一种基于多通道盲辨识和多通道均衡的语音去混响方法
- 国知局
- 2024-06-21 11:32:19
本发明属于语音去混响,更为具体地讲,涉及一种基于多通道盲辨识和多通道均衡的语音去混响方法。
背景技术:
1、盲辨识是仅仅利用系统输出信号估计系统的脉冲响应的方法,在语音降噪、波束形成、语音去混响和声源定位等语音处理技术中扮演着重要角色。近年来,学者们针对这一问题对批处理算法和自适应算法进行了广泛研究。在这些算法中,归一化多通道频域最小均方算法(nmcflms)使用快速傅里叶变换(fft)在频域实现,具有计算效率高的特点,因此该算法在实时处理系统中具有特殊的吸引力。同时,为了加快自适应滤波器的收敛速度和减小由于信道输出幅度大而引起的梯度噪声放大问题,该算法使用了牛顿迭代法。众所周知,牛顿迭代法作为一种优化方法,其中的hessian矩阵的正则化至关重要。然而nmcflms算法仅仅利用系统输出的第一个块信号构造正则化因子,由此导致该算法在不同语音段以及不同信噪比环境下的正则化因子差别很大,难以获得一个合适的正则化参数。
2、针对hessian矩阵的正则化问题,学者们已提出大量的解决方案,其中最经典的方法是通过修正牛顿法的搜索方向,使其偏向最速下降方向。该策略可通过在hessian矩阵中加入一个合适的数量矩阵予以实现。在自适应滤波算法中,引入正则化参数不仅可确保数值稳定,还可增强滤波器的收敛性能。近年来已有大量正则化方法被提出,在这些方法中,一类是常数正则化方法即正则化参数在滤波器迭代过程中不会更新,利用激励信号的相关信息和信噪比的信息来确定最优的正则化参数,使得自适应滤波器在噪声环境下具有更好的鲁棒性,但实际上这种常数正则化方法是在滤波器的收敛速度和稳态误差间作了一个折中。另一类是可变正则化方法即正则化参数在滤波器迭代过程中实时利用相关数据信息,包括误差信号、估计噪声和系统输入等信息,由于可变正则化方法的实时性,这类方法比常数正则化方法具有更快的收敛速度。然而对于盲系统辨识,由于输入信号的不可获得以及系统的时变特性,现有方法并不能直接应用于时变系统的盲辨识问题。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于多通道盲辨识和多通道均衡的语音去混响方法,设计一种可变正则化函数,将信噪比、输出信号能量和滤波器长度信息融入其中,使对加性噪声、语音的非平稳性具有鲁棒性,在时变条件下具有更好的跟踪性能,在噪声环境下能获得更快的收敛速度和跟踪速度,能使基于通道均衡的语音去混响获得更好的去混响效果,尤其是在低信噪比环境下自适应滤波器处于暂态期间,去混响性能显著提升。
2、为实现上述发明目的,本发明基于多通道盲辨识和多通道均衡的语音去混响方法,其特征在于,包括以下步骤:
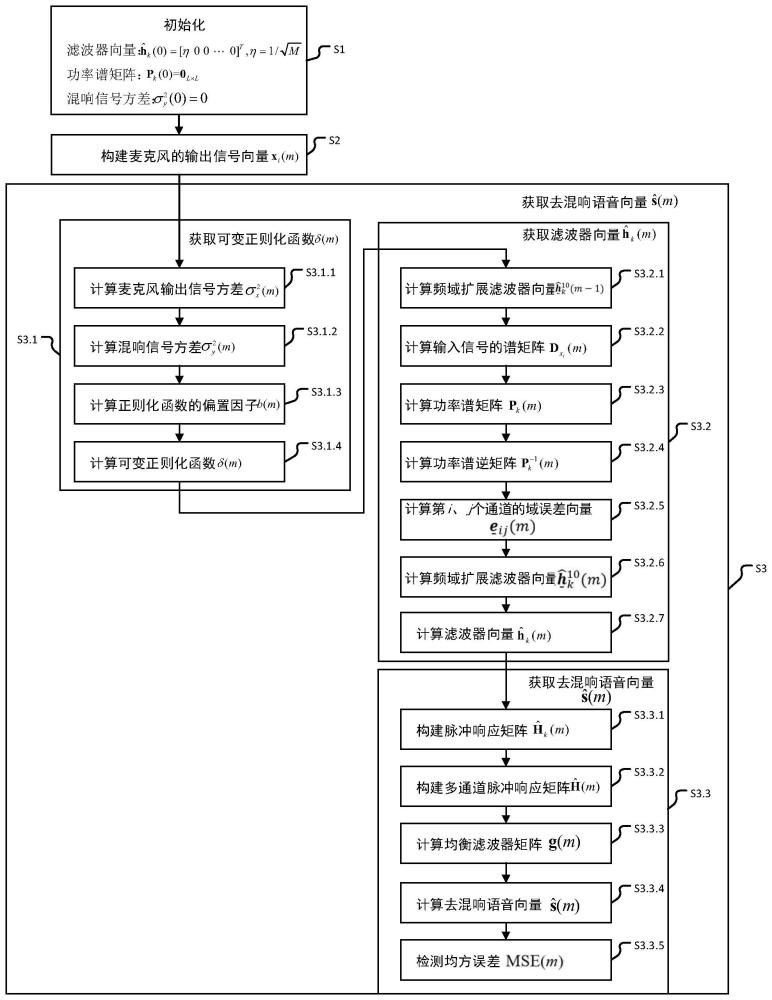
3、(1)、初始化
4、初始化第k个通道0时刻的长度为l的滤波器向量为:
5、
6、其中,t表示转置,m为通道数量,l为是声通道脉冲响应向量的长度;
7、初始化第k个通道0时刻的功率谱矩阵pk(0)为:
8、pk(0)=0l×l
9、初始化混响信号方差为:
10、
11、(2)、对m只麦克风声信号进行采集,其中,第i个通道的采样值表示为xi(n),i=1,2,…,m,n=0,1,2,…,n为采样点时间索引,并构建块时间索引m对应的声信号向量xi(m),i=1,2,...,m即第i只麦克风的输出信号向量:
12、xi(m)=[xi(ml-l)xi(ml-l+1)…xi(ml+l-1)]t
13、(3)、从块时间索引m=1开始,获取去混响语音向量
14、3.1)、获取可变正则化函数δ(m)
15、3.1.1)、计算麦克风输出信号方差
16、
17、其中,||·||2表示向量的2范数,是一个平滑因子;
18、3.1.2)、计算混响信号方差
19、
20、其中,λ1为遗忘因子,snr为输出信噪比;
21、3.1.3)、计算正则化函数的偏置因子b(m):
22、
23、其中,v表示系数因子;
24、3.1.4)、计算可变正则化函数δ(m):
25、
26、其中,α为控制函数曲线整体范围的参数,k为控制曲线陡度的参数,该值越大曲线突变处越陡,ξ为控制曲线升降点位置的参数,初始值为ξ0;
27、3.2)、获取滤波器向量
28、3.2.1)、计算频域扩展滤波器向量
29、
30、其中,f2l×2l是大小为2l×2l的傅里叶矩阵,0为长度为l的零列向量;
31、3.2.2)、计算输入信号的谱矩阵
32、
33、其中,diag[·]表示将向量展开成对角阵;
34、3.2.3)、计算功率谱矩阵pk(m):
35、
36、其中,λ2为遗忘因子,上标*表示共轭矩阵;
37、3.2.4)、计算功率谱逆矩阵
38、
39、其中,i2l×2l是大小为2l×2l的单位矩阵;
40、3.2.5)、计算第i、j个通道的频域误差向量
41、
42、其中,fl×l是大小为l×l的傅里叶矩阵,0l×l是大小为l×l的零矩阵,il×l是大小为l×l的单位矩阵,是大小为2l×2l的傅里叶逆矩阵;
43、3.2.6)、计算频域扩展滤波器向量
44、
45、其中,ρ为自适应滤波器步长因子,频域拓展误差向量是大小为2l×2l的傅里叶矩阵,是大小为l×l的傅里叶逆矩阵;
46、3.2.7)、计算滤波器向量
47、
48、其中,下标1:l表示取前l个值;
49、3.3)、获取去混响语音向量
50、3.3.1)、构建脉冲响应矩阵
51、
52、其中:脉冲响应矩阵为大小lc×lg的矩阵,lc=l+lg-1,lg为均衡滤波器向量长度;
53、3.3.2)、构建多通道脉冲响应矩阵
54、
55、3.3.3)、计算均衡滤波器矩阵g(m)
56、
57、其中为第k个通道的均衡滤波器向量,d为期望的均衡脉冲响应向量;
58、3.3.4)、计算去混响语音向量
59、
60、其中,conv(·)表示卷积函数;
61、3.3.5)、检测均方误差mse(m)
62、首先计算均方误差mse(m):
63、
64、其中,上标h表示共轭转置,然后更新判断:
65、如果mse(m)大于阈值上限γ,则启动进行可变正则化函数δ(m)的刷新,令参数ξ=m+ξ0,其中,ξ0是设定的一个初值,如果mse(m)不大于阈值上限γ,则参数ξ维持不变;
66、m=m+1,返回步骤3.1.1进行下一个块时间的混响语音向量的计算。
67、本发明的发明目的是这样实现的:
68、本发明提出了一种基于多通道盲辨识和多通道均衡的语音去混响方法,对多通道盲辨识问题,在归一化多通道频域最小均方算法(nmcflms)的基础上,设计了一种可变正则化函数,将信噪比、输出信号能量和滤波器长度信息融入其中,使算法对加性噪声、语音的非平稳性具有鲁棒性。此外,为了使所提方法在时变条件下具有更好的跟踪性能,提出了一种根据均方误差对正则化参数刷新的机制。这样,在噪声环境下能获得更快的收敛速度和跟踪速度,能使基于通道均衡的语音去混响获得更好的去混响效果,尤其是在低信噪比环境下自适应滤波器处于暂态期间,去混响性能显著提升。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22084.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表