1.本发明属于过程挖掘、过程建模、图像分析技术领域,具体涉及一种基于代码动态特征的代码作弊行为检测方法。
背景技术:
2.2002年,lutz prechelt在journal of universal computer science上提出的jplag web服务基于greedystringtiling(一种基于token分析的算法)分析代码相似度,现已成功在实践中用于检测java程序提交中的抄袭,支持c、c 和scheme语言。在开发者程序集中的表现评估表明,jplag算法在配置参数方面健壮性强,能够可靠检测大部分的抄袭作弊行为,运行速度快,可用性强,是现下最普及的代码作弊行为检测机制。
3.token是在预处理过程中词法分析所生成的单元,在c 中,通过使用clang-fsyntax-only-xclang-dump-tokens可以在stderr中直接观察到。在当前的相似度检测发展中并不直接使用基础的token定义,而是采用了一套更加抽象的token,规避了比较过程中一些较细粒度连续token串的误判。
4.传统作弊行为检测有着显而易见的优势,算法实现简单,而且可以独立于待检测代码的语言,当待比较的代码适配同一套token系统,通过gst算法比较相似度。也是因为预处理操作的功效,且比较一致性时不考虑token的实际值和所处位置,因此可以抵抗插入无效代码、插入注释、修改变量名的简单修改方式。但是,由于仅考虑了代码的静态特征,所以无法检测循环方式的替换,数据存储格式的修改以及无用的调用和语句。而当下实践环境中,为了规避作弊检测,对提交代码做不透明谓词,循环展开,插入无效函数和调用的混淆手段操作,采用传统的代码作弊检测机制,便会失去效果。
技术实现要素:
5.针对现有技术中存在的问题,本发明的目的在于提供一种基于代码动态特征的代码作弊行为检测方法。
6.为达到上述目的,提出以下技术方案:
7.首先对待判定代码进行代码清洗,主要通过构造程序依赖图(pdg)分析冗余代码并去除,其次为代码添加代码探针,通过探针程序自动添加局部,该探针代码语句和规则由预定义获得,通过探针输出形成运行日志;再通过pm(process mining)完成代码依赖知识发现(knowledge discover),挖掘实际编译逻辑进行分析,构造出编译层面反映代码动态特征得到代码流程图(cfc);接着根据标准化代码流程图(scfc),对已有cfc进行标准化处理,以去除不同编程语言语法对流程图结构的影响;最后,采用最短路径图内核(spgk)图相似度算法,计算语法分析图间相似度,并以此为依据,获得代码相似度,从而完成对代码作弊行为的判断。
8.具体地包括如下步骤:
9.步骤1构造程序依赖图:找到程序和语句之间的依赖关联,进行代码清洗,去除冗
余代码,获得代码完成目标功能的最简程序依赖图;程序依赖图(pdg,program dependence graph)是程序的一种图形表示,它是带有标记的有向多重图,程序依赖图能够表示程序的控制依赖和数据依赖关系,常见的模糊处理技术会通过添加冗余代码,增加生成代码流程图(cfc)中的节点数和边数,从而影响基于流程图的代码相似性精度。
10.步骤2运行日志生成:构造探针代码,打印简洁的运行日志,保存探针日志结果作为过程挖掘的输入;构造探针代码的目的是生成代码运行日志,从而明确代码的运行流程,作为代码流程图的构造依据。因此,需要在代码中加入实现目标功能以外的探针代码,从而为日志生成提供代码支持。根据本发明的构思核心,该探针应该植入于源代码,即对源文件进行完整的词法、语法分析后,确认插桩的位置,相比于对目标代码的探针植入,源代码植入具有针对性和精确性。植入方法使用中国航天系统科学与工程研究院在2016年提出的基于源代码的程序自动插桩方法,在本发明中的应用,定义如下几条探针语句和探针代码添加规则:
11.(1)declare(type1,type2,
…
,typen):在变量声明操作后植入,其中,typek(k∈[1,n])为该代码对应程序语言中变量类型集合的元素。其具体值为探针代码前的一个代码基本块的声明类型。若该探针前代码基本块只有一个声明语句,则括号中的参数为单值,即声明类型;若该探针前有多个连续声明语句则合并,按照变量名称首字母顺序放入参数中。并且为该类型每次探针使用,从1开始编号。
[0012]
(2)assign(type1,type2,
…
,typen):在赋值操作后植入,其中,typek(k∈[1,n])为该代码对应程序语言中变量类型集合的元素。其具体值为探针代码前的一个代码基本块的被赋值变量类型。若在该基本块中有多个连续的,彼此无数据依赖的赋值语句,则将探针代码合并为一个,所有变量类型按照源代码顺序放入参数中,位于最后一个赋值语句之后。并且为该类型每次探针使用,从1开始编号。需要注意的是,若声明和赋值在同一句中实现,则插入该探针。
[0013]
(3)output:在打印操作后植入,并且为该类型每次探针使用,从1开始编号。
[0014]
(4)return:在返回操作后植入,并且为该类型每次探针使用,从1开始编号。
[0015]
步骤3代码流程图构造:通过过程挖掘(pm,processmining)算法构造出清洗后的代码流程图(cfc),得到代码的实际运行过程。为避免alpha算法对于短循环处理的限制本发明采取2003年a.j.m.m.weijters所提出的启发式算法(heuristicalgorithm),基于直观或者经验构造,在可接受的开销(时间和空间)内给出待解决组合优化问题的一个可行解,使用现存工具插件生成流程图。
[0016]
步骤4代码流程图标准化:将代码流程图标准化为标准化代码流程图;由于不同的编程语言有不同的语法特征,而流程图的生成又与这些语法密切相关,因此在待测代码有不同语言编写时,直接采用流程图相似度来表示代码相似度是不客观的,因此先将流程图标准化为统一的结构规范再比较相似度,可以消除不同的编程语言对结果的影响。
[0017]
步骤4的具体操作过程包括如下步骤:
[0018]
4.1)分析代码流程图的组成,用标准化代码流程图节点定义标记出全部的操作语句代码块的类型;
[0019]
4.2)分析代码流程图的结构和数据流动关系,基于标准化代码流程图结构类型,分析图使用的结构,从而确定出逻辑直接相关的代码块;
[0020]
4.3)分析代码块之间的具体关系,并采用标准化代码流程图的边缘将其关联。标准化代码流程图(scfc)的相关定义:
[0021]
4.1.1)标准化代码流程图(scfc)是一个流程图模型,scfc
p
=(v,e,tv,te,μ,δ)是一段代码p的标准化代码流程图其中,
[0022]
(1)v是节点的集合,是边的集合;
[0023]
(2)tv={assign,declare,control,loop,jump,call site,return,output,combine}是节点类型的集合;
[0024]
(3)te={see,cde}是一组边缘类型;
[0025]
(4)μ:v
→
tv是分配节点类型tv∈tv到v∈v的节点;
[0026]
(5)δ:e
→
te是指定边类型t的函数te∈te到边缘e∈e。
[0027]
4.1.2)标准化代码流程图(scfc)节点包括八种类型:
[0028]
(1)declare:变量声明语句;
[0029]
(2)assign:变量赋值语句;
[0030]
(3)loop:循环语句;
[0031]
(4)jump:控制进程的跳跃语句;
[0032]
(5)callsite:函数调用语句;
[0033]
(6)return:函数值返回语句;
[0034]
(7)control:分支语句;
[0035]
(8)output:输出语句。
[0036]
4.1.3)标准化代码流程图(scfc)边缘包括两种类型:
[0037]
(1)顺序执行边缘(see)对于scfc节点v1和v2,如果对应于v2的语句紧跟在对应v1的语句之后执行,则从v1指向v2;
[0038]
(2)控件依赖关系边缘(cde)对于属于循环或控制节点v1类型的scfc节点,如果v1中的条件值控制基本块是否执行,而v2是该块的第一个节点,则存在从v1到节点v2。控件依赖关系边具有两个属性:cde-y表示边满足控制条件,cde-n表示边不满足控制条件。
[0039]
4.1.4)标准化代码流程图(scfc)结构包括三种类型:
[0040]
(1)ss:顺序结构;
[0041]
(2)bs:分支结构;
[0042]
(3)ls:循环结构。
[0043]
步骤5图相似度计算:通过基于最短路径图内核的图相似度计算方法获得图相似度,并以此作为代码相似度依据来检测作弊行为。由于scfc是有向图,因此采用图相似度计算算法来测量两种scfc图的相似性,本发明基于图相似度计算中的基于路径相似度度量方法,基于最短路径图内核(spgk)来计算,不考虑相同边缘的重复遍历。spgk使用floyd
–
warshall算法,根据图形的邻接矩阵查找图形中任意两个顶点之间的距离。基于此本发明提出了scfc-spgk算法。由于scfc是与根节点的有向图,因此从根节点到其他节点的最短路径(单源路径)足以反映scfc的特征,并且可以降低时间复杂度。
[0044]
步骤5)的具体操作过程包括如下步骤:
[0045]
5.1)s1={p1,p2,
…
,pn}和s2={p1,p2,
…
,pm}代表获取到的两个待比较代码的最短路径集,l是s1中各个路径pi的路径长度,在s2中[l-1,l 1]的范围中进行匹配,从而获得集
合s={(pi,p
′j)|0《i《n,0《j《m},其中pi,p
′j分别表示s1中的路径以及与之匹配的s2中的路径;
[0046]
5.2)对每个路径对,计算编辑距离dv的节点属性序列(vi,vj),0《i《n,0《j《m和编辑距离de的边属性序列(ei,ej),0《i《n,0《j《m;5.3)选择dv与de之和最小的路径p
′j与pi配对,并在剩余的未配对路径集合中去除分别取出该路径对元素;
[0047]
5.4)最终配对后的路径对集合为s
final
={(pi,p
′j)|0《i《t,0《j《t,t=min(m,n)},核函数定义如下:
[0048][0049]
其中g1,g2表示待计算的两个图,mi=len(pi),mj=len(pj),在获得两个图的核之后,将核的比值和匹配集中匹配的路径对的数目作为两个图的相似度,然后对匹配集中的匹配路径对进行匹配,
[0050][0051]
所得sim(g1,g2)即为图相似度,即待测代码的相似度,当该相似度大于设置值时,能判断存在作弊现象。
[0052]
本发明的有益效果在于:
[0053]
1)在已有作弊检测算法的基础上增加了对循环方式替换,数据存储格式的修改以及无用调用和语句混淆手段的抗性。
[0054]
2)在使用计算图相似度表示代码相似度的过程中,通过图标准化消除了不同编程语言对相似度终值的影响。
[0055]
3)基于最短路径图内核的图相似度计算方法针对代码流程图计算,对比其他算法更节约时间,效率更高。
附图说明
[0056]
图1为实施例的程序依赖图;
[0057]
图2为实施例的有向程序依赖图;
[0058]
图3为实施例的运行代码流程图;
[0059]
图4为标准化后的代码流程图。
具体实施方式
[0060]
下面结合实施例和说明书附图对本发明做进一步地说明,但本发明的保护范围并不仅限于此。
[0061]
实施例
[0062]
步骤1构造程序依赖图(pdg):找到程序和语句之间的依赖关联,进行代码清洗,去除冗余代码(无效声明、无效调用、注释、空行、无效计算),获得代码完成目标功能的最简pdg;
[0063]
例如给出两段计算最小值的代码片段两份,其中一份包含无效声明和无效处理,为了符合一般代码习惯,两份代码都通过return语句结尾。
[0064]
给出一段计算最小值的代码(a),其中包含冗余代码
[0065][0066][0067]
将源代码转换为pdg,记为图1,pdg中所有边的原点和终点进行交换,在pdg中从输出语句对应的节点执行深度遍历,并返回语句(跳过已遍历的节点),获得新的有向图2。
[0068]
将不在图2中的节点对应代码在源代码中删去,获得清洗后的代码(b)
[0069][0070]
至此,步骤1,代码清洗完成。
[0071]
步骤2运行日志生成:构造探针代码,打印简洁的运行日志,保存探针日志结果作为pm的输入。构造探针代码的目的是生成代码运行日志,从而明确代码的运行流程,作为代码流程图的构造依据。因此,需要在代码中加入实现目标功能以外的探针代码,从而为日志生成提供代码支持。根据本发明的构思核心,该探针应该植入于源代码,即对源文件进行完整的词法、语法分析后,确认插桩的位置,相比于对目标代码的探针植入,源代码植入具有针对性和精确性。植入方法使用中国航天系统科学与工程研究院在2016年提出的基于源代码的程序自动插桩方法,在本发明中的应用,定义如下几条探针语句和探针代码添加规则:
[0072]
(1)declare(type1,type2,
…
,typen):在变量声明操作后植入,其中,typek(k∈[1,n])为该代码对应程序语言中变量类型集合的元素。其具体值为探针代码前的一个代码基本块的声明类型。若该探针前代码基本块只有一个声明语句,则括号中的参数为单值,即声明类型;若该探针前有多个连续声明语句则合并,按照变量名称首字母顺序放入参数中。并且为该类型每次探针使用,从1开始编号。
[0073]
(2)assign(type1,type2,
…
,typen):在赋值操作后植入,其中,typek(k∈[1,n])为该代码对应程序语言中变量类型集合的元素。其具体值为探针代码前的一个代码基本块的被赋值变量类型。若在该基本块中有多个连续的,彼此无数据依赖的赋值语句,则将探针代码合并为一个,所有变量类型按照源代码顺序放入参数中,位于最后一个赋值语句之后。并且为该类型每次探针使用,从1开始编号。需要注意的是,若声明和赋值在同一句中实现,则插入该探针。
[0074]
(3)output:在打印操作后植入,并且为该类型每次探针使用,从1开始编号。
[0075]
(4)return:在返回操作后植入,并且为该类型每次探针使用,从1开始编号。
[0076]
针对上述规则,使用本发明在步骤1中使用的代码给出实例:
[0077]
代码行1、行2为变量声明语句,声明类型均为int,彼此无数据关联,根据第一条规
则,合并为assign1(int,int)。if分支出两个基本块,对其中的返回语句分别进行探针植入,即表1中的return1和return2。
[0078]
表1探针日志
[0079][0080]
至此,步骤2运行日志生成完成。
[0081]
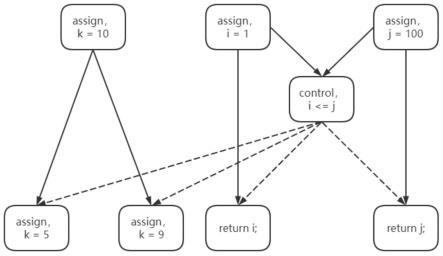
步骤3代码流程图(cfc)构造:通过pm算法构造出清洗后的代码流程图,得到代码的实际运行过程。
[0082]
基于上述步骤的日志实例,生成下方代码流程图cfc=(v,e)。其中v为日志节点集合,将每一次探针打印序列作为一个活动,以多次运行结果的日志序列中各个语句的出现凑数和依赖度量值生成流程图。实例中return1,return2出现在不同的运行日志中因此分装在互斥分支中。分别与前方assign1语句有直接依赖关系,因此共同为其后继,得到的代码流程图cfc如图3所示。
[0083]
步骤4代码流程图标准化:将代码流程图标准化为标准化代码流程图图3标准化的具体步骤如下:
[0084]
1)分析图的组成,按照图顺序为:一个assign代码块赋初值;分支由控制块获得,因此包含一个control控制代码块;控制获得两条分支分别对应两个赋值,因此又包含两个assign。
[0085]
2)确定代码块关系:首个assign与control有顺序结构关系,因此二者直接相关;最后两个assign由control获得,因此分别与assign相关;分析边缘。
[0086]
3)上述关系1为顺序结构,因此用顺序执行边缘see相连。
[0087]
4)上述关系2为控制分支获得,因此用控件依赖关系边缘cde相连。由于该控制模块为判断模块,因此有正确yes和错误no两种可能,因此边缘区分为cde-y与cde-n,结果如图4所示。
[0088]
步骤5图相似度计算:通过基于最短路径图内核的图相似度计算方法获得图相似度,并以此作为代码相似度依据来检测作弊行为。
[0089]
5.1)s1={p1,p2,
…
,pn}和s2={p1,p2,
…
,pm}代表获取到的两个待比较代码的最短路径集,l是s1中各个路径pi的路径长度,在s2中[l-1,l 1]的范围中进行匹配,从而获得集合s={(pi,p
′j)|0《i《n,0《j《m},其中pi,p
′j分别表示s1中的路径以及与之匹配的s2中的路径;
[0090]
5.2)对每个路径对,计算编辑距离dv的节点属性序列(vi,vj),0《i《n,0《j《m和编辑距离de的边属性序列(ei,ej),0《i《n,0《j《m;
[0091]
5.3)选择dv与de之和最小的路径p
′j与pi配对,并在剩余的未配对路径集合中去除分别取出该路径对元素;
[0092]
5.4)最终配对后的路径对集合为s
final
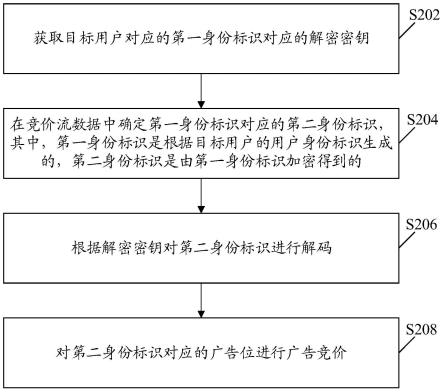
={(pi,p
′j)|0《i《t,0《j《t,t=min(m,n)},核函数定义如下:
[0093]
[0094]
其中g1,g2表示待计算的两个图,mi=len(pi),mj=len(pj),在获得两个图的核之后,将核的比值和匹配集中匹配的路径对的数目作为两个图的相似度,然后对匹配集中的匹配路径对进行匹配,
[0095][0096]
所得sim(g1,g2)即为图相似度,即待测代码的相似度,当该相似度大于设置值时,能判断存在作弊现象。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。