1.本发明属于计算机视觉技术,特别涉及一种基于视觉特征约束的细粒度图像分类方法。
背景技术:
2.自然语言处理中使用大量的未处理数据作为训练数据得到的预训练模型,可以适用于不同的下游任务。但是计算机视觉中大量的预训练模型只能适用于部分与训练数据集分布类似的数据集,无法和自然语言处理模型一样适用于多类型的下游任务。因此,研究人员提出clip(contrastive language-image pre-training)方法。该方法充分地利用互联网上可以轻易爬取搜集得到的大量成对的文本和图像数据,将文本作为图像的标签训练一个具有较强泛化能力,便于迁移到其他下游任务的模型。
3.clip方法的主要过程如下:首先通过50万条查询文本在搜索引擎中得到4亿张图片,然后通过视觉特征编码器和文本特征编码器分别提取图片和文本的特征,最后利用度量学习的方法训练配对的视觉特征编码器和文本特征编码器。clip方法最后可以获得能提取图片特征的视觉特征编码器和提取文本特征的文本特征编码器,并且两个编码器提取的特征在同一个特征空间中,可以通过对比得到相似度。当前有很多的下游任务采用clip方法,通过预训练的编码器的帮助提升性能,但还没有将clip方法应用在细粒度图片分类领域。细粒度图片分类数据集中对于每张图片都会有对应的文本描述,正好可以结合clip方法中训练得到的文本特征编码器提取文本特征帮助细粒度图片分类。通过对模型提取的视觉特征进行约束从而提高细粒度模型的准确率。
技术实现要素:
4.(一)要解决的技术问题
5.解决当前有很多的下游任务采用clip方法,通过预训练的编码器的帮助提升性能,但还没有将clip方法应用在细粒度图片分类领域的问题,提供了一种基于视觉特征约束的细粒度图像分类方法。
6.(二)技术方案
7.本发明的目的在于利用clip方法中得到的视觉特征编码器和文本编码器帮助细粒度图像分类模型提升性能,提供一种基于视觉特征约束的细粒度图像分类方法,具体包括以下步骤:
8.步骤一:训练数据集的采集;
9.步骤二:对训练图片进行数据预处理和数据增广;
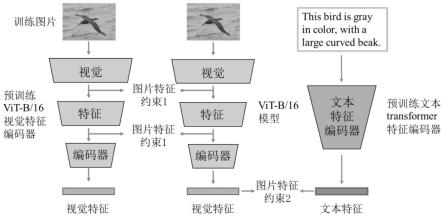
10.步骤三:采用clip方法中的vit-b/16模型作为基础模型提取训练图片的视觉特征;
11.步骤四:利用clip方法中在大型数据集上预训练得到的vit-b/16视觉特征编码器提取步骤三中训练图片的视觉特征,每一层编码器输出提取图片得到的中间特征;将这些
中间特征作为标准对步骤三中的vit-b/16模型的中间特征进行约束,得到图片特征约束1;
12.步骤五:每张训练图片都有对应的描述性文本数据,利用clip方法中在大型数据集上预训练得到的transformer文本特征编码器提取步骤三中训练图片所对应的描述性文本数据得到文本特征;将这些文本特征作为标准对步骤三中模型得到的图片视觉特征向量进行约束,得到图片特征约束2;
13.步骤六:利用clip方法中在大型数据集上预训练得到的vit-b/16视觉特征编码器获取训练图片的激活图(activation map),将激活图作为掩码对训练图片进行掩码处理;
14.步骤七:用步骤三的模型提取步骤六中掩码处理后的图片的视觉特征,得到掩码图片视觉特征;
15.步骤八:将步骤三和步骤七得到的普通视觉特征和掩码图片视觉特征进行组合后得到的图片特征作为训练图片的最终图片视觉特征;将最终图片视觉特征经过多层感知机后得到每一类的置信度,通过交叉熵损失函数进行分类损失的计算;
16.步骤九:将步骤四、步骤五和步骤八中的图片特征约束1、图片特征约束2和分类损失相加后得到任务的总损失;通过总损失训练步骤三中的vit-b/16模型;
17.步骤十:测试阶段,将测试图片复制4份,将四份分别旋转一定的角度,再使用步骤九中训练完成的vit-b/16模型对这四份测试图片分别进行预测,然后平均四份的输出结果,最终平均得分最高的类别就是测试图片的预测类别。
18.作为优选的技术方案,步骤一中,采用的数据集是caltech-ucsd birds-200-2011鸟类细分类数据集,该数据集包含200类鸟类的图片数据,共11788张图片,并且每张图片都有对应的一段描述性文本数据;取该数据集中的5994张图片作为训练数据集。
19.作为优选的技术方案,步骤二中,将图片缩放至统一的尺寸224
×
224的大小,然后利用随机剪裁、随机翻转、随机高斯模糊等数据增广方式提升训练图片的数量。
20.作为优选的技术方案,步骤三中的vit-b/16模型的输入为将图片切成16
×
16大小的块,输出为图片的768维的视觉特征向量,最后经过一个多层感知机得到图的类别得分。
21.作为优选的技术方案,步骤四中,vit-b/16模型共有12层,取预训练vit-b/16模型的最后4、3、2层输出的中间特征作为图片特征约束1的约束特征;图片特征约束1的计算公式如下:
22.l1=σ||f
1-f2||2,
23.其中f1是步骤四中预训练模型提取的中间特征,f2是步骤三中模型的对应的中间特征。
24.作为优选的技术方案,步骤五中,transformer文本特征编码器提取得到的文本特征维度为768维;利用这个文本特征对步骤三中模型提取得到的图片视觉特征进行图片特征约束2;图片特征约束2的计算公式如下:
25.l2=||f
t-fi||2,
26.其中f
t
是步骤五中文本transformer特征编码器提取得到的文本特征,fi是步骤三中的模型提取的图片视觉特征。
27.作为优选的技术方案,步骤六中使用的预训练视觉特征编码器得到训练图片的激活图;利用激活图对训练图片进行掩码处理;具体而言,保留激活图数值大于0.5的训练图片相对位置上的像素点,将激活图数值小于0.5的训练图片相对位置上的像素点设置为零。
28.作为优选的技术方案,步骤八中使用的将步骤三和步骤七得到的普通视觉特征和掩码图片视觉特征进行组合,组合特征的计算公式如下:
29.f=αfi (1-α)fm,
30.其中fi是步骤三中的模型提取的最后一层的图片视觉特征,fm是步骤七中提取得到的掩码图片视觉特征,α是一个调节两个特征重要性的参数。
31.作为优选的技术方案,步骤十中的旋转角度分别是0
°
、90
°
、180
°
和270
°
。
32.(三)有益效果
33.本发明的有益效果是:本方法通过利用clip方法在大量文本图片配对数据下得到的预训练图片视觉特征编码器和文本特征编码器约束模型的视觉特征的方式帮助细粒度图像分类模型提升性能。具体而言,将预训练视觉特征编码器不同层的中间特征作为视觉特征约束1帮助细粒度图像分类提取视觉特征;将文本特征编码器提取得到的文本特征作为视觉特征约束2帮助细粒度图像分类更好地学习到图像中的文本对应的细节部分;利用预训练视觉特征编码器得到的激活图,对训练图片进行掩码处理后,提取掩码图片的视觉特征与普通的视觉特征组合后,再进行图片的分类。使用激活图对图片进行掩码可以更好地提取模型关注的特征区域,减少背景等区域对特征提取的影响。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
35.图1是整体的模型结构;
36.图2是掩码图片特征获取过程;
37.图3是测试阶段过程。
具体实施方式
38.下面结合附图和具体实施例对本发明作进一步详细说明。
39.如图1所示,本发明采用的技术方案的主要步骤如下:
40.步骤一:采用caltech-ucsd birds-200-2011鸟类细分类数据集作为训练数据集,其中有200类鸟类,共5994张训练图片。
41.步骤二:对步骤一中的训练图片缩放至统一的224
×
224的大小,采用随机剪裁、随机翻转、随机高斯模糊等数据增广方式增加训练图片数量。
42.步骤三:采用与clip方法中的vit-b/16模型输入将图片划分为16
×
16的块,输出768维的图片视觉特征,提取视觉特征后通过多层感知机得到的每类的分类得分。
43.步骤四:利用clip方法中在大型数据集上预训练得到的vit-b/16视觉特征编码器提取步骤三中训练图片的视觉特征,每一层编码器输出提取得到的中间特征。将这些中间特征作为标准对步骤三中的vit-b/16模型的中间特征进行约束,即图1中图片特征约束1。
44.步骤五:每张训练图片都有对应的描述性文本数据,利用clip方法中在大型数据集上预训练得到的transformer文本特征编码器提取步骤三中训练图片所对应的描述性文
本数据得到文本特征。将这些文本特征作为标准对步骤三中的提取得到的最终的视觉特征向量进行约束,即图1中图片特征约束2。
45.步骤六:利用clip方法中在大型数据集上预训练得到的vit-b/16视觉特征编码器获取训练图片的激活图(activation map),将激活图作为掩码对训练图片进行掩码处理,如图2中所示。
46.步骤七:用步骤三的模型提取步骤六中掩码处理后的图片的视觉特征,得到图2的掩码图片特征。
47.步骤八:将步骤三和步骤六得到的普通视觉特征和掩码图片视觉特征进行组合后得到的图片特征作为训练图片的最终图片视觉特征。通过α调节两个特征的重要性,经测试,我当α等于0.5时效果最佳。将最终的图片视觉特征通过多层感知机后得到每一类的置信度,然后通过交叉熵损计算分类的损失。
48.步骤九:将步骤四、步骤五和步骤八中的图片特征约束1、图片特征约束2和分类损失相加后,得到总损失。通过总损失训练步骤三中的vit-b/16模型。
49.步骤十:测试阶段,如图3所示,将测试图片复制4份,将四份分别旋转一定的角度,再使用步骤九中训练完成的vit-b/16模型对这四份测试图片分别进行预测,然后平均四份的输出结果,最后平均得分最高的类别就是测试图片的预测类别。
50.需要说明的是:本发明利用clip方法在大型文本图片数据集下得到的预训练视觉特征编码器和文本特征编码器提取训练图片的视觉特征和配对文本的文本特征帮助细粒度图像分类模型更好地识别细粒度类别。具体而言,首先将预训练视觉特征编码器提取图片得到的中间特征作为视觉约束1约束细粒度分类模型提取的中间特征。其次,将预训练的文本特征编码器提取得到的文本特征监督作为视觉特征约束2约束细粒度分类模型提取的最后的图片特征。最后用预训练的视觉特征编码器获取训练图片的激活图,将其作为掩码对训练图片进行掩码处理后再获取掩码图片的视觉特征,和普通的视觉特征组合后再进行分类。
51.上面的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的构思和范围进行限定,在不脱离本发明设计构思的前提下,本领域普通人员对本发明的技术方案做出的各种变型和改进,均应落入到本发明的保护范围,本发明请求保护的技术内容,已经全部记载在权利要求书中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
