一种基于TinyML与ChatGPT的智能检测方法与流程
- 国知局
- 2024-06-21 11:33:29
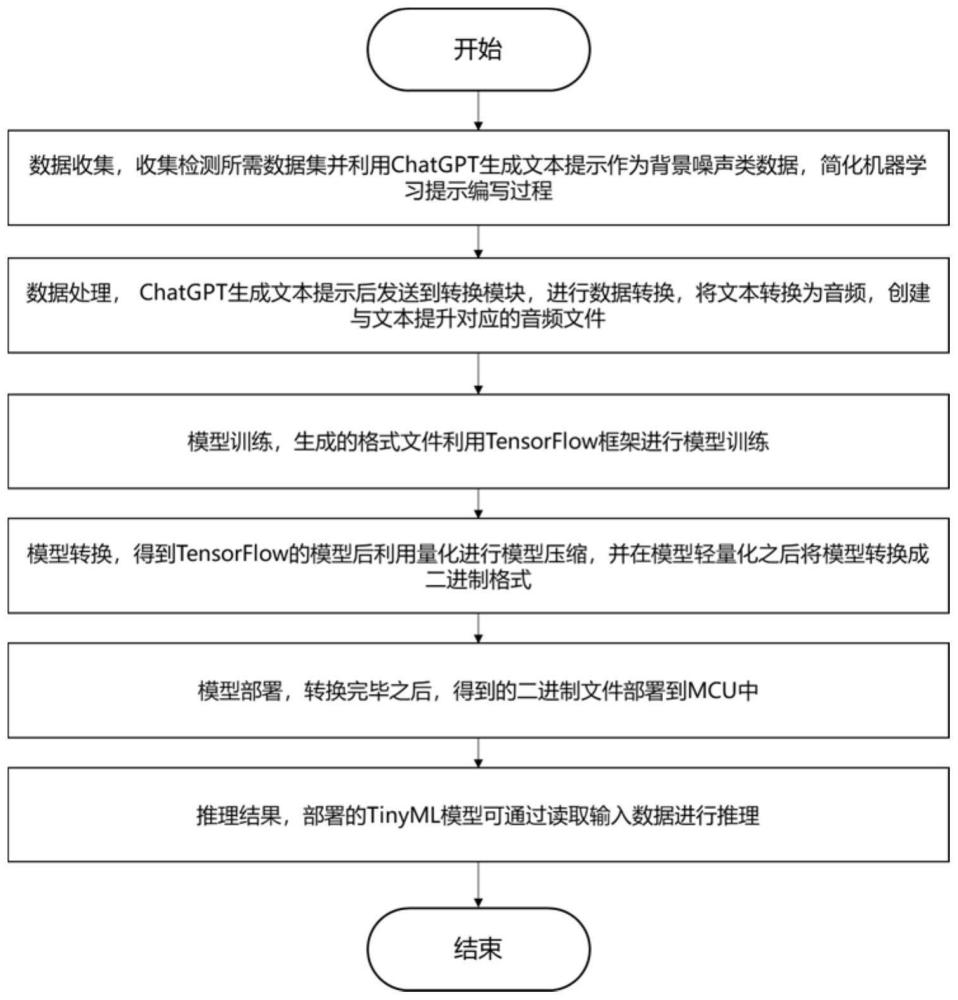
本发明涉及计算机数据处理,具体来说是一种基于tinyml与chatgpt的智能检测方法。
背景技术:
1、在当今的信息化社会,音频检测技术在众多领域都发挥着至关重要的作用,如智能家居控制、安防监控、医疗健康等。传统的音频检测技术主要基于手工特征提取和经典机器学习算法,这种方法在大多数标准化场景中表现尚可。然而,随着物联网设备和嵌入式设备的普及,对于实时、高效和准确的音频检测提出了新的要求。
2、然而,现有的技术存在以下主要不足:
3、1.数据依赖性:传统方法高度依赖于大量的真实数据样本。在很多实际应用中,尤其是新兴的应用场景,相关的真实数据难以获取,这导致模型训练的困难和泛化能力的不足。
4、2.计算资源限制:众多先进的音频检测算法和模型需要高昂的计算成本。这些模型在资源丰富的环境下可能运行流畅,但在资源受限的嵌入式或物联网设备上则面临巨大挑战。
5、3.数据生成技术的局限性:尽管有尝试利用文本到音频的转换工具生成模拟数据,但由于这些数据与真实场景存在差异,可能导致模型在实际应用中的效果不佳。
技术实现思路
1、本发明的主要目的在于提供一种基于tinyml与chatgpt的智能检测方法,可以有效解决背景技术中所涉及的问题。
2、为实现上述目的,本发明采取的技术方案为:
3、一种基于tinyml与chatgpt的智能检测方法,包括以下步骤:
4、s1:利用chatgpt生成文本数据,并通过文本到音频的转换工具将文本转换为音频文件,形成数据集;
5、s2:利用tensorflow框架对所述数据集进行机器学习模型的训练;
6、s3:利用模型轻量化技术转换所述机器学习模型的格式,并将其部署到微控制器上;
7、s4:通过微控制器读取实时音频输入数据进行推理,输出分类结果。
8、进一步的,所述文本数据包括由chatgpt根据提供的文本提示生成的文本。
9、进一步的,所述文本到音频的转换工具为audioldm。
10、进一步的,所述机器学习模型的训练使用tensorflow框架进行。
11、进一步的,来自麦克风的实时音频输入被传输至微控制器模块,模型读取输入数据进行推理,并根据需求添加触发操作。
12、进一步的,所述基于tinyml与chatgpt的智能检测方法进一步包括:利用chatgpt生成一些与原始数据集相似的新样本,并将其添加到训练数据集中以增强模型的泛化能力。
13、进一步的,所述数据集包含大量音频样本,每个样本都有一个类标签,用于识别声音的类型。
14、与现有技术相比,本发明专利具有如下有益效果:
15、1.高效的数据生成:通过利用chatgpt生成文本数据并将其转换为音频文件,本发明能够快速且高效地生成大量与真实场景相似的数据。这不仅大大简化了数据收集和标注的过程,还确保了生成数据的真实性和多样性,从而提高模型的训练质量和泛化能力。
16、2.资源优化的模型训练和部署:本发明利用tinyml技术和模型轻量化技术,确保机器学习模型能够在资源受限的嵌入式设备上流畅运行。这解决了传统音频检测模型在资源受限环境中的部署和运行问题。
17、3.实时音频检测:通过微控制器实时读取和处理音频输入数据,本发明能够实时进行音频检测并输出分类结果,满足各种实时应用的需求。
18、4.增强的模型泛化能力:本发明利用chatgpt生成的与原始数据集相似的新样本,丰富了训练数据集,从而增强了模型的泛化能力,使其在各种不同的场景中都能表现出色。
19、5.全面的声音类型识别:由于数据集中包含大量音频样本,每个样本都有一个类标签,本发明能够识别多种声音类型,满足多样化的应用需求。
20、6.自动化的触发操作:根据实时音频检测的结果,本发明可以根据需求添加触发操作,例如向手机发送通知,进一步提高应用的实用性和用户体验。
技术特征:1.一种基于tinyml与chatgpt的智能检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:所述文本数据包括由chatgpt根据提供的文本提示生成的文本。
3.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:所述文本到音频的转换工具为audioldm。
4.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:所述机器学习模型的训练使用tensorflow框架进行。
5.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:来自麦克风的实时音频输入被传输至微控制器模块,模型读取输入数据进行推理,并根据需求添加触发操作。
6.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:进一步包括:利用chatgpt生成一些与原始数据集相似的新样本,并将其添加到训练数据集中以增强模型的泛化能力。
7.根据权利要求1所述的基于tinyml与chatgpt的智能检测方法,其特征在于:所述数据集包含大量音频样本,每个样本都有一个类标签,用于识别声音的类型。
技术总结本发明公开了一种基于TinyML与ChatGPT的智能检测方法。首先,通过ChatGPT生成与音频场景相似的文本数据,并使用AudioLDM转换工具将文本转化为音频文件。接着,利用TensorFlow框架对所得数据集进行模型训练,并采用模型轻量化技术,如剪枝、量化等,使模型适应微控制器的运行环境。在实际应用中,微控制器实时捕获音频输入数据,模型进行推理并输出分类结果。根据推理结果,微控制器执行预设的触发操作,如控制设备或发送通知。本发明提供了一个高效、实用且具有广泛应用前景的音频检测方法。技术研发人员:高晨,赵鑫鑫,姜凯,李锐受保护的技术使用者:山东浪潮科学研究院有限公司技术研发日:技术公布日:2024/3/11本文地址:https://www.jishuxx.com/zhuanli/20240618/22228.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表