一种兵棋推演的策略生成方法、电子设备、存储介质与流程
- 国知局
- 2024-07-11 16:09:29
本发明涉及多智能体强化学习,特别是涉及一种兵棋推演的策略生成方法、电子设备、存储介质
背景技术:
1、兵棋推演是一种可以用于模拟军事部署、推演战斗过程、预测战斗结果,从而评估战术可行性、战斗的胜负、人员以及装备损害程度的重要手段,随着信息技术和军事技术的高速发展,兵棋推演逐渐演变成海、陆、空、天、网络空间和电磁空间的多主体联合作战的过程,如何规划和协调多个作战主体的作战能力,成为兵棋推演中的重要研究问题,通过人工智能模型进行兵棋推演,利用计算机资源为指挥者提供决策支持具有深远意义。
2、但是由于兵棋推演以多主体联合作战为主,而各个主体的决策是相对独立的,且每个主体能观测到的信息都是有限的,这导致通过人工智能模型进行兵棋推演的过程具有策略的不可传递性、不完美信息、多主体同时决策等特性,不完美信息是指每个决策主体无法获取完整的博弈环境的信息,难以做出最优决策,奖赏稀疏会导致智能体无法确定所执行的动作是否有利于完成任务,难以学习到有效的策略且模型学习缓慢难以收敛,多主体之间的策略不可传递性会导致每个决策主体在决策时容易陷入局部最优,同时多主体决策会导致每个决策主体之间的行为相互影响,决策复杂度大幅提高,这导致模型难以得到整体最优解。此外,由于其他主体的动作影响,决策主体在面临同一观测状态作出相同决策时,决策主体的观测状态的改变是不唯一的,这导致了多主体协作过程不平稳的问题。
技术实现思路
1、本发明实施例的主要目的在于提出一种兵棋推演的策略生成方法、电子设备、计算机可读存储介质,可以解决通过人工智能模型进行兵棋推演的过程中难以得到最优解以及多智能体协作不平稳的问题。
2、为实现上述目的,本发明实施例的第一方面提出一种兵棋推演的策略生成方法,所述方法包括:
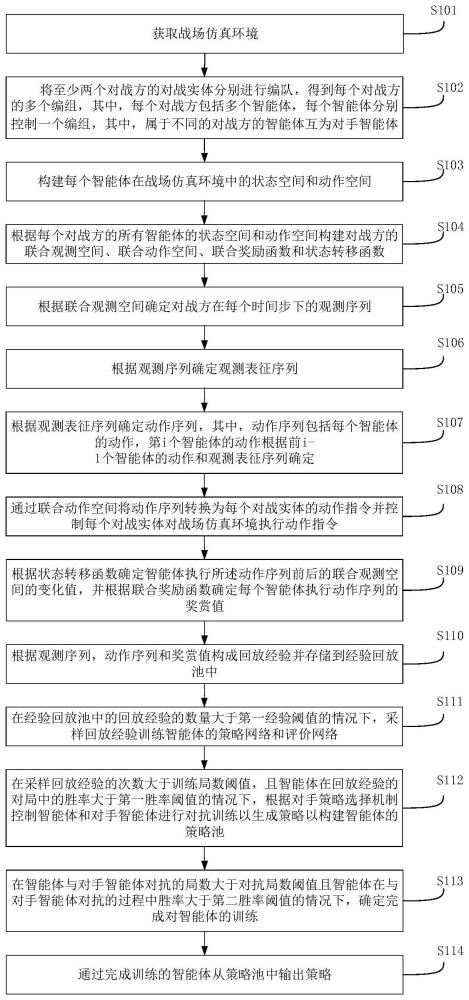
3、获取战场仿真环境;
4、将至少两个对战方的对战实体分别进行编队,得到每个所述对战方的多个编组,其中,每个所述对战方包括多个智能体,每个所述智能体分别控制一个编组,其中,属于不同的所述对战方的智能体互为对手智能体;
5、构建每个所述智能体在所述战场仿真环境中的状态空间和动作空间;
6、根据每个所述对战方的所有所述智能体的所述状态空间和所述动作空间构建所述对战方的联合观测空间、联合动作空间、联合奖励函数和状态转移函数;
7、根据所述联合观测空间确定所述对战方在每个时间步下的观测序列;
8、根据所述观测序列确定观测表征序列;
9、根据所述观测表征序列确定动作序列,其中,所述动作序列包括每个所述智能体的动作,第i个所述智能体的动作根据前i-1个所述智能体的动作和所述观测表征序列确定;
10、通过所述联合动作空间将所述动作序列转换为每个所述对战实体的动作指令并控制每个所述对战实体对所述战场仿真环境执行动作指令;
11、根据所述状态转移函数确定所述智能体执行所述动作序列前后的所述联合观测空间的变化值,并根据所述联合奖励函数确定每个所述智能体执行所述动作序列的奖赏值;
12、根据所述观测序列,所述动作序列和所述奖赏值构成回放经验并存储到经验回放池中;
13、在所述经验回放池中的所述回放经验的数量大于第一经验阈值的情况下,采样所述回放经验训练所述智能体的策略网络和评价网络;
14、在采样所述回放经验的次数大于训练局数阈值,且所述智能体在所述回放经验的对局中的胜率大于第一胜率阈值的情况下,根据对手策略选择机制控制所述智能体和所述对手智能体进行对抗训练以生成策略以构建所述智能体的策略池;
15、在所述智能体与所述对手智能体对抗的局数大于对抗局数阈值且所述智能体在与所述对手智能体对抗的过程中胜率大于第二胜率阈值的情况下,确定完成对所述智能体的训练;
16、通过完成训练的所述智能体从所述策略池中输出策略。
17、在一些实施例中,所述根据每个所述对战方的所有所述智能体的所述状态空间和所述动作空间构建所述对战方的联合观测空间、联合动作空间、联合奖励函数和状态转移函数,包括:
18、根据第一对战方的所有所述智能体的状态空间确定所述第一对战方的联合观测空间;其中,所述第一对战方是所述对战方中的一个;
19、根据所述第一对战方的所有所述智能体的动作空间确定所述第一对战方的联合动作空间;
20、根据所述第一对战方的所述联合观测空间和所述联合动作空间构建所述第一对战方的联合奖励函数和状态转移函数,其中,所述联合奖励函数用于计算所述对战方在所述联合观测空间下采取执行策略的期望奖励值,所述状态转移函数用于表征所述对战方执行策略前后所述联合观测空间的变化关系。。
21、在一些实施例中,所述方法还包括:
22、构建所述评价网络的值函数,其中,所述评价网络的值函数为:
23、
24、
25、其中,π表示所述对战方的所有所述智能体的动作构成的团队策略,a1:∞表示所述智能体在从1到∞的任一时间步下的动作,a1:∞~π表示所述智能体在任一时间步下的动作所述团队策略π中采样,o1:∞表示从1到∞的所有时间步下的所述联合空间状态的变化,o1:∞~p表示任一时间步下的所述联合空间状态的变化服从所述状态转移函数p,a0表示初始的所述动作序列,o0表示初始的所述联合状态空间,a表示给定的初始动作序列,qπ(o,a)表示观测-动作对值函数,所述观测-动作对值函数表征所述对战方在初始的所述联合观测空间o0为o,初始的所述动作序列a0为a,所述联合观测空间的变化服从所述状态转移函数p,在任一时间步下所述智能体所选取的所述动作序列从所述团队策略π中采样的情况下的累积折扣回报rγ的期望值;vπ(o)表示观测值函数,所述观测值函数表征所述对战方在初始的所述联合观测空间o0为o,初始的所述动作序列a0从所述团队策略π中采样,所述联合观测空间的变化服从所述状态转移函数p,在任一时间步的所选取的所述动作序列从所述团队策略π中采样的情况下,所述累积折扣回报rγ的期望值;表示取期望值,γ表示折扣因子。
26、在一些实施例中,所述采样所述回放经验训练所述智能体的策略网络和评价网络,包括:
27、获取所述回放经验中每个智能体在每个时间步下的所述观测表征序列、所述动作序列和所述奖赏值;
28、根据所述观测表征序列确定每个所述智能体在每个时间步下的值函数估计值,其中,所述值函数估计值是所述观测值函数和所述观测-动作对值函数中的一个;
29、根据每个所述智能体在每个时间步下的值函数估计值和所述对战方在每个时间步的所述奖赏值优化所述评价网络的参数;
30、根据所述观测表征序列和所述动作序列确定每个所述智能体在每个时间步下的策略;
31、根据每个所述智能体在每个时间步下的所述值函数估计值、每个所述智能体在每个时间步下的策略优化所述策略网络的参数。
32、在一些实施例中,所述根据所述观测表征序列确定动作序列,包括:
33、对所述对战方的每个所述智能体执行如下操作:
34、将所述智能体作为第i个智能体;
35、获取所述第i个智能体的观测表征,其中,所述第i个智能体的观测表征根据所述观测表征序列确定
36、获取前i-1个智能体的动作;
37、根据所述第i个智能体的观测表征和所述前i-1个智能体的动作确定所述第i个智能体的动作;
38、将所述第i个智能体的动作添加到所述对战方的所述动作序列中。
39、在一些实施例中,所述根据所述对手策略选择机制控制所述智能体和所述对手智能体对抗并生成策略以构建所述智能体的策略池,包括:
40、将至少两个所述对战方分别确定为主练方和陪练方,其中,所述主练方的智能体为第一智能体,所述陪练方的所述智能体包括主陪练智能体和副陪练智能体;
41、将所述主陪练智能体的策略池和所述副陪练智能体的策略池中的策略周期性初始化为专家规则;
42、所述第一智能体根据所述对手策略选择机制从所述主陪练智能体的策略池和所述副陪练智能体的策略池中选取对手策略进行训练,以生成新的策略并添加到所述第一智能体的策略池中以构建所述智能体的策略池;
43、所述主陪练智能体以所第一智能体在当前周期选择的策略为对手进行训练,以生成新的策略并添加到所述主陪练智能体的策略池中作为所述第一智能体的对手策略;
44、所述副陪练智能体以所述第一智能体的策略池中的历史策略为对手进行训练,以生成新的策略并添加到所述副陪练智能体的策略池中作为所述第一智能体的对手策略。
45、在一些实施例中,所述方法还包括:
46、获取所述智能体以第一策略击败所述对手智能体的每个策略的统计概率,其中,所述第一策略是所述智能体当前选择的策略;
47、根据所述智能体以第一策略击败所述对手智能体的第二策略的统计概率以及所述智能体以所述第一策略击败所述对手智能体每个策略的统计概率的总和确定所述对手智能体选择所述第二策略的概率,其中,所述第二策略是所述对手智能体的策略中的一个
48、根据所述对手智能体选择每个所述第二策略的概率构建所述对手策略选择机制。
49、在一些实施例中,所述根据所述智能体以第一策略击败所述对手智能体的第二策略的统计概率以及所述智能体以所述第一策略击败所述对手智能体除所述第二策略外的所有策略的统计概率的总和确定所述对手智能体选择所述第二策略的概率,包括:
50、对所述智能体的训练进行难度划分,得到所述智能体的多个训练难度;
51、确定所述智能体在每个所述训练难度下的第一映射函数,其中,所述第一映射函数用于将所述智能体以所述第一策略击败所述对手智能体的每个策略的统计概率映射至相应的所述训练难度;
52、根据所述智能体当前选择的所述训练难度和所述第一映射函数更新所述智能体以所述第一策略击败所述对手智能体的每个策略的统计概率;
53、根据更新后的所述统计概率确定所述对手智能体选择所述第二策略的概率。
54、在一些实施例中,所述方法还包括:
55、确定所述智能体执行任务的初始达成率和所述智能体执行任务的目标达成率;
56、根据训练局数阈值、所述初始达成率和所述目标达成率确定所述智能体的至少一个阶段达成率,所述阶段达成率用于表征所述智能体在训练过程中的每个阶段的任务达成率;
57、根据所述初始达成率、所述阶段达成率和所述目标达成率构建所述智能体的奖赏函数;
58、在所述智能体和所述对手智能体进行对抗训练的过程中,根据所述奖赏函数给予所述智能体奖赏值。
59、在一些实施例中,所述方法还包括:
60、在所述智能体消灭所述对手智能体控制的所述对战实体时,向所述智能体的奖赏函数中增加第一奖赏值;
61、在所述智能体控制的所述对战实体被所述对手智能体消灭时,从所述智能体的奖赏函数中扣除所述第一奖赏值。
62、本技术实施例的第二方面提出一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如第一方面实施例中任意一项所述的方法。
63、本技术实施例的第三方面提出一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器运行,以实现如第一方面实施例中任一项所述的方法。
64、本技术实施例提出一种战场仿真的策略生成方法、电子设备和存储介质,方法包括:获取战场仿真环境;将至少两个对战方的对战实体分别进行编队,得到每个所述对战方的多个编组,其中,每个所述对战方包括多个智能体,每个所述智能体分别控制一个编组,其中,属于不同的所述对战方的智能体互为对手智能体;构建每个所述智能体在所述战场仿真环境中的状态空间和动作空间;根据每个所述对战方的所有所述智能体的所述状态空间和所述动作空间构建所述对战方的联合观测空间、联合动作空间、联合奖励函数和状态转移函数;根据所述联合观测空间确定所述对战方在每个时间步下的观测序列;根据所述观测序列确定观测表征序列;根据所述观测表征序列确定动作序列,其中,所述动作序列包括每个所述智能体的动作,第i个所述智能体的动作根据前i-1个所述智能体的动作和所述观测表征序列确定;通过所述联合动作空间将所述动作序列转换为每个所述对战实体的动作指令并控制每个所述对战实体对所述战场仿真环境执行动作指令;根据所述状态转移函数确定所述智能体执行所述动作序列前后的所述联合观测空间的变化值,并根据所述联合奖励函数确定每个所述智能体执行所述动作序列的奖赏值;根据所述观测序列,所述动作序列和所述奖赏值构成回放经验并存储到经验回放池中;在所述经验回放池中的所述回放经验的数量大于第一经验阈值的情况下,采样所述回放经验训练所述智能体的策略网络和评价网络;在采样所述回放经验的次数大于训练局数阈值,且所述智能体在所述回放经验的对局中的胜率大于第一胜率阈值的情况下,根据对手策略选择机制控制所述智能体和所述对手智能体进行对抗训练以生成策略以构建所述智能体的策略池;在所述智能体与所述对手智能体对抗的局数大于对抗局数阈值且所述智能体在与所述对手智能体对抗的过程中胜率大于第二胜率阈值的情况下,确定完成对所述智能体的训练;通过完成训练的所述智能体从所述策略池中输出策略。本技术实施例通过基于每个智能体的状态空间和动作空间构建多智能体的联合状态空间、联合动作空间、联合奖励函数和状态转移函数,使多智能体可以在团队层面进行学习和决策,避免每个智能体在决策时陷入局部最优,同时将多智能体决策问题转化为生成动作序列的策略生成问题,大幅降低了多智能体决策的复杂度,同时,控制每个智能体在决策时除了基于智能体的观测信息外还需要考虑其它智能体的动作序列,一方面,由于智能体在决策时会考虑其它智能体的动作,智能体在面临同一观测状态时也会由于其它智能体的动作而选择不同的动作,从而避免智能体在面临同一观测状态时采取相同动作,却由于其它智能体的影响使得观测状态空间的变化不唯一,导致多智能体协作不平稳的问题,另一方面可以避免由于多智能体之间的策略不可传递导致每个智能体决策时容易陷入局部最优的问题,有效提高了兵棋推演场景下智能体决策的平稳性,同时使得多智能体的决策可以更好的逼近全局最优解,基于此,提供一种可以有效地利用人工智能模型进行兵棋推演,为指挥者提供决策支持的方法。
本文地址:https://www.jishuxx.com/zhuanli/20240615/77783.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表