一种基于改进swin transformer的杂志、书刊广告嵌入方法
技术领域
1.本发明属于图像处理技术领域,具体是指一种基于改进swin transformer的文本广告嵌入方法。
背景技术:
2.杂志广告是指刊登在杂志上的广告。杂志广告具有针对性强,保留时间长,传阅者众多,画面印刷效果好等优点;专业性杂志针对不同的读者对象,安排相应的阅读内容,因而就能受到不同的读者对象的欢迎;杂志的专业化倾向也发展得很快,如医学杂志、科普杂志、各种技术杂志等,其发行对象是特定的社会阶层或群体,专业性杂志由于具有固定的读者层面,可以使广告宣传深入某一专业行业。
3.杂志的封页、内页及插页都可做广告之用,对广告的位置可机动安排,可以突出广告内容,激发读者的阅读兴趣;同时对于广告内容的安排,可做多种技巧性变化,如折页、插页、连页、变形等,吸引读者的注意;目前,杂志广告往往单独成页,且杂志广告所占篇幅较大,据统计,平均一本专业杂志上的广告占总页数的百分之十五之多,若将杂志广告与杂志内的文章加以融合,可以大幅提高纸张的利用率,这对减少能源消耗、改善生态环境有着举足轻重的作用。
4.将杂志广告与杂志文本的融合涉及图像处理领域,传统的方法需要专业制图人员使用专业绘图工具,才能将杂志广告融合到杂志文本中。
技术实现要素:
5.为解决现有技术的上述问题,本发明提供一种基于改进swin transformer的文本广告嵌入方法,可以有效解决:
6.(1)将杂志广告与杂志文本进行融合,有效提升纸张的利用率;
7.(2)传统的图像融合需要专业人员进行人工处理,且存在效果的不一致性问题;
8.(3)技术领域设计图像处理领域,而传统的图像融合方式采用卷积神经网络,当处理的图像尺寸较大时,计算复杂度指数级增大。
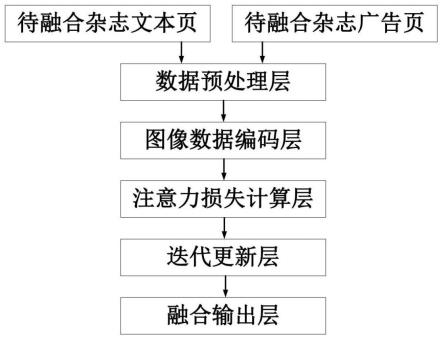
9.具体的,本发明采用的一种技术方案为:一种基于改进swin transformer的文本广告嵌入方法,包括待融合杂志文本页、待融合杂志广告页、数据预处理层、图像数据编码层、注意力损失计算层、迭代更新层和融合输出层:所述图像数据编码层包括多头自注意力层和前馈网络层:
10.进一步地,所述待融合杂志文本页为杂志内除广告以外的论文或期刊文章的内容页,在初始排版时文件格式为doc文件,进行后续的处理需将其格式转换为jpg格式或png格式,对待融合杂志文本页的尺寸reshape操作,得到尺寸为h
×w×
c,记为text_page。
11.作为优选地,所述待融合杂志广告页为杂志内的广告页面,在进行后续的处理时需将其转换为jpg格式或png格式,所述待融合杂志广告页的尺寸reshape操作,得到尺寸为h
×w×
c,记为ad_page。
12.进一步地,在数据预处理层对text_page和ad_page数据预处理操作,包括分块操作、展平操作与合并操作:
13.(1)分块操作,text_page和ad_page的尺寸均为h
×w×
c,分块后均得到个数为n的小正方形区域,其中,小正方形区域的尺寸为:
14.p
×
p
×c15.小正方形区域的个数n为:
[0016][0017]
(2)展平操作,对每个小正方形区域进行展平,得到1
×
(p
×
p
×
c)维的向量x;
[0018]
(3)合并操作,将n个小正方形展平后的向量进行合并得到矩阵x,其维度为n
×
(p
×
p
×
c),形式为:
[0019]
x=[x1,x2,
…
,xn]
t
[0020]
将text_page经过数据预处理层得到的结果记为x
text
,将ad_page经过数据预处理层得到的结果记为x
ad
。
[0021]
作为优选地,所述自注意力层用于比较每个小正方形区域之间相关性并得到抽象语义特征,可解决信息量过大带来的算力不足的问题,具体计算步骤如下:
[0022]
s1、生成每个分量的取值范围在-1到1之间的特征矩阵l、m和n,将特征矩阵l、m和n设置为不可修改,其中特征矩阵l、m和n的形式均为:
[0023]
l=[l1,l2,
…
,ln]
t
[0024]
m=[m1,m2,
…
,mn]
t
[0025]
n=[n1,n2,
…
,nn]
t
[0026]
其中,特征矩阵l、m和n的每个分量的维度均为(p
×
p
×
c)
×
1;
[0027]
s2、通过特征矩阵l、m和n生成查寻矩阵in、键矩阵k和值矩阵v,具体计算方式为:
[0028]
in=x
×
l
t
[0029]
k=x
×mt
[0030]
v=x
×nt
[0031]
其中,
[0032]
in=[in1,in2,
…
,inn]
t
[0033]
k=[k1,k2,
…
,kn]
t
[0034]
v=[v1,v2,
…
,vn]
t
[0035]
s3、计算注意力分布,具体计算公式为:
[0036][0037]
根据注意力分布对输入信息进行加权平均:
[0038][0039]
上式中,atti为的维度为n
×
1。
[0040]
进一步地,所述前馈网络层,包括bp神经网络,所述bp神经网络的个数为n个,所述
bp神经网络包括前馈输入层和中间隐层和前馈输出层构成,其中前馈输入层含有n个神经元,中间隐层均含有p
×
c个神经元,前馈输出层含有p个神经元;前馈输入层的输入分别为att1、att2、...、att
n-1
和attn,分别将att1、att2、...、att
n-1
和attn输入到各自的bp神经网络中计算得到的前馈输出记为f1、f2、...、f
n-1
和fn,具体计算步骤为:
[0041]fi
=max(w1atti b1)w2 b
2 i∈(1,2,
…
,n)
[0042]
上式中,b1表示中间隐层的偏置,b2表示前馈输出层的偏置,w1为中间隐层的内星权向量,w2为前馈输出层的内星权向量,其中的b1、b2、w1和w2设为不可训练,fi为每个bp神经网络的输出,具体为f1、f2、...、f
n-1
和fn,其维度均为p
×
1。
[0043]
作为优选地,所述注意力损失计算层用于计算text_page的前馈输出与ad_page的前馈输出之间的差异,具体计算公式如下:
[0044][0045]
上式中,f
text
表示text_page的前馈输出,f
ad
表示ad_page的前馈输出。
[0046]
进一步地,所述迭代更新层利用梯度下降算法对text_page进行迭代更新得到图像pic,由于图像数据编码层中的参数l、m、n、b1、b2、w1和w2均为固定值,只需对text_page进行更新即可,具体计算公式为:
[0047][0048]
上式中,x
text
表示text_page经过数据预处理层处理后得到的结果,λ为学习率,最后更新结果即为图像pic,其形式为:
[0049][0050]
作为优选地,所述融合输出层的数据由两部分构成,包括图像pic和将text_page经过数据预处理层得到的x
text
,所述融合输出层的计算步骤如下:
[0051]
c=μ*pic ξ*x
text
[0052]
展开为:
[0053][0054]
上式中,μ和ξ为加权系数,c表示最终嵌入了广告的杂志文本所对应的矩阵形式,将其转录为图像即为最终结果。
[0055]
采用上述方法,本发明具有以下优点:
[0056]
(1)将杂志广告与杂志文本进行融合,有效提升纸张的利用率;
[0057]
(2)本发明提出的一种基于改进swin transformer的文本广告嵌入方法是一种自动化的杂志广告嵌入处理方式,节省了人工劳动力。
[0058]
(3)本发明使用改进swin transformer取代了传统的基于卷积神经网络的图像处理方式,可方便实现并行计算和分布式计算,加快了数据处理速度;
[0059]
(4)本发明提出的一种基于改进swin transformer的文本广告嵌入方法可方便的使用pytorch或tensorflow进行搭建;
[0060]
(5)由于在图像数据编码层中的参数l、m、n、b1、b2、w1和w2均为固定值,因此有别与
传统swin transformer,不存在训练阶段,直接进行迭代更新即可。
附图说明
[0061]
图1为本发明提出的一种基于改进swin transformer的文本广告嵌入方法的计算流程图;
[0062]
图2为本发明提出的数据预处理层的计算流程图;
[0063]
图3为图像数据编码层的计算流程图;
[0064]
图4为注意力损失计算层计算方法的示意图。
[0065]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
具体实施方式
[0066]
下面将结合本方案实施例中的附图,对本方案实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本方案一部分实施例,而不是全部的实施例;基于本方案中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本方案保护的范围。
[0067]
实施例
[0068]
结合附图1-4,本实施例提供一种基于改进swin transformer的文本广告嵌入方法,包括待融合杂志文本页、待融合杂志广告页、数据预处理层、图像数据编码层、注意力损失计算层、迭代更新层和融合输出层:所述图像数据编码层包括多头自注意力层和前馈网络层。
[0069]
待融合杂志文本页为杂志内除广告以外的论文或期刊文章的内容页,在初始排版时文件格式为doc文件,进行后续的处理需将其格式转换为jpg格式或png格式,对待融合杂志文本页的尺寸reshape操作,得到尺寸为208
×
288
×
3,记为text_page。
[0070]
待融合杂志广告页为杂志内的广告页面,在进行后续的处理时需将其转换为jpg格式或png格式,所述待融合杂志广告页的尺寸reshape操作,得到尺寸为208
×
288
×
3,记为ad_page。
[0071]
数据预处理层对text_page和ad_page数据预处理操作,包括分块操作、展平操作与合并操作:
[0072]
(1)分块操作,text_page和ad_page的尺寸均为208
×
288
×
3,分块后均得到个数为234的小正方形区域,其中,小正方形区域的尺寸为:
[0073]
16
×
16
×3[0074]
小正方形区域的个数n为:
[0075][0076]
(2)展平操作,对每个小正方形区域进行展平,得到1
×
768维的向量x;
[0077]
(3)合并操作,将234个小正方形展平后的向量进行合并得到矩阵x,其维度为234
×
768,形式为:
[0078]
x=[x1,x2,
…
,xn]
t
[0079]
将text_page经过数据预处理层得到的结果记为x
text
,将ad_page经过数据预处理层得到的结果记为x
ad
。
[0080]
自注意力层用于比较每个小正方形区域之间相关性并得到抽象语义特征,可解决信息量过大带来的算力不足的问题,具体计算步骤如下:
[0081]
s1、生成每个分量的取值范围在-1到1之间的特征矩阵l、m和n,将特征矩阵l、m和n设置为不可修改,其中特征矩阵l、m和n的形式均为:
[0082]
l=[l1,l2,
…
,ln]
t
[0083]
m=[m1,m2,
…
,mn]
t
[0084]
n=[n1,n2,
…
,nn]
t
[0085]
其中,特征矩阵l、m和n的每个分量的维度均为768
×
1;
[0086]
s2、通过特征矩阵l、m和n生成查寻矩阵in、键矩阵k和值矩阵v,具体计算方式为:
[0087]
in=x
×
l
t
[0088]
k=x
×mt
[0089]
v=x
×nt
[0090]
其中,
[0091]
in=[in1,in2,
…
,inn]
t
[0092]
k=[k1,k2,
…
,kn]
t
[0093]
v=[v1,v2,
…
,vn]
t
[0094]
s3、计算注意力分布,具体计算公式为:
[0095][0096]
根据注意力分布对输入信息进行加权平均:
[0097][0098]
上式中,atti为的维度为234
×
1。
[0099]
前馈网络层包括bp神经网络,所述bp神经网络的个数为234个,所述bp神经网络包括前馈输入层和中间隐层和前馈输出层构成,其中前馈输入层含有234个神经元,中间隐层均含有48个神经元,前馈输出层含有16个神经元;前馈输入层的输入分别为att1、att2、...、att
n-1
和attn,分别将att1、att2、...、att
n-1
和attn输入到各自的bp神经网络中计算得到的前馈输出记为f1、f2、...、f
n-1
和fn,具体计算步骤为:
[0100]fi
=max(w1atti b1)w2 b
2 i∈(1,2,
…
,234)
[0101]
上式中,b1表示中间隐层的偏置,b2表示前馈输出层的偏置,w1为中间隐层的内星权向量,w2为前馈输出层的内星权向量,其中的b1、b2、w1和w2设为不可训练,fi为每个bp神经网络的输出,具体为f1、f2、...、f
n-1
和fn,其维度均为16
×
1。
[0102]
注意力损失计算层用于计算text_page的前馈输出与ad_page的前馈输出之间的差异,具体计算公式如下:
[0103][0104]
上式中,f
text
表示text_page的前馈输出,f
ad
表示ad_page的前馈输出。
[0105]
迭代更新层利用梯度下降算法对text_page进行迭代更新得到图像pic,由于图像数据编码层中的参数l、m、n、b1、b2、w1和w2均为固定值,只需对text_page进行更新即可,具体计算公式为:
[0106][0107]
上式中,x
text
表示text_page经过数据预处理层处理后得到的结果,λ为学习率,最后更新结果即为图像pic,其形式为:
[0108][0109]
融合输出层的数据由两部分构成,包括图像pic和将text_page经过数据预处理层得到的x
text
,所述融合输出层的计算步骤如下:
[0110]
c=μ*pic ξ*x
text
[0111]
展开为:
[0112][0113]
上式中,μ和ξ为加权系数,c表示最终嵌入了广告的杂志文本所对应的矩阵形式,按照数据预处理层的规则将其转录为图像即为最终结果。
[0114]
实施例一:
[0115]
s1、将杂志的文本页和杂志的广告页都转化为jpg格式或png格式,并将其全部压缩到同样的尺寸208
×
288
×
3,分别记为text_page和ad_page。
[0116]
s2、在数据预处理层对text_page和ad_page进行数据预处理操作:
[0117][0118][0119]
其中text_page经过数据预处理层得到的结果为x
text
,ad_page经过数据预处理层得到的结果为x
ad
。
[0120]
s4、将x
text
和x
ad
输入到自注意力层得到各自的抽象语义特征,即为:
[0121][0122]
上式子中,各个分量的维度均为16
×
1。
[0123]
s5、使用注意力损失计算层计算x
text
的前馈输出与x
ad
的前馈输出之间的差异,具体计算公式如下:
[0124][0125]
s6、使用迭代更新层对x
text
进行迭代更新得到图像pic,具体更新计算公式为:
[0126][0127]
上式中,λ为学习率,最后更新结果即为图像pic,其形式为:
[0128][0129]
s7、融合输出层的数据由两部分构成,包括图像pic和x
text
,所述融合输出层的计算步骤如下:
[0130]
c=μ*pic ξ*x
text
[0131]
上式中,μ和ξ为加权系数,c表示最终嵌入了广告的杂志文本所对应的矩阵形式,按照数据预处理层的规则将其转录为图像即为最终结果。
[0132]
以上便是本发明具体的工作流程,下次使用时重复此步骤即可。
[0133]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
[0134]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
[0135]
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。