对讲终端的语音处理方法、装置、终端设备及存储介质与流程
- 国知局
- 2024-06-21 11:26:12
本发明涉及语音处理,尤其涉及一种对讲终端的语音处理方法、装置、终端设备及存储介质。
背景技术:
1、随着语音技术的广泛应用,各个智能语音设备可以利用智能语音技术与用户进行交互。在对讲终端中,对讲终端的输入端接收用户的输入语音,经由对讲终端的输出端将用户的输入语音输出。在对讲终端接收到输入语音后,现有技术通常未经处理将所输入的语音直接输出到语音输出端,这样导致所接收到的语音包含过多噪音,所输出的语音质量低。因此,亟需一种能提高对讲终端输出语音质量的方法。
技术实现思路
1、本发明实施例提供一种对讲终端的语音处理方法、装置、终端设备及存储介质,能提高对讲终端输出语音质量。
2、本发明一实施例提供一种对讲终端的语音处理方法,包括:
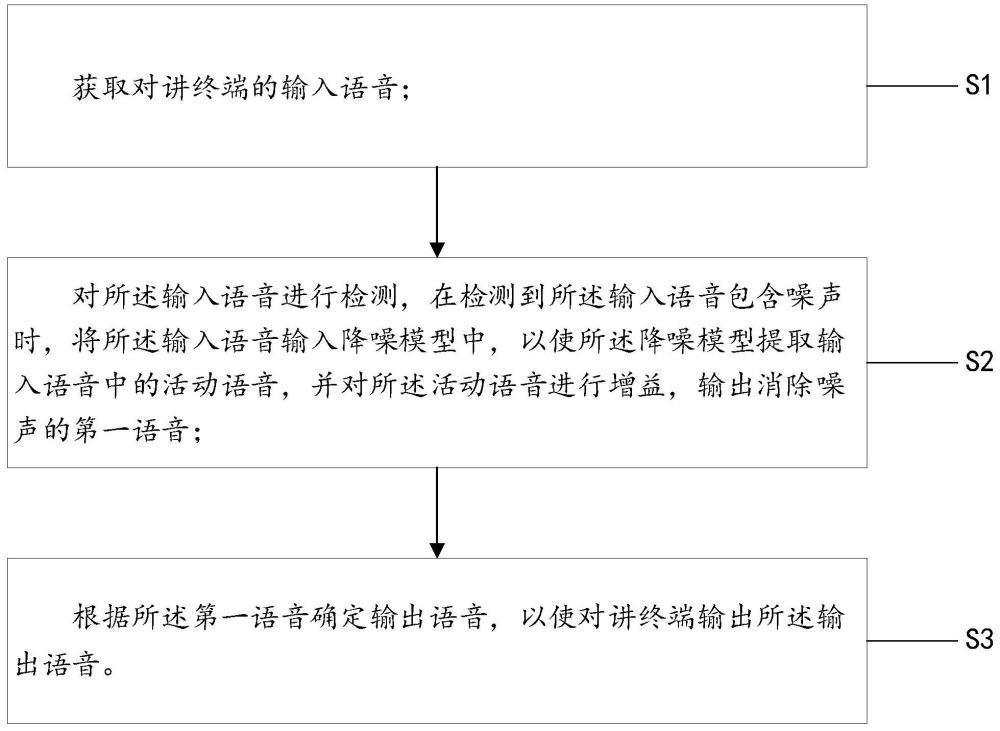
3、获取对讲终端的输入语音;
4、对所述输入语音进行检测,在检测到所述输入语音包含噪声时,将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音;
5、根据所述第一语音确定输出语音,以使对讲终端输出所述输出语音。
6、进一步地,所述降噪模型包括:活动语音检测子模型和增益子模型;
7、所述活动语音检测子模型由具有24个神经元的dense层、具有24个神经元的gru层和具有1个神经元的dense层构成;
8、所述增益子模型由具有48个神经元的gru层、具有96个神经元的gru层和具有22个神经元的dense层构成。
9、进一步地,所述将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音,包括:
10、将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音的特征点,并将所述特征点输入活动语音检测子模型,以使所述特征点经过活动语音检测子模型处理后,确定输入语音中活动语音的位置;将所述特征点输入增益子模型,以使所述特征点经过增益子模型处理后,确定输入语音对应的目标增益;
11、所述降噪模型根据所述目标增益对输入语音中的活动语音进行增益,输出消除噪声的第一语音。
12、进一步地,还包括:
13、在检测到所述输入语音包含回声时,根据回声消除算法对所述输入语音进行处理,生成消除回声的第二语音;
14、根据所述第一语音和第二语音确定输出语音,以使对讲终端输出所述输出语音。
15、进一步地,所述根据回声消除算法对所述输入语音进行处理,生成消除回声的第二语音,包括:
16、获取所述输入语音的近端信号和远端信号;
17、对所述近端信号和远端信号分别进行傅里叶变换,生成第一转换信号和第二转换信号;
18、根据所述第一转换信号、第二转换信号和nlms自适应算法确定误差信号;
19、根据所述误差信号、第一转换信号和第二转换信号确定输入语音的回声状态;
20、根据所述回声状态和误差信号确定回声抑制滤波器的滤波系数;
21、根据所述滤波系数调整回声抑制滤波器,以使回声抑制滤波器消除所述误差信号,生成消除回声的第二语音。
22、在上述方法项实施例的基础上,本发明对应提供了装置项实施例;
23、本发明一实施例对应提供了一种对讲终端的语音处理装置,包括:语音获取模块、语音处理模块和语音输出模块;
24、所述语音获取模块,用于获取对讲终端的输入语音;
25、所述语音处理模块,用于对所述输入语音进行检测,在检测到所述输入语音包含噪声时,将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音;
26、所述语音输出模块,用于根据所述第一语音确定输出语音,以使对讲终端输出所述输出语音。
27、进一步地,所述降噪模型包括:活动语音检测子模型和增益子模型;
28、所述活动语音检测子模型由具有24个神经元的dense层、具有24个神经元的gru层和具有1个神经元的dense层构成;
29、所述增益子模型由具有48个神经元的gru层、具有96个神经元的gru层和具有22个神经元的dense层构成。
30、进一步地,所述将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音,包括:
31、将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音的特征点,并将所述特征点输入活动语音检测子模型,以使所述特征点经过活动语音检测子模型处理后,确定输入语音中活动语音的位置;将所述特征点输入增益子模型,以使所述特征点经过增益子模型处理后,确定输入语音对应的目标增益;
32、所述降噪模型根据所述目标增益对输入语音中的活动语音进行增益,输出消除噪声的第一语音。
33、本发明另一实施例提供了一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现上述发明实施例所述的一种对讲终端的语音处理方法。
34、本发明另一实施例提供了一种存储介质,所述存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述存储介质所在设备执行上述发明实施例所述的一种对讲终端的语音处理方法。
35、通过实施本发明具有如下有益效果:
36、本发明提供了一种对讲终端的语音处理方法、装置、终端设备及存储介质,所述方法通过获取对讲终端的输入语音,并对输入语音进行检测,在检测到的输入语音中包含有噪声时,根据降噪模型确定输入语音中的活动语音,即确定输入语音中的人声部分,根据降噪模型对所确定的活动语音进行增益以达到消除噪声的效果,继而再将消除噪声后的第一语音作为输出语音;通过对输入语音的处理,解决了将输入语音直接输出导致输出语音包含过多噪声使语音质量低的问题,提高了对讲终端输出语音质量。
技术特征:1.一种对讲终端的语音处理方法,其特征在于,包括:
2.如权利要求1所述的一种对讲终端的语音处理方法,其特征在于,所述降噪模型包括:活动语音检测子模型和增益子模型;
3.如权利要求2所述的一种对讲终端的语音处理方法,其特征在于,所述将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音,包括:
4.如权利要求1所述的一种对讲终端的语音处理方法,其特征在于,还包括:
5.如权利要求4所述的一种对讲终端的语音处理方法,其特征在于,所述根据回声消除算法对所述输入语音进行处理,生成消除回声的第二语音,包括:
6.一种对讲终端的语音处理装置,其特征在于,包括:语音获取模块、语音处理模块和语音输出模块;
7.如权利要求6所述的一种对讲终端的语音处理装置,其特征在于,所述降噪模型包括:活动语音检测子模型和增益子模型;
8.如权利要求7所述的一种对讲终端的语音处理装置,其特征在于,所述将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音,包括:
9.一种终端设备,其特征在于,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至5中任意一项所述的一种对讲终端的语音处理方法。
10.一种存储介质,其特征在于,所述存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述存储介质所在设备执行如权利要求1至5中任意一项所述的一种对讲终端的语音处理方法。
技术总结本发明公开了一种对讲终端的语音处理方法、装置、终端设备及存储介质。所述方法包括:获取对讲终端的输入语音;对所述输入语音进行检测,在检测到所述输入语音包含噪声时,将所述输入语音输入降噪模型中,以使所述降噪模型提取输入语音中的活动语音,并对所述活动语音进行增益,输出消除噪声的第一语音;根据所述第一语音确定输出语音,以使对讲终端输出所述输出语音。通过实施本发明能提高对讲终端输出语音质量。技术研发人员:郑桂鹏,张常华,阮胜林,明德,林弟受保护的技术使用者:广东保伦电子股份有限公司技术研发日:技术公布日:2024/2/6本文地址:https://www.jishuxx.com/zhuanli/20240618/21514.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表