一种海南方言语音识别系统及装置
- 国知局
- 2024-06-21 11:29:38
本发明涉及语音识别,特别涉及一种海南方言语音识别系统及装置。
背景技术:
1、汉语方言不仅代表着一种文字符号,更承载着深厚的中华文化。因此,针对构成方言保护核心环节的方言语音识别研究具有重要的现实意义。通常,汉语方言分为北方方言、粤方言等七大方言,也包含了海南省境内的海南方言。由于地域和文化差异,海南省境内的海南方言在发音和语法上都存在一定的差异,跨越片区的方言互通程度仍然比较低。加上大规模方言语音语料库的采集和人工标注成本非常高,研究人员早期聚焦于带方言口音的普通话语音识别,这些传统模型主要基于概率模型或距离度量方法。
2、此外,也有部分利用传统特征工程方法进行方言语音识别,如自动抽取并构建方言中的多发音词典,并将该词典用于方言语音识别;或提出基于hmm(hidden markovmodel)的方言语音识别系统,由于传统特征工程方法成本太高,近期深度学习方法能够自动抽取语义特征,提升方言语音识别性能。
3、然而现有深度学习模型缺乏考虑方言语音中特定方言音素的重要性,同时对多种语音特征提取及融合方面比较为鲜见,导致方言语音识别性能仍然不高。实际上,方言本身特定的音素串(发音底层特征)有利于方言语音识别。
技术实现思路
1、本发明提供了一种海南方言语音识别系统及装置,利用残差网络(residualnetwork)和bi-lstm(bi-directional long short-term memory)分别在语音帧内和帧间特征提取的优势,并采用多头自注意力机制有效提取不同方言中特定方言音素信息构成语音发音底层特征,利用该方言发音底层特征进行方言语音识别;能够有效提取不同方言特有的音素串发音底层特征,同时多种语音特征的融入使得方言语音识别性能得到大幅度提升。
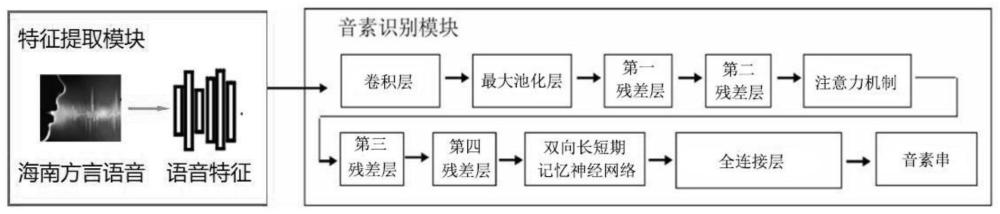
2、本发明提供了一种海南方言语音识别系统,包括特征提取模块和音素识别模块;
3、所述特征提取模块通过对原始海南方言语音提取出各种语音特征,所述音素识别模块将所述语音特征依次通过卷积神经网络、残差网络、多头注意力机制以及长短期记忆网络组合而成的声学模型得到发音底层特征,再通过全连接层映射到合适的维度,生成音素串;
4、经过ctc损失函数计算预测的音素串与真实的音素串的差值,并通过ad-am算法对模型中的参数进行优化,得到音素错误率;
5、根据所述发音底层特征,利用海南方言发音底层特征进行方言语音识别。
6、进一步地,所述语音特征包括fbank特征和log-mels特征;
7、所述fbank特征的获取过程为:首先对输入采样频率为16khz的音频预加重并去除直流偏移,然后选用分帧窗口大小为25ms且帧移为10ms的单位分帧,经过汉明窗处理,并通过离散傅里叶变换,利用23个滤波器组成的滤波器组处理得到梅尔频谱,并获取到80维的fbank特征;
8、所述log-mels特征的获取过程为:通过分帧和加窗操作后,然后进行快速傅里叶变换,得到频域方面的信息,并且通过堆叠所有频域信号可以获取声谱图,再取对数后,得到更加具有辨识度log-mels特征。
9、进一步地,所述音素识别模块接收fbank特征和log-mels特征的组合作为输入,采用一个残差网络提取语音更抽象的局部特征,再利用一个多头自注意力层抽取每一帧语音与其他帧的关系,然后利用一个全连接层将音素映射到设定维度,最后采用ctc损失函数计算预测的音素串与真实音素串的差异,输出对应的音素串;
10、将多头注意力层加在第二个残差层后,残差网络经过四个残差层结构可以提取语音抽象的局部特征。
11、进一步地,所述多头自注意力层采用自注意力机制,所述自注意力机制使用标准的点积注意力,多头自注意力是重复执行多次单个注意力,会产生h个q,k和v;其中q和k的维度大小为dk,v的维度大小为dv。
12、进一步地,计算注意力权重的公式为:
13、
14、其中,查询向量q和键向量k的维度都是dk,值向量v的长度是dv。
15、进一步地,向量的生成过程的公式为:
16、multihead(q,k,v)=concat(head1,...,headh)wo
17、
18、其中,h是自注意力头的个数,dmodel是模型的总体维度。
19、进一步地,所述ctc损失函数为:ctc通过扩展模型的输出层,建立标签和输出文本的对应关系,直接对输入的语音特征进行训练,达到输出的序列在概率上最大化,采用adam极大化公式所示的似然函数。
20、进一步地,采用的adam极大化公式所示的似然函数为:
21、
22、其中,(x,z)∈s表示训练实例,x代表输入的语音特征序列,z代表音素串,每个训练样本可以用一个元组(x,z)表示。
23、本发明还提供了一种海南方言语音识别装置,基于如上所述的海南方言语音识别系统,其特征在于,还包括海南方言获取模块、方言语音识别输出模块和语音播放模块,所述海南方言获取模块用于获取海南方言以进行语音特征提取,所述方言语音识别输出模块用于输出所述海南方言语音的识别结果,所述语音播放模块用于根据海南方言语音的识别结果进行语音播放。
24、本发明的有益效果为:
25、本发明提取了多种语音特征,并利用深度学习模型将两者集成;模型首先利用残差网络(residual network)和bi-lstm(bi-di-rectional long short-term memory)提取帧内和帧间的语音特征,然后利用多头自注意力机制(multi-head attention)有效提取不同方言特有的音素串信息构成语音发音底层特征,并利用ctc(connection-ist temporalclassification)计算音素损失,进行方言语音识别。引入多头自注意力机制能够有效提取不同方言特有的音素串发音底层特征,同时多种语音特征的融入使得方言语音识别性能得到大幅度提升。
技术特征:1.一种海南方言语音识别系统,其特征在于,包括特征提取模块和音素识别模块;
2.根据权利要求1所述的海南方言语音识别系统,其特征在于:所述语音特征包括fbank特征和log-mels特征;
3.根据权利要求2所述的海南方言语音识别系统,其特征在于,所述音素识别模块接收fbank特征和log-mels特征的组合作为输入,采用一个残差网络提取语音更抽象的局部特征,再利用一个多头自注意力层抽取每一帧语音与其他帧的关系,然后利用一个全连接层将音素映射到设定维度,最后采用ctc损失函数计算预测的音素串与真实音素串的差异,输出对应的音素串;
4.根据权利要求3所述的海南方言语音识别系统,其特征在于,所述多头自注意力层采用自注意力机制,所述自注意力机制使用标准的点积注意力,多头自注意力是重复执行多次单个注意力,会产生h个q,k和v;其中q和k的维度大小为dk,v的维度大小为dv。
5.根据权利要求4所述的海南方言语音识别系统,其特征在于,计算注意力权重的公式为:
6.根据权利要求5所述的海南方言语音识别系统,其特征在于,向量的生成过程的公式为:
7.根据权利要求3所述的海南方言语音识别系统,其特征在于,所述ctc损失函数为:ctc通过扩展模型的输出层,建立标签和输出文本的对应关系,直接对输入的语音特征进行训练,达到输出的序列在概率上最大化,采用adam极大化公式所示的似然函数。
8.根据权利要求7所述的海南方言语音识别系统,其特征在于,采用的adam极大化公式所示的似然函数为:
9.一种海南方言语音识别装置,基于权利要求1-8中任一项所述的海南方言语音识别系统,其特征在于,还包括海南方言获取模块、方言语音识别输出模块和语音播放模块,所述海南方言获取模块用于获取海南方言以进行语音特征提取,所述方言语音识别输出模块用于输出所述海南方言语音的识别结果,所述语音播放模块用于根据海南方言语音的识别结果进行语音播放。
技术总结本发明涉及语音识别技术领域,公开了一种海南方言语音识别系统,包括特征提取模块和音素识别模块;特征提取模块通过对原始海南方言语音提取出各种语音特征,音素识别模块将所述语音特征依次通过卷积神经网络、残差网络、多头注意力机制以及长短期记忆网络组合而成的声学模型得到发音底层特征,通过全连接层映射到合适的维度,生成音素串;经过CTC损失函数计算预测的音素串与真实的音素串的差值,通过Ad‑am算法对模型中的参数进行优化,得到音素错误率;根据发音底层特征,利用海南方言发音底层特征进行方言语音识别。本发明能够有效提取不同方言特有的音素串发音底层特征,同时多种语音特征的融入使得方言语音识别性能得到大幅度提升。技术研发人员:王忠,曹春杰,王艺臻,张良峰,王昱陈曲,谢夏,符龙生,林丽姝受保护的技术使用者:海南大学技术研发日:技术公布日:2024/2/21本文地址:https://www.jishuxx.com/zhuanli/20240618/21829.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表