远场语音识别方法、装置、冰箱及存储介质与流程
- 国知局
- 2024-06-21 11:30:05
本发明涉及计算机,具体地涉及一种远场语音识别方法、装置、冰箱及存储介质。
背景技术:
1、在智能家居应用中,随着语音交互的普及,用户常常以语音形式提问,但多模态环境下的语音数据中常混杂着环境噪声和其他声音,造成语音识别的困难。
2、比如“今天冰箱里还有多少个鸡蛋”,“今天冰箱里还有多个松花蛋”,在这两个句子里极有可能出现漏字错字比如“划蛋、滑蛋”,造成原因就是在编码阶段出现冗余信号、提取有效语音特征不是最佳。结合当前智能家居至少带有二个麦克风阵列,因此利用这些软硬件充分挖掘智能冰箱多源异构语音数据、数据间及数据级联之间的语音信号关系或提取有效语音特征来降低远程识别字错误率。但是现有技术发明专利都未涉及到远程语音识别在智能家居比如智能冰箱人机交互或智能交互、信息获取分发等从前端编码前消除冗余语音信号维度解决所述的问题。首先,有些方法仅仅端到端的编码-解码框架进行远程语音识别,而忽视了编码阶段前的有效语音特征提取;其次,虽然对前端编码前采用回声消除、或端点检测vad方法,但是忽视了对冗余信号过度处理即把有用的语音信号进行处理,导致比如输出端语音识别准确率低等问题;再次,有些方法未考虑语音信号的多通道多尺寸等因素,包括远程识别时在编码时存在时序、或语音信号前后序列关系,这些方法未提高远程识别准确率存在局限性。
3、远总而言之,场语音识别存在信号冗余影响语音识别准确率较低、字错误率高的核心问题,过往远程识别方法忽视了前端处理前对冗余的语音信号进行处理比如消除无用冗余信号,造成前端编码有效信号不是最佳的,因此有必要进一步对远程语音识别前端编码前的冗余语音信号采用有效方法提升智能家居如智能冰箱人机交互的便捷性及降低语音识别字错误率等问题。
技术实现思路
1、本发明的目的在于提供一种远场语音识别方法、装置、冰箱及存储介质。
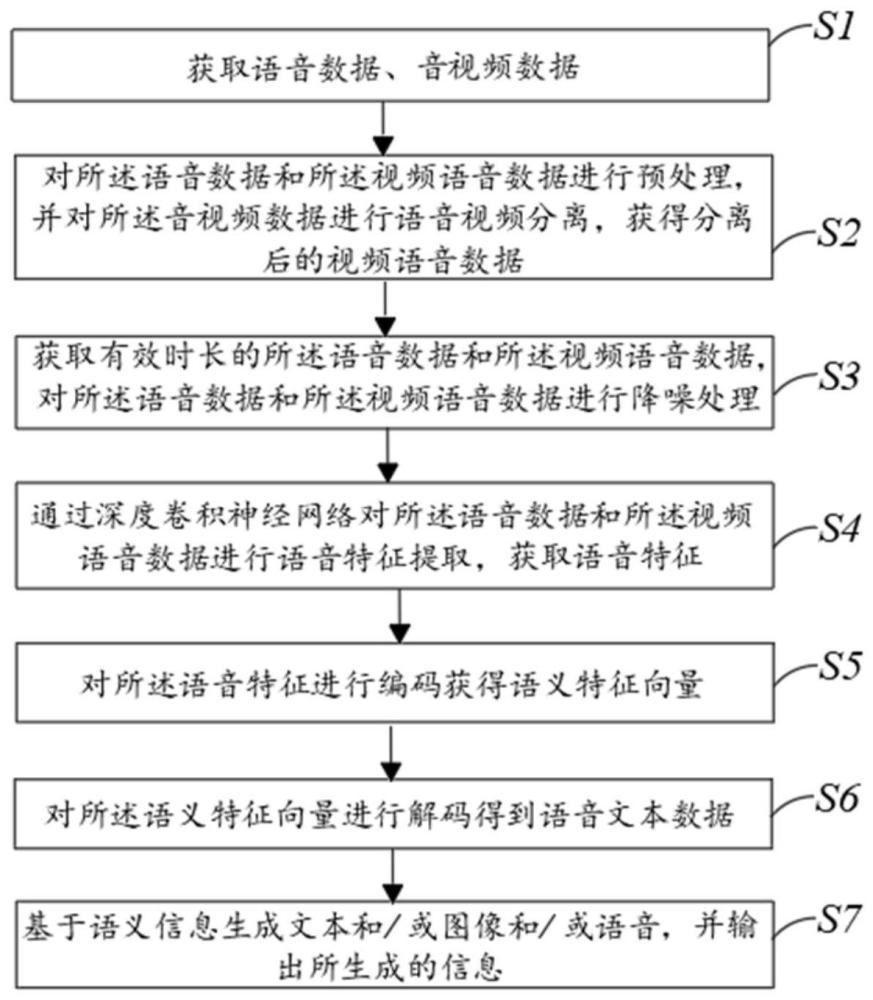
2、本发明提供一种远场语音识别方法,其包括步骤:
3、获取语音数据、音视频数据;
4、对所述语音数据和所述音视频数据进行预处理,并对所述音视频数据进行语音视频分离,获得分离后的视频语音数据;
5、获取有效时长的所述语音数据和所述视频语音数据,对所述语音数据和所述视频语音数据进行降噪处理;
6、通过深度卷积神经网络对所述语音数据和所述视频语音数据进行语音特征提取,获取语音特征;
7、对所述语音特征进行编码获得语义特征向量;
8、对所述语义特征向量进行解码得到语音文本数据;
9、基于语义信息生成文本和/或图像和/或语音,并输出所生成的信息。
10、作为本发明的进一步改进,所述对所述语音数据和所述视频语音数据进行降噪处理,具体包括:
11、通过双向长短时记忆网络基于所述语音数据和所述视频语音数据前后序列关系和上下文信息消除所述视频语音数据的回声和噪声。
12、作为本发明的进一步改进,在处理后获取有效时长的所述语音数据和所述视频语音数据后,还包括:
13、对所述语音数据和所述视频语音数据进行过滤,筛除部分冗余语音信号。
14、作为本发明的进一步改进,所述对所述语音特征进行编码获得语义特征向量,具体包括:
15、通过wav2vec模型将所述语音特征进行编码获得语义特征向量。
16、作为本发明的进一步改进,所述对所述语义特征向量进行解码得到语音文本数据,具体包括:
17、通过多层transformer深度网络模型对所述语义特征向量进行解码得到语音文本数据。
18、作为本发明的进一步改进,所述对所述语音数据和音视频数据进行预处理,包括:
19、对所述语音数据和音视频数据进行数据清洗、格式转化及存储任务。
20、作为本发明的进一步改进,所述基于语义信息生成文本和/或图像和/或语音具体包括:
21、基于语义信息生成文本,和/或
22、基于语义信息采用clip模型方法生成图像,和/或
23、基于语义信息采用波形拼接和端到端神经网络模型生成语音。
24、作为本发明的进一步改进,所述获取语音数据、音视频数据,具体包括:
25、获取语音采集装置所采集的所述语音数据,和/或
26、获取自客户终端传输的所述语音数据;
27、获取语音采集装置所采集的所述音视频数据,和/或
28、获取自客户终端传输的所述音视频数据。
29、作为本发明的进一步改进,所述输出所生成的信息,具体包括:
30、将所述生成的文本和/或图像和/或语音直接输出,和/或
31、将所述生成的文本和/或图像和/或语音传输至客户终端输出。
32、本发明还提供一种远场语音识别装置,其包括:
33、数据获取模块,用于获取语音数据、音视频数据;
34、语音数据处理模块,用于对所述语音数据和所述音视频数据进行预处理,并对所述音视频数据进行语音视频分离,获得分离后的视频语音数据;获取有效时长的所述语音数据和所述视频语音数据,对所述语音数据和所述视频语音数据进行降噪处理;通过深度卷积神经网络对所述语音数据和所述视频语音数据进行语音特征提取,获取语音特征;
35、编码模块,用于对所述语音特征进行编码获得语义特征向量;
36、解码模块,用于对所述语义特征向量进行解码得到语音文本数据;
37、结果生成和输出模块,基于语义信息生成文本和/或图像和/或语音,并输出所生成的信息。
38、作为本发明的进一步改进,所述语音数据处理模块通过双向长短时记忆网络基于所述语音数据和所述视频语音数据前后序列关系和上下文信息消除所述视频语音数据的回声和噪声。
39、作为本发明的进一步改进,语音数据处理模块还被用于对所述语音数据和所述视频语音数据进行过滤,筛除部分冗余语音信号。
40、作为本发明的进一步改进,所述编码模块通过wav2vec模型将所述语音特征进行编码获得语义特征向量。
41、作为本发明的进一步改进,所述解码模块通过多层transformer深度网络模型对所述语义特征向量进行解码得到语音文本数据。
42、作为本发明的进一步改进,所述结果生成和输出模块基于语义信息生成文本,和/或基于语义信息采用clip模型方法生成图像,和/或基于语义信息采用波形拼接和端到端神经网络模型生成语音。
43、作为本发明的进一步改进,所述数据获取模块被配置用于获取语音采集装置所采集的所述语音数据,和/或获取自客户终端传输的所述语音数据;获取语音采集装置所采集的所述音视频数据,和/或获取自客户终端传输的所述音视频数据。
44、作为本发明的进一步改进,所述结果生成和输出模块被配置用于将所述生成的文本和/或图像和/或语音直接输出,和/或将所述生成的文本和/或图像和/或语音传输至客户终端输出。
45、本发明还提供一种冰箱,其包括:
46、存储器,用于存储可执行指令;
47、处理器,用于运行所述存储器存储的可执行指令时,实现上述的远场语音识别方法。
48、本发明还提供一种计算机可读存储介质,其特征在于,其存储有可执行指令,所述可执行指令被处理器执行时实现上述的远场语音识别方法。
49、本发明的有益效果是:本发明通过数据采集、清洗、回声与噪声消除、深度神经网络特征提取等步骤,从而在编码前端有效降低冗余信号,提升语音质量,增强语音的可懂度与准确性,配合后续的语义编码和解码过程,以及多媒体的展示信息生成方式,提升了智能冰箱等智能家居设备的用户体验和性能。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21886.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表