1.本发明涉及联邦学习框架下隐私保护技术领域,特别是基于双重扰动的联邦学习对抗推理攻击隐私保护方法。
背景技术:
2.近年来,机器学习受益于终端用户设备的巨大增长以及在这些设备上收集的数据量的急剧膨胀。基于机器学习的智能系统已经应用到日常生活的许多方面,如智能疾病诊断服务、智能教育系统等。然而,机器学习需要在基于云的服务器上收集分布式用户的数据,以便进行集中计算。在现实场景中,由于数据隐私规则和条例的限制,很难将这些数据收集在一起。联邦学习为这一挑战提供了技术解决方案。在联邦学习模型中,终端设备不需要将本地敏感数据上传到中央服务器;相反,它只需要在本地训练模型,并将本地更新的数据上传到服务器进行聚合即可。
3.尽管联邦学习可以在一定程度上提供隐私保护,但相关研究工作表明,共享模型更新或梯度使得联邦学习容易遭受推理攻击,如成员推理攻击和重构攻击。重构攻击的目的是利用模型更新或梯度来尽可能准确地恢复客户端的原始训练数据。为了防御重构攻击,研究学者提出了许多方案,这些方案可以大致分为三类。第一类是基于传统加密技术的方案,存在准确性不高、计算复杂度高、时间开销大等问题。第二类防御方案通过扰动在联邦学习模型上计算出来的信息,这些方案的防御思想主要是对模型参数或梯度进行了无差别的扰动,保护了隐私的同时也造成了不可忽略的准确性损失。还有一些文献,通过直接扰动特征表示或将神经网络分为私有和公共模型,仅共享公共模型提取的特征表示来使得攻击者重构数据的质量严重下降。这一类方案只保护了联邦学习模型计算出来的信息,并没有为客户所持有的敏感数据提供有效的隐私保护。第三类方法通过扭曲或者替换客户的训练数据来保护隐私,这类防御措施往往会导致显著的性能下降,因为数据的分类特征分布被破坏。此外,这类方案只保护了客户的数据,对联邦学习模型的计算信息没有采取任何隐私保护措施。
技术实现要素:
4.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
5.鉴于上述和/或现有的基于双重扰动的联邦学习对抗推理攻击隐私保护方法中存在的问题,提出了本发明。
6.因此,本发明所要解决的问题在于如何增强联邦学习场景下的安全性,提高客户端抵抗外部推理攻击的能力,为实现安全的数据隐私环境提供了有力支撑。
7.为解决上述技术问题,本发明提供如下技术方案:基于双重扰动的联邦学习对抗推理攻击隐私保护方法,其包括,由客户端为条件生成对抗网络设置分类特征提取器,并为
条件生成对抗网络的生成器设计模糊函数,客户端在本地数据集上使用两阶段对抗训练机制训练条件生成对抗网络;
8.使用训练好的条件生成对抗网络为本地数据集中的每一个数据生成伪数据,并将真实数据与伪数据按一定比例混合构造参与联邦学习训练的伪训练数据;
9.通过中央服务器随机初始化全局模型参数,并通过通信链路向参与训练的客户端发送当前通信轮次的全局模型参数,客户端在私有数据集上训练本地模型;
10.模型训练过程中设计一个目标函数来构造扰动矩阵对全连接层的梯度进行扰动;
11.根据被扰动的梯度和当前模型参数每个参与的客户端执行随机梯度下降算法更新模型参数;
12.更新所有来自客户端的模型,通过中央服务器根据样本量的权重进行聚合,得到下一轮的全局模型参数。
13.作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述条件生成对抗网络的设置与训练过程包括,
14.为生成器的目标设置一个模糊项μ(vr(g(z|yi))-ve)2,其中,μ是模糊项的系数,z是噪声,yi是标签,连同vr来计算生成器g生成的伪图片g(z|yi)的方差,预设期望方差ve;
15.先训练生成器,固定鉴别器d,只更新生成器g;
16.从先验分布pz(z)中随机选取一批噪声z,将其输入到生成器g构造伪样本g(z|yi);
17.将在imagenet数据集上预训练好的神经网络第一个卷积层作为分类特征提取器f,提取真实数据和伪数据的分类特征。
18.作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述伪训练数据的生成过程包括,
19.客户端i所持有的数据集di中的每一个数据xi,将其标签yi和随机噪声z输入到训练好的条件生成网络的生成器中,生成一个与xi具有相同标签的伪数据xi′
;
20.将xi和xi′
按一定的比例λ混合构造伪训练数据xi″
,通过如下公式表示:
21.xi″
=λxi (1-λ)xi′
22.客户端i(i∈{1,2,...,k})得到一个由伪训练数据xi″
构成的伪训练数据集di″
。
23.作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的优选方案,其中:协同训练开始时,中央服务器通过通信链路向参与训练的客户端发送当前全局模型参数θ
t
;
24.从中央服务器接收全局模型θ后,客户端在自己的数据集d
″
上利用分类损失函数训练本地模型m,通过如下公式表示:
[0025][0026]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述一个目标函数来构造扰动矩阵对全连接层的梯度进行扰动应遵循两个原则,包括攻击者推理出的数据和训练数据之间的差异尽可能大;攻击者推理出的数据特征表示和真实数据特征表示相似。
[0027]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述全连接层梯度的扰动的过程包括,
[0028]
给出真实数据特征表示f与推理出的数据特征f
′
表示相似度的定义:f
′
的部分元素值为零,其他元素的值等于f对应位置元素的值;f和f
′
之间的相似度可以用0元素的数量来衡量,α为0元素个数的阈值;均方误差被用来作为模型的真实输入数据x
″
和重建的输入数据之间相似性的度量。
[0029]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述客户端模型更新过程包括,
[0030]
计算得到被扰动的全连接层梯度
[0031]
每个参与的客户端根据被扰动的梯度、当前模型参数、学习率η执行梯度下降算法更新模型参数,公式如下所示:
[0032][0033][0034]
其中,θ表示全局模型。
[0035]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述模型聚合过程包括,
[0036]
本地模型更新完成后,客户端将本地模型更新通过通信链路发送到中央服务器;
[0037]
当收到所有来自客户端的模型更新后,中央服务器根据样本量的权重进行聚合,得到下一轮的全局模型参数θ
t 1
,具体如下所示:
[0038][0039]
服务器将新的全局模型参数θ
t 1
发送给客户端进行下一轮训练。
[0040]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述条件生成对抗网络的设置与训练过程还包括,
[0041]
将每个伪样本的分类特征f(g(z|yi))输入鉴别器d,得到输出:
[0042]
log(1-d(f(g(z|yi)))
[0043][0044]
再训练鉴别器,在此阶段,固定生成器g,只更新鉴别器d,将真实数据的分类特征f(xi)和假样本的分类特征f(g(z|yi))分别输入鉴别器对真假样本进行鉴别,得到两个输出:logd(f(xi)|yi)和log(1-d(f(g(z|yi)):
[0045][0046]
交替训练生成器与鉴别器直至条件生成对抗网络模型收敛。
[0047]
作为本发明所述基于双重扰动的联邦学习对抗推理攻击隐私保护方法的一种优选方案,其中:所述全连接层梯度的扰动的过程还包括,
[0048]
根据梯度扰动方法遵循的两个原则,构建了如下的目标函数:
[0049][0050]
其中,特征f∈r
l
表示的每个元素fii∈{0,1,......,l-1}分别计算式子当推理特征表示的元素值fi′
=0时,的值越小,输入数据x
″
和推理数据之间的均方差就越大;
[0051]
用集合j来记录集合的前α小的元素值索引i,并且构造一个所有元素的值为1的向量掩码mask∈r
l
,通过迭代j中的元素j,令maskj=0得到用于构造扰动矩阵的剪枝掩码mask;
[0052]
初始化的扰动矩阵h∈r
l
×b所有元素值均为1,矩阵h的β个列向量被向量掩码mask替换以构造扰动矩阵h;
[0053]
将全连接层梯度与扰动矩阵h执行哈达玛乘积,计算和扰动梯度的过程如下所示:
[0054][0055][0056][0057]
本发明有益效果为(1)通过设计生成伪训练数据的方法,引入了一个特征提取器来帮助生成器学习真实数据的分类特征分布,并在生成器的目标函数中添加了一个函数来模糊生成的图像,将生成的图像与真实图像按一定比例混合构造伪训练图像参与联邦训练,有效保障了客户端本地数据的安全性,提高了客户端抵抗外部推理攻击的能力;(2)针对联邦学习训练过程中客户端上传的梯度,设计了扰动全连接层的梯度的算法,扰动了梯度中包含的最有利于攻击者重构训练数据的信息,使得攻击者利用扰动后的梯度重构的数据与真实数据的差异较大,提供了有力的隐私保护,并且攻击者推理出的数据特征表示与真实的数据特征表示是相似的,维持了联邦学习的性能;(3)传统的联邦学习机制在客户端与服务器之间的通信链路上容易受到一系列安全威胁的影响,本发明在客户端本地数据以及模型计算信息上都采取了隐私保护措施,能够有效抵抗推理攻击的入侵,提供了强有力的隐私保护,并且几乎不会降低模型的性能。
附图说明
[0058]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用
的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0059]
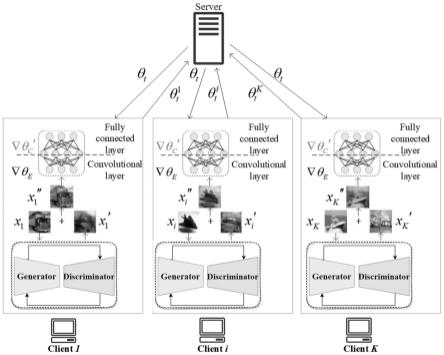
图1是本发明所述的基于双重扰动的联邦学习隐私保护系统模型;
[0060]
图2是本发明所述的构造伪训练数据方法在mnist数据集上的防御效果图;
[0061]
图3是本发明所述的构造伪训练数据方法消融实验对比图;
[0062]
图4是本发明所述的在mnist数据集的防御效果图
[0063]
图5是本发明所述的在cifar10数据集上的防御效果图;
[0064]
图6是本发明所述方法相较于dp-laplace、gc方案在cifar10数据集的防御效果对比图。
[0065]
图7是本发明所述方法相较于dp-laplace、gc方案在mnist数据集上的准确性对比图。
[0066]
图8是本发明所述方案相较于dp-laplace、gc方案在mnist数据集上的损失对比图。
具体实施方式
[0067]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
[0068]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0069]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
[0070]
实施例1
[0071]
参照图1和图2,为本发明第一个实施例,该实施例提供了基于双重扰动的联邦学习对抗推理攻击隐私保护方法,包括:
[0072]
s1:由客户端为条件生成对抗网络设置分类特征提取器并为条件生成对抗网络的生成器设计模糊函数,客户端在本地数据集上使用两阶段对抗训练机制训练条件生成对抗网络;
[0073]
条件生成对抗网络的设置与训练,步骤如下:
[0074]
为生成器的目标设置一个模糊项μ(vr(g(z|yi))-ve)2,μ是模糊项的系数,连同vr来计算生成器g生成的伪图片g(z|yi)的方差,预设期望方差ve;
[0075]
先训练生成器,在这个阶段,固定鉴别器d,只更新生成器g。从先验分布pz(z)中随机选取一批噪声z,将其输入到生成器g构造伪样本g(z|yi)。在imagenet数据集上预训练好的神经网络第一个卷积层作为分类特征提取器f,用于提取真实数据和伪数据的分类特征。接着将每个伪样本的分类特征f(g(z|yi))输入鉴别器d,得到输出log(1-d(f(g(z|yi))):
[0076]
[0077]
再训练鉴别器,在此阶段,固定生成器g,只更新鉴别器d,将真实数据的分类特征f(xi)和假样本的分类特征f(g(z|yi))分别输入鉴别器对真假样本进行鉴别,得到两个输出:logd(f(xi)|yi)和log(1-d(f(g(z|yi)):
[0078][0079]
交替训练生成器与鉴别器直至条件生成对抗网络模型收敛。
[0080]
s2:客户端使用训练好的条件生成对抗网络为本地数据集中的每一个数据生成伪数据,并将真实数据与伪数据按一定比例混合构造参与联邦学习训练的伪训练数据。
[0081]
伪训练数据的生成,包括如下步骤:
[0082]
客户端i所持有的数据集di中的每一个数据xi,将其标签yi和随机噪声z输入到训练好的条件生成网络的生成器中,生成一个与xi具有相同标签的伪数据xi′
;
[0083]
将xi和xi′
按一定的比例λ混合构造伪训练数据xi″
;
[0084]
xi″
=λxi (1-λ)xi′
[0085]
客户端i(i∈{1,2,...,k})得到一个由伪训练数据xi″
构成的伪训练数据集di″
。
[0086]
s3:中央服务器随机初始化全局模型参数并通过通信链路向参与训练的客户端发送当前全局模型参数,从中央服务器接收全局模型后,客户端在自己的数据集上训练本地模型。
[0087]
客户端与服务器的交互,包括如下步骤:
[0088]
协同训练开始时,中央服务器通过通信链路向参与训练的客户端发送当前全局模型参数θ
t
;
[0089]
从中央服务器接收全局模型θ后,客户端在自己的数据集d
″
上利用分类损失函数l训练本地模型m:
[0090][0091]
s4:模型训练过程中设计了一个目标函数来构造扰动矩阵对全连接层的梯度进行扰动,目标函数使得梯度的扰动遵循两个原则:1)为了保护隐私,攻击者推理出的数据和训练数据之间的差异尽可能大;2)攻击者推理出的数据特征表示和真实数据特征表示应该是相似的,以保持fl性能。
[0092]
全连接层梯度的扰动,包括如下步骤:
[0093]
给出真实数据特征表示f与推理出的数据特征表示f
′
相似度的定义:f
′
的部分元素值为零,其他元素的值等于f对应位置元素的值。因此,f和f
′
之间的相似度可以用0元素的数量来衡量,α为0元素个数的阈值。均方误差被用来作为模型的真实输入数据x
″
和重建的输入数据之间相似性的度量。
[0094]
根据梯度扰动方法遵循的两个原则,构建了如下的目标函数:
[0095][0096]
特征表示f∈r
l
的每个元素fi(i∈{0,1,......,l-1})分别计算式子当推理特征表示的元素值fi′
=0时,的值越小,输入数据x
″
和推理数据之间的均方差就越大;
[0097]
用集合j来记录集合的前α小的元素值索引i,并且构造一个所有元素的值为1的向量掩码mask∈r
l
,通过迭代j中的元素j,令maskj=0得到用于构造扰动矩阵的剪枝掩码mask;
[0098]
初始化的扰动矩阵h∈r
l
×b所有元素值均为1。接着,矩阵h的β个列向量被向量掩码mask替换以构造扰动矩阵h;
[0099]
将全连接层梯度与扰动矩阵h执行哈达玛乘积,计算和扰动梯度的过程如下所示:
[0100][0101][0102][0103]
s5:每个参与的客户端根据被扰动的梯度和当前模型参数执行随机梯度下降算法更新模型参数;
[0104]
客户端模型更新,包括如下步骤:
[0105]
计算得到被扰动的全连接层梯度
[0106]
每个参与的客户端根据被扰动的梯度、当前模型参数、学习率η执行梯度下降算法更新模型参数,公式如下所示:
[0107][0108][0109]
s6:接收到所有来自客户端的模型更新后,中央服务器根据样本量的权重进行聚合,得到下一轮的全局模型参数。
[0110]
模型聚合,包括如下步骤:
[0111]
本地模型更新完成后,客户端将本地模型更新通过通信链路发送到中央服务器;
compression,gc),本方法下攻击者重构的均方误差mse更大,即重构数据与原始敏感数据的差距更大,隐私保护的效果更好,同时保证隐私保护的情况下,本发明提的方法与dp-laplace、gc方法相比具备优越的准确性。这主要是因为本发明中为了维持联邦学习的性能,本方法在梯度扰动的过程中仅仅扰动了全连接层中最有利于攻击者重构原始数据的信息,而且dp-laplace和gc方法是对模型参数或梯度进行了无差别的扰动或者添加噪声。同样地,本发明设计方法的损失同样要比dp-laplace和gc方法小。总结可知,本发明设计方法更适用于实际的联邦学习场景。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。