1.本发明属于车牌检测技术领域,涉及一种复杂场景车牌检测方法,尤其涉及一种基于语义特征引导的多尺度关系建模的复杂场景车牌检测方法。
背景技术:
2.随着社会的快速发展,在各行各业,机器以及代替人类从事各项活动,尤其是人工智能的出现,为机器提供了智能化的基础,尤其是智能交通领域的车牌检测,已经基本上代替人类,然而,在复杂场景下的车牌检测方面仍然存在精度不高的问题。
3.传统的车牌检测方法往往基于手工设计特征采集的方式对车牌检测,因为提取特征的能力有限,其精度没有较大提升。随着车牌检测大规模数据集的提出,基于数据驱动的深度学习方式逐渐成为主流,尤其是基于深度学习的物体检测领域,如,faster rcnn,yolo等。虽然一些方法尝试将物体检测的算法迁入到车牌检测领域来提升车牌检测精度,取得了非常好的效果,但是,其算法并不是针对车牌检测问题设计,尤其是在困难场景下的车牌检测往往效果差强人意。
4.由于车牌拍摄条件的复杂性,导致拍摄的车牌图片并不是理想,现有基于深度学习的方式通过融合不同尺度的特征达到检测不同大小车牌的目的,然而,其融合的方式并不能充分发挥车牌检测尺度的优势,尤其是针对复杂场景下的车牌检测,如车牌倾斜、低对比度、雨雪天气等,导致检测精度低。现有方法针对这种困难场景下的车牌检测方法,往往通过在网络中嵌入针对特定问题的处理模块,从而提升车牌检测的精度,针对车牌形变问题引入变形卷积,针对低对比度问题引入图像增强算法,这种方式仅仅在一种困难场景下起作用,在新的困难场景下,仍然存在精度低的问题。
5.由此可见,针对不同场景下的车牌检测技术,亟需一种新的车牌检测方法,提升不同场景下车牌检测的精度。
技术实现要素:
6.本发明的目的在于克服现有技术存在的缺点,设计提出一种复杂场景车牌检测方法,解决传统车牌检测方法对于多尺度特征蕴含的深层信息挖掘不充分、问题域大的问题,提高复杂场景下车牌检测的鲁棒性。
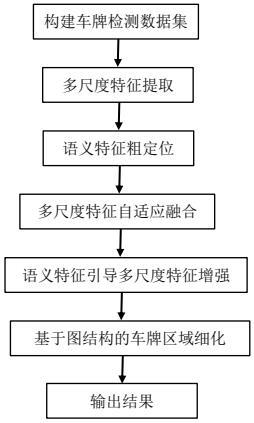
7.为实现上述目的,本发明具体包括如下步骤:(1)构建车牌检测数据集采用复杂场景下的车牌图像构建车牌检测数据集,并对车牌图像进行标注,将车牌检测数据集划分为训练集、验证集和测试集;(2)多尺度特征提取将车牌图像依次经过归一化和去均值预处理后输入到深度学习backbone网络,将深度学习backbone网络不同层的侧输出conv_0、conv_1、conv_2、conv_3和conv_4作为不同尺度特征;
(3)语义特征粗定位在深度学习backbone网络的语义分支最后一层引入不同膨胀因子的膨胀卷积以及类别分支和回归分支,并计算与水平矩形框之间的位置敏感loss_1;(4)多尺度特征自适应融合将深度学习backbone网络不同层的侧输出通过卷积层以及下采样层和上采样层转变为统一大小的多尺度特征层;(5)语义特征引导多尺度特征增强将多尺度特征层输入语义引导的特征增强模块进行多尺度特征增强;(6)基于图结构的车牌区域细化将步骤(5)增强后的多尺度特征输入图卷积网络,基于图结构对车牌区域细化,在精细化分支输出层后引入类别分支和回归分支,并计算与畸变框之间的精细化loss_2;(7)训练网络使用步骤(1)训练集作为网络的拟合数据,将批量车牌检测图像数据输入到网络中,语义分支的输出结果为车牌类别置信度和回归坐标位置;精细化分支的输出结果为车牌类别置信度和回归坐标位置,采用focalloss计算车牌class 损失,smooth l1 loss计算车牌位置误差;经过设定56次完整训练集训练迭代后,保存精度最高的模型参数;(8)测试网络使用步骤(1)测试集作为网络的拟合数据,以长宽比例为基准将车牌图像填充后将批量车牌检测图像数据输入网络中,并加载步骤(7)训练好的模型参数,网络输出车牌类别置信度和回归坐标位置,设置阈值过滤掉低置信度的车牌,最后使用非极大抑制删除网络输出的冗余的框,实现复杂场景车牌检测。
8.作为本发明的进一步技术方案,步骤(1)对车牌图像标注的内容包含车牌的四个顶点位置坐标,对车牌图像标注采用倾斜矩形框坐标和水平矩形框坐标两种标注。
9.作为本发明的进一步技术方案,步骤(4)所述卷积层的卷积核为,得到的特征层为: ,其中为卷积操作,为上采样或下采样操作,为深度学习backbone网络不同层的侧输出。
10.作为本发明的进一步技术方案,步骤(5)所述语义引导的特征增强模块为:,其中为经过膨胀卷积后的特征,t代表转置操作,代表矩阵点乘法,代表矩阵叉乘。
11.作为本发明的进一步技术方案,步骤(6)的具体过程为:先构建图卷积网络的节点(i,j)之间的相似性度量为:,再构建网络图:
其中,i和j分别为中层特征的索引。
12.与现有技术相比,本发明先基于深度学习网络生成多尺度特征,在多尺度特征中嵌入语义特征从而极大的缩小问题域,利用多尺度特征弥补语义特征对于细节信息的缺失,在语义特征引导的基础上,为充分糅合语义特征与细节特征之间的互补优势,提出了语义特征与多尺度特征关系建模网络,通过图卷积网络(gcn)建模二者之间的特征关系,凭借gcn对于非规则物体的建模的优势,极大的提升了复杂场景下车牌检测的精度,同时针对车牌检测网络采用单一分支优化难的问题,将车牌检测网络拆解为双流网络,不仅可以用来进行复杂场景下的车牌检测,还可用于复杂场景下的物体分割等复杂场景下的检测,在ccpd数据集中精度达到97.9%。
附图说明
13.图1为本发明所述语义引导的特征增强模块结果结构框架示意图。
14.图2为本发明实现复杂场景车牌检测所采用的整个网络结构图。
15.图3为本发明实现复杂场景车牌检测的流程框图。
16.图4为本发明提供的车牌检测结果一,其中(a)为baseline方法,(b)为本发明方法。
17.图5为本发明提供的车牌检测结果二,其中(a)为baseline方法,(b)为本发明方法。
18.图6为本发明提供的车牌检测结果三,其中(a)为baseline方法,(b)为本发明方法。
具体实施方式
19.下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
20.实施例:本实施例通过主干网络提取不同层侧输出特征作为多尺度特征,而网络最后一层的特征富含高层语义信息,且对位置敏感,能够精确的定位车牌,而底层多尺度信息富含细节信息,辅助车牌精细化检测(如,尺度变化大,低对比度等复杂场景),为充分糅合语义与底层细节之间的互补优势,通过在多尺度信息中引入语义信息能够极大的缩小问题域,同时,多尺度信息能够弥补语义特征对于细节信息的缺失,本实施例在语义引导的多尺度信息融合的基础上,将二者进行关系建模以精细化车牌检测,首先将二者映射到高纬度空间,然后,凭借gcn对于非规则物体的建模的优势,引入图卷积网络(gcn)建模二者之间的特征关系。针对车牌检测单一网络优化难的问题,将车牌检测网络拆解为两个子网络,即位置敏感loss_1,精细化loss_2,如图1、图2和图3所示,具体实施包括如下步骤:(1)构建车牌检测数据集为解决复杂场景下车牌检测的问题,数据集采用复杂场景下的车牌图像构建了包含20000张图像的数据集,车牌标注包含,车牌的四个顶点位置坐标,同时,为了兼顾位置敏感loss_1,本实施例提供两种标注,即倾斜矩形框坐标(主要用于精细化loss_2)和水平矩形框坐标(主要用于位置敏感loss_1),其中数据集划分为训练集,验证集,测试集;
(2)多尺度特征提取将大小为512512的车牌图像经过归一化和去均值预处理后输入到backbone网络(resnet),将resnet的侧输出(conv_0,conv_1,conv_2,conv_3,conv_4)作为不同尺度特征;(3)语义特征粗定位(loss粗定位坐标框)因深度学习网络随着层数加深(conv_0-》4),层中蕴含的特征(f)越来越抽象,最后一层(conv_4)的特征富含语义特征,且其对车牌位置敏感,能够提供精确的车牌位置信息,同时,为增大语义信息的感受野,在语义分支输出层引入不同膨胀因子的膨胀卷积以及类别分支和回归分支,并计算与车牌图像水平框之间的位置敏感loss_1;(4)多尺度特征自适应融合(resize到大小相同)由于最后一层特征对于细节不敏感,如车牌倾斜、不同大小的车牌,为弥补最后一层特征的细节丢失,本实施例将网络不同层的侧输出(conv_0-》4)通过卷积层conv()以及下采样层(down)和上采样层(up)转变为统一大小(6464512)的特征层:;(5)语义特征引导多尺度特征增强为缩小多尺度特征引入导致的问题域过大导致网络不好收敛问题,在多尺度特征层后面引入语义特征作为特征引导,同时,二者存在强互补性,因此,需要设计网络为既能够建模语义特征和多尺度特征之间的互补性,语义特征在其中又要起到引导作用,设计的模块为:,其中,t代表转置操作,代表矩阵点乘法,代表矩阵叉乘;(6)基于图结构的车牌区域细化为克服复杂场景下车牌的畸变、形变等问题,需要将高层语义关系中蕴含的特征建模,本实施例引入图网络来应对复杂场景下不规则车牌的检测,先构建图网络的节点(i,j)之间的相似性度量为:,则,网络图的构建为:其中,i和j分别为中特征层的索引;在精细化分支输出层之后引入类别分支和回归分支,并计算与畸变框之间的loss_2;(7)训练网络使用步骤(1)中训练集作为网络的拟合数据,将批量车牌检测图片数据输入到本实施例采用的网络中,分别得到语义分支的输出结果:车牌类别置信度和回归坐标位置;多尺度分支的输出结
果:车牌类别置信度和回归坐标位置,其中class(0, 1),代表车牌是否出现,p是输出车牌推荐(proposal)的数量,为车牌的四个顶点(42=8)的坐标;采用focalloss计算车牌class 损失,smooth l1 loss计算车牌location误差,经过设定56次完整训练集训练迭代后,保存精度最高的模型参数;(8)测试网络使用步骤(1)测试集作为网络的拟合数据,为适应网络输入尺寸,本实施例以长宽比例为基准,将图像填充,然后将批量车牌检测图像数据输入到网络中,并加载训练好的模型参数,网络输出车牌类别置信度和回归坐标位置,设置置信度阈值(0.1)过滤掉低置信度的车牌,最后使用非极大抑制(nms)删除网络输出的冗余的框。
21.本实施例通过在多尺度信息中引入语义信息极大的缩小问题域,同时,利用多尺度信息够弥补语义特征对于细节信息的缺失,能够高效的实现车牌检测矫正。
22.实施例2:本实施例采用实施例1所述技术方案,利用ccpd数据集对车牌检测效果进行验证,并与现有baseline方法进行对比,检测结果图如图4、图5和图6所示。
23.本文中未详细说明的网络结构、算法均为本领域通用技术。
24.需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。