一种轻量化多轴Transformer的单通道降噪方法
- 国知局
- 2024-06-21 11:28:47
本发明涉及降噪方法,尤其涉及一种轻量化多轴transformer的单通道降噪方法。
背景技术:
1、语音增强能够有效抑制环境噪声,提高语音信号的可理解性,是语音信号前端处理的关键任务。在语音通话和视频会议等互动过程中,经常会面临语音信号受到噪声干扰的问题,这严重影响了用户体验。为了改善这一情况,许多降噪解决方案已经被提出。目前的单通道语音增强方法存在的问题是对音频的时频特征分析不足,这会使得算法在复杂声学场景中性能大幅下降。同时,基于经典transformer结构的模型存在计算量大的缺点,特别是随着音频时长的增加,计算量会呈现指数增长,这会大幅提高模型对计算机资源的占用。
2、此外,在现有的transformer设计中,查询和键之间的所有相似性都用于特征聚合。然而,由于并非所有查询都与键相关,因此使用所有相似度不能有效地促进高效的语音信号增强。
技术实现思路
1、针对现有技术中存在的缺陷或不足,本发明所要解决的技术问题是:提供一种有效的轻量级动态多尺度自关注网络来解决单通道语音增强问题。具体而言,本文提出了一种简单而有效的多尺度时频特征分析方法,可以充分提取语音信号潜在的时频特征。
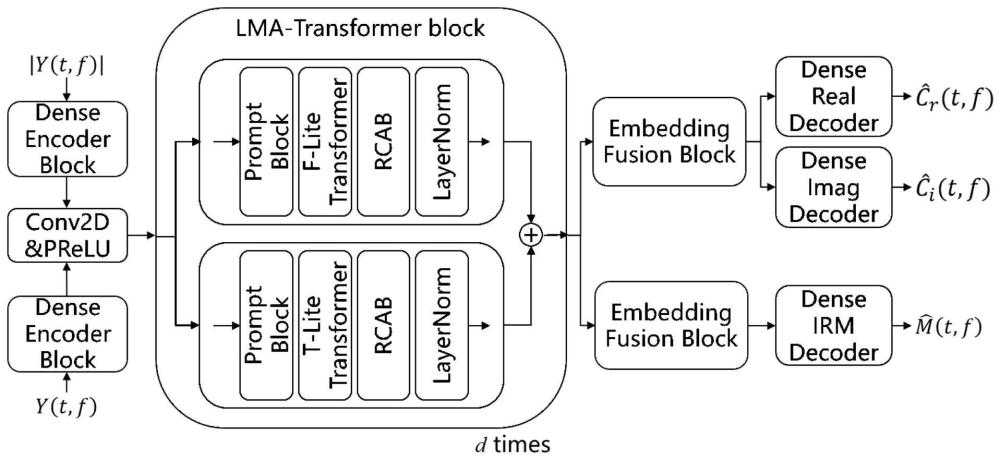
2、为了实现上述目的,本发明采取的技术方案为提供一种,语音轻量级多轴变压器transformer包括理想比例掩模和复数频谱补偿两个训练目标,将幅度谱特征|y(t,f)|和复谱特征y(t,f)传入到密集的编码器块(dense encoder block)中,其中t和f分别表示帧索引和频率点,密集的编码器块用于捕获低级特征,这些特征随后由提示块、轻量级多轴变压器和剩余通道注意块(residual channel attention block,rcab)进行处理,以提取高级特征。
3、作为本发明的进一步改进,嵌入融合块进一步提取和压缩这些高级特征,系统通过类似于密集编码块的密集解码块产生屏蔽值m(t,f)和补偿值c(t,f)。增强后的复谱可表示为:
4、
5、作为本发明的进一步改进,提示块(prompt block)用于促进改进的频率特征提取,提取计算如下,输入特征x通过全局平均池化转换为xgap,同时引入提示张量p,它是一个随机初始化的可学习张量,通过对xgap应用线性层,我们得到xlinear,softmax函数完成后,将xlinear与提示张量p相乘,得到pmul,pmul在第一维求和得到psum,通过sigmoid激活,我们得到频率特征提示张量,记为psigmoid,随后使用x进行元素乘法,然后进行二维卷积和残差拼接,从而产生频率提示模块的最终输出。
6、作为本发明的进一步改进,:采用低复杂度的时频多分离卷积头自注意对语音信号的时频进行分析,时间多分离卷积头自注意和频率多分离卷积头自注意,
7、时间多分离卷积头自注意计算方法如下,输入特征通过点向卷积在通道维度上进行扩展,使用深度可分离卷积和拆分操作来生成三个基本组件:查询、键和值,得到注意图;
8、拓展注意图,引入了一组可学习的参数,将注意图与值相乘,然后通过逐点卷积得到输出特征。
9、作为本发明的进一步改进,在整个训练过程中,loss函数使用了mse,其具体计算过程如式2所示:
10、mse=α·||sri-sri||2+β·||smag-smag||2 (2)
11、作为本发明的进一步改进,使用pesq、stoi、ssnr、csig、cbak和covl等指标评估模型性能。
12、本发明的有益效果是:本发明利用最有用的全局特征来促进语音信号的重构。本文提出的方法具有更少的网络参数和更低的计算成本,同时与最先进的方法相比,在语音信号的质量和可懂度方面具有竞争力。该算法的主要优点如下:(1)该方法可以充分提取语音信号潜在的时频特征,使模型在复杂声学环境下增强效果更好;(2)该方法提出一种轻量化transformer,能够有效降低计算机的资源消耗。(3)该方法提出一种提示块以使得模型更好学得频率特征信息。
技术特征:1.一种轻量化多轴transformer的单通道降噪方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的轻量化多轴transformer的单通道降噪方法,其特征在于:嵌入融合块进一步提取和压缩这些高级特征,系统通过类似于密集编码块的密集解码块产生屏蔽值m(t,f)和补偿值c(t,f)。增强后的复谱可表示为:
3.根据权利要求2所述的轻量化多轴transformer的单通道降噪方法,其特征在于:提示块(prompt block)用于促进改进的频率特征提取,提取计算如下,输入特征x通过全局平均池化转换为xgap,同时引入提示张量p,它是一个随机初始化的可学习张量,通过对xgap应用线性层,我们得到xlinear,softmax函数完成后,将xlinear与提示张量p相乘,得到pmul,pmul在第一维求和得到psum,通过sigmoid激活,我们得到频率特征提示张量,记为psigmoid,随后使用x进行元素乘法,然后进行二维卷积和残差拼接,从而产生频率提示模块的最终输出。
4.根据权利要求1所述的轻量化多轴transformer的单通道降噪方法,其特征在于:采用低复杂度的时频多分离卷积头自注意对语音信号的时频进行分析,时间多分离卷积头自注意和频率多分离卷积头自注意,
5.根据权利要求1所述的轻量化多轴transformer的单通道降噪方法,其特征在于:在整个训练过程中,loss函数使用了mse,其具体计算过程如式2所示:
6.根据权利要求1所述的轻量化多轴transformer的单通道降噪方法,其特征在于:使用pesq、stoi、ssnr、csig、cbak和covl等指标评估模型性能。
技术总结本发明涉及降噪方法,尤其涉及一种轻量化多轴Transformer的单通道降噪方法。可以充分提取语音信号潜在的时频特征。采用多头动态局部自关注模块高效提取局部特征。本文提出的方法具有更少的网络参数和更低的计算成本,同时与最先进的方法相比,在语音信号的质量和可懂度方面具有竞争力。可以充分提取语音信号潜在的时频特征,能够有效降低计算机的资源消耗。提示块以使得模型更好学得频率特征信息。技术研发人员:张泽华,王明江受保护的技术使用者:哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院)技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21737.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表