13.参数调整模块,用于调整所述gpu的工作频率以及所述gpu的工作电压,以使得所述gpu在所述工作周期内的耗电量达到最小值。
14.另一个方面,本技术提供了一种终端设备,所述终端设备包含处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如一个方面所述的图形处理单元的控制方法。
15.另一个方面,本技术提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如一个方面所述的图形处理单元的控制方法。
16.另一方面,本技术实施例提供了一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行如上述一个方面所述的图形处理单元的控制方法。
17.另一方面,本技术实施例提供了一种应用发布平台,所述应用发布平台用于发布计算机程序产品,其中,当所述计算机程序产品在计算机上运行时,使得所述计算机执行如上述一个方面所述的图形处理单元的控制方法。
18.本技术实施例提供的技术方案带来的有益效果至少包括:
19.本技术通过获取图形处理单元gpu的工作周期以及工作电压;根据工作周期以及工作电压,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。本技术基于耗电量最小值的方式对gpu的工作频率以及gpu的工作电压进行调整,可以避免降低gpu的工作频率过程中gpu的耗电量依旧增加的情况出现,提高了终端设备的续航能力,减少了终端设备对电量的浪费。
附图说明
20.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
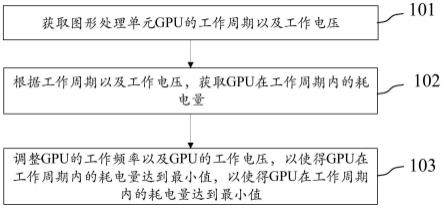
21.图1是本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图;
22.图2是本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图;
23.图3是本技术一示例性实施例涉及的一种图形处理单元的结构框图;
24.图4是本技术一示例性实施例涉及的一种soc系统架构的结构示意图;
25.图5是本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图;
26.图6是本技术一示例性实施例提供的图形处理单元的控制装置的结构框图;
27.图7是本技术一示例性实施例提供的一种终端设备的结构示意图。
具体实施方式
28.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
29.随着科学技术的快速发展,各种各样的终端设备已经应用在人们的日常生活中,人们在工作中、生活中、学习中都需要使用终端设备,比如,人们利用终端设备对周围环境
进行拍照,利用终端设备对工作中的数据进行记录等。随着人们使用终端设备的场景越来越多,万物互联的推广与使用,终端设备中提高续航能力越来越重要。
30.目前,终端设备主要的系统有安卓(android)系统,ios系统,linux系统等,对于各种内核系统的终端设备,各自的中央处理单元(central processing unit,cpu),图像处理单元gpu等处理器在终端设备运行过程中主要作为任务处理单元进行处理,相应的,这些任务处理单元在工作时对终端设备的电量有消耗。
31.在实际应用中,为了提高终端设备的续航能力,为延长手机的电池使用时间,终端中的系统级芯片(system on chip,soc)设计采用多种方案降低功耗。其中,大多数终端设备中的图形处理器都会采用dvfs机制调整工作频率和工作电压,从而降低gpu工作时的功耗水平。其中,dvfs机制是根据当前gpu的利用率情况,调整gpu的工作频率,使得gpu的利用率维持在某一个目标值,以满足当前图形处理任务的计算能力需求。
32.即,上述dvfs技术的频率电压调整方案是尽可能降低图形处理器的工作频率,以满足负载任务的处理需求,这种调整方案的本质是调整工作频率以使得gpu以最低功率运行能够满足负载任务的处理需求即可。但是,实际生活中,终端设备的使用场景是受限于电池容量的,不断降低gpu的工作功率相当于不断降低gpu的工作主频,在gpu的工作电压降到最低时,如果继续降低工作功率,反而会导致gpu的耗电量的增加,存在终端设备电量浪费的问题。
33.为了解决上述相关技术中存在的问题,提高终端设备的续航能力,减少终端设备对电量的浪费,本技术提供了一种图形处理单元的控制方法,可以基于gpu的耗电量对工作频率和工作电压进行调整,达到调整工作频率和工作电压之后,可以实现gpu对电池的耗电量是最低的情况。
34.请参考图1,其示出了本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图,该图形处理单元的控制方法可以用于终端设备中。如图1所示,该图形处理单元的控制方法可以包括如下步骤:
35.步骤101,获取图形处理单元gpu的工作周期以及工作电压。
36.可选的,本技术中提到的终端设备可以是手机、平板电脑,笔记本电脑,智能眼镜,智能手表,mp3播放器(moving picture experts group audio layer iii,动态影像专家压缩标准音频层面3),mp4(moving picture experts group audio layer iv,动态影像专家压缩标准音频层面4)播放器,台式电脑,膝上型便携计算机,智能家居设备等具有gpu的电子设备。
37.在终端设备的gpu运行过程中,各种数据处理任务需要gpu来处理,比如,数据处理任务可以是对图像的渲染、展示等。在本方案中,终端设备可以通过cpu获取gpu的工作周期以及工作电压,也可以通过gpu自身获取自身的工作周期以及工作电压。本方案对获取gpu的工作周期以及工作电压的方式并不限定。
38.步骤102,根据工作周期以及工作电压,获取gpu在工作周期内的耗电量。
39.可选的,终端设备可以将获取到的gpu的工作周期以及工作电压,带入至耗电量的计算公式中,从而计算得到gpu在工作周期内的耗电量。比如,终端设备的gpu的耗电量可以写为下面函数:
40.e=g(f,v,c,w);
41.在上述公式中,f表示gpu的工作频率,v表示gpu的工作电压,c表示gpu中运算单元的数量,w表示gpu的工作负载,e表示gpu的耗电量。其中,对于终端设备的gpu来说,其当前的工作周期可以是t,gpu在一个工作周期t内的耗电量可以用e表示。c可以是默认的固定数量,也可以是进行调整后的当前运行的运算单元的数量。
42.步骤103,调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。
43.可选的,在本方案中,通过调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。在调整过程中,终端设备可以对工作频率进行调整,并根据调整后的工作频率以及电压计算公式,获取目标电压,目标电压是调整后的工作频率对应的工作电压。其中,电压计算公式是:v=k2*f。其中,k2是常数,k2可以由开发人员或者运维人员根据终端设备的系统级芯片的工艺参数设定。可选的,本步骤相当于通过对f和v进行调整,对上述e求取最小值的过程。
44.综上所述,本技术通过获取图形处理单元gpu的工作周期以及工作电压;根据工作周期以及工作电压,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。本技术基于耗电量最小值的方式对gpu的工作频率以及gpu的工作电压进行调整,可以避免降低gpu的工作频率过程中gpu的耗电量依旧增加的情况出现,提高了终端设备的续航能力,减少了终端设备对电量的浪费。
45.在一种可能实现的方式中,本技术中还可以对gpu的运算单元的数量进行调整,提高终端设备的gpu的能量效率。
46.请参考图2,其示出了本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图,该图形处理单元的控制方法可以用于终端设备中。如图2所示,该图形处理单元的控制方法可以包括如下步骤:
47.步骤201,获取图形处理单元gpu的工作周期以及工作电压。
48.可选的,t表示工作周期,终端设备获取到的gpu的工作周期t可以用以下公式表示:t=k1*(w/f),其中,w表示gpu的工作负载,f表示gpu的当前工作频率。即,终端设备可以根据gpu的当前工作频率以及gpu的工作负载,计算出gpu的当前工作周期。其中,k1与上述k2类似,也是由开发人员或者运维人员根据终端设备的系统级芯片的工艺参数设定。另外,gpu的工作电压可以用v表示,gpu的工作电压与gpu的工作频率之间的关系(v=k2*f)可以参考上述图1中步骤103中的描述,此处不再赘述。
49.步骤202,获取gpu的顶模的能量利用率以及子核能量利用率,子核能量利用率是gpu中各个正在运行的运算单元的能量利用率的平均利用率。
50.其中,gpu的顶模的能量利用率是gpu的顶模对电池能量的利用率。gpu中各个正在运行的运算单元的能量利用率是gpu中各个正在运行的运算单元对电池能量的利用率。
51.可选的,请参考图3,其示出了本技术一示例性实施例涉及的一种图形处理单元的结构框图。如图3所示,在图形处理单元300中包含了顶模301,各个运算单元302。在上述图3中,图形处理单元300可以分为一个顶模(topmodule)301以及各个运算单元(core)302,其中顶模301可以负责终端设备中的内存访问、几何处理等工作,各个运算单元302可以负责终端设备中的fragment处理等工作。顶模301的时钟为f
top
,各个运算单元302使用同一个时
钟f
core
,终端设备对顶模301的时钟与各个运算单元302的时钟相互独立控制。
52.其中,gpu中可以包含一个顶模和多个运算单元,在本方案中,终端设备还可以获取顶模的能量利用率以及子核能量利用率。比如,终端设备通过gpu的性能计数器(performance counter)对顶模301的能量利用率进行计算,得到αtop,通过gpu的性能计数器对各个正在运行的运算单元302的利用率进行计算,并根据各个正在运行的运算单元302的利用率获取平均值,从而得到gpu中各个正在运行的运算单元的能量利用率的平均利用率αcore。
53.可选的,本方案中终端设备的gpu的运算单元的数量可以是默认的固定数量,也可以是灵活调整的。即,如果gpu中运行的运算单元的数量是固定数量的,本方案可以跳过步骤202直接进入步骤204,如果gpu中运行的运算单元的数量是灵活调整的,可以进入步骤203。也就是说,如果gpu中运行的运算单元的数量是固定数量的,在上述e=g(f,v,c,w)中,c相当于一个常数。
54.步骤203,根据顶模的能量利用率以及子核能量利用率,调整gpu中各个正在运行的运算单元的数量。
55.可选的,如果gpu中的运算单元的个数可以单独控制打开或关闭其工作电源,由于不同运算单元的处理能力以及完成的子工作负载不同,相互之间涉及到很多配合,本方案可以针对不同情况获取一个最优的运算单元工作数目,从而使得能量效率最高。
56.可选的,终端设备根据顶模的能量利用率以及子核能量利用率,调整gpu中各个正在运行的运算单元的数量的方式可以如下:根据顶模的能量利用率以及子核能量利用率,计算第一比例值;当第一比例值大于第一阈值时,在gpu中各个正在运行的运算单元的数量基础上增加第一预设数量个运算单元;当第一比例值小于第二阈值时,在gpu中各个正在运行的运算单元的数量基础上减少第一预设数量个运算单元。其代码可以如下:
57.defineβ=k*α
core
/α
top
58.ifβ》βu59.iecrease core number,n
core
=n
core
δ
60.else ifβ《βd61.decrease top module frequency,n
core
=n
core-δ
62.endif
63.其中,β表示第一比例值,第一阈值是βu,第二阈值是βd,第一预设数量是δ,n
core
是正在运行的运算单元的数量。k是常数,可以由开发人员或者运维人员根据终端设备的系统级芯片的工艺参数设定。即,终端设备将获取到的顶模的能量利用率以及子核能量利用率带入上述β的计算公式中,得到第一比例值β,判断β与第一阈值,第二阈值之间的大小关系,当β》第一阈值时,在gpu中各个正在运行的运算单元的数量基础上增加δ个运算单元。当β《第二阈值时,在gpu中各个正在运行的运算单元的数量基础上减少δ个运算单元。
64.比如,βu可以是3,βd可以是1/3,δ取值为2,若n
core
是5,计算得到的β是4时,则在正在运行的运算单元的数量基础上增加2个,那么调整后的正在运行的运算单元的数量是7。若n
core
是5,计算得到的β是0.2时,则在正在运行的运算单元的数量基础上减少2个,那么调整后的正在运行的运算单元的数量是3。可选的,当β处于第二阈值至第一阈值之间时,终端设备可以保持正在运行的运算单元的数量不变。即,当第一比例值大于第一阈值时,说明
gpu的顶模的能量利用率较高,可以增加运算单元的数目以增强gpu的处理能力,提高gpu的能量效率。当第一比例值小于第二阈值时,说明gpu的顶模的能量利用率较低,可以减少运算单元的数目以增强gpu的处理能力,提高gpu的能量效率。
65.在一种可能实现的方式中,在减少运算单元的数量时,终端设备可以按照如下方式:当第一比例值小于第二阈值时,终端设备可以确定gpu中各个正在运行的运算单元的任务优先级;按照任务优先级从低到高的顺序,将gpu中各个正在运行的运算单元依次减少第一预设数量个运算单元。即,当第一比例值小于第二阈值时,终端设备可以获取各个正在运行的运算单元的任务优先级。比如,各个正在运行的运算单元分别是运算单元一,运算单元二,运算单元三,运算单元四,运算单元五,这五个运算单元各自处理的任务是任务一,任务二,任务三,任务四,任务五,这五个运算单元各自处理的任务按照任务优先级从低到高的顺序排列依次是任务一,任务四,任务五,任务三,任务二,当终端设备计算的第一比例值小于第二阈值时,获取到各个正在运行的运算单元的任务优先级,仍然以上述δ取值为2为例,减少运算单元的数量时,将gpu中运算单元一和运算单元四关闭。
66.步骤204,根据工作周期,工作电压以及gpu中各个正在运行的运算单元的数量,获取gpu在工作周期内的耗电量。
67.可选的,仍然以上述e表示gpu在工作周期内的耗电量,终端设备将工作周期,工作电压以及gpu中各个正在运行的运算单元的数量带入上述公式即可得到,此处不再赘述。
68.步骤205,调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。
69.可选的,以上述终端设备的gpu的耗电量可以写为下面函数:e=g(f,v,c,w)为例,由于f表示gpu的工作频率,v表示gpu的工作电压,c表示gpu中运算单元的数量,w表示gpu的工作负载,e表示gpu的耗电量。由于在dvfs机制中f和v之间存在线性映射关系:v=k2*f,因此可以将e=g(f,v,c,w)简化为e=g(f,c,w),本方案的目标是求取
70.例如,终端设备通过上述方式获取到的gpu的工作周期如下:
[0071][0072]
那么,gpu的工作电压为v=k2*f,因此,gpu的动态功耗可以按照如下公式表示:
[0073]
p
dyn
=k3v2f;
[0074]
那么,gpu的动态功耗对应的耗电量为e
dyn
=p
dyn
t=k4f2w;
[0075]
可选的,本方案中还考虑了gpu的静态功耗,gpu的静态功耗可以按照如下公式表示:
[0076]
p
lkg
=k5v2;
[0077]
那么,gpu的静态功耗对应的耗电量为e
lkg
=p
lkg
t=k6fw;
[0078]
gpu的总耗电量为e=e
dyn
e
lkg
;
[0079]
本方案中对dvfs机制进行了调整,选择满足工作负载的最低工作频率时对应的能量消耗最小,即,求取上面k3,k4,k5均为常数,也都可以由开发人员或者运维人员根据终端设备的系统级芯片的工艺参数设定。
[0080]
在上述图3中,gpu中包含顶模以及运算单元,在本步骤中,终端设备可以按照如下
方式进行调整:将gpu的顶模的工作频率调整至第一频率以及将gpu的顶模的工作电压调整至第一电压,以使得gpu的顶模在工作周期内的耗电量达到最小值;以及,将gpu的运算单元的工作频率调整至第二频率以及将gpu的运算单元的工作电压调整至第二电压,以使得gpu的运算单元在工作周期内的耗电量达到最小值。
[0081]
可选的,本方案中,将gpu的顶模的工作频率调整至第一频率以及将gpu的顶模的工作电压调整至第一电压,以使得gpu的顶模在工作周期内的耗电量达到最小值的过程可以如下:
[0082]
终端设备可以将上述获取到的顶模的能量利用率αtop与第五阈值进行比较,当αtop》第五阈值时,增加顶模的工作频率,且根据v=k2*f获取调整后的工作频率对应的顶模的工作电压,从而对顶模的工作电压进行调整。将上述获取到的顶模的能量利用率αtop与第六阈值进行比较,当αtop《第六阈值时,减少顶模的工作频率,且根据v=k2*f获取调整后的工作频率对应的顶模的工作电压,从而对顶模的工作电压进行调整,当顶模的工作频率达到最低工作电压时能够工作的最高频率时,控制顶模的工作频率保持不变。其对应的代码可以如下:
[0083]
ifα_top》α_(top_u)
[0084]
increase top module frequency,f_top,##增加顶模的工作频率
[0085]
adjusttop module workingvoltage;##调整顶模的工作电压
[0086]
else ifα_top《α_(top_d)
[0087]
decrease top module frequency,f_top##减少顶模的工作频率
[0088]
iff_top reaches f_(top_min),then maintain f_topat the minimum frequency.##当顶模的工作频率达到最低工作电压时能够工作的最高频率时,控制顶模的工作频率保持不变
[0089]
adjusttop module workingvoltage;##调整顶模的工作电压
[0090]
endif
[0091]
其中,α_(top_u)是第五阈值,α_(top_d)是第六阈值,可选的,第五阈值和第六阈值可以由开发人员预先设置在终端设备中,比如,第五阈值可以是80%,第六阈值可以是30%。
[0092]
可选的,本方案中,将gpu的运算单元的工作频率调整至第二频率以及将gpu的运算单元的工作电压调整至第二电压,以使得gpu的运算单元在工作周期内的耗电量达到最小值的过程可以如下:
[0093]
可选的,终端设备还可以将上述获取到的子核能量利用率αcore与第五阈值进行比较,当αcore》第七阈值时,增加运算单元的工作频率,且根据v=k2*f获取调整后的工作频率对应的运算单元的工作电压,从而对运算单元的工作电压进行调整。将上述获取到的子核能量利用率αcore与第八阈值进行比较,当αcore《第八阈值时,减少运算单元的工作频率,且根据v=k2*f获取调整后的工作频率对应的运算单元的工作电压,从而对运算单元的工作电压进行调整,当运算单元的工作频率达到最低工作电压时能够工作的最高频率时,控制运算单元的工作频率保持不变。其对应的代码可以如下:
[0094]
ifα_core》α_(core_u)
[0095]
increase core module frequency,f_core##增加运算单元的工作频率
[0096]
adjust core workingvoltage;##调整运算单元的工作电压
[0097]
else ifα_core《α_(core_d)
[0098]
decrease core module frequency,f_core##减少运算单元的工作频率
[0099]
iff_core reaches f_(core_min),then maintain f_coreat the minimum frequency.当运算单元的工作频率达到最低工作电压时能够工作的最高频率时,控制运算单元的工作频率保持不变
[0100]
adjustcoreworkingvoltage;##调整运算单元的工作电压
[0101]
endif
[0102]
其中,α_(core_u)是第七阈值,α_(core_d)是第八阈值,可选的,第七阈值和第八阈值可以由开发人员预先设置在终端设备中,比如,第七阈值可以是80%,第八阈值可以是30%。
[0103]
在上述内容中,由于实际gpu有最低工作电压的限制,因此,当gpu中的顶模的工作电压达到最低工作电压,gpu中的运算单元的工作电压达到最低工作电压时,上述v也可以看做是一个常数,因此通过推导可以得到gpu的动态功耗对应的耗电量为e
dyn
=p
dyn
t=k4w;
[0104]
gpu的静态功耗对应的耗电量为
[0105]
因此,本方案在最低工作电压时保持工作频率不变,防止一直降低工作频率带来的增加静态功耗的问题,即,在调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值的过程中,当gpu的工作电压达到最低工作电压时,控制gpu的工作频率保持不变。
[0106]
在一种可能实现的方式中,终端设备还可以在将gpu的顶模的工作频率调整至第一频率以及将gpu的顶模的工作电压调整至第一电压,以使得gpu的顶模在工作周期内的耗电量达到最小值之后,获取调整后的gpu的顶模的工作频率以及调整前的gpu的顶模的工作频率;当调整后的gpu的顶模的工作频率与调整前的gpu的顶模的工作频率之间的比值大于第三阈值时,增加双倍速率ddr存储系统的工作频率;当调整后的gpu的顶模的工作频率与调整前的gpu的顶模的工作频率之间的比值小于第四阈值时,减少ddr存储系统的工作频率;当调整后的gpu的顶模的工作频率与调整前的gpu的顶模的工作频率之间的比值处于第四阈值与第三阈值范围之内时,保持ddr存储系统的工作频率不变;其中,第三阈值大于第四阈值。
[0107]
可选的,本技术中gpu可以处于soc系统架构中,gpu处理的任务还可以涉及soc系统中的其他子系统共同完成,当gpu处理的负载发生变化时,其他子系统的频率也需要进行调整以提高soc的能量效率。与gpu相关的子系统包括双倍速率(double data rate,ddr)存储系统,cpu系统以及display显示系统。
[0108]
请参考图4,其示出了本技术一示例性实施例涉及的一种soc系统架构的结构示意图。如图4所示,在soc架构400中包含了cpu 401,gpu 402,display显示系统403以及ddr存储系统404。终端设备还可以在将gpu的顶模的工作频率调整至第一频率以及将gpu的顶模的工作电压调整至第一电压,以使得gpu的顶模在工作周期内的耗电量达到最小值之后,可以继续对ddr存储系统的工作频率进行调整,以提高soc的能量效率。
[0109]
可选的,对ddr存储系统的工作频率进行调整的代码可以如下:
[0110]
if f_(top_curr)/f_(top_prev)》f_(top_ratio_u)
[0111]
increaseddrfrequency,f_(ddr_freq);##增加ddr存储系统的工作频率
[0112]
adjust ddr workingvoltage;##调整ddr存储系统的工作电压
[0113]
else if f_(top_curr)/f_(top_prev)《f_(top_ratio_d)
[0114]
decreaseddrfrequency,f_(ddr_freq);##减少ddr存储系统的工作频率
[0115]
adjust ddr workingvoltage;##调整ddr存储系统的工作电压
[0116]
else
[0117]
maintain ddr frequency.##保持ddr存储系统的工作频率
[0118]
endif
[0119]
其中,f_(top_curr)是调整后的gpu的顶模的工作频率,f_(top_prev)是调整前的gpu的顶模的工作频率,f_(top_ratio_u)是第三阈值,f_(top_ratio_d)是第四阈值,可选的,第三阈值和第四阈值可以由开发人员预先设置在终端设备中,比如,第三阈值可以是2,第四阈值可以是1/2。可选的,每次对ddr存储系统增加或者减少的工作频率可以是当前ddr存储系统的工作频率的一半。
[0120]
需要说明的是,本方案也可以对soc架构中的显示系统以及cpu的工作电压和工作频率进行调整,从而提高soc的能量效率,其方式可以参考对ddr存储系统的调整方式,此处不再赘述。
[0121]
综上所述,本技术通过获取图形处理单元gpu的工作周期以及工作电压;根据工作周期以及工作电压,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。本技术基于耗电量最小值的方式对gpu的工作频率以及gpu的工作电压进行调整,可以避免降低gpu的工作频率过程中gpu的耗电量依旧增加的情况出现,提高了终端设备的续航能力,减少了终端设备对电量的浪费。
[0122]
另外,本技术通过调整gpu中运算单元的数量,可以灵活改变gpu对负载的执行力度,提高终端设备的gpu的能量效率。本技术还可以对soc系统架构上的其他子系统的工作频率和工作电压进行调整,提高了soc的能量效率。
[0123]
以终端设备是手机为例,手机在运行游戏应用程序过程中,通过本方案中基改进的dvfs机制对gpu的工作电压和工作频率进行调整,从而延长手机的持续时间,提高续航能力。
[0124]
请参考图5,其示出了本技术一示例性实施例提供的一种图形处理单元的控制方法的方法流程图,该图形处理单元的控制方法可以用于终端设备中。如图5所示,该图形处理单元的控制方法可以包括如下步骤:
[0125]
步骤501,检测α_top是否大于α_(top_u)。
[0126]
若大于,执行步骤502,否则执行步骤503。
[0127]
步骤502,增加顶模的工作频率,调整顶模的工作电压。
[0128]
步骤503,检测α_top是否小于α_(top_d)。
[0129]
若小于,进入步骤504,否则执行步骤505。
[0130]
步骤504,减少顶模的工作频率,调整顶模的工作电压。
[0131]
步骤505,检测α_core是否大于α_(core_u)。
[0132]
若大于,执行步骤506,否则执行步骤507。
[0133]
步骤506,增加运算单元的工作频率,调整运算单元的工作电压。
[0134]
步骤507,检测α_core是否小于α_(core_d)。
[0135]
若小于,进入步骤508,否则执行步骤509。
[0136]
步骤508,减少运算单元的工作频率,调整运算单元的工作电压。
[0137]
步骤509,计算β。
[0138]
步骤510,检测β是否大于βu。
[0139]
若是,执行步骤511,否则执行步骤512。
[0140]
步骤511,增加正在运行的运算单元的数量。
[0141]
步骤512,检测β是否小于βd。
[0142]
若是,执行步骤513,否则保持正在运行的运算单元的数量不变。
[0143]
步骤513,减少正在运行的运算单元的数量。
[0144]
可选的,上述各个参数与图2实施例中的各个参数含义相同,此处不再赘述。需要说明的是,步骤501至步骤504的执行,与步骤505至步骤508的执行可以同时进行,也可以调整先后顺序,此处不再赘述。
[0145]
步骤514,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值。
[0146]
综上所述,本技术通过获取图形处理单元gpu的工作周期以及工作电压;根据工作周期以及工作电压,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。本技术基于耗电量最小值的方式对gpu的工作频率以及gpu的工作电压进行调整,可以避免降低gpu的工作频率过程中gpu的耗电量依旧增加的情况出现,提高了终端设备的续航能力,减少了终端设备对电量的浪费。
[0147]
下述为本技术装置实施例,可以用于执行本技术方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术方法实施例。
[0148]
请参考图6,其示出了本技术一示例性实施例提供的图形处理单元的控制装置的结构框图。该图形处理单元的控制装置600可以用于终端设备中,以执行图1、图2或图5所示实施例提供的方法中由终端设备执行的全部或者部分步骤。该图形处理单元的控制装置600包括:
[0149]
第一获取模块601,用于获取所述图形处理单元gpu的工作周期以及工作电压;
[0150]
第二获取模块602,用于根据所述工作周期以及所述工作电压,获取所述gpu在所述工作周期内的耗电量;
[0151]
参数调整模块603,用于调整所述gpu的工作频率以及所述gpu的工作电压,以使得所述gpu在所述工作周期内的耗电量达到最小值。
[0152]
综上所述,本技术通过获取图形处理单元gpu的工作周期以及工作电压;根据工作周期以及工作电压,获取gpu在工作周期内的耗电量;调整gpu的工作频率以及gpu的工作电压,以使得gpu在工作周期内的耗电量达到最小值,以使得gpu在工作周期内的耗电量达到最小值。本技术基于耗电量最小值的方式对gpu的工作频率以及gpu的工作电压进行调整,可以避免降低gpu的工作频率过程中gpu的耗电量依旧增加的情况出现,提高了终端设备的
续航能力,减少了终端设备对电量的浪费。
[0153]
可选的,所述装置还包括:第三获取模块和第一调整模块
[0154]
所述第三获取模块,用于在所述根据所述工作周期以及所述工作电压,获取所述gpu在所述工作周期内的耗电量之前,获取所述gpu的顶模的能量利用率以及子核能量利用率,所述子核能量利用率是所述gpu中各个正在运行的运算单元的能量利用率的平均利用率;
[0155]
所述第一调整模块,用于根据所述顶模的能量利用率以及子核能量利用率,调整所述gpu中各个正在运行的运算单元的数量;
[0156]
所述第二获取模块,用于根据所述工作周期,所述工作电压以及所述gpu中各个正在运行的运算单元的数量,获取所述gpu在所述工作周期内的耗电量。
[0157]
可选的,所述第一调整模块,包括:第一计算单元,第一增加单元和第一减少单元;
[0158]
所述第一计算单元,用于根据所述顶模的能量利用率以及子核能量利用率,计算第一比例值;
[0159]
所述第一增加单元,用于当所述第一比例值大于第一阈值时,在所述gpu中各个正在运行的运算单元的数量基础上增加第一预设数量个运算单元;
[0160]
所述第一减少单元,用于当所述第一比例值小于第二阈值时,在所述gpu中各个正在运行的运算单元的数量基础上减少第一预设数量个运算单元。
[0161]
可选的,所述第一减少单元,包括:第一确定子单元和第一减少子单元;
[0162]
所述第一确定子单元,用于当所述第一比例值小于第二阈值时,确定所述gpu中各个正在运行的运算单元的任务优先级;
[0163]
所述第一减少子单元,用于按照所述任务优先级从低到高的顺序,将所述gpu中各个正在运行的运算单元依次减少第一预设数量个运算单元。
[0164]
可选的,所述参数调整模块,包括:第二调整模块以及第三调整模块,
[0165]
所述第二调整模块,用于将所述gpu的顶模的工作频率调整至第一频率以及将所述gpu的顶模的工作电压调整至第一电压,以使得所述gpu的顶模在所述工作周期内的耗电量达到最小值;
[0166]
所述第三调整模块,用于将所述gpu的运算单元的工作频率调整至第二频率以及将所述gpu的运算单元的工作电压调整至第二电压,以使得所述gpu的运算单元在所述工作周期内的耗电量达到最小值。
[0167]
可选的,所述装置还包括:
[0168]
第四获取模块,用于在所述将所述gpu的顶模的工作频率调整至第一频率以及将所述gpu的顶模的工作电压调整至第一电压,以使得所述gpu的顶模在所述工作周期内的耗电量达到最小值之后,获取调整后的所述gpu的顶模的工作频率以及调整前的所述gpu的顶模的工作频率;
[0169]
第二增加模块,用于当调整后的所述gpu的顶模的工作频率与调整前的所述gpu的顶模的工作频率之间的比值大于第三阈值时,增加双倍速率ddr存储系统的工作频率;
[0170]
第二减少模块,用于当调整后的所述gpu的顶模的工作频率与调整前的所述gpu的顶模的工作频率之间的比值小于第四阈值时,减少所述ddr存储系统的工作频率;
[0171]
第一保持模块,用于当调整后的所述gpu的顶模的工作频率与调整前的所述gpu的
顶模的工作频率之间的比值处于所述第四阈值与所述第三阈值范围之内时,保持所述ddr存储系统的工作频率不变;其中,所述第三阈值大于所述第四阈值。
[0172]
可选的,在所述将所述gpu的工作频率调整至目标频率以及将所述gpu的工作电压调整至目标电压的过程中,当所述gpu的工作电压达到最低工作电压时,控制所述gpu的工作频率保持不变。。
[0173]
图7是本技术一示例性实施例提供的一种终端设备的结构示意图。如图7所示,终端设备700包括中央处理单元(central processing unit,cpu)701、包括随机存取存储器(random access memory,ram)702和只读存储器(read only memory,rom)703的系统存储器704,以及连接系统存储器704和中央处理单元701的系统总线705。所述终端设备700还包括帮助计算机内的各个器件之间传输信息的基本传输/输出系统(input/output system,i/o系统)706,和用于存储操作系统712、应用程序713和其他程序模块714的大容量存储设备707。
[0174]
所述基本传输/输出系统706包括有用于显示信息的显示器706和用于用户传输信息的诸如鼠标、键盘之类的传输设备709。其中所述显示器706和传输设备709都通过连接到系统总线705的传输输出控制器710连接到中央处理单元701。所述基本传输/输出系统706还可以包括传输输出控制器710以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的传输。类似地,传输输出控制器710还提供输出到显示屏、打印机或其他类型的输出设备。
[0175]
所述大容量存储设备707通过连接到系统总线705的大容量存储控制器(未示出)连接到中央处理单元701。所述大容量存储设备707及其相关联的计算机可读介质为终端设备700提供非易失性存储。也就是说,所述大容量存储设备707可以包括诸如硬盘或者cd-rom(compact disc read-only memory,只读光盘)驱动器之类的计算机可读介质(未示出)。
[0176]
所述计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括ram、rom、eprom(erasable programmable read only memory,可擦除可编程只读存储器)、eeprom(electrically erasable programmable read-only memory,带电可擦可编程只读存储器)、闪存或其他固态存储其技术,cd-rom、dvd(digital video disc,高密度数字视频光盘)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知所述计算机存储介质不局限于上述几种。上述的系统存储器704和大容量存储设备707可以统称为存储器。
[0177]
终端设备700可以通过连接在所述系统总线705上的网络接口单元711连接到互联网或者其它网络设备。所述存储器还包括一个或者一个以上的程序,所述一个或者一个以上程序存储于存储器中。
[0178]
本技术实施例还提供了一种计算机可读介质,该计算机可读介质存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现如上各个实施例所述的图形处理单元的控制方法中,由终端设备执行的全部或部分步骤。
[0179]
本技术实施例还提供了一种计算机程序产品,该计算机程序产品存储有至少一条
指令,所述至少一条指令由所述处理器加载并执行以实现如上各个实施例所述的图形处理单元的控制方法,由终端设备或者服务器执行的全部或部分步骤。
[0180]
需要说明的是:上述实施例提供的装置在执行终端设备的控制时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
[0181]
上述本技术实施例序号仅仅为了描述,不代表实施例的优劣。
[0182]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0183]
以上所述仅为本技术的可选实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。