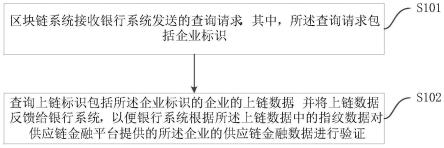
1.本公开总体上涉及约车系统,并且更具体地涉及约车车辆站的系统和方法。
背景技术:
2.自主车辆(av)提供出租车服务并模仿顾客的使用方式是有利的。虽然约车服务提供了一些希望,但是它们依赖于通过使用在用户的移动装置(诸如智能电话)上执行的应用程序来进行的数字约车动作。也就是说,用户可以通过从他们的移动装置上的约车服务应用程序请求服务来约一辆av。这种依赖性意味着手机电池耗尽的客户无法访问约车服务,尤其是自主约车车辆。此外,没有电话的客户根本无法访问约车服务。
技术实现要素:
3.本公开总体上涉及可以向所有乘客提供公平服务的增强的约车系统和方法。在一些情况下,这些增强的服务可以包括专用的自主约车车辆站,其允许客户在街道上请求自主约车车辆而无需使用智能电话。专用站可以放置在地理区域中,其中站的gps坐标被登记并映射到av的导航系统中。在其他情况下,图案可以显示在智能装置或标牌、卡片、标志或其他物理结构上。
4.约车站可以包括可以训练av以识别的图案化信号。当前没有被引导给客户的车辆可以进入等待模式路线,在这种路线中,它们朝向最可能的接载区域移动。本公开的av可以以类似于人类驾驶的正常出租车的方式被“呼叫”。av可以利用视觉或(红外)ir相机来检测来自请求乘坐的客户的图案化标志和/或人类信令。在另一个示例中,光探测和测距(lidar)装置也可以被av用来检测标志附近的人和/或指示约车手势(诸如挥手)的身体移动。然后,av可以识别出它正在被呼叫,靠边停车,并向潜在的乘坐者要求输入。请求输入是为了确保av不会出错,并防止潜在客户尝试在未付款的情况下进入av。
附图说明
5.关于附图阐述具体实施方式。使用相同的附图标记可以指示类似或相同的项。各种实施例可以利用除了附图中示出的那些之外的元件和/或部件,并且一些元件和/或部件可能不存在于各种实施例中。附图中的元件和/或部件不一定按比例绘制。在整个本公开中,根据上下文,单数和复数术语可以可互换使用。
6.图1示出了可以实践本公开的系统和方法的示例性架构。
7.图2是可以实践本公开的各方面的场景的示例性示意图。
8.图3是可以实践本公开的各方面的场景的另一个示例性示意图。
9.图4是本公开的示例性方法的流程图。
10.图5是本公开的另一个示例性方法的流程图。
具体实施方式
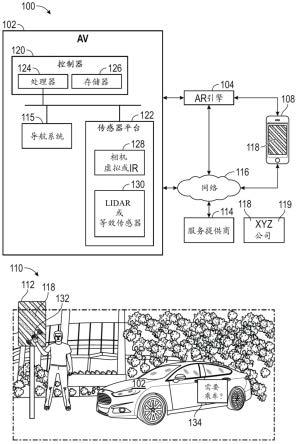
11.现在转到附图,图1描绘了可以实现本公开的技术和结构的说明性架构100。架构100可以包括av 102(可互换地称为av或车辆)、分布式增强现实(ar)引擎(下文称为ar引擎104)、用户设备(ue108)、具有图案化标志112的约车站110、服务提供商114和网络116。架构100中的这些部件中的一些或全部可以使用网络116彼此通信。网络116可以包括使得架构100中的部件能够彼此通信的网络组合。网络116可以包括多种不同类型的网络中的任一种或其组合,诸如有线网络、互联网、无线网络以及其他私有和/或公共网络。在一些情况下,网络116可包括蜂窝网络、wi-fi或wi-fi直连。
12.约车站110可包括邻近街道、停车场、建筑物的任何指定区域,或可接载用户(例如,乘客)以进行约车服务的任何其他位置。约车站110的位置可以由约车服务和/或市政当局预先确定。可以确定约车站110的位置并将其存储在由服务提供商114维护的数据库中。约车站110的位置(以及av 102的位置中的其他约车站)还可以由av 102存储。在一些情况下,服务提供商114可以将约车站110的位置传输给av 102以供在av 102的导航系统115中使用。除了使用诸如全球定位系统(gps)坐标的位置信息之外,还可以包括附加的约车站信息,诸如约车站相对于十字路口或其他地标的基本方向,以及当约车站邻近街道时此类约车站位于街道的哪一侧。约车站110的详细取向信息通常可以被称为约车站取向或超定位。
13.图案化标志112可以包括其上设置有特定图案118的基板。图案118的特定美学细节可以根据设计要求而变化,但是在所提供的示例中,图案包括成角度(例如,45度倾斜)取向的交替的黄色和黑色条纹。应当理解,虽然已经示出了示例性图案,但是图案化标志112可以包括av系统可以被训练来识别的任何图案。此外,虽然已经描述了图案化标志,但是可以使用除标志之外的其他图案化对象。例如,用于指示约车位置的图案可以打印在建筑物或另一结构的侧面上。如下面将更详细讨论的,用户可以使用在其ue 108上显示的图案化图像来招停av 102,而不是使用图案化标志。例如,当ue 108是智能电话时,可以在智能电话的屏幕上显示图案118。此外,在ue 108上显示图案可以允许使用可以改变的动态或独特的图案。数字图案还可以包括编码的结构化图案,所述编码的结构化图案可以嵌入其他类型的信息,诸如关于用户的信息(例如,用户简档、偏好、支付信息等)。虽然已经公开了智能电话,但是还可以使用其他装置,诸如智能手表、平板电脑等。
14.在一个模拟示例中,图案118可以打印在用户携带的卡片上。用户可以出示卡片以招停av 102。以这种方式,约车站是便携式的,并且可以由用户携带。用户不需要找到图案化标志或约车站,而是可以使用他们的ue或卡片在任何位置请求av 102服务。本文提供的示例不旨在是限制性的,而是出于说明的目的而提供。同样,还可以利用显示可被av 102识别为约车请求的图案的机制或方法的其他配置。
15.在一些情况下,选择图案118的颜色组成和/或美观性,使得当颠倒时,不显示图案118,以便防止被ar引擎104混淆。在一个示例中,图案118的底片119可以包括消息,诸如xyz公司的广告。可以用光来照亮图案化标志112以使其在低光条件下更可见。
16.av 102通常包括控制器120和传感器平台122。控制器120可以包括处理器124和存储器126,所述存储器用于存储可执行指令,处理器124可以执行存储在存储器126中的指令以执行本文公开的任何增强的约车特征。当提及由控制器120执行的操作时,应当理解,这包括由处理器124执行存储在存储器126中的指令。av 102还可以包括允许控制器120通过
网络116传输和/或接收数据的通信接口。
17.传感器平台122可以包括一个或多个相机128以及lidar 130。一个或多个相机128可以包括视觉和/或红外相机。一个或多个相机128获得图像,所述图像可由ar引擎104处理,以确定图像中是否存在约车站和/或乘客何时出现在约车站处。
18.lidar传感器130可以用于检测对象之间(诸如在av与图案化标志之间,以及在av与在图案化标志附近等待的用户之间)的距离和/或对象(诸如图像中的用户)的移动。一个或多个相机128可以包括视觉和/或红外相机。一个或多个相机128获得图像,所述图像可由ar引擎104处理,以确定图像中是否存在约车站和/或乘客何时出现在约车站处。
19.控制器120可以被配置为在等待来自用户的约车请求时使av102在约车站110周围以保持或盘旋模式穿行。可以使用导航系统115指示av 102以预定模式在约车站110或一组约车站周围行驶。替代地,可以指示av 102停车,直到接收到约车请求。在一些情况下,av 102所遵循的盘旋或驾驶模式可以基于由服务提供商114确定的历史或预期使用模式。也就是说,服务提供商114可以向控制器120传输信号,以基于历史约车模式操作av 102。在其他示例中,av 102可以在约车站的已知位置周围以某种模式驾驶。
20.如上所述,控制器120可以维护约车站在给定区域中所处位置的列表。随着av 102接近约车站,控制器120可以使一个或多个相机128获得图像。图像可以由控制器120通过网络116传输到ar引擎104以进行处理。ar引擎104可以向控制器120返回信号以指示用户是否存在并试图从约车站110呼叫av 102。
21.ar引擎104可以被配置为提供特征,诸如场景识别(标识图像中的对象或地标)、用户姿势(例如,挥手)、步态识别和/或群体生物特征。总的来说,这些数据可以被ar引擎104用来确定用户的情境。下文更详细地提供了关于用户情境的附加细节。
22.例如,图像可由ar引擎104处理,以确定图像中存在(或不存在)约车站。这可以包括ar引擎104检测图案化标志112的图案118。当检测到标志时,ar引擎104还可以确定用户何时呼叫av 102。在一个示例中,用户可以在图案化标志112的图案118前挥手132,从而部分地遮蔽图案118。ar引擎104可以确定形状像人手的对象正在遮挡图案118的一部分。在一些情况下,ar引擎104可以使用多个图像来检测手132的挥动或其他类似的运动。在另一个示例中,用户可以保持任何物体抵靠图案118以遮蔽图案118的一部分。如果图案118的任何部分被遮挡,则ar引擎104可以确定用户存在于图案化标志112中。如上所述,av 102可以包括lidar或可以检测对象存在和移动的其他类型的非基于视觉的传感器。在一些情况下,ar引擎104可以使用一个或多个存在和/或移动检测传感器来确定用户在约车站110处的存在。在一些情况下,ar引擎104可以确定用户、av 102和图案化标志112之间的相对距离。例如,ar引擎104可以确定av 102与图案化标志112之间的距离。然后,ar引擎104可以确定用户与图案化标志112之间的距离。当这两个距离的计算结果在指定范围内(例如,零到五英尺,但是可以基于期望的灵敏度进行调整)时,ar引擎104可以确定用户在约车站110处并且正在等待服务。
23.除了确定用户存在和意图之外,ar引擎104还可以被配置为评估图像以进行场景识别,其中ar引擎104检测图像中的背景信息,诸如建筑物、街道、标志等。ar引擎104还可以被配置为检测用户的手势、姿势和/或步态(例如,身体移动)。例如,当av 102越来越靠近约车站110时,ar引擎104可以检测到用户正在向前走,这可以指示用户意图呼叫av 102。如上
所述,ar引擎104还可以检测多个用户以及用户的生物特征。
24.而且,ar引擎104可以被配置为确定用户的情境。通常,情境指示针对av 102的特定用户要求。例如,ar引擎104可以从图像中检测到存在多个用户。可以提示av 102询问这一个或多个用户是否需要合乘服务。多个用户也可以指示家庭。在另一个示例中,情境可以包括确定图像中的轮椅或婴儿车。控制器120可以向用户请求信息,所述信息确认是否需要为一群人或运输大件物品(诸如婴儿车、轮椅、包裹和其他类似物体)提供特殊便利。控制器120可以被配置为确定情境何时指示av 102能够或不能够容纳用户。
25.当在约车站110处检测到用户并且ar引擎104已经确定用户正在或可能试图呼叫av 102时,ar引擎104向av 102传输信号,所述信号由控制器120接收。所述信号向控制器120指示av 102是否应停靠在约车站110处。在一些情况下,ar引擎104的功能可以结合到av 102中。也就是说,控制器120可以被编程为提供ar引擎104的功能。
26.控制器120可以指示av 102停靠在约车站110处。在一些情况下,控制器120可以使av 102的外部显示器134(例如,安装在av外部的显示器)显示一个或多个图形用户界面,所述图形用户界面要求用户确认他们是否需要约车服务。控制器120可以使外部显示器134向用户询问预期目的地、支付形式或将指示控制器120关于用户意图(例如,用户是否意图呼叫av)的任何其他提示。虽然已经公开了使用外部显示器,但是可以使用用于与用户进行通信以确定用户意图的其他方法,诸如通过扬声器广播的可听消息。av 102可以启用语音识别以允许用户使用自然语言语音说出他们的意图。
27.在用户进入av 102之前接收输入和确认可以确保av 102不会错误地为对使用av 102不感兴趣的用户停靠,或者导致av 102在用户未请求av 102停靠的时停靠在约车站110处的任何其他一般性错误。在允许用户进入av 102之前获得用户确认或付款还可以防止用户试图在未经授权的情况下接管av并获得庇护,这将对av功能和整体服务造成破坏。
28.图2提供了其中当多于一个av在地理位置中操作时,可以使用约车站相对于街道的相对位置来选择适当的av的示例。可以肯定的是,每个av都是如上文关于图1的av 102所公开的那样被配置的。在本示例中,三个av 202、204和206正在约车站208周围执行盘旋模式。av 202正在进行右转,并且将会在将被呼叫的街道的正确一侧。同样,可以向每一辆av提供关于约车站208的位置的超定位信息。由于这种超定位信息,av 204将确定它在街道的错误一侧。av204可以忽略任何约车用户并且将继续搜索乘客或另一个约车站。同样,任何av都可以被配置为检测在ue上显示的图案化对象或可以指示用户正在请求服务的其他物理对象。
29.而且,正在接近十字路口的av 206将识别出用户的呼叫尝试。av 202和av 206可以协调接载,或者默认为先到达先接载场景。例如,如果十字路口处的信号灯的定时导致av 206首先到达约车站208,则av 206将接载用户。在进一步的过程中,如果av 206确定用户的情境指示多个乘坐者或大件物品,则av 206可以与av 202协调以便一前一后地运输用户和/或其货物。这些av可以通过服务提供商(作为示例参见图1的服务提供商114)或通过经由网络116的车辆对车辆(v2v)连接来协调它们的动作。
30.图3提供了这两个av之间的协作行为的示例。可以肯定的是,每个av都是如上文关于图1的av 102所公开的那样被配置的。在本示例中,av 302和304正在约车站306周围的区域中操作。对于本示例,将假设av 302已经满员和/或正在为更喜欢独自乘坐的乘客(例如,
不是合乘服务)提供行程。av 302检测到用户正试图呼叫av302进行约车行程。av 302可以与av 304进行协调以接载用户。例如,av 302可以通过v2v或其他类似的无线连接308向av 304传输信号,所述信号指示用户正在请求搭乘。所述信号可以指示约车站306的位置或标识符,和/或当av 302驶过约车站306时获得的任何图像或情境信息。av 304可以预处理由av 302获得的约车站306的图像,使得av 304可以确定其是否可为用户提供服务。例如,av 304可以评估这些图像,并确定用户的情境是否与av 304的能力或容量相对应。如果用户具有大件物品,则av 304可以确定其是否有容量同时容纳用户和其大件物品。在另一个示例中,当情境指示多个用户正在请求乘坐时,av 304可以确定其是否具有用于多个用户的座位容量。
31.图4是本公开的示例性方法的流程图。所述方法可以包括步骤402:从由车辆相机获得的图像中确定与约车站相关联的图案化对象的图案。在一些情况下,图案化对象可以是标志。如上所述,av可以被配置为以使av驶过约车站的预定模式行驶。例如,控制器可以被配置为使车辆在约车站周围以一定模式穿行,直到在约车站处检测到用户。每个约车站可以设置有包括独特图案的图案化标志。每个约车站可以通过其位置以及约车站取向(例如,超定位)来标识。可以映射这些位置以便在av的导航系统中使用。因此,预定模式可以基于约车站的映射位置。
32.接下来,所述方法包括步骤404:通过标识所述图案化对象的至少一部分何时被遮挡或使用所述车辆的传感器何时检测到用户,使用所述图像确定所述用户在所述约车站处的存在。在一个示例中,用户可以用他们的手或另一个物体来遮蔽图案化对象的一部分。例如,确定用户的存在可以包括确定所述用户的手在图案化标志前挥动。在另一个示例中,当用户站在图案化对象旁边并且他们的身体定位在av与图案化对象之间时,图案化对象的一部分可能被遮挡。在另一种情况下,可以基于用户与av和/或图案化对象的接近度来确定用户的存在。例如,可以确定av与图案化对象相距200码,并且用户与av相距196码。这一距离指示用户紧邻图案化对象并且可能正在等待约车服务。接下来,所述方法可以包括步骤406:当确定所述用户的存在时,使所述车辆停靠在所述约车站处。
33.所述方法可以包括步骤408:在所述用户进入所述车辆之前,请求所述用户确认所述用户呼叫了所述车辆。如果用户并不意图呼叫av,则av可以返回到其预定驾驶模式以等待另一次约车机会。当用户已经意图请求服务时,则所述方法可以包括步骤410:基于所述用户确认所述用户意图呼叫所述av而允许进入所述车辆。在一些情况下,这可以包括用户进行支付或以其他方式被授权进入av。
34.图5是示例性方法的另一流程图。所述方法可以包括步骤502:基于在由车辆相机获得的图像中检测到图案来确定用户正在请求约车行程。在一些情况下,车辆可以基于与约车站相关联的映射位置的接近度来获得图像。
35.在其他情况下,车辆可以连续地使用相机来获得图像并评估图像以检测指示用户正在请求约车行程的模式。一些示例包括检测图案化标志、显示在智能装置的屏幕上的图案、用户持有的标牌或卡片等。
36.所述方法还可以包括步骤504:使用所述图像确定所述约车行程的情境。同样,所述情境可以指示针对车辆的特定用户要求,诸如车辆容量(例如,乘坐者计数)、存放或行李容量和/或残疾人可及性要求。可以使用位于服务提供商处和/或作为网络可访问服务的ar
引擎来完成对用户存在和情境的确定。ar引擎可以在车辆层面上进行定位。
37.所述方法可以包括步骤506:当所述车辆满足针对所述车辆的所述特定用户要求时,允许所述用户进入所述车辆。在一些情况下,在车辆已经接收到支付信息之后,可以允许用户进入车辆。接下来,所述方法可以包括步骤508:当所述车辆无法满足针对所述车辆的所述特定用户要求时,向另一车辆传输消息以导航到所述用户的位置。
38.本文公开的系统、设备、装置和方法的实现方式可以包括或利用专用或通用计算机,所述专用或通用计算机包括计算机硬件,例如诸如一个或多个处理器和系统存储器,如本文所讨论。计算机可执行指令包括例如在处理器处执行时致使通用计算机、专用计算机或专用处理装置执行某个功能或某组功能的指令和数据。本文公开的装置、系统和方法的实现方式可以通过计算机网络进行通信。“网络”被定义为使得能够在计算机系统和/或模块和/或其他电子装置之间传输电子数据的一个或多个数据链路。
39.尽管已经用特定于结构特征和/或方法动作的语言描述了本主题,但是应理解,在所附权利要求中限定的主题可以不必限于上面描述的所述特征或动作。而是,所描述的特征和动作被公开作为实现权利要求的示例性形式。
40.虽然上文已经描述了本公开的各种实施例,但是应理解,这些实施例仅通过示例而非限制的方式呈现。相关领域的技术人员将明白,在不脱离本公开的精神和范围的情况下可进行形式和细节上的各种改变。因此,本公开的广度和范围不应受上述示例性实施例中的任一者的限制,而是应仅根据所附权利要求及其等效物来限定。已经出于说明和描述目的而呈现了前述描述。前述描述并不意图是详尽的或将本公开限制于所公开的精确形式。鉴于以上教导,许多修改和变化形式是可能的。此外,应注意,前述可选实现方式中的任一者或全部可按任何所期望的组合使用,以形成本公开的附加混合实现方式。例如,相对于特定装置或部件描述的任何功能可以通过另一个装置或部件来执行。除非另有特别说明或在使用时在上下文内以其他方式理解,否则诸如尤其是“能够”、“可能”、“可以”或“可”的条件语言通常意图表达某些实施例可以包括某些特征、元件和/或步骤,而其他实施例可以不包括某些特征、元件和/或步骤。因此,此类条件语言一般并不意图暗示一个或多个实施例无论如何都需要各特征、元件和/或步骤。
41.根据本发明的实施例,所述图案被包括在约车站的图案化标志上。
42.根据本发明的实施例,所述图案被显示在智能装置的屏幕上。
43.根据本发明的实施例,所述图案被包括在所述用户持有的物理对象上。
44.根据本发明的一个实施例,所述图案的底片可以由所述相机确定,所述图案的所述底片包括通信。
45.根据本发明的一个实施例,上述发明的特征还在于增强现实引擎,所述增强现实引擎被配置为确定场景识别、用户手势和步态、群组数据以及生物特征数据中的任何一者或多者,所述情境部分地基于增强现实引擎的输出。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。