基于迁移学习和端到端模型的直升机话音识别方法及设备
- 国知局
- 2024-06-21 10:38:22
本发明属于语音识别,涉及一种直升机话音识别方法及设备。
背景技术:
1、直升机作为20世纪航空技术的杰出成果之一,拥有特殊的垂直起降和悬停能力,使得它在许多不同的领域中得到了广泛的应用,包括军事、民用、科学研究和建筑施工等方面。但是近年来直升机坠机事件时有发生,一旦有坠机事件发生,飞行员及乘客能够生还的几率很小,还极有可能被烧毁,民航事故调查分析局在对空难事故原因进行调查一般是通过黑匣子。黑匣子主要分为飞行数据记录仪和驾驶舱话音记录仪两种。对于分析事故发生的原因,驾驶舱话音记录仪内部记录的话音提供了非常关键的信息源。
2、为了了解飞行过程和为事故原因调查提供关键信息,需要对直升机的座舱话音进行准确的识别。由于直升机飞行环境的特殊性,驾驶舱话音记录仪内部的声音信号较为复杂,面对很强的背景噪声和电台声的干扰、对话内容不是常见词,严重影响了直升机座舱话音识别的准确性,并且由于目前没有直升机话音领域大量已标注的数据集,因此导致基于深度学习进行的方式训练比较困难,且会影响训练得到的模型检测准确度,这都使得直升机话音识别具有挑战性。
3、目前的语音识别技术主要面向通用领域,主要关注在弱噪声环境下对标准普通话的准确识别。现阶段如果想要了解话音数据中所包含的信息,只能通过相关的专业人员通过人耳来进行分辨,在对话音数据的信息进行研究时,需要巨大的工作量才能完成对话音数据的分析。因此利用当前的声音分析方法以及语音识别技术,准确的识别出驾驶舱话音记录仪包含的话音数据,对于后续的事故原因分析、调查,具有重要意义。
技术实现思路
1、本发明为了解决现有语音识别技术进行直升机座舱话音识别准确性低的问题以及识别模型训练难度大的问题。
2、基于迁移学习和端到端模型的直升机话音识别方法,首先获取待识别的直升机座舱话音,然后对待识别的直升机座舱话音数据进行音速扰动处理,然后提取声学特征;基于直升机座舱话音识别模型对提取的声学特征进行识别;
3、所述的直升机座舱话音识别模型通过以下步骤得到:
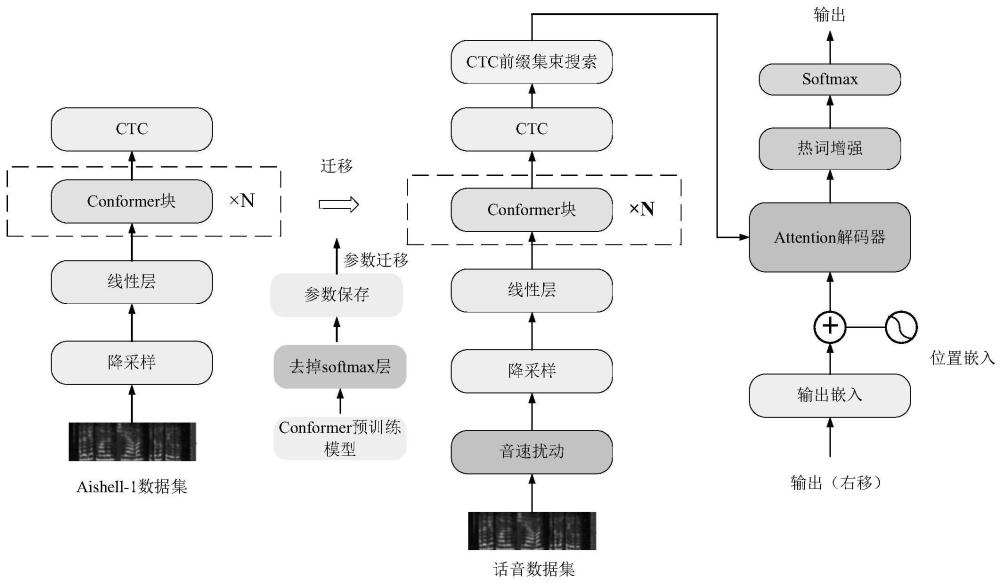
4、首先训练出一个端到端的语音识别模型,端到端语音识别模型采用编码器-解码器结构,语音识别模型的编码器采用conformer编码器;同时调用在wenet语音识别工具上开源的预训练模型;基于模型的迁移学习方法,利用在开源数据集上训练的语音识别模型的权重参数,结合预训练模型结构得到直升机话音识别模型,直升机话音识别模型采用编码器-解码器结构,其中编码器为conformer编码器;在迁移的过程中,将在开源数据集上训练的语音识别模型的权重参数保存,将预训练模型的参数按照语音识别模型的参数进行更改,然后在直升机话音数据集上训练,接着在迁移预训练模型时,去掉softmax层,得到直升机话音识别模型;
5、在话音识别模型的测试阶段,编码器输出高维的特征表示,之后进入ctc解码器,使用ctc的解码结果作为中间结果,再通过ctc前缀集数搜索算法产生n个最好的效果,然后采用attention解码器对多个候选结果重打分,最后对话音热词进行热词增强,最终送入softmax层得到输出结果;
6、在话音识别模型的基础上搭建融合语言模型,作为最终的直升机座舱话音识别模型;在话音识别模型的基础上搭建融合语言模型的过程包括以下步骤:
7、以基于迁移学习得到的话音识别模型为声学模型,在测试解码阶段与语言模型通过浅融合的方式进行解码,通过ctc解码得到字符序列,然后加入语言模型对ctc计算单词序列的概率,最后将字符序列和单词序列两个序列结合起来计算每个前缀的概率;进而得到以话音识别模型为声学模型并与语言模型融合的融合语言模型。
8、进一步地,对直升机座舱话音数据进行音速扰动处理之前需要对直升机座舱话音数据进行降噪处理,具体过程包括以下步骤:
9、针对1khz以内的噪声,采用有源噪声控制方式进行初步降噪,针对高于1khz以内的噪声进行二次降噪。
10、进一步地,所述初步降噪采用自适应最小均方误差算法或递归最小二乘法进行降噪处理;所述二次降噪采用谱减法或维纳滤波法进行降噪处理。
11、进一步地,基于直升机座舱话音识别模型对提取的声学特征进行识别的过程中,对提取的声学特征进行降采样,之后送入线性层,经过线性层后送入conformer编码器继续处理。
12、进一步地,对直升机座舱话音数据进行音速扰动处理的过程中,对直升机座舱话音数据进行0.8倍速音速扰动处理。
13、进一步地,训练端到端的语音识别模型的过程中是利用开源的汉语语音数据集训练的。
14、进一步地,所述的语言模型为n-gram语言模型或transformer语言模型。
15、进一步地,所述的声学特征为fbank特征。
16、一种计算机存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现基于迁移学习和端到端模型的直升机话音识别方法。
17、一种基于迁移学习和端到端模型的直升机话音识别设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现基于迁移学习和端到端模型的直升机话音识别方法。
18、有益效果:
19、1.本发明利用深度学习的方法和技术,实现对直升机座舱话音的自动识别,克服了传统方法需要人工分辨话音数据的不足。
20、2.本发明对驾驶舱话音记录仪记录的话音数据进行降噪处理,有效的对噪声进行消除,从而得到相对纯净的话音数据,降低噪声对话音识别效果产生的影响。
21、3.本发明手动标注话音数据集,基于迁移学习方法训练直升机座舱话音识别模型,并将语言模型与端到端话音识别模型相结合,提高了识别的准确性和效率。
技术特征:1.基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,首先获取待识别的直升机座舱话音,然后对待识别的直升机座舱话音数据进行音速扰动处理,然后提取声学特征;基于直升机座舱话音识别模型对提取的声学特征进行识别;
2.根据权利要求1所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,对直升机座舱话音数据进行音速扰动处理之前需要对直升机座舱话音数据进行降噪处理,具体过程包括以下步骤:
3.根据权利要求2所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,所述初步降噪采用自适应最小均方误差算法或递归最小二乘法进行降噪处理;所述二次降噪采用谱减法或维纳滤波法进行降噪处理。
4.根据权利要求1、2或3所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,基于直升机座舱话音识别模型对提取的声学特征进行识别的过程中,对提取的声学特征进行降采样,之后送入线性层,经过线性层后送入conformer编码器继续处理。
5.根据权利要求4所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,对直升机座舱话音数据进行音速扰动处理的过程中,对直升机座舱话音数据进行0.8倍速音速扰动处理。
6.根据权利要求5所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,训练端到端的语音识别模型的过程中是利用开源的汉语语音数据集训练的。
7.根据权利要求6所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,所述的语言模型为n-gram语言模型或transformer语言模型。
8.根据权利要求7所述的基于迁移学习和端到端模型的直升机话音识别方法,其特征在于,所述的声学特征为fbank特征。
9.一种计算机存储介质,其特征在于,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如权利要求1至8任意一项所述的基于迁移学习和端到端模型的直升机话音识别方法。
10.一种基于迁移学习和端到端模型的直升机话音识别设备,其特征在于,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如权利要求1至8任意一项所述的基于迁移学习和端到端模型的直升机话音识别方法。
技术总结基于迁移学习和端到端模型的直升机话音识别方法及设备,属于语音识别技术领域。为了解决现有语音识别技术进行直升机座舱话音识别准确性低的问题以及识别模型训练难度大的问题,本发明首先构建编码器‑解码器结构的话音识别模型,基于模型的迁移学习方法,利用训练好的语音识别模型对应的模型权重参数和预训练模型得到话音识别模型;编码器输出高维的特征表示,之后进入CTC解码器,通过CTC前缀集数搜索算法产生N个最好的效果,采用Attention解码器对多个候选结果重打分,最后对话音热词进行热词增强,送入Softmax层输出结果;以话音识别模型为声学模型与语言模型融合得到直升机座舱话音识别模型,用于对待识别的直升机座舱话音进行识别。技术研发人员:王国涛,王佳琦,王世成,节艳红,宋守来,孙玥受保护的技术使用者:黑龙江大学技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20853.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表