1.本发明涉及社交媒体分析领域,尤其涉及一种社交媒体网络用语的语义变化自动检测与解释方法及系统。
背景技术:
2.随着tiktok、bilibili等在线社交媒体平台的兴起,用户在浏览视频的同时分享个人的观点和感受变得十分方便。在大量的视频评论中可以观察到一个很有趣的现象,即许多用户创造了诸多语义改变的网络用语用于表达他们独特的想法或者感情。显然,对于不理解这些亚文化的新用户而言,理解这些网络用语所表达的含义是非常困难的,从而带来糟糕的用户体验。因此,对于平台管理人员来说,提供一个自动检测这些语义变化的网络用语,并提供规范化语义解释的工具,具有十分重要的应用价值。
3.然而,对于智能系统而言,充分理解这些亚文化所传达的信息仍旧是十分有挑战性的任务。近年来,随着自然语言处理技术的迅速发展,已有部分技术初步实现了历史记录中词语语义变化的检测。然而,这些方法缺乏有效融合多模态信息的能力,因此无法捕获视频中的网络用语的相关信息,更没有考虑对于检测出的语义变化词语进行规范化语言解释的后续任务,这严重限制了这些技术的应用范围。更糟糕的是,这些网络用语在语义上可能因不同的视觉语境而产生微妙变化。因此,如果不能充分理解网络用语使用场景的视觉语境,而是仅仅通过构建通用词典,可能无法准确翻译网络用语的真实含义,甚至会导致用户对于含意微妙变化的误解。显然,需要一种更为有效且精准的、结合多模态语义信息的检测和解释方法。
技术实现要素:
4.本发明的目的是提供一种社交媒体网络用语的语义变化自动检测与解释方法及系统,可以准确检测网络用语并结合多模态信息生成相应的解释文本。
5.本发明的目的是通过以下技术方案实现的:
6.一种社交媒体网络用语的语义变化自动检测与解释方法,包括:
7.网络用语检测阶段:对于社交媒体评论语料库cu中的社交媒体评论文本,通过给定的通用语料库cg对应的单词向量表示集合获得社交媒体评论文本中所有单词的向量表示,构成第一文本向量序列,以及通过社交媒体评论语料库cu对应的单词向量表示集合,获得社交媒体评论文本中所有单词的向量表示,构成第二文本向量序列;对第一文本向量序列与第二文本向量序列中相同单词之间的向量表示的距离进行度量,从社交媒体评论文本中选出距离最大的k个单词作为网络用语;
8.网络用语解释阶段:通过基于transformer模型的编码器分别对社交媒体评论文本对应的视频帧图像的视觉表征、网络用语与社交媒体评论文本的文本表征、以及网络用语与社交媒体评论文本的语音表征进行编码,将编码获得的视频帧图像的图像特征、网络用语与社交媒体评论文本的文本表征,以及网络用语与社交媒体评论文本的语音特征,输
入至基于transformer模型的解码器,生成自然语言解释文本。
9.一种社交媒体网络用语的语义变化自动检测与解释系统,包括:
10.图像增强的网络用语检测模块,应用于网络用语检测阶段,所述网络用语检测阶段包括:对于社交媒体评论语料库cu中的社交媒体评论文本,通过给定的通用语料库cg对应的单词向量表示集合获得社交媒体评论文本中所有单词的向量表示,构成第一文本向量序列,以及通过社交媒体评论语料库cu对应的单词向量表示集合,获得社交媒体评论文本中所有单词的向量表示,构成第二文本向量序列;对第一文本向量序列与第二文本向量序列中相同单词之间的向量表示的距离进行度量,从社交媒体评论文本中选出距离最大的k个单词作为网络用语;
11.网络用语解释任务模块,应用于网络用语解释阶段,所述网络用语解释阶段包括:通过基于transformer模型的编码器分别对社交媒体评论文本对应的视频帧图像的视觉表征、网络用语与社交媒体评论文本的文本表征、以及网络用语与社交媒体评论文本的语音表征进行编码,将编码获得的视频帧图像的图像特征、网络用语与社交媒体评论文本的文本表征,以及网络用语与社交媒体评论文本的语音特征,输入至基于transformer模型的解码器,生成自然语言解释文本。
12.一种处理设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;
13.其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述的方法。
14.一种可读存储介质,存储有计算机程序,当计算机程序被处理器执行时实现前述的方法。
15.由上述本发明提供的技术方案可以看出,通过两阶段的方案自动检测和理解社交媒体评论中的网络用语语义变化现象,第一个阶段中,通过单词在不同语料库中对应的向量表示的距离,可以以找到语义上发生变化的词语(即网络用语);第二个阶段,利用多模态信息可以生成网络用语的解释文本,从而准确翻译网络用语的真实含义。
附图说明
16.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
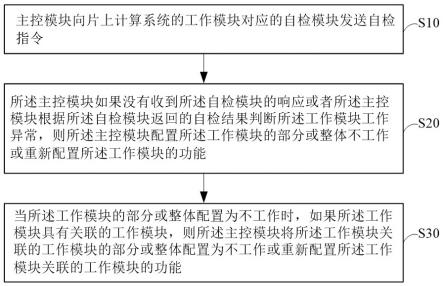
17.图1为本发明实施例提供的一种社交媒体网络用语的语义变化自动检测与解释方法的流程图;
18.图2为本发明实施例提供的一种社交媒体网络用语的语义变化自动检测与解释方法的整体框架图;
19.图3为本发明实施例提供的一种社交媒体网络用语的语义变化自动检测与解释系统的示意图;
20.图4为本发明实施例提供的处理设备的示意图。
具体实施方式
21.下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
22.首先对本文中可能使用的术语进行如下说明:
23.术语“包括”、“包含”、“含有”、“具有”或其它类似语义的描述,应被解释为非排它性的包括。例如:包括某技术特征要素(如原料、组分、成分、载体、剂型、材料、尺寸、零件、部件、机构、装置、步骤、工序、方法、反应条件、加工条件、参数、算法、信号、数据、产品或制品等),应被解释为不仅包括明确列出的某技术特征要素,还可以包括未明确列出的本领域公知的其它技术特征要素。
24.下面对本发明所提供的一种社交媒体网络用语的语义变化自动检测与解释方法及系统进行详细描述。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本发明实施例中未注明具体条件者,按照本领域常规条件或制造商建议的条件进行。
25.实施例一
26.本发明实施例提供一种社交媒体网络用语的语义变化自动检测与解释方法,如图1所示,主要包括如下两个阶段:
27.一、网络用语检测阶段。
28.本阶段中,对于社交媒体评论语料库cu中的社交媒体评论文本(即待检测的文本),通过给定的通用语料库cg对应的单词向量表示集合获得社交媒体评论文本中所有单词的向量表示,构成第一文本向量序列,以及通过社交媒体评论语料库cu对应的单词向量表示集合,获得社交媒体评论文本中所有单词的向量表示,构成第二文本向量序列;对第一文本向量序列与第二文本向量序列中相同单词之间的向量表示的距离进行度量,从社交媒体评论中选出距离最大的k个单词作为网络用语。
29.本发明实施例中,所述单词向量表示集合包含多个单词的向量表示,每一单词的向量表示均通过针对文本的预训练模型提取,对于单词w
′
,其向量表示为v,提取方式表示为:
30.v=wgw
31.其中,wg表示针对文本的预训练模型的参数,w表示单词w
′
的独热向量。
32.将通用语料库cg对应的单词向量表示集合记为其中,表示通用语料库cg中第l个单词的表示向量,l=1,2,
…
;将社交媒体评论语料库cu对应的单词向量表示集合记为其中,表示社交媒体评论语料库cu中第t个单词的表示向量,t=1,2,
…
。
33.本发明实施例中,将第一文本向量序列记为将第二本文向量序列记为其中,n为社交媒体评论文本中单词的数目,i为社交媒体评论文本中单词的序号,表示通过给定的通用语料库cg对应的单词向量表示集合获得的第i个单词的向量表示,
表示通过社交媒体评论语料库cu对应的单词向量表示集合获得的第i个单词的向量表示;如果第i个单词未出现在给定的通用语料库cg中,则对应的向量表示为组成第i个单词的所有字符的表征向量的平均值。
34.本领域技术人员可以理解,针对文本的预训练模型(例如,glove)得到中文单词表征时,还会得到单个字(字符)的表征。例如,得到“你好”这个单词的表征时,也会单独得到“你”和“好”这两个字的表征。通常情况下,如果能确定是一个单词,且含有相应单词的表征,则可以直接使用,否则,使用所有字表征的平均。
35.通过距离函数对第一文本向量序列与第二文本向量序列中相同序号i的向量表示与之间的距离进行度量。
36.本发明实施例中,网络用语检测阶段通过图像增强的网络用语检测模块实现,所述图像增强的网络用语检测模块包括:针对文本的预训练模型、针对图像的预训练模型、编码器、解码器以及提取器;其中:
37.所述针对文本的预训练模型,用于提取给定的通用语料库cg、以及社交媒体评论语料库cu对应的单词向量表示集合;
38.所述提取器,用于结合社交媒体评论文本获得第一文本向量序列与第二文本向量序列,对第一文本向量序列与第二文本向量序列中相同单词之间的向量表示的距离进行度量,从社交媒体评论文本中选出距离最大的k个单词作为网络用语;
39.针对图像的预训练模型、编码器与解码器仅应用于训练阶段,训练阶段,编码器的输入为第二文本向量序列,输出为句子层面的向量表示,解码器基于句子层面的向量表示生成重构文本,利用重构文本与社交媒体评论文本的差异计算重构损失针对图像的预训练模型的输入为社交媒体评论文本对应的视频帧图像,输出为整体的视觉表征;通过正交矩阵g将句子层面的向量表示从句子语义空间转换至视觉空间后通过距离函数计算与整体的视觉表征的距离损失结合重构损失距离损失以及正交矩阵g的约束项构建第一训练损失,通过第一训练损失训练图像增强的网络用语检测模块中的针对文本的预训练模型、编码器与解码器;
40.测试阶段移除针对图像的预训练模型、编码器与解码器,通过针对文本的预训练模型与提取器检测网络用语,通常情况下,训练阶段与测试阶段输入的社交媒体评论文本均来自社交媒体评论语料库cu。
41.二、网络用语解释阶段。
42.本阶段中,通过基于transformer模型的编码器分别对社交媒体评论文本对应的视频帧图像的视觉表征、网络用语与社交媒体评论文本的文本表征、以及网络用语与社交媒体评论文本的语音表征进行编码,将编码获得的视频帧图像的图像特征、网络用语与社交媒体评论文本的文本表征,以及网络用语与社交媒体评论文本的语音特征,输入至基于transformer模型的解码器,生成自然语言解释文本。
43.本发明实施例中,所述网络用语解释阶段用过网络用语解释任务模块实现,其包括:基于transformer模型的编码器与基于transformer模型的解码器;训练阶段,根据基于transformer模型的解码器生成自然语言解释文本与数据集中的解释文本,计算交叉熵损
失以及通过平均池化层处理文本特征获得宏观文本表示,基于宏观文本表示与整体的视觉表征的距离差异计算对齐损失结合交叉熵损失与对齐损失构建第二训练损失,通过所述第二损失函数训练网络用语解释任务模块;其中,所述整体的视觉表征属于视频帧图像的视觉表征的一部分(具体在后文进行介绍)。
44.本发明实施例中,基于transformer模型的编码器包含三个编码单元,分别处理视觉模态、文本模态、语音模态的信息。
45.对于视觉模态,即社交媒体评论文本对应的视频帧图像,使用针对图像的预训练模型,获得整体的视觉表征以及一系列的局部的视觉表征,构成视频帧图像的视觉表征,并输入至基于transformer模型的编码器中的第一编码单元,获得视觉特征。
46.对于文本模态,将网络用语与社交媒体评论文本连接起来,并在连接部分设置分隔符,获得文本序列;使用所述针对文本的预训练模型,获得文本序列中每一单词的向量表示,构成网络用语与社交媒体评论文本的文本表征,并输入至基于transformer模型的编码器中的第二编码单元,获得文本特征。
47.对于语音模态将每个单词翻译为对应的音标,将网络用语中单词的音标与社交媒体评论文本中单词的音标连接起来,并在连接部分设置分隔符,获得音标序列;利用可变线性层获得音标序列中每一音标的特征表示,构成网络用语与社交媒体评论文本的语音表征,并输入至基于transformer模型的编码器中的第三编码单元,获得语音特征。
48.本发明实施例中,通过设置分隔符可以让网络用语解释任务模块在训练的时候学会它是一个特殊符号,用来分开网络用语和它所在的社交媒体评论文本。
49.基于transformer模型的编码器输出图像特征、文本特征与语音特征后,将三类特征进行连接,并使用注意力机制进行融合,再通过基于transformer模型的解码器使用自回归的方式生成每一时刻的单词,按照时刻顺序将单词组合为自然语言解释文本。
50.为了更加清晰地展现出本发明所提供的技术方案及所产生的技术效果,下面以具体实施例对本发明实施例所提供的一种社交媒体网络用语的语义变化自动检测与解释方法进行详细描述。
51.一、问题定义。
52.给定一个通用语料库cg,以及一个用户生成的社交媒体评论语料库cu。当一个单词w
′
满足如下两个条件时,定义单词w
′
为网络用语:
53.条件一:单词w
′
或其变体同时存在于cg和cu中,即w
′
∈cg∩cu中,也就是说,只有当词语同时存在于通用语料库和社交媒体评论语料库中才满足条件一,一般而言都会满足条件一。
54.条件二:cu中的单词w
′
的含义应该不同于这个字词或词组在cg中的变体,即,给定距离函数dis(.),与原先含义向量表示相比变化较大,即dis(vg,vu)较大,其中vg和vu是w
′
在cg和cu中的对应向量表示。
55.考虑到通用语料是指日常使用的语料,事实上任何情况下都无法覆盖全部可能的词语,例如可能用于训练通用语料表征的数据里刚好没有“清华大学”这个词语,但是这个词语很明显存在于日常使用中,因此在通常处理中会使用字符的平均值来表示这些可能恰好没有涉及到的词语。同样基于上述原因,因为通用语料过于庞大,无法完全覆盖,因此本发明默认所有词语都在通用语料中均存在。而对于社交媒体评论语料,由于进行检测的时
候,检测的语句均来自于社交媒体,也默认这些词语均属于社交媒体评论语料。基于上述理由,在发明中所获得的句子默认满足条件一。
56.本领域技术人员可以理解,变体是指直观上两个不同词语代表同一个意思,其中一个为标准词语,另一个则为标准词语的变体。例如,哥哥与老哥代表同一个意思,哥哥为标准词语,老哥为哥哥的一种变体。
57.二、语义变化自动检测与解释框架。
58.如图2所示,展示了语义变化自动检测与解释框架,其中,上方虚线框部分即前文所述的图像增强的网络用语检测模块,用于语义变化自动检测;下方虚线框部分即前文所述的网络用语解释任务模块,用于生成网络用语的解释文本。需要说明的是,图2左上部分所呈现的文本内容以及视频帧图像的内容仅为示意。下面针对上下两部分做详细的介绍。
59.1、图像增强的网络用语检测模块。
60.本发明实施例中,图像增强的网络用语检测模块是一个无监督的模块,通过迭代重建文本序列来学习在社交媒体评论语句中每个词语的真实含义。然后,通过缩小句子表征与图像表征之间的距离,来提取并整合视觉信息。通过这种方式,训练良好的检测器将获得真实语境下的词语表征,并将训练获得的词语特征表征与相应的通用语料库中训练得到的词语表征进行比较,以找到语义上发生变化的词语(即网络用语)。下面针对该模块的训练方式进行介绍。
61.首先,需要对单词进行初始化表示。对于通用语料库cg中的单词,针对文本的预训练模型来获得每一单词的向量表示;示例性的,针对文本的预训练模型可以使用预先训练过的中文glove模型。同时,来自社交媒体评论语料库cu的单词也用相同的特征形式初始化,即输入至针对文本的预训练模型,获得每一单词的向量表示。更加形式化地,从社交媒体评论语料库中给出一个句子(即社交媒体评论文本)将每个单词表示为基于预先训练的通用向量,所有这些向量都是可训练的:
[0062][0063]
其中,w
glove
是线性层的可训练参数,由glove模型进行初始化后得到,为单词的独热(one-hot)向量。如果单词没有出现在通用语料库中,则被设置为组成第i个单词的所有字符的表征向量的平均值词语组成字符的表征向量的平均值。
[0064]
本发明实施例中,对于通用语料库cg以及社交媒体评论语料库cu分别使用不同的针对文本的预训练模型,通过训练可以得到一个通用语料库wg对应的针对文本的预训练模型,以及社交媒体评论语料库cu对应的针对文本的预训练模型;两个针对文本的预训练模型的工作原理、训练方式是相同的,下面以社交媒体评论语料库cu为例,介绍针对文本的预训练模型的训练过程。
[0065]
在单词编码过程之后,引入了句子的表征。由于句子的表征是一种典型的序列类型数据,选择基于编码器-解码器结构构造数据的特征向量。编码器读取文本向量序列,并将其转换为句子隐藏层状态hs作为句向量(句子层面的向量表示)。然后,解码器基于该语义向量重构原始句子。计算流程可以表示为:
[0066][0067]ai
=decoder(w1,w2,
…
,w
i-1
,hs)
[0068][0069]
其中,decoder表示编码器,表示句子中所有单词的向量表示;decoder表示解码器,w1,w2,
…
,w
i-1
表示第1个,第2个,第i-1个重构得到的单词,zi是解码器输出的第i个单词解码时得到的中间特征,f(.)是激活函数,w
out
和b
out
是输出层的参数,表示输出层预测的第i个单词为词表中各个单词的概率。
[0070]
之后,进行重建损失的计算。重建损失是每一步正确单词的负对数似然的总和,如下所示:
[0071][0072]
在获得句子的语义向量后,可以通过重构文本的过程来学习每个词语的真实表征。然而,仅仅利用句子进行重建来学习表征就忽略了一个重要的假设,即出现在同一视频帧中的句子通常包含相似的主题。为了解决这个局限性,本发明提出了另一个损失,衡量句子语义和视频帧语义之间的距离。值得注意的是,重建损失和距离损失在某种程度上是对立的。因为随着重建损失的减少,句子的语义向量变得更加多样,这可能会阻碍距离损失的减少。具体来说,在获得句子的语义向量后,视觉信息将通过针对图像的预训练模型(例如,预训练的vision transformer模型)和池化层的处理变为图像的语义表示,称为整体的视觉表征此处固定了视觉向量,以获得不变的图像语义空间,即针对图像的预训练模型的参数不更新。然后,使用正交矩阵g作为从句子语义空间到图像的有效转换。最终的距离损失公式如下:
[0073][0074]
示例性的,距离函数dist(.)可以选择欧几里德距离。
[0075]
最后,第一训练损失如下所示:
[0076][0077]
其中,α1与β1均为超参数,t为矩阵转置符号,第三项β1‖g
t
g-i‖f用于约束正交矩阵g。由于存在对抗关系,通过调整超参数α1,可以控制它们的聚合程度,这是影响最终性能的关键因素。
[0078]
经过几个时期的训练(例如,2个时期)后,使得图像信息可以融入网络用语检测模块。类似的,通用语料库cg对应的针对文本的预训练模型也采用以上方式训练,最终通过训练后的两个针对文本的预训练模型,分别得到对应语料库中每个单词的向量表示集合。之后,可以通过对社交媒体评论文本中每个单词对应的向量表示和向量表示之间的距离进行排序来检测语义变化的单词,最终将会选取距离最大的k个词语将被视为网络用语。
[0079]
本发明实施例中,训练针对文本的预训练模型可以理解为,更新各个单词的向量表示,各单词向量表示即为针对文本的预训练模型的参数。相同单词对应的两个向量表示的差异较大,则认定为网络用语。
[0080]
2、网络用语解释任务模块。
[0081]
本发明实施例中,网络用语解释任务模块为语音增强的transformer解释模型
(prote)。在这一部分,prote将会获取检测模块过滤得到的网络用语作为输入,并获取原始对应视频帧以及社交媒体评论文本作为输入。首先介绍网络用语对应语境下的多模态语境信息的表示,它由三部分组成,即对应的图像或视频帧、包含该网络用语的实时评论和该实时评论对应的发音。
[0082]
对于视频帧图像,同样使用了针对图像的预训练模型,主要用来提取整体的视觉表征以及一系列的局部的视觉表征,记为其中,为整体的视觉表征,为一系列的局部的视觉表征,m是图像块的数量,每一图像块对应一个局部的视觉表征,之后输入至基于transformer模型的编码器。
[0083]
如图2所示,基于transformer模型的编码器包含三个编码单元,分别用于处理视觉模态、文本模态、语音模态的信息;三个编码单元的结构相同,均包含依次连接的自注意力模块与前向传播网络。具体的,视觉表征先通过线性变换和平均池化层进行调整,再输入至第一编码单元。
[0084]
对于视频帧图像的整体处理流程表示为:
[0085][0086][0087][0088]
ffn1(x)=max(0,xw1 b1)w2 b2[0089]
其中,i表示视频帧图像,vit表示针对图像的预训练模型,此处以vision transformer(vit)模型为例。avgpool表示平均池化层的操作,wi和bi是线性变换层的可训练参数,表示通过线性变换和平均池化层调整后得到的视觉表征,self attn1表示第一编码单元中的自注意力模块,ffn1表示第一编码单元中的前向传播网络,式子ffn1(x)展示了前向传播网络的处理过程,x为自注意力模块self attn1的输出;是视觉特征,第一项是视频帧图像的宏观特征,其余每一项代表一个图像块的局部特征。
[0090]
对于文本模态,先将网络用语和社交媒体评论文本连接起来,并使用一个特殊的符号(例如,符号[sep])作为分隔符。每个单词通过一个可训练的线性层被编码成一个向量在初始编码之后,特征第二编码单元映射到隐藏状态h
t
。计算流程如下:
[0091][0092][0093]
其中,wr为连接后的文本序列中第r个单词的独特向量,r为文本序列单词总数(即网络用语和社交媒体评论文本的单词总数),为字表征矩阵;self attn2表示第二编码单元中的自注意力模块,ffn2表示第二编码单元中的前向传播网络,隐藏状态h
t
即为文本特征。
[0094]
对于语音模态,通过分析社交媒体评论,可以发现同音词或谐音词在用户创建的内容中占很大比例。为了利用网络用语中常见的同音词,本发明引入了发音作为一种附加
模态来增强模型的能力。具体而言,在本发明中,将网络用语以及社交媒体评论文本中的每个单词翻译成对应的音标,然后,类似于文本模态中应用的过程,将网络用语和社交媒体评论文本的音标连接起来,构成语音表征,表示为p=(p1,p2,...pr),pr是第r个单词的音标;之后,通过可变线性层将它们转换为特征表示最后,它们中的每一个特征表示都将被转换为隐藏表示h
p
。需要说明的是,文本和语音符号在被自注意力模块处理之前都添加了位置编码。计算流程如下:
[0095][0096][0097]
其中,为发音表征矩阵;selfattn3表示第三编码单元中的自注意力模块,ffn3表示第三编码单元中的前向传播网络,隐藏表示h
p
即为语音特征。
[0098]
需要说明的是,为了便于表示,在上述文本表征与语音表征p=(p1,p2,...pr)中省去了分隔符;此外,在语言处理中,不同文字在不一样的位置会有不一样的含义,但是自注意力模块不会考虑文本的位置,因此,文本和语音表征在被对应自注意力模块处理之前都添加了位置编码们可以给自注意力模块提供位置信息。此处使用的位置编码和基于transformer结构的模型的通常使用的位置编码方式一致。
[0099]
通过前述处理,获得三个编码单元输出三部分特征,三部分特征连接起来,并通过一个transformer模块(图2底部的transformer的组成部分)来应用自注意力机制来融合它们的表征和信息。最后,利用基于transformer的解码器(图2底部的transformer的组成部分)来生成自然语言解释文本。
[0100][0101]
p(e
t
)=softmax(y
twproj
)
[0102]
其中,e
proj
是线性映射矩阵,transformer表示transformer模块,y
t
表示第t个单词的中间特征表示,与表示模型生成的第1个与第t-1个单词,p(e
t
)表示生成第t个单词为e
t
的概率,选择概率最高的作为模型生成的第t个单词
[0103]
训练阶段,基于transformer的解码器的输出,使用交叉熵损失函数来指导语言生成。从形式上讲,它可以描述如下:
[0104][0105]
其中,k是数据集中的解释数,nk是第k个解释文本中的字数。
[0106]
然而,由于网络用语和相对应的图像之间存在巨大的语义鸿沟,模型很难捕捉到有用的区域信息或全局信息,因为评论通常只集中在一个或两个区域。为了解决这一局限性并进一步探索视觉信息,构建了一个文本图像的宏观对齐损失函数,以增强模型跨越网络用语文本和图像之间的语义鸿沟的能力。具体来说,使用一个平均池化层来处理文本特征h
t
,并获得宏观文本表示h
t
。测量宏观文本表示和图像的整体表示之间的距离,作为对
齐损失
[0107][0108]
通过这种监督,模型可以深入理解视觉信息,并通过文本的引导选择正确的信息。最后,第二训练损失,其定义如下:
[0109][0110]
其中,α2是一个超参数,用于平衡两个损失。
[0111]
训练完毕后,按照前文介绍的方式,通过基于transformer的解码器来生成自然语言解释文本。
[0112]
实施例二
[0113]
本发明还提供一种社交媒体网络用语的语义变化自动检测与解释系统,其主要基于前述实施例提供的方法实现,如图3所示,该系统主要包括:
[0114]
图像增强的网络用语检测模块,应用于网络用语检测阶段,所述网络用语检测阶段包括:对于社交媒体评论语料库cu中的社交媒体评论文本,通过给定的通用语料库cg对应的单词向量表示集合获得社交媒体评论文本中所有单词的向量表示,构成第一文本向量序列,以及通过社交媒体评论语料库cu对应的单词向量表示集合,获得社交媒体评论文本中所有单词的向量表示,构成第二文本向量序列;对第一文本向量序列与第二文本向量序列中相同单词之间的向量表示的距离进行度量,从社交媒体评论文本中选出距离最大的k个单词作为网络用语;
[0115]
网络用语解释任务模块,应用于网络用语解释阶段,所述网络用语解释阶段包括:通过基于transformer模型的编码器分别对社交媒体评论文本对应的视频帧图像的视觉表征、网络用语与社交媒体评论文本的文本表征、以及网络用语与社交媒体评论文本的语音表征进行编码,将编码获得的视频帧图像的图像特征、网络用语与社交媒体评论文本的文本表征,以及网络用语与社交媒体评论文本的语音特征,输入至基于transformer模型的解码器,生成自然语言解释文本。
[0116]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
[0117]
实施例三
[0118]
本发明还提供一种处理设备,如图4所示,其主要包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述实施例提供的方法。
[0119]
进一步的,所述处理设备还包括至少一个输入设备与至少一个输出设备;在所述处理设备中,处理器、存储器、输入设备、输出设备之间通过总线连接。
[0120]
本发明实施例中,所述存储器、输入设备与输出设备的具体类型不做限定;例如:
[0121]
输入设备可以为触摸屏、图像采集设备、物理按键或者鼠标等;
[0122]
输出设备可以为显示终端;
[0123]
存储器可以为随机存取存储器(random access memory,ram),也可为非不稳定的
存储器(non-volatile memory),例如磁盘存储器。
[0124]
实施例四
[0125]
本发明还提供一种可读存储介质,存储有计算机程序,当计算机程序被处理器执行时实现前述实施例提供的方法。
[0126]
本发明实施例中可读存储介质作为计算机可读存储介质,可以设置于前述处理设备中,例如,作为处理设备中的存储器。此外,所述可读存储介质也可以是u盘、移动硬盘、只读存储器(read-only memory,rom)、磁碟或者光盘等各种可以存储程序代码的介质。
[0127]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。