1.本发明属于交通检测技术领域,尤其涉及一种基于多任务学习的实时高速公路行人闯入事件检测方法。
背景技术:
2.随着高速公路建设的快速发展与迅速成熟,高速公路的运行速度和通车里程不断增加,给人们的生活带来了便利,但同时高速公路的事故也随之频发。其中,行人闯入是高速公路事故中主要突发事件来源之一,若不能及时准确的进行行人检测和报警,会极大程度导致交通事故的发生,严重影响到高速公路的行车安全和人员的人身安全。因此高速公路行人闯入的实时检测与自动预警对保障公路交通安全具有重要意义。
3.目前,利用现有的高速公路视频监控系统已经可以实现了对行人的实时监控。但对于行人闯入情况的发现,仍然需要辅以工作人员观察视频图像序列、通过人工监控以及自动检测辅助的方式实现,并未完全实现行人的自动检测。究其根本原因是:行人自动检测的准确率以及召回率有待提升。
4.目前基于视频的行人检测方法分为传统的行人检测方法和深度学习的行人检测方法。传统的行人检测算法主要采用基于图像处理的方法,需要人工提取图像特征,不仅耗时耗力,而且检测效果并不理想。基于视频序列的行人检测方法使用背景差分法或者帧间差分法等方法区分前景,再进一步识别行人,但识别准确率均不高。上述的两种传统行人检测算法误检率高,无法满足高速公路行人闯入事件检测的实时性和准确性要求。
5.深度学习算法能提取目标的深层特征,不需要人工设计,在目标检测的实时性和准确性上都有很好的效果。包括两阶段方法,比如r-cnn与faster r-cnn等,一阶段方法,比如yolo与ssd等。为了满足高速公路上的检测实时性,目前工业界常用一阶段的yolo算法。
6.但是传统方法与深度学习方法大部分是对全图区域进行检测,不符合高速公路的特定应用场景,即对高速公路上的行人进行预警,因此会出现道路之外的行人误预警。并且,现有最好的方法仍然会出现阴影、栏杆、锥桶、树木等误报,准确率难以满足高速公路场景。除外,也有一些学者考虑先分割后检测方法,但这种方法需要先分割出道路,然后才能在此基础上进行行人检测,实时性达不到应用要求。
技术实现要素:
7.技术问题:针对现有技术存在的不足,本发明的目的在于提供了一种基于多任务学习的实时高速公路行人闯入事件检测方法,该方法能够准确、实时、有效的针对高速公路的行人闯入事件进行检测,为高速公路的交通安全提供保障。
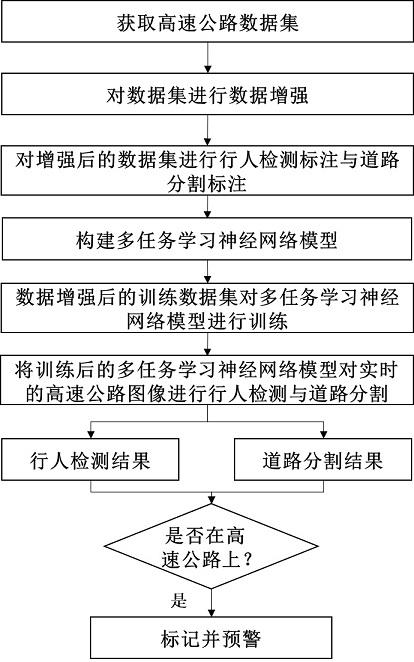
8.技术方案:为实现上述目的,本发明提出了一种基于多任务学习的实时高速公路行人闯入事件检测方法,该方法包括如下步骤:s1、从高速公路摄像头中获取数据集;s2、对获取的数据集进行数据增强;
s3、对数据增强后的数据集进行行人检测标注与道路分割标注以构建数据集;s4、构建多任务学习神经网络模型;s5、根据数据增强后的训练数据集对多任务学习神经网络进行训练;s6、根据训练后的多任务学习神经网络模型对实时高速公路图像进行行人检测和道路分割;s7、判断行人是否在高速公路上,并对高速公路上的行人进行标记和预警。
9.进一步的,步骤s1中,对高速公路上摄像头获取的视频以预设帧率获取原始图像,原始图像包含高速公路上不同时段、不同角度摄像头下所拍摄的图像。
10.进一步的,步骤s2中,对获取的数据集进行数据增强的方法如下:(1)将原始图像进行几何变换:随机图像旋转:将原始图像进行-15度至 15度之间随机旋转生成新的图像;随机水平翻转:将原始图像进行随机水平翻转生成新的图像;(2)将原始图像进行裁剪与拼接:将图像从纵向均等切分为p1、p2、p3三部分,若p1中含有行人并且行人未被截断,则p1复制两份p11,p12,再将p1,p11,p12按照纵向拼接成新的图像;(3)对原始图像进行行人增加:随机在所有图像上增加预设数量的行人以增加高速公路上的行人样本数量;经过步骤(1)-(3)数据增强后得到增强后的数据集。
11.进一步的,步骤s3中,对增强后的数据集中的每一张图像分别进行行人检测标注与道路分割标注包括如下步骤:先将增强后的原图输入到yolov5模型中,自动标注以获取初步的行人标注文件,每张图像对应一个txt标注文件,txt文件中记录该张图像中所有的行人信息,txt文件中多行代表有多个行人,每一行表示该图像中的一个行人记录,该记录包含类别代号id,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h;利用lableme标注工具中的矩形标注按钮对上述自动标注的信息进行修正,将非行人标注成行人的情况删除;将未被标注的行人,手动添加标注;将标注框有所偏移的情况进行修正,将修正完成后的txt标注文件作为该图像的行人检测标注文件;对同一张原始图像利用lableme标注工具中的多边形标注按钮对图像中的道路区域以选点连线的方式形成封闭多边形,将多边形内的道路区域的像素值置为1,多边形外的背景像素值置为0,生成像素值只含有0与1的图像,将生成的图像作为该图像的分割标注文件;将一张原始图像对应一个行人检测的txt标注文件以及一张分割标注图像,所有图像经过上述操作得到多个txt标注文件以及分割标注图像以构成多任务数据集;将上述的多任务数据集按照3:1比例划分为训练集与测试集。
12.进一步的,步骤s4中,构建多任务学习神经网络模型包括共享模块、检测模块、分割模块;a、共享模块:所述的共享模块是由yolov5的第一层至第十六层构成,图像经过共享模块后,得到的特征图尺寸为输入图像的八分之一,得到的特征图通道数为256;b、检测模块:所述检测模块是由yolov5的第十六层至第二十四层构成,与共享模
块进行串联,将共享模块得到的特征图输入到检测模块中,通过检测模块后得到的行人预测结果,其含预测出的行人边界框总数量n、每个行人边界框对应的分类预测值、置信度预测值,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h,其中,置信度预测值表示该边界框中包含行人对象的确定性概率,且置信度预测值∈[0,1];c、分割模块:所述分割模块是与共享模块进行串联,与检测模块进行并联,分割模块共包含9层,依次是cbs层f1、upsample上采样层f2、c3_1_2层f3、cbs层f4、upsample上采样层f5、cbs层f6、c3_1_2层f7、上采样层f8以及cbs层f9;其中,将共享模块的得到的特征图先输入到f1层,f1层包含一个核大小为3*3的卷积conv,此时特征图的通道数从256降维至128,特征图的尺寸为输入图像的八分之一;从f1得到的特征图输入到f2层,将特征图的尺寸上采样2倍,此时的特征图尺寸为输入图像的四分之一,通道数不变;接着输入到f3层,将特征图的通道数从128降维至64,特征图的尺寸不变;接着输入到f4层,将特征图的通道数从64降维至32,特征图的尺寸不变;接着输入到f5层,将特征图的尺寸上采样2倍,此时的特征图尺寸为输入图像的二分之一,通道数不变;接着输入到f6层,将特征图的通道数从32降维至16,特征图的尺寸不变;接着输入到f7层,将特征图的通道数从16降维至8,特征图的尺寸不变;接着输入到f8层,将特征图的尺寸上采样2倍,恢复成输入图像的大小,通道数不变;接着输入到f9层,将特征图的通道数从8降维至1,特征图的尺寸不变,为输入图像的大小;通过分割模块后,输出一张与输入图像大小相同的特征图,其中,特征图中的每一个值对应输入图像的每个位置对应的类别值,其中,预测的类别值为0,代表该位置为背景部分,预测的类别值为1,代表该位置为道路部分。
[0013]
进一步的,步骤s5,根据数据增强后的训练数据集对多任务学习神经网络进行训练包括如下步骤;随机选取数据增强后的训练集中s个图像数据{x
(1)
,
…
,x
(s)
}输入到多任务模型中,得到相应的输出预测结果{y
(1)
,
…
, y
(s)
};每个图像的输出预测结果包含检测结果以及分割结果两个部分,其中,检测结果包含预测出的行人边界框总数量n、每个行人边界框对应的分类预测值、置信度预测值,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h;分割结果输出一张与输入图像大小相同的特征图,特征图中的每一个值对应输入图像的每个位置对应的类别值,其中,预测的类别值为0,代表该位置为背景部分,预测的类别值为1,代表该位置为道路部分,根据多任务模型的损失函数,通过反向传播算法,更新迭代权重参数,将此步骤进行循环迭代训练,直至多任务网络模型收敛;其中,所述的多任务网络模型的损失函数由检测模块损失函数和分割模块损失函数两部分组成,其中检测模块损失函数为:为:为:为:
其中,为分类损失函数,为位置损失函数,为置信度损失函数,、、分别为分类损失、位置损失、置信度损失的权重,表示输入图像的类别真实值,表示输入图像的类别预测值,表示输入图像的预测目标框,表示输入图像的真实目标框,表示输入图像的预测目标框与输入图像的真实目标框的交集的面积,表示输入图像的预测目标框与输入图像的真实目标框的并集的面积,表示预测目标框的中心点,表示真实目标框的中心点,表示预测目标框中心点与真实目标框中心点之间的距离,表示输入图像的置信度真实值,表示输入图像的置信度预测值;其中,分割模块损失函数为:其中,为输入图像中所有的像素点个数,为输入图像中第个像素点对应位置的预测类别概率值,为输入图像中第个像素点对应位置的真实标签值。
[0014]
进一步的,步骤s6中,将一张实时图像输入至训练后的多任务模型中进行行人闯入事件检测以得到行人检测结果以及道路分割结果,行人检测结果包含输入的图像中是否存在行人,若存在行人,得到行人所在的位置;道路分割结果输出一张与输入图像大小相同的特征图,特征图里的值为0或者为1,若值为0,代表输入的图像中相对应的位置为背景部分,若值为1,代表输入的图像中相对应的位置为道路部分。
[0015]
进一步的,步骤s7中,由步骤s6得到行人检测框位置与道路区域位置,根据行人检测框与道路区域的交集面积判断行人是否在高速公路上,当交集面积大于0时,则该行人在高速公路上,则进行标记并产生预警;当交集面积等于0时,则该行人不在高速公路上,不进行预警。
[0016]
有益效果:与现有技术先比,本发明的技术方案具有以下有益技术效果:(1)本发明根据高速公路摄像头下的特有角度,将图像中目标所在的区域进行裁剪、复制、拼接成新图像,有效增加目标的数量,进而提高目标的检测率。
[0017]
(2)本发明采用深度学习神经网络自动学习提取道路语义分割特征,能够分割多个不同摄像头下高速公路的道路区域,提取高速公路上感兴趣区域,减少道路之外的误检。
[0018]
(3)本发明基于一种多任务学习神经网络模型,其能够同时进行目标检测与道路分割,满足高速公路监控视频实时的处理需要。
[0019]
(4)本发明提出的一种基于多任务学习的实时高速公路行人闯入事件检测方法,能够有效地解决高速公路上行人闯入事件的检测与预警。
附图说明
[0020]
图1为本发明yolov5模型的结构示意图;
图2为本发明多任务学习神经网络模型简图;图3为本发明多任务学习神经网络模型详细图;图4为本发明行人与道路区域位置示意图;图5为本发明的方法流程图。
具体实施方式
[0021]
下面结合附图和具体实施例对本发明作进一步详细说明。
[0022]
本实施例公开了一种基于多任务学习的实时高速公路行人闯入事件检测方法,该方法包括如下步骤:s1、从高速公路摄像头中获取数据集;s2、对获取的数据集进行数据增强;s3、对数据增强后的数据集进行行人检测标注与道路分割标注以构建数据集;s4、构建多任务学习神经网络模型;s5、根据数据增强后的训练数据集对多任务学习神经网络进行训练;s6、根据训练后的多任务学习神经网络模型对实时高速公路图像进行行人检测和道路分割;s7、判断行人是否在高速公路上,并对高速公路上的行人进行标记和预警。
[0023]
更具体的,步骤s1包括如下具体步骤:对高速公路上摄像头获取的视频以预设帧率获取原始图像,原始的图像包含高速公路上不同时段、不同角度摄像头下所拍摄的图像。
[0024]
更具体的,步骤s2的具体步骤包括:(1)将原始图像进行几何变换:随机图像旋转:将原始图像进行-15度至 15度之间随机旋转生成新的图像;随机水平翻转:将原始图像进行随机水平翻转生成新的图像;(2)将原始图像进行裁剪与拼接:将图像纵向均等切分为p1、p2、p3三部分,若p1中含有行人并且行人未被截断,则p1复制两份p11,p12,再将p1,p11,p12按照纵向拼接成新的图像;(3)对原始图像进行行人增加:随机在所有图像上增加预设数量的行人以增加高速公路上的行人样本数量;经过步骤(1)-(3)数据增强后得到增强后的数据集。
[0025]
更具体的,步骤s3的具体步骤包括:标注的过程:先将增强后的原图输入到yolov5模型中,自动标注以获取初步的行人标注文件,每张图像对应一个txt标注文件,txt文件中记录这张图像中所有的行人信息,txt文件中多行代表有多个行人,每一行表示该图像中的一个行人记录,包含类别代号id,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h;利用lableme标注工具中的矩形标注按钮对上述自动标注的信息进行修正,将非行人标注成行人的情况删除;将未被标注的行人,手动添加标注;将标注框有所偏移的情况进行修正,将修正完成后的txt标注文件作为这张图像的行人检测标注文件;
对同一张原始图像利用lableme标注工具中的多边形标注按钮对图像中的道路区域以选点连线的方式形成封闭多边形,将多边形内的道路区域的像素值置为1,多边形外的背景像素值置为0,生成像素值只含有0与1的图像,将生成的图像作为该图像的分割标注文件;将一张原始图像对应一个行人检测的txt标注文件以及一张分割标注图像,所有图像经过上述操作得到多个txt标注文件以及分割标注图像以构成多任务数据集;将上述的多任务数据集按照3:1比例划分为训练集与测试集。
[0026]
更具体的,步骤s4的具体步骤包括:本发明构建一个适合于高速公路场景的多任务学习神经网络模型,所述的多任务学习神经网络模型基于一阶段的yolov5模型,yolov5模型是目前目标检测任务中精度与速度达到平衡的一个实时检测模型,常被用于工业界,yolov5网络模型共有二十四层如图1所示。针对高速公路场景本方案将yolov5单任务模型追加一个分割模块改为可以同时进行检测与分割的多任务模型,所设计的多任务学习神经网络模型简图如图2所示。构建的多任务模型可分解为三个子模块 :共享模块、检测模块、分割模块。
[0027]
a、共享模块:如图3所示,所述的共享模块是由yolov5的第一层至第十六层构成,图像经过共享模块后,得到的特征图尺寸为输入图像的八分之一,得到的特征图通道数为256;b、检测模块:如图3所示,所述检测模块是由yolov5的第十六层至第二十四层构成,与共享模块进行串联,将共享模块得到的特征图输入到检测模块中,通过检测模块后得到的行人预测结果,其含预测出的行人边界框总数量n、每个行人边界框对应的分类预测值、置信度预测值,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h,其中,置信度预测值表示该边界框中包含行人对象的确定性概率,且置信度预测值∈[0,1];c、分割模块:如图3所示,所述分割模块是与共享模块进行串联,与检测模块进行并联,分割模块共包含9层,依次是cbs层f1、upsample上采样层f2、c3_1_2层f3、cbs层f4、upsample上采样层f5、cbs层f6、c3_1_2层f7、上采样层f8以及cbs层f9。
[0028]
其中,将共享模块的得到的特征图先输入到f1层,f1层包含一个核大小为3*3的卷积conv,此时特征图的通道数从256降维至128,特征图的尺寸为输入图像的八分之一;从f1得到的特征图输入到f2层,将特征图的尺寸上采样2倍,此时的特征图尺寸为输入图像的四分之一,通道数不变;接着输入到f3层,将特征图的通道数从128降维至64,特征图的尺寸不变;接着输入到f4层,将特征图的通道数从64降维至32,特征图的尺寸不变;接着输入到f5层,将特征图的尺寸上采样2倍,此时的特征图尺寸为输入图像的二分之一,通道数不变;接着输入到f6层,将特征图的通道数从32降维至16,特征图的尺寸不变;接着输入到f7层,将特征图的通道数从16降维至8,特征图的尺寸不变;接着输入到f8层,将特征图的尺寸上采样2倍,恢复成输入图像的大小,通道数不变;接着输入到f9层,将特征图的通道数从8降维至1,特征图的尺寸不变,为输入图像的大小;通过分割模块后,输出一张与输入图像大小相同的特征图,其中,特征图中的每一个值对应输入图像的每个位置对应的类别值,其中,预测的类别值为0,代表该位置为背景部分,预测的类别值为1,代表该位置为道路部分。
[0029]
更具体的,步骤s5的具体步骤包括如下步骤:
随机选取数据增强后的训练集中s个图像数据{x
(1)
,
…
,x
(s)
}输入到多任务模型中,得到相应的输出预测结果{y
(1)
,
…
, y
(s)
};每个图像的输出预测结果包含检测结果以及分割结果两个部分,其中,检测结果包含预测出的行人边界框总数量n、每个行人边界框对应的分类预测值、置信度预测值,标注框的中心点横坐标与原图宽的比例center_x,标注框的中心点纵坐标与原图高的比例center_y,标注框的宽与原图宽的比例w以及标注框的高与原图高的比例h;分割结果输出一张与输入图像大小相同的特征图,特征图中的每一个值对应输入图像的每个位置对应的类别值,其中,预测的类别值为0,代表该位置为背景部分,预测的类别值为1,代表该位置为道路部分,根据多任务模型的损失函数,通过反向传播算法,更新迭代权重参数,将此步骤进行循环迭代训练,直至多任务网络模型收敛;其中,所述的多任务网络模型的损失函数由检测模块损失函数和分割模块损失函数两部分组成,其中检测模块损失函数为:为:为:为:其中,为分类损失函数,为位置损失函数,为置信度损失函数,、、分别为分类损失、位置损失、置信度损失的权重,表示输入图像的类别真实值,表示输入图像的类别预测值,表示输入图像的预测目标框,表示输入图像的真实目标框,表示输入图像的预测目标框与输入图像的真实目标框的交集的面积,表示输入图像的预测目标框与输入图像的真实目标框的并集的面积,表示预测目标框的中心点,表示真实目标框的中心点,表示预测目标框中心点与真实目标框中心点之间的距离,表示输入图像的置信度真实值,表示输入图像的置信度预测值;其中,分割模块损失函数为:其中,为输入图像中所有的像素点个数,为输入图像中第个像素点对应位置的预测类别概率值,为输入图像中第个像素点对应位置的真实标签值。
[0030]
更具体的,步骤s6的具体步骤包括:将一张实时图像输入至训练后的多任务模型中进行行人闯入事件检测以得到行人检测结果以及道路分割结果,行人检测结果包含输入的图像中是否存在行人,若存在行人,得到行人所在的位置;道路分割结果输出一张与输入图像大小相同的特征图,特征图里
的值为0或者为1,若值为0,代表输入的图像中相对应的位置为背景部分,若值为1,代表输入的图像中相对应的位置为道路部分。
[0031]
更具体的,步骤s7的具体步骤包括:由步骤s6得到行人检测框位置与道路区域位置如图4所示,根据行人检测框与道路区域的交集面积判断行人是否在高速公路上,当交集面积大于0时,则该行人在高速公路上,则进行标记并产生预警;当交集面积等于0时,则该行人不在高速公路上,不进行预警。
[0032]
以上对本发明实施例所提供的一种基于多任务学习的实时高速公路行人闯入事件检测方法进行了详细介绍,对于本领域的一般技术人员,依据本发明实施例的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。