命令词识别方法及装置、计算机可读存储介质、终端与流程
- 国知局
- 2024-06-21 11:28:52
本发明实施例涉及语音识别,尤其涉及一种命令词识别方法及装置、计算机可读存储介质、终端。
背景技术:
1、随着语音处理技术的发展,关键词识别技术在越来越多的交互场景中被应用。具备命令词识别功能的终端通过一系列的音频预处理、编解码操作生成脉冲编码调制(pulsecode modulation,pcm)数据,经过关键词识别模块识别出关键词,再通过后处理将其转换为对应的控制信号。例如,在智能座舱场景中,用户发出语音控制命令,如“拨打电话”,通过关键词识别后,将其转换为对应的控制信号,即可实现拨打电话的功能,为用户行车提供方便快捷的体验。
2、目前,通常结合声学模型、语言模型、发音词典用维特比算法(viterbi)算法进行语音识别解码,并获取多条最优(nbest)路径,每条最优路径对应一条语音识别候选结果,从多条最优路径中选取最合理的路径。
3、然而,由于命令词识别的应用场景的不同、环境噪声以及相近词等影响,易出现命令词误识,导致命令词结果的虚警率较高。
技术实现思路
1、本发明实施例解决的技术问题是现有的命令词识别中易出现命令词误识,导致命令词结果的虚警率较高。
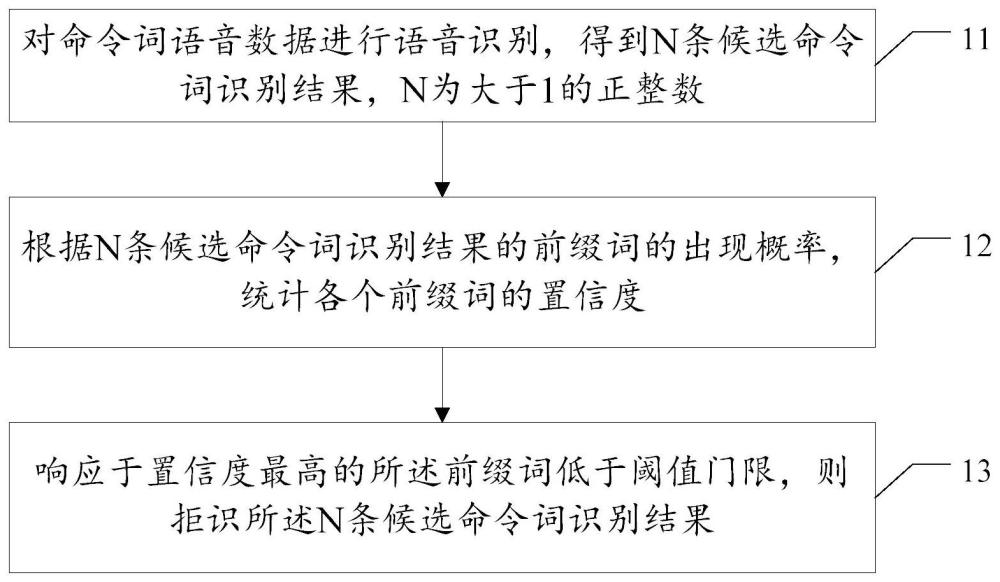
2、为解决上述技术问题,本发明实施例提供一种命令词识别方法,包括:对命令词语音数据进行语音识别,得到n条候选命令词识别结果,n为大于1的正整数;根据n条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度;响应于置信度最高的所述前缀词小于阈值门限,则拒识所述n条候选命令词识别结果。
3、可选的,所述根据n条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度,包括:根据每条候选命令词识别结果的识别输出概率,计算每条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率;对n条候选命令词识别结果的前缀词进行对齐操作,得到对齐结果,所述对齐结果用于表征各条候选命令词识别结果的前缀词是否相同;根据所述对齐结果以及每条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率,将相同的前缀词的出现概率进行累加,基于累加结果得到各个前缀词的置信度。
4、可选的,所述对n条候选命令词识别结果的前缀词进行对齐,包括:在对n条候选命令词识别结果的前缀词进行对齐操作时,响应于第一候选命令词识别结果的前缀词被第二候选命令词识别结果的前缀词包含,则将所述第一候选命令词识别结果的前缀词和前缀词后的词作为第一词组,将所述第二候选命令词识别结果的前缀词和前缀词后的词作为第二词组,将第一词组和第二词组进行对齐操作;响应于所述第一词组和所述第二词组完全对齐,则判定所述第一候选命令词识别结果的前缀词与所述第二候选命令词识别结果的前缀词相同。
5、可选的,所述对n条候选命令词识别结果的前缀词进行对齐操作,包括:采用构建混淆网络算法或者动态规划算法对所述n条候选命令词识别结果的前缀词进行对齐操作。
6、可选的,所述根据每条候选命令词识别结果的识别输出概率,计算每条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率,包括:采用如下公式计算每条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率;pj=exp(scorej)/sum(exp(scorej));其中,pj为第j条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率;exp(scorej)为第j条候选命令词识别结果的前缀词的出现概率,1≤j≤n;sum(exp(scorej))为n条候选命令词识别结果的前缀词的出现概率之和。
7、可选的,所述阈值门限包括:设定阈值或者所述n条候选命令词识别结果的前缀词的最大出现概率。
8、本发明实施例还提供一种命令词识别装置,包括:语音识别单元,用于对命令词语音数据进行语音识别,得到n条候选命令词识别结果,n为大于1的正整数;置信度确定单元,用于根据n条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度;拒识单元,用于响应于置信度最高的所述前缀词小于阈值门限,则拒识所述n条候选命令词识别结果。
9、本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行上述任一种命令词识别方法的步骤。
10、本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述任一种命令词识别方法的步骤。
11、与现有技术相比,本发明实施例的技术方案具有以下有益效果:
12、对命令词语音数据进行语音识别得到的n条候选命令词识别结果,根据n条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度,根据置信度最高的前缀词与阈值门限的关系,对n条候选命令词识别结果进行抑制或裁剪。若置信度最高的所述前缀词小于阈值门限的,则表征n条候选命令词识别结果的歧义较大,拒识n条候选命令词识别结果。如此,能够对置信度低于阈值门限的命令词识别结果进行抑制或裁剪,实现对命令词识别结果的修正,以降低虚警率。
技术特征:1.一种命令词识别方法,其特征在于,包括:
2.如权利要求1所述的命令词识别方法,其特征在于,所述根据n条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度,包括:
3.如权利要求2所述的命令词识别方法,其特征在于,所述对n条候选命令词识别结果的前缀词进行对齐,包括:
4.如权利要求2所述的命令词识别方法,其特征在于,所述对n条候选命令词识别结果的前缀词进行对齐操作,包括:
5.如权利要求2所述的命令词识别方法,其特征在于,所述根据每条候选命令词识别结果的识别输出概率,计算每条候选命令词识别结果的前缀词在n条候选命令词识别结果的前缀词中的出现概率,包括:
6.如权利要求1所述的命令词识别方法,其特征在于,所述阈值门限包括:设定阈值或者所述n条候选命令词识别结果的前缀词的最大出现概率。
7.一种命令词识别装置,其特征在于,包括:
8.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器运行时执行权利要求1至6任一项所述的命令词识别方法的步骤。
9.一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,其特征在于,所述处理器运行所述计算机程序时执行权利要求1至6任一项所述的命令词识别方法的步骤。
技术总结本公开提供一种命令词识别方法及装置、计算机可读存储介质、终端,所述命令词识别方法包括:对命令词语音数据进行语音识别,得到N条候选命令词识别结果,N为大于1的正整数;根据N条候选命令词识别结果的前缀词的出现概率,统计各个前缀词的置信度;响应于置信度最高的所述前缀词小于阈值门限,则拒识所述N条候选命令词识别结果。上述方案能够对置信度低于阈值门限的命令词识别结果进行抑制或裁剪,实现对命令词识别结果的修正,以降低虚警率。技术研发人员:刘志忠受保护的技术使用者:展讯通信(上海)有限公司技术研发日:技术公布日:2024/2/19本文地址:https://www.jishuxx.com/zhuanli/20240618/21756.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表